
Le sharding est un processus qui consiste à diviser les ensembles de données à grande échelle en un ensemble d’ensembles de données plus petits sur plusieurs instances MongoDB dans un environnement distribué.
Qu’est-ce que le sharding ?
Lesharding MongoDB fournit une solution évolutive pour stocker une grande quantité de données sur plusieurs serveurs au lieu de les stocker sur un seul serveur.
En pratique, il n’est pas possible de stocker des données à croissance exponentielle sur une seule machine. L’interrogation d’une grande quantité de données stockées sur un seul serveur pourrait entraîner une utilisation élevée des ressources et ne pas fournir un débit de lecture et d’écriture satisfaisant.
Fondamentalement, il existe deux types de méthodes de mise à l’échelle permettant d’intégrer des données croissantes dans le système :
- Verticale
- Horizontale
La miseà l’échelle verticale permet d’améliorer les performances d’un serveur unique en ajoutant des processeurs plus puissants, en améliorant la mémoire vive ou en ajoutant de l’espace disque au système. Mais il existe des implications possibles de l’application de la mise à l’échelle verticale dans des cas d’utilisation pratiques avec la technologie et les configurations matérielles existantes.
La mise à l’échellehorizontale consiste à ajouter des serveurs et à répartir la charge sur plusieurs serveurs. Étant donné que chaque machine traitera un sous-ensemble de l’ensemble des données, cette solution est plus efficace et plus rentable que le déploiement d’un matériel haut de gamme. Mais elle nécessite une maintenance supplémentaire d’une infrastructure complexe avec un grand nombre de serveurs.
Le sharding de Mongo DB fonctionne selon la technique de la mise à l’échelle horizontale.
Composants du sharding
Pour réaliser le sharding dans MongoDB, les composants suivants sont nécessaires :
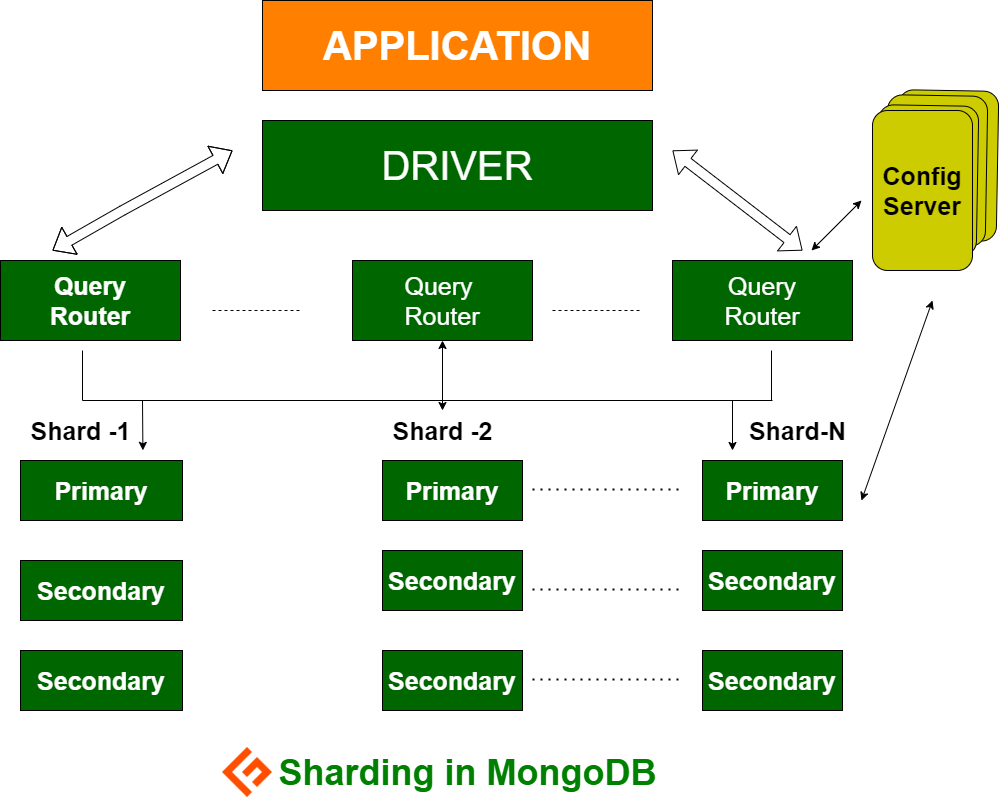
Leshard est une instance Mongo qui gère un sous-ensemble de données originales. Les shards doivent être déployés dans l’ensemble de répliques.
Mongos est une instance Mongo qui sert d’interface entre une application client et un cluster partagé. Il fonctionne comme un routeur de requêtes vers les grappes.
Config Server est une instance Mongo qui stocke les métadonnées et les détails de configuration du cluster. MongoDB exige que le serveur de configuration soit déployé en tant qu’ensemble de répliques.
Architecture du sharding
Le cluster MongoDB est constitué d’un certain nombre d’ensembles de répliques.
Chaque ensemble de répliques se compose d’un minimum de 3 instances Mongo ou plus. Un cluster shardé peut être constitué de plusieurs instances mongo shards, et chaque instance shard travaille au sein d’un ensemble de répliques shard. L’application interagit avec Mongos, qui communique à son tour avec les clusters. Par conséquent, dans le cas du sharding, les applications n’interagissent jamais directement avec les nœuds de shard. Le routeur de requêtes distribue les sous-ensembles de données entre les nœuds de stockage sur la base de la clé de stockage.
Mise en œuvre du sharding
Suivez les étapes suivantes pour la mise en place d’un système de stockage (sharding)
Étape 1
- Démarrez le serveur config dans l’ensemble de répliques et activez la réplication entre eux.
mongod --configsvr --port 27019 --replSet rs0 --dbpath C:\data\data1 --bind_ip localhost
mongod --configsvr --port 27018 --replSet rs0 --dbpath C:\data\data2 --bind_ip localhost
mongod --configsvr --port 27017 --replSet rs0 --dbpath C:\data\data3 --bind_ip localhost
Étape 2
- Initialiser l’ensemble de répliques sur l’un des serveurs de configuration.
rs.initiate( { _id : "rs0", configsvr : true, members : [ { _id : 0, host : "IP:27017" }, { _id : 1, host : "IP:27018" }, { _id : 2, host : "IP:27019" } ] })
rs.initiate( { _id : "rs0", configsvr : true, members : [ { _id : 0, host : "IP:27017" }, { _id : 1, host : "IP:27018" }, { _id : 2, host : "IP:27019" } ] })
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1593569257, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1593569257, 1),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569257, 1)
}Étape 3
- Démarrez les serveurs de sharding dans l’ensemble de répliques et activez la réplication entre eux.
mongod --shardsvr --port 27020 --replSet rs1 --dbpath C:\data\data4 --bind_ip localhost
mongod --shardsvr --port 27021 --replSet rs1 --dbpath C:\data\data5 --bind_ip localhost
mongod --shardsvr --port 27022 --replSet rs1 --dbpath C:\data\data6 --bind_ip localhost
MongoDB initialise le premier serveur de sharding en tant que serveur primaire, pour déplacer le serveur de sharding primaire, utilisez la méthode movePrimary.
Étape 4
- Initialisez l’ensemble de répliques sur l’un des serveurs de sharding.
rs.initiate( { _id : "rs0", members : [ { _id : 0, host : "IP:27020" }, { _id : 1, host : "IP:27021" }, { _id : 2, host : "IP:27022" } ] })
rs.initiate( { _id : "rs0", members : [ { _id : 0, host : "IP:27020" }, { _id : 1, host : "IP:27021" }, { _id : 2, host : "IP:27022" } ] })
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1593569748, 1),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569748, 1)
}Étape 5
- Démarrez les mangos pour le cluster shardé
mongos --port 40000 --configdb rs0/localhost:27019,localhost:27018, localhost:27017
Étape 6
- Connectez le serveur de route Mongo
mongo --port 40000
- Maintenant, ajoutez les serveurs de sharding.
sh.addShard( "rs1/localhost:27020,localhost:27021,localhost:27022")
sh.addShard( "rs1/localhost:27020,localhost:27021,localhost:27022")
{
"shardAdded" : "rs1",
"ok" : 1,
"operationTime" : Timestamp(1593570212, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570212, 2),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Étape 7
- Dans le shell Mongo, activez le sharding sur la base de données et les collections.
- Activez le sharding sur la base de données
sh.enableSharding("geekFlareDB")
sh.enableSharding("geekFlareDB")
{
"ok" : 1,
"operationTime" : Timestamp(1591630612, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1591630612, 1),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Étape 8
- Pour partager la collection, vous devez utiliser la clé de partage (décrite plus loin dans cet article).
Syntaxe: sh.shardCollection("dbName.collectionName", { "key" : 1 } )<br>
sh.shardCollection("geekFlareDB.geekFlareCollection", { "key" : 1 } )
{
"collectionharded" : "geekFlareDB.geekFlareCollection",
"collectionUUID" : UUID("0d024925-e46c-472a-bf1a-13a8967e97c1"),
"ok" : 1,
"operationTime" : Timestamp(1593570389, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570389, 3),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Remarque : si la collection n’existe pas, créez-la comme suit.
db.createCollection("geekFlareCollection")
{
"ok" : 1,
"operationTime" : Timestamp(1593570344, 4),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570344, 5),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Étape 9
Insérez les données dans la collection. Les journaux Mongo vont commencer à augmenter, ce qui indique qu’un équilibreur est en action et qu’il essaie d’équilibrer les données parmi les shards.
Étape 10
La dernière étape consiste à vérifier l’état de la répartition. L’état peut être vérifié en exécutant la commande suivante sur le nœud de route Mongos.
État de la répartition
Vérifiez l’état de la répartition en exécutant la commande suivante sur le nœud de route Mongo.
sh.status()
mongos> sh.status()
--- Statut de la sauvegarde ---
version de la répartition : {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5ede66c22c3262378c706d21")
}
shards :
{ "_id" : "rs1", "host" : "rs1/localhost:27020,localhost:27021,localhost:27022", "state" : 1 }
mongoses actives :
"4.2.7" : 1
autosplit :
Actuellement activé : oui
balancer :
Actuellement activé : oui
En cours d'exécution : non
Rondes d'équilibrage échouées au cours des 5 dernières tentatives : 5
Dernière erreur signalée : Impossible de trouver un hôte correspondant à la préférence de lecture { mode : "primary" } pour l'ensemble rs1
Heure de l'erreur signalée : Tue Jun 09 2020 15:25:03 GMT 0530 (India Standard Time)
Résultats de la migration pour les dernières 24 heures :
Aucune migration récente
bases de données :
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key : { "_id" : 1 }
unique : false
balancing : true
chunks :
rs1 1024
trop de chunks à imprimer, utilisez verbose si vous voulez forcer l'impression
{ "_id" : "geekFlareDB", "primary" : "rs1", "partitioned" : true, "version" : { "uuid" : UUID("a770da01-1900-401e-9f34-35ce595a5d54"), "lastMod" : 1 } }
geekFlareDB.geekFlareCol
shard key : { "key" : 1 }
unique : false
balancing : true
chunks :
rs1 1
{ "key" : { "$minKey" : 1 } } -->
> { "key" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
geekFlareDB.geekFlareCollection
shard key : { "product" : 1 }
unique : false
balancing : true
chunks :
rs1 1
{ "product" : { "$minKey" : 1 } } -->
> { "product" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs1", "partitioned" : false, "version" : { "uuid" : UUID("fbc00f03-b5b5-4d13-9d09-259d7fdb7289"), "lastMod" : 1 } }
mongos>Distribution des données
Le routeur Mongos répartit la charge entre les shards en fonction de la clé du shard et, pour répartir les données de manière uniforme, l’équilibreur entre en action.
Les composants clés de la distribution des données entre les serveurs sont les suivants
- Un équilibreur joue un rôle dans l’équilibrage du sous-ensemble de données entre les nœuds de stockage. L’équilibreur s’exécute lorsque le serveur Mongos commence à répartir les charges entre les nuages. Une fois lancé, l’équilibreur distribue les données de manière plus homogène. Pour vérifier l’état de l’équilibreur, exécutez
<strong>sh.status()</strong>oush.getBalancerState()oush<code class="language-markup">.isBalancerRunning().
mongos> sh.isBalancerRunning()
true
mongos>OR
mongos> sh.getBalancerState()
true
mongos>Après avoir inséré les données, nous pourrions remarquer une certaine activité dans le démon Mongos indiquant qu’il déplace des morceaux pour les unités de stockage spécifiques et ainsi de suite, c’est-à-dire que l’équilibreur sera en action en essayant d’équilibrer les données entre les unités de stockage. L’exécution de l’équilibreur peut entraîner des problèmes de performance ; il est donc conseillé d’exécuter l’équilibreur à l’intérieur d’une certaine fenêtre d’équilibreur.
mongos> sh.status()
--- État de la sauvegarde ---
version de la répartition : {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5efbeff98a8bbb2d27231674")
}
shards :
{ "_id" : "rs1", "host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022", "state" : 1 }
{"_id" : "rs2", "host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025", "state" : 1 }
mongoses actives :
"4.2.7" : 1
autosplit :
Actuellement activé : oui
balancer :
Actuellement activé : oui
En cours d'exécution : oui
Rondes d'équilibrage échouées au cours des 5 dernières tentatives : 5
Dernière erreur signalée : Impossible de trouver un hôte correspondant à la préférence de lecture { mode : "primary" } pour l'ensemble rs2
Heure de l'erreur signalée : Wed Jul 01 2020 14:39:59 GMT 0530 (India Standard Time)
Résultats de la migration pour les dernières 24 heures :
1024 : Succès
bases de données :
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key : { "_id" : 1 }
unique : false
balancing : true
chunks :
rs2 1024
trop de chunks à imprimer, utilisez verbose si vous voulez forcer l'impression
{ "_id" : "geekFlareDB", "primary" : "rs2", "partitioned" : true, "version" : { "uuid" : UUID("a8b8dc5c-85b0-4481-bda1-00e53f6f35cd"), "lastMod" : 1 } }
geekFlareDB.geekFlareCollection
shard key : { "key" : 1 }
unique : false
balancing : true
chunks :
rs2 1
{ "key" : { "$minKey" : 1 } } -->
> { "key" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs2", "partitioned" : false, "version" : { "uuid" : UUID("a28d7504-1596-460e-9e09-0bdc6450028f"), "lastMod" : 1 } }
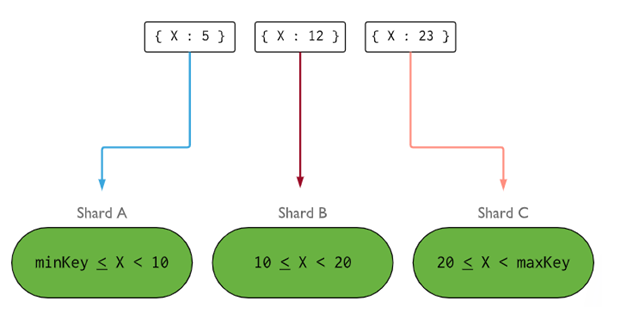
mongos>- Laclé de tesson détermine la logique de distribution des documents de la collection de tessons entre les tessons. La clé du nuage peut être un champ indexé ou un champ composé indexé qui doit être présent dans tous les documents de la collection à insérer. Les données seront divisées en morceaux, et chaque morceau sera associé à la clé de stockage basée sur l’intervalle. Sur la base de la plage, le routeur décidera du dépôt qui stockera le morceau.
Laclé de stockage peut être sélectionnée en tenant compte de cinq propriétés :
- Cardinalité
- Distribution en écriture
- Distribution en lecture
- Ciblage de la lecture
- Localité de lecture
Une clé idéale permet à MongoDB de répartir uniformément la charge entre tous les serveurs. Le choix d’une bonne clé est extrêmement important.
Suppression d’un nœud de stockage
Avant de retirer les nœuds de la grappe, l’utilisateur doit s’assurer que la migration des données vers les nœuds restants s’effectue en toute sécurité. MongoDB se charge de drainer en toute sécurité les données vers d’autres nœuds de stockage avant la suppression du nœud de stockage requis.
Exécutez la commande ci-dessous pour supprimer le nœud de stockage requis.
Étape 1
Tout d’abord, nous devons déterminer le nom d’hôte du nœud de stockage à supprimer. La commande ci-dessous permet d’obtenir la liste de tous les serveurs présents dans le cluster ainsi que leur état.
db.adminCommand( { listShards : 1 } )
mongos> db.adminCommand( { listShards : 1 } )
{
"shards" : [
{
"_id" : "rs1",
"host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022",
"state" : 1
},
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593572866, 15),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572866, 15),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Étape 2
Exécutez la commande ci-dessous pour supprimer le nœud de stockage requis du cluster. Une fois la commande lancée, l’équilibreur se charge de retirer les morceaux du nœud de stockage épuisé et de répartir les morceaux restants entre les autres nœuds de stockage.
db.adminCommand( { removeShard : "shardedReplicaNodes" } )
mongos> db.adminCommand( { removeShard : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022" } )
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "rs1",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1,
"operationTime" : Timestamp(1593572385, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572385, 2),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Étape 3
Pour vérifier l’état du shard drainé, exécutez à nouveau la même commande.
db.adminCommand( { removeShard : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022" } )
Nous devons attendre que la vidange des données soit terminée. Les champs msg et state indiqueront si la vidange des données est terminée ou non, comme suit
"msg" : "draining ongoing" (vidange en cours),
"state" : "ongoing",Vous pouvez également vérifier le statut avec la commande sh.status(). Une fois que le nœud shardé a été supprimé, il ne sera pas reflété dans la sortie. Mais si la vidange est en cours, le noeud barricadé aura le statut “vidange” comme vrai.
Étape 4
Continuez à vérifier l’état de la vidange avec la même commande ci-dessus, jusqu’à ce que le sharded requis soit complètement supprimé.
Une fois l’opération terminée, la sortie de la commande reflétera le message et l’état terminé.
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "rs1",
"ok" : 1,Étape 5
Enfin, nous devons vérifier les shards restants dans le cluster. Pour vérifier l’état, entrez <strong>sh.status()</strong> ou <strong>db.adminCommand( { listShards : 1 } )</strong>
mongos> db.adminCommand( { listShards : 1 } )
{
"shards" : [
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593575215, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593575215, 3),
"signature" : {
"hash" : BinData(0, "AAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}Ici, nous pouvons voir que le shard supprimé n’est plus présent dans la liste des shards.
Avantages du sharding par rapport à la réplication
- Dans la réplication, le nœud principal gère toutes les opérations d’écriture, tandis que les serveurs secondaires doivent maintenir des copies de sauvegarde ou effectuer des opérations en lecture seule. En revanche, dans le cas du sharding et des ensembles de répliques, la charge est répartie entre un certain nombre de serveurs.
- Un ensemble de répliques est limité à 12 nœuds, mais il n’y a pas de restriction sur le nombre d’ensembles de répliques.
- La réplication nécessite du matériel haut de gamme ou une mise à l’échelle verticale pour traiter les grands ensembles de données, ce qui est trop coûteux par rapport à l’ajout de serveurs supplémentaires dans le sharding.
- Dans le cas de la réplication, les performances en lecture peuvent être améliorées par l’ajout de serveurs esclaves/secondaires, alors que dans le cas du sharding, les performances en lecture et en écriture seront améliorées par l’ajout de nœuds de sharding supplémentaires.
Limitation du sharding
- Le cluster Sharded ne supporte pas l’indexation unique à travers les shards jusqu’à ce que l’index unique soit préfixé avec la clé complète du shard.
- Toutes les opérations de mise à jour d’une collection shardée sur un ou plusieurs documents doivent contenir la clé shardée ou le champ _id dans la requête.
- Les collections peuvent être partagées si leur taille ne dépasse pas le seuil spécifié. Ce seuil peut être estimé sur la base de la taille moyenne de toutes les clés de la collection et de la taille configurée des morceaux.
- Le sharding comprend des limites opérationnelles sur la taille maximale de la collection ou le nombre de divisions.
- Le choix d’une mauvaise clé de répartition peut avoir des conséquences sur les performances.
Conclusion
MongoDB propose un système de répartition intégré qui permet d’implémenter une base de données volumineuse sans compromettre les performances. J’espère que ce qui précède vous aidera à configurer le sharding MongoDB. Ensuite, vous voudrez peut-être vous familiariser avec certaines des commandes MongoDB couramment utilisées.