Hadoop et Spark, tous deux développés par l’Apache Software Foundation, sont des frameworks open-source largement utilisés pour les architectures big data. Nous sommes actuellement au cœur du phénomène Big Data et les entreprises ne peuvent plus ignorer l’impact des données sur leur prise de décision, d’où la nécessité de comparer Hadoop et Spark.
Pour rappel, les données considérées comme Big Data répondent à trois critères : vélocité, vitesse et variété. Cependant, vous ne pouvez pas traiter les Big Data avec les systèmes et technologies traditionnels.
C’est pour pallier ce problème qu’Apache Software Foundation a proposé les solutions les plus utilisées, à savoir Hadoop et Spark.
Cependant, les personnes qui débutent dans le traitement des Big Data ont du mal à comprendre ces deux technologies. Pour lever tous les doutes, découvrez dans cet article les principales différences entre Hadoop et Spark et quand vous devez choisir l’une ou l’autre, ou les utiliser ensemble.
Hadoop
Hadoop est un logiciel utilitaire composé de plusieurs modules formant un écosystème pour le traitement des Big Data. Le principe utilisé par Hadoop pour ce traitement est la distribution distribuée des données pour les traiter en parallèle.
La configuration du système de stockage distribué de Hadoop est composée de plusieurs ordinateurs ordinaires, formant ainsi un cluster de plusieurs nœuds. L’adoption de ce système permet à Hadoop de traiter efficacement l’énorme quantité de données disponibles en effectuant plusieurs tâches simultanément, rapidement et efficacement.
Les données traitées avec Hadoop peuvent prendre plusieurs formes. Elles peuvent être structurées comme des tableaux Excel ou des tableaux dans un SGBD conventionnel. Ces données peuvent également être présentées de manière semi-structurée, comme des fichiers JSON ou XML. Hadoop prend également en charge les données non structurées telles que les images, les vidéos ou les fichiers audio.
Principaux composants
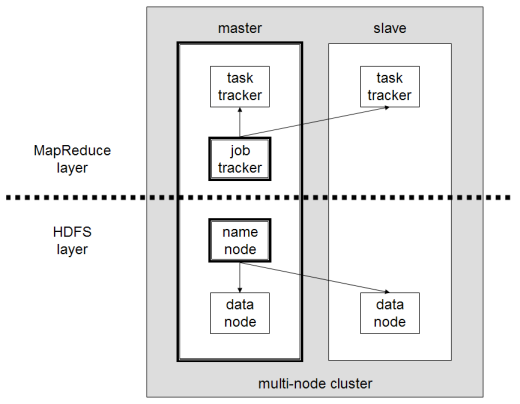
Les principaux composants de Hadoop sont les suivants
- HDFS ou Hadoop Distributed File System est le système utilisé par Hadoop pour effectuer le stockage distribué des données. Il est composé d’un nœud maître contenant les métadonnées du cluster et de plusieurs nœuds esclaves dans lesquels sont stockées les données elles-mêmes ;
- MapReduce est le modèle algorithmique utilisé pour traiter ces données distribuées. Ce modèle de conception peut être mis en œuvre à l’aide de plusieurs langages de programmation, tels que Java, R, Scala, Go, JavaScript ou Python. Il s’exécute en parallèle dans chaque nœud ;
- Hadoop Common, dans lequel plusieurs utilitaires et bibliothèques prennent en charge d’autres composants Hadoop ;
- YARN est un outil d’orchestration qui permet de gérer les ressources du cluster Hadoop et la charge de travail exécutée par chaque nœud. Il supporte également l’implémentation de MapReduce depuis la version 2.0 de ce framework.
Apache Spark
Apache Spark est un framework open-source initialement créé par l’informaticien Matei Zaharia dans le cadre de son doctorat en 2009. Il a ensuite rejoint l’Apache Software Foundation en 2010.

Spark est un moteur de calcul et de traitement de données réparti de manière distribuée sur plusieurs nœuds. La principale spécificité de Spark est qu’il effectue des traitements en mémoire, c’est-à-dire qu’il utilise la RAM pour mettre en cache et traiter les données volumineuses réparties dans le cluster. Cela lui confère de meilleures performances et une vitesse de traitement beaucoup plus élevée.
Spark prend en charge plusieurs tâches, notamment le traitement par lots, le traitement en flux réel, l’apprentissage automatique et le calcul graphique. Nous pouvons également traiter des données provenant de plusieurs systèmes, tels que HDFS, RDBMS ou même des bases de données NoSQL. L’implémentation de Spark peut se faire avec plusieurs langages, comme Scala ou Python.
Principaux composants
Les principaux composants d’Apache Spark sont :
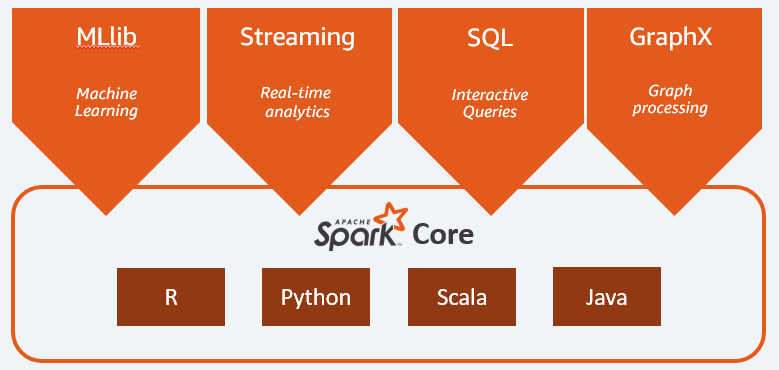
- Spark Core est le moteur général de toute la plateforme. Il est responsable de la planification et de la distribution des tâches, de la coordination des opérations d’entrée/sortie ou de la récupération en cas de panne ;
- Spark SQL est le composant fournissant le schéma RDD qui prend en charge les données structurées et semi-structurées. Il permet notamment d’optimiser la collecte et le traitement de données de type structuré en exécutant du SQL ou en donnant accès au moteur SQL ;
- Spark Streaming qui permet l’analyse de données en continu. Spark Streaming prend en charge les données provenant de différentes sources telles que Flume, Kinesis ou Kafka ;
- MLib, la bibliothèque intégrée d’Apache Spark pour l’apprentissage automatique. Elle fournit plusieurs algorithmes d’apprentissage automatique ainsi que plusieurs outils pour créer des pipelines d’apprentissage automatique ;
- GraphX combine un ensemble d’API pour effectuer des modélisations, des calculs et des analyses de graphes au sein d’une architecture distribuée.
Hadoop vs Spark : Différences
Spark est un moteur de calcul et de traitement de données Big Data. En théorie, il est donc un peu comme Hadoop MapReduce, qui est beaucoup plus rapide puisqu’il fonctionne en mémoire. Mais qu’est-ce qui différencie Hadoop et Spark ? Voyons cela de plus près :

- Spark est beaucoup plus efficace, notamment grâce au traitement en mémoire, alors qu’Hadoop procède par lots ;
- Spark est beaucoup plus cher en termes de coût car il nécessite une quantité importante de RAM pour maintenir ses performances. Hadoop, quant à lui, ne s’appuie que sur une machine ordinaire pour le traitement des données ;
- Hadoop convient mieux au traitement par lots, tandis que Spark est plus adapté au traitement de données en continu ou de flux de données non structurées ;
- Hadoop est plus tolérant aux pannes car il réplique continuellement les données, tandis que Spark utilise des ensembles de données distribuées résilientes (RDD) qui s’appuient eux-mêmes sur HDFS.
- Hadoop est plus évolutif, car il vous suffit d’ajouter une machine supplémentaire si les machines existantes ne suffisent plus. Spark s’appuie sur le système d’autres frameworks, tels que HDFS, pour s’étendre.
| Facteur | Hadoop | Spark |
|---|---|---|
| Traitement | Traitement par lots | Traitement en mémoire |
| Gestion des fichiers | HDFS | Utilise HDFS de Hadoop |
| Vitesse | Rapide | 10 à 1000 fois plus rapide |
| Langages pris en charge | Java, Python, Scala, R, Go et JavaScript | Java, Python, Scala et R |
| Tolérance aux pannes | Plus tolérant | Moins tolérante |
| Coût | Moins cher | Plus cher |
| Évolutivité | Plus évolutive | Moins évolutive |
Hadoop est une bonne solution pour
Hadoop est une bonne solution si la vitesse de traitement n’est pas essentielle. Par exemple, si le traitement des données peut être effectué pendant la nuit, il est judicieux d’envisager l’utilisation de MapReduce de Hadoop.
Hadoop vous permet de décharger les grands ensembles de données des entrepôts de données où il est comparativement difficile de les traiter, car HDFS d’Hadoop offre aux organisations un meilleur moyen de stocker et de traiter les données.
Spark est bon pour :
Les RDD (Resilient Distributed Datasets) de Spark permettent de multiples opérations de mappage en mémoire, alors que Hadoop MapReduce doit écrire les résultats intermédiaires sur le disque, ce qui fait de Spark une option privilégiée si vous souhaitez effectuer des analyses de données interactives en temps réel.
Le traitement en mémoire de Spark et la prise en charge de bases de données distribuées telles que Cassandra ou MongoDB constituent une excellente solution pour la migration et l’insertion de données – lorsque les données sont extraites d’une base de données source et envoyées vers un autre système cible.
Utilisation conjointe d’Hadoop et de Spark
Vous devez souvent choisir entre Hadoop et Spark ; cependant, dans la plupart des cas, il n’est pas nécessaire de choisir, car ces deux frameworks peuvent très bien coexister et travailler ensemble. En effet, la raison principale du développement de Spark était d’améliorer Hadoop plutôt que de le remplacer.

Comme nous l’avons vu dans les sections précédentes, Spark peut être intégré à Hadoop en utilisant son système de stockage HDFS. En effet, ils permettent tous deux un traitement plus rapide des données dans un environnement distribué. De même, vous pouvez allouer des données sur Hadoop et les traiter à l’aide de Spark ou exécuter des tâches dans Hadoop MapReduce.
Conclusion
Hadoop ou Spark ? Avant de choisir le framework, vous devez considérer votre architecture, et les technologies qui la composent doivent être cohérentes avec l’objectif que vous souhaitez atteindre. De plus, Spark est entièrement compatible avec l’écosystème Hadoop et fonctionne de manière transparente avec Hadoop Distributed File System et Apache Hive.