Dans cet article, nous allons parler de la vectorisation – une technique de TAL – et comprendre son importance grâce à un guide complet sur les différents types de vectorisation.
Nous avons abordé les concepts fondamentaux du prétraitement NLP et du nettoyage de texte. Nous avons examiné les bases du TAL, ses diverses applications et des techniques telles que la tokenisation, la normalisation, la standardisation et le nettoyage de texte.

Avant d’aborder la vectorisation, revoyons ce qu’est la tokenisation et en quoi elle diffère de la vectorisation.
Qu’est-ce que la tokenisation ?
La tokenisation est le processus de décomposition des phrases en unités plus petites appelées tokens. Les jetons aident les ordinateurs à comprendre et à travailler facilement avec le texte.
EX. ‘Cet article est bon’
Tokens- [‘Cet’, ‘article’, ‘est’, ‘bon’]
Qu’est-ce que la vectorisation ?
Comme nous le savons, les modèles et algorithmes d’apprentissage automatique comprennent des données numériques. La vectorisation est un processus qui consiste à convertir des données textuelles ou catégorielles en vecteurs numériques. En convertissant les données en données numériques, vous pouvez entraîner votre modèle avec plus de précision.
Pourquoi avons-nous besoin de la vectorisation ?
❇️ La tokenisation et la vectorisation ont une importance différente dans le traitement du langage naturel (TLN). La tokenisation décompose les phrases en petits jetons. La vectorisation les convertit dans un format numérique afin que l’ordinateur/le modèle de langage naturel puisse les comprendre.
❇️ La vectorisation n’est pas seulement utile pour la conversion en format numérique, mais aussi pour la capture du sens sémantique.
❇️ La vectorisation peut réduire la dimensionnalité des données et les rendre plus efficaces. Cela peut s’avérer très utile lorsque vous travaillez sur un grand ensemble de données.
❇️ De nombreux algorithmes d’apprentissage automatique nécessitent une entrée numérique, tels que les réseaux neuronaux, de sorte que la vectorisation peut nous aider.
Il existe différents types de techniques de vectorisation, que nous allons comprendre dans cet article.
Sac de mots
Si vous disposez d’un ensemble de documents ou de phrases et que vous souhaitez les analyser, un sac de mots simplifie ce processus en traitant le document comme un sac rempli de mots.
L’approche par sac de mots peut être utile pour la classification des textes, l’analyse des sentiments et la recherche de documents.
Supposons que vous travailliez sur un grand nombre de textes. Un sac de mots vous aidera à représenter les données textuelles en créant un vocabulaire de mots uniques dans nos données textuelles. Après avoir créé le vocabulaire, il codera chaque mot sous la forme d’un vecteur basé sur la fréquence (combien de fois chaque mot apparaît dans ce texte) de ces mots.
Ces vecteurs sont constitués de nombres non négatifs (0,1,2…..) qui représentent le nombre de fréquences dans ce document.
Le sac de mots comporte trois étapes :
Étape 1 : tokenisation
Elle décompose les documents en jetons.
Ex – (Phrase : “J’aime les pizzas et j’aime les hamburgers”)
Étape 2 : Séparation des mots uniques/création d’un vocabulaire
Créez une liste de tous les mots uniques qui apparaissent dans vos phrases.
[“Je”, “aime”, “Pizza”, “et”, “Burgers”]
Étape 3 : Comptage des occurrences de mots/création de vecteurs
Cette étape consiste à compter le nombre de fois que chaque mot est répété à partir du vocabulaire et à le stocker dans une matrice éparse. Dans la matrice éparse, chaque ligne d’un vecteur de phrase dont la longueur (les colonnes de la matrice) est égale à la taille du vocabulaire.
Importer CountVectorizer
Nous allons importer CountVectorizer pour entraîner notre modèle de sac de mots
from sklearn.feature_extraction.text import CountVectorizerCréer un vecteur
Dans cette étape, nous allons créer notre modèle à l’aide de CountVectorizer et l’entraîner en utilisant notre échantillon de document texte.
# Échantillon de documents textuels
documents = [
"Ceci est le premier document",
"Ce document est le deuxième document.",
"Et voici le troisième",
"Est-ce le premier document ?",
]
# Créez un CountVectorizer
cv = CountVectorizer()# Ajuster et transformer
X = cv.fit_transform(documents)Convertir en un tableau dense
Dans cette étape, nous allons convertir nos représentations en un tableau dense. Nous allons également obtenir les noms des caractéristiques ou des mots.
# Obtenez les noms/mots des caractéristiques
feature_names = vectorizer.get_feature_names_out()
# Convertir en tableau dense
X_dense = X.toarray()
Imprimons la matrice des termes du document et les mots caractéristiques
# Affichez la MNT et les noms des caractéristiques
print("Matrice Document-Terme (MDT) :")
print(X_dense)
print("Noms des caractéristiques :")
print(noms_caractéristiques)
Matrice Document-Terme (DTM) :

Noms des caractéristiques :

Comme vous pouvez le constater, les vecteurs sont constitués de nombres non négatifs (0,1,2……) qui représentent la fréquence des mots dans le document.
Nous disposons de quatre exemples de documents textuels et nous avons identifié neuf mots uniques dans ces documents. Nous avons stocké ces mots uniques dans notre vocabulaire en leur attribuant des “noms de caractéristiques”
Ensuite, notre modèle de sac de mots vérifie si le premier mot unique est présent dans notre premier document. S’il est présent, il lui attribue la valeur 1, sinon il lui attribue la valeur 0.
Si le mot apparaît plusieurs fois (par exemple, deux fois), il lui attribue une valeur en conséquence.
Par exemple, dans le deuxième document, le mot “document” apparaît deux fois; sa valeur dans la matrice sera donc 2.
Si nous voulons qu’un seul mot soit considéré comme une caractéristique du vocabulaire clé – Représentation des unigrammes.
n – grammes = Unigrammes, bigrammes…….etc.
Il existe de nombreuses bibliothèques comme scikit-learn pour mettre en œuvre les sacs de mots : Keras, Gensim, et d’autres. Cette méthode est simple et peut s’avérer utile dans différents cas.
Le sac de mots est plus rapide, mais il présente certaines limites.
- Il attribue le même poids à chaque mot, quelle que soit son importance. Dans de nombreux cas, certains mots sont plus importants que d’autres.
- La méthode BoW se contente de compter la fréquence d’un mot ou le nombre de fois qu’un mot apparaît dans un document. Cela peut entraîner un biais en faveur des mots courants tels que “le”, “et”, “est”, etc. qui peuvent ne pas avoir beaucoup de sens.
- Les documents plus longs peuvent compter plus de mots et créer des vecteurs plus importants. Cela peut compliquer la comparaison. Il peut en résulter une matrice éparse, ce qui n’est pas favorable à la réalisation de projets NLP complexes.
Pour résoudre ce problème, nous pouvons choisir de meilleures approches, l’une d’entre elles étant le TF-IDF. Comprenons-le en détail.
TF-IDF
TF-IDF, ou Term Frequency – Inverse Document Frequency, est une représentation numérique permettant de déterminer l’importance des mots dans un document.
Pourquoi avons-nous besoin de TF-IDF plutôt que d’un sac de mots ?
Un sac de mots traite tous les mots de la même manière et ne s’intéresse qu’à la fréquence des mots uniques dans les phrases. Le TF-IDF accorde de l’importance aux mots d’un document en tenant compte à la fois de leur fréquence et de leur caractère unique.
Les mots qui sont répétés trop souvent ne prennent pas le dessus sur les mots moins fréquents et plus importants.
TF: La fréquence des termes mesure l’importance d’un mot dans une phrase.
IDF: La fréquence inverse des documents mesure l’importance d’un mot dans l’ensemble des documents.
TF = Fréquence des mots dans un document / Nombre total de mots dans ce document
DF = Document contenant le mot w / Nombre total de documents
IDF = log(Nombre total de documents / Documents contenant le mot w)
L’IDF est la réciproque de DF. La raison en est que plus le mot est commun à tous les documents, moins il est important dans le document actuel.
Score TF-IDF final : TF-IDF = TF * IDF
Il s’agit d’un moyen de déterminer quels mots sont communs dans un seul document et uniques dans tous les documents. Ces mots peuvent être utiles pour trouver le thème principal du document.
Par exemple, Doc1 = “J’aime l’apprentissage automatique”,
Doc1 = “J’aime l’apprentissage automatique”
Doc2 = “J’aime Geekflare”
Nous devons trouver la matrice TF-IDF pour nos documents.
Tout d’abord, nous allons créer un vocabulaire de mots uniques.
Vocabulaire = [“I”, “love”, “machine”, “learning”, “Geekflare”]
Nous avons donc 5 mots. Trouvons la TF et l’IDF pour ces mots.
TF = Fréquence des mots dans un document / Nombre total de mots dans ce document
TF :
- Pour “I” = TF pour Doc1 : 1/4 = 0.25 et pour Doc2 : 1/3 ≈ 0.33
- Pour “amour” : TF pour Doc1 : 1/4 = 0.25 et pour Doc2 : 1/3 ≈ 0.33
- Pour “Machine” : TF pour Doc1 : 1/4 = 0,25 et pour Doc2 : 0/3 ≈ 0
- Pour “Apprentissage” : TF pour Doc1 : 1/4 = 0.25 et pour Doc2 : 0/3 ≈ 0
- Pour “Geekflare” : TF pour Doc1 : 0/4 = 0 et pour Doc2 : 1/3 ≈ 0.33
Maintenant, calculons l’IDF.
IDF = log(Nombre total de documents / Documents contenant le mot w)
IDF :
- Pour “I” : IDF est log(2/2) = 0
- Pour “amour” : IDF est log(2/2) = 0
- Pour “Machine” : IDF est log(2/1) = log(2) ≈ 0.69
- Pour “Apprentissage” : IDF est log(2/1) = log(2) ≈ 0.69
- Pour “Geekflare” : IDF est log(2/1) = log(2) ≈ 0.69
Maintenant, calculons le score final du TF-IDF :
- Pour “I” : TF-IDF pour Doc1 : 0.25 * 0 = 0 et TF-IDF pour Doc2 : 0.33 * 0 = 0
- Pour “amour” : TF-IDF pour Doc1 : 0.25 * 0 = 0 et TF-IDF pour Doc2 : 0.33 * 0 = 0
- Pour “Machine” : TF-IDF pour Doc1 : 0.25 * 0.69 ≈ 0.17 et TF-IDF pour Doc2 : 0 * 0.69 = 0
- Pour “Apprentissage” : TF-IDF pour Doc1 : 0.25 * 0.69 ≈ 0.17 et TF-IDF pour Doc2 : 0 * 0.69 = 0
- Pour “Geekflare” : TF-IDF pour Doc1 : 0 * 0.69 = 0 et TF-IDF pour Doc2 : 0.33 * 0.69 ≈ 0.23
La matrice TF-IDF ressemble à ceci :
J'aime l'apprentissage automatique Geekflare
Doc1 0.0 0.0 0.17 0.17 0.0
Doc2 0.0 0.0 0.0 0.0 0.23
Les valeurs d’une matrice TF-IDF vous indiquent l’importance de chaque terme dans chaque document. Des valeurs élevées indiquent qu’un terme est important dans un document particulier, tandis que des valeurs faibles suggèrent que le terme est moins important ou moins courant dans ce contexte.
La matrice TF-IDF est principalement utilisée pour la classification de textes, la recherche d’informations dans les chatbots et le résumé de textes.
Importer TfidfVectorizer
Importons TfidfVectorizer de sklearn
from sklearn.feature_extraction.text import TfidfVectorizerCréer un vecteur
Comme vous pouvez le voir, nous allons créer notre modèle Tf Idf en utilisant TfidfVectorizer.
# Échantillon de documents textuels
text = [
"Ceci est le premier document",
"Ce document est le deuxième document.",
"Et voici le troisième",
"Est-ce le premier document ?",
]
# Créez un TfidfVectorizer
cv = TfidfVectorizer()Création de la matrice TF-IDF
Entraînons notre modèle en fournissant du texte. Après cela, nous allons convertir la matrice représentative en un tableau dense.
# Ajustez et transformez pour créer la matrice TF-IDF
X = cv.fit_transform(text)# Obtenez les noms/mots des caractéristiques
feature_names = vectorizer.get_feature_names_out()
# Convertissez la matrice TF-IDF en un tableau dense pour une manipulation plus facile (optionnel)
X_dense = X.toarray()Imprimer la matrice TF-IDF et les mots-clés
# Imprimez la matrice TF-IDF et les mots caractéristiques
print("Matrice TF-IDF :")
print(X_dense)
print("Noms des caractéristiques :")
print(noms_caractéristiques)
Matrice TF-IDF :

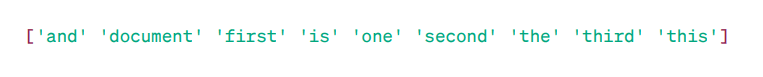
Comme vous pouvez le constater, ces nombres entiers à virgule indiquent l’importance des mots dans des documents spécifiques.
Vous pouvez également combiner des mots par groupes de 2, 3, 4, etc. à l’aide de n-grammes.
D’autres paramètres peuvent être inclus : min_df, max_feature, subliner_tf, etc.
Jusqu’à présent, nous avons exploré les techniques de base basées sur la fréquence.
Jusqu’à présent, nous avons exploré les techniques de base basées sur la fréquence, mais le TF-IDF ne peut pas fournir une signification sémantique et une compréhension contextuelle du texte.
Voyons maintenant des techniques plus avancées qui ont changé le monde de l’incorporation de mots et qui sont meilleures pour la signification sémantique et la compréhension contextuelle.
Word2Vec
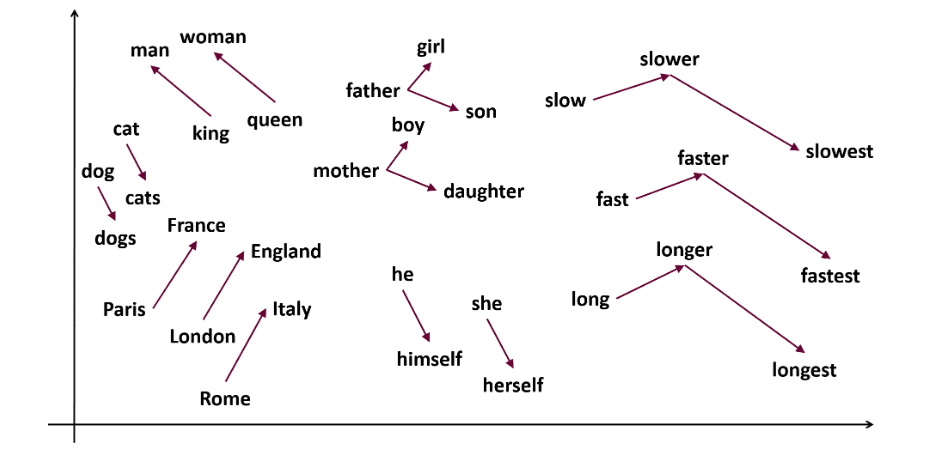
Word2vec est une technique populaire d’intégration de mots (type de vecteur de mots et utile pour capturer la similarité sémantique et syntaxique) dans le domaine du NLP. Elle a été développée par Tomas Mikolov et son équipe chez Google en 2013. Word2vec représente les mots comme des vecteurs continus dans un espace multidimensionnel.
Word2vec vise à représenter les mots d’une manière qui capture leur sens sémantique. Les vecteurs de mots générés par word2vec sont positionnés dans un espace vectoriel continu.
Par exemple, les vecteurs “chat” et “chien” sont plus proches que les vecteurs “chat” et “fille”.
Deux architectures de modèles peuvent être utilisées par word2vec pour créer l’intégration de mots.
CBOW: Le modèle CBOW (Continous bag of words) tente de prédire un mot en calculant la moyenne du sens des mots voisins. Il prend un nombre fixe ou une fenêtre de mots autour du mot cible, le convertit en forme numérique (Embedding), fait la moyenne de tous les mots et utilise cette moyenne pour prédire le mot cible à l’aide du réseau neuronal.
Ex- Prédire la cible : ‘Fox’
Mots de la phrase : ‘The’, ‘quick’, ‘brown’, ‘jumps’, ‘over’, ‘the’
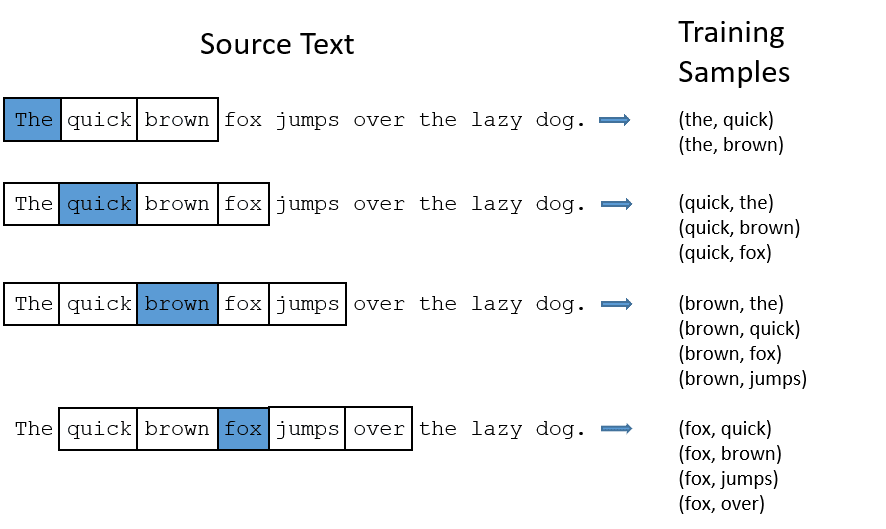
- CBOW prend une fenêtre de taille fixe (nombre) de mots comme 2 (2 à gauche et 2 à droite)
- Convertit en intégration de mots.
- CBOW calcule la moyenne de l’intégration des mots.
- CBOW calcule la moyenne de l’intégration des mots par rapport aux mots du contexte.
- Le vecteur moyenné tente de prédire un mot cible à l’aide d’un réseau neuronal.
Voyons maintenant en quoi le skip-gram est différent de CBOW.
Skip-gram : Il s’agit d’un modèle d’intégration de mots, mais il fonctionne différemment. Au lieu de prédire le mot cible, le skip-gram prédit les mots du contexte à partir des mots cibles.
Les skip-grams capturent mieux les relations sémantiques entre les mots.
Exemple : “Roi – Hommes Femmes = Reine”
Si vous souhaitez travailler avec Word2Vec, vous avez deux possibilités : soit vous entraînez votre propre modèle, soit vous utilisez un modèle pré-entraîné. Nous allons utiliser un modèle pré-entraîné.
Importez gensim
Vous pouvez installer gensim en utilisant pip install :
pip install gensimTokenisez la phrase en utilisant word_tokenize :
Tout d’abord, nous allons convertir les phrases en bas. Ensuite, nous allons tokeniser nos phrases en utilisant word_tokenize.
# Importez les bibliothèques nécessaires
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Exemple de phrases
sentences = [
"J'aime Thor",
"Hulk est un membre important des Avengers",
"Ironman aide Spiderman",
"Spiderman est l'un des membres les plus populaires des Avengers",
]
# Tokeniser les phrases
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Entraînons notre modèle:
Nous allons entraîner notre modèle en fournissant des phrases tokenisées. Nous utilisons 5 fenêtres pour ce modèle d’entraînement, vous pouvez les adapter à vos besoins.
# Entraînez un modèle Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Trouver des mots similaires
mots_similaires = model.wv.most_similar("avengers")# Imprimer les mots similaires
print("Mots similaires à 'avengers' :")
pour mot, score dans mots_similaires :
print(f"{mot} : {score}")Mots similaires à ‘avengers’ :

Voici quelques-uns des mots similaires à“avengers” d’après le modèle Word2Vec, ainsi que leur score de similarité.
Le modèle calcule un score de similar ité (principalement la similarité cosinus) entre les vecteurs de mots de “avengers” et d’autres mots de son vocabulaire. Le score de similarité indique dans quelle mesure deux mots sont étroitement liés dans l’espace vectoriel.
Ex
Ici, le mot“aide” a une similarité en cosinus de -0,005911458611011982 avec le mot“vengeurs“. La valeur négative suggère qu’ils pourraient être différents l’un de l’autre.
Les valeurs de similarité en cosinus vont de -1 à 1, où :
- 1 indique que les deux vecteurs sont identiques et présentent une similarité positive.
- Les valeurs proches de 1 indiquent une similarité positive élevée.
- Les valeurs proches de 0 indiquent que les vecteurs ne sont pas fortement liés.
- Les valeurs proches de -1 indiquent une forte dissimilarité.
- –1 indique que les deux vecteurs sont totalement opposés et ont une similarité négative parfaite.
Visitez ce lien si vous souhaitez mieux comprendre les modèles word2vec et obtenir une représentation visuelle de leur fonctionnement. C’est un outil très intéressant pour voir CBOW et skip-gram en action.
Tout comme Word2Vec, nous avons GloVe. GloVe peut produire des embeddings qui nécessitent moins de mémoire que Word2Vec. Voyons ce qu’il en est de GloVe.
GloVe
Les vecteurs globaux pour la représentation des mots (GloVe) sont une technique similaire à word2vec. Elle est utilisée pour représenter les mots sous forme de vecteurs dans un espace continu. Le concept de GloVe est le même que celui de Word2Vec : il produit des ancrages de mots contextuels tout en tenant compte des performances supérieures de Word2Vec.
Pourquoi avons-nous besoin de GloVe ?
Word2vec est une méthode basée sur les fenêtres, qui utilise les mots proches pour comprendre les mots. Cela signifie que la signification sémantique du mot cible n’est affectée que par les mots qui l’entourent dans les phrases, ce qui constitue une utilisation inefficace des statistiques.
GloVe, quant à lui, capture les statistiques globales et locales pour venir avec l’intégration des mots.
Quand utiliser GloVe ?
Utilisez GloVe lorsque vous souhaitez un ancrage des mots qui capture des relations sémantiques plus larges et des associations de mots globales.
GloVe est meilleur que d’autres modèles sur les tâches de reconnaissance d’entités nommées, d’analogie de mots et de similarité de mots.
Tout d’abord, nous devons installer Gensim :
pip install gensimEtape 1 : Nous allons installer les bibliothèques importantes
# Importez les bibliothèques nécessaires
import numpy as np
import matplotlib.pyplot en tant que plt
from sklearn.manifold import TSNE
import gensim.downloader as api Étape 2 : Importer le modèle Glove
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')Etape 3 : Récupérer la représentation vectorielle du mot ‘cute’
glove_model["cute"]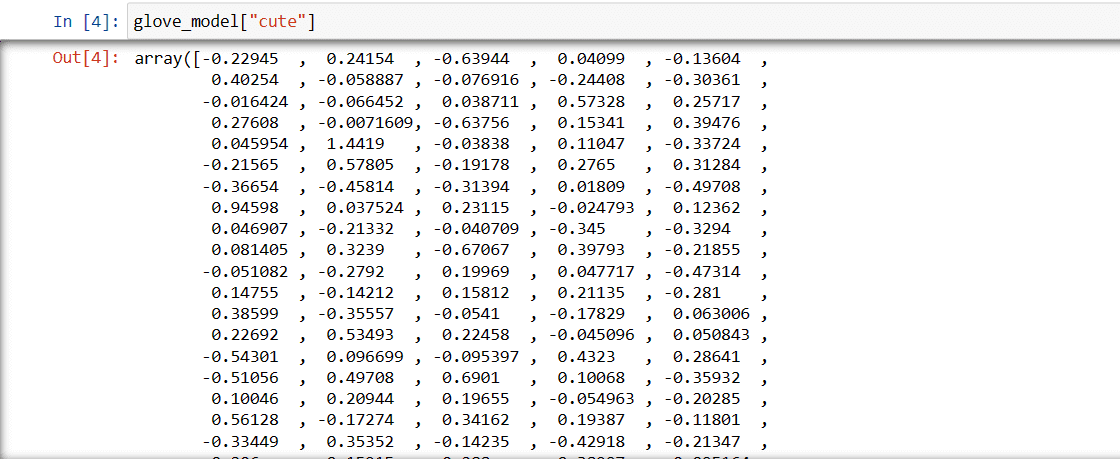
Ces valeurs capturent le sens du mot et ses relations avec d’autres mots. Les valeurs positives indiquent des associations positives avec certains concepts, tandis que les valeurs négatives indiquent des associations négatives avec d’autres concepts.
Dans un modèle GloVe, chaque dimension du vecteur de mot représente un certain aspect du sens ou du contexte du mot.
Les valeurs négatives et positives de ces dimensions contribuent à la manière dont le mot “mignon” est sémantiquement lié à d’autres mots du vocabulaire du modèle.
Les valeurs peuvent être différentes d’un modèle à l’autre. Trouvons des mots similaires au mot “garçon”
Top 10 des mots similaires qui, selon le modèle, sont les plus proches du mot “garçon
# Trouver un mot similaire
glove_model.most_similar("garçon")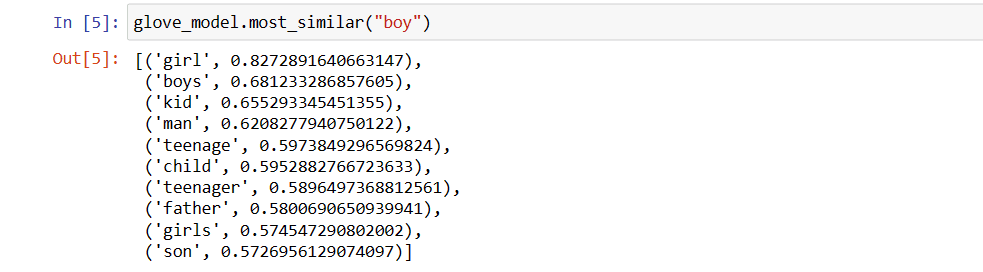
Comme vous pouvez le constater, le mot le plus similaire à “garçon” est “fille”.
Maintenant, nous allons essayer de déterminer avec quelle précision le modèle obtiendra la signification sémantique des mots fournis.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
Notre modèle est capable de trouver des relations parfaites entre les mots.
Définissez la liste de vocabulaire :
Essayons maintenant de comprendre la signification sémantique ou la relation entre les mots à l’aide d’un graphique. Définissez la liste des mots que vous souhaitez visualiser.
# Définissez la liste des mots que vous souhaitez visualiser
vocab = ["garçon", "fille", "homme", "femme", "roi", "reine", "banane", "pomme", "mangue", "vache", "noix de coco", "orange", "chat", "chien"]
Créez une matrice d’intégration :
Écrivons le code de création de la matrice d’intégration.
# Votre code pour créer la matrice d'intégration
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word : index for index, word in enumerate(vocab)}
num_mots = len(vocabulaire)
matrice_intégration = np.zeros((num_mots, EMBEDDING_DIM))
pour mot, i dans mot_index.items() :
vecteur_encastrement = modèle_gant[mot]
si embedding_vector n'est pas None :
matrice_intégration<x><x><x><x><x><x>[i]</x></x></x></x></x></x> = vecteur_intégrationDéfinissez une fonction pour la visualisation t-SNE :
A partir de ce code, nous allons définir une fonction pour notre graphique de visualisation.
def tsne_plot(embedding_matrix, words) :
tsne_model = TSNE(perplexité=3, n_composants=2, init='pca', random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[ :, 0], coordinates[ :, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words) :
plt.scatter(x<x><x><x><x><x><x>[i]</x></x></x></x></x></x>, y<x><x><x><x><x><x>[i]</x></x></x></x></x></x>)
plt.annotate(word,
xy=(x<x><x><x><x><x><x>[i]</x></x></x></x></x></x>, y<x><x><x><x><x><x>[i]</x></x></x></x></x></x>),
xytext=(2, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
Voyons à quoi ressemble notre graphique :
# Appelez la fonction tsne_plot avec votre matrice d'intégration et votre liste de mots
tsne_plot(matrice_intégration, vocabulaire)
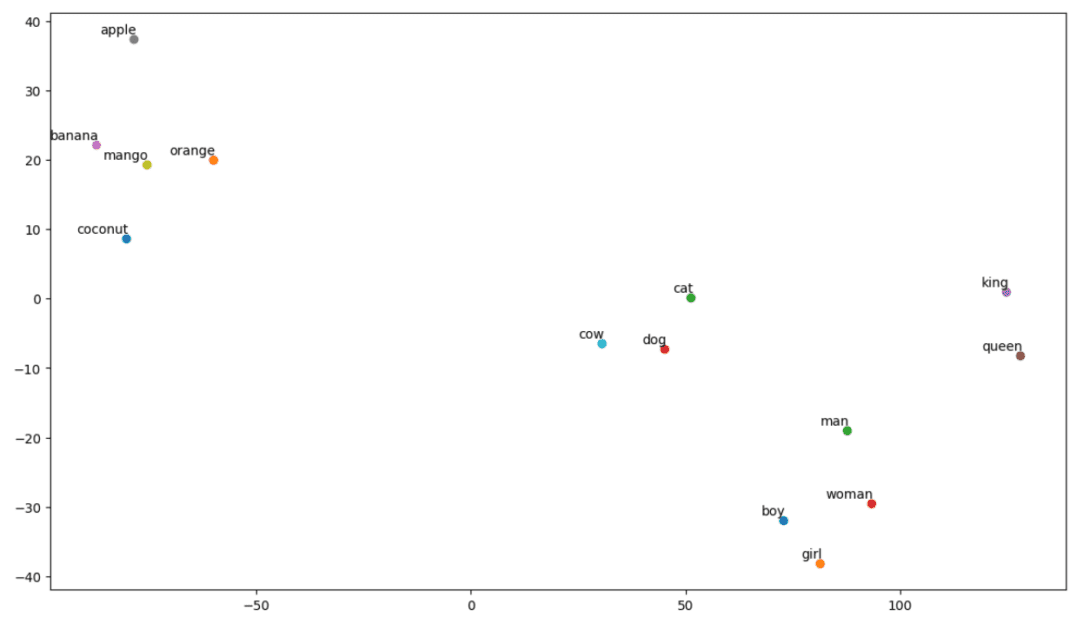
Comme nous pouvons le voir, des mots tels que “banane”, “mangue”, “orange”, “noix de coco” et “pomme” se trouvent à gauche de notre graphique. En revanche, “vache”, “chien” et “chat” sont similaires parce qu’il s’agit d’animaux.
Notre modèle peut donc également trouver une signification sémantique et des relations entre les mots !
En modifiant simplement le vocabulaire ou en créant votre modèle à partir de zéro, vous pouvez expérimenter avec différents mots.
Vous pouvez utiliser cette matrice d’intégration comme bon vous semble. Elle peut être appliquée à des tâches de similarité de mots ou être introduite dans la couche d’intégration d’un réseau neuronal.
GloVe s’entraîne sur une matrice de cooccurrence pour en déduire la signification sémantique. Il repose sur l’idée que les cooccurrences de mots sont un élément essentiel de la connaissance et que leur utilisation est un moyen efficace d’utiliser les statistiques pour produire des ancrages de mots. C’est ainsi que GloVe parvient à ajouter des “statistiques globales” au produit final.
Voilà pour GloVe ; Une autre méthode populaire de vectorisation est FastText. Nous allons en parler plus en détail.
FastText
FastText est une bibliothèque open-source introduite par l’équipe de recherche en IA de Facebook pour la classification des textes et l’analyse des sentiments. FastText fournit des outils pour la formation de word embedding, qui sont des vecteurs denses représentant les mots. Cela permet de capturer le sens sémantique du document. FastText prend en charge la classification multi-label et multi-classe.
Pourquoi FastText ?
FastText est meilleur que les autres modèles en raison de sa capacité à se généraliser aux mots inconnus, ce qui n’était pas le cas des autres méthodes. FastText fournit des vecteurs de mots pré-entraînés pour différentes langues, ce qui peut être utile dans diverses tâches où nous avons besoin de connaissances préalables sur les mots et leur signification.
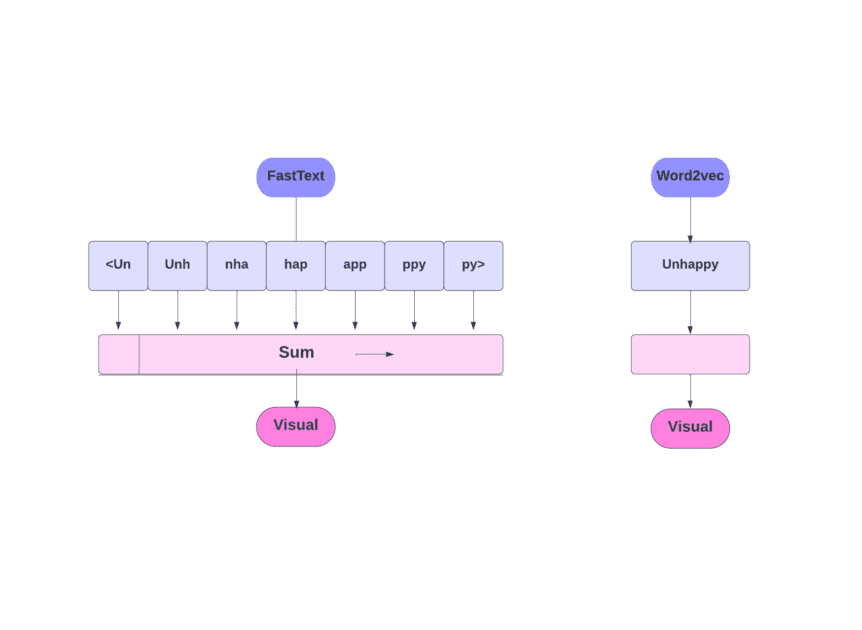
Comment fonctionne ce modèle ?
Comme nous l’avons vu, d’autres modèles, tels que Word2Vec et GloVe, utilisent des mots pour l’intégration des mots. Mais FastText se base sur des lettres plutôt que sur des mots. Cela signifie qu’ils utilisent des lettres pour l’intégration des mots.
L’utilisation de caractères au lieu de mots présente un autre avantage. Moins de données sont nécessaires pour l’apprentissage. Comme un mot devient son contexte, il est possible d’extraire davantage d’informations du texte.
L’intégration de mots obtenue via FastText est une combinaison d’intégrations de niveau inférieur.
Voyons maintenant comment FastText utilise les informations sur les sous-mots.
Supposons que nous ayons le mot “lecture”. Pour ce mot, des n-grammes de caractères de longueur 3-6 seraient générés comme suit :
- Le début et la fin sont indiqués par des crochets angulaires.
- Le hachage est utilisé parce qu’il peut y avoir un grand nombre de n-grammes ; au lieu d’apprendre un encastrement pour chaque n-gramme distinct, nous apprenons un total de B encastrements, où B représente la taille du seau. La taille de 2 millions de godets a été utilisée dans l’article original.
- Chaque n-gramme de caractère, tel que “eadi”, est associé à un nombre entier compris entre 1 et B à l’aide de cette fonction de hachage, et cet index est associé à l’intégration correspondante.
- En faisant la moyenne de ces intégrations de n-grammes constitutifs, on obtient alors l’intégration complète du mot.
- Même si cette approche de hachage entraîne des collisions, elle permet de gérer la taille du vocabulaire dans une large mesure.
- Le réseau utilisé dans FastText est similaire à Word2Vec. Comme dans ce dernier, nous pouvons entraîner FastText en deux modes – CBOW et skip-gram. Il n’est donc pas nécessaire de répéter cette partie ici.
Vous pouvez entraîner votre propre modèle ou utiliser un modèle pré-entraîné. Nous allons utiliser un modèle pré-entraîné.
Tout d’abord, vous devez installer FastText.
pip install fasttextNous allons utiliser un jeu de données qui consiste en du texte conversationnel concernant quelques médicaments, et nous devons classer ces textes en 3 types. Comme avec le type de médicaments auxquels ils sont associés.

Pour entraîner un modèle FastText sur n’importe quel jeu de données, nous devons préparer les données d’entrée dans un certain format, qui est :
__label__<valeur de l'étiquette><espace><point de données associé>
Faisons de même pour notre ensemble de données.
all_texts = train['text'].tolist()
all_labels = train['type de médicament'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)) :
sample = '__label__' str(all_labels<x><x><x><x><x><x>[i]</x></x></x></x></x></x>) ' ' all_texts<x><x><x><x><x><x>[i]</x></x></x></x></x></x>
prep_datapoints.append(sample)
Nous avons omis beaucoup de prétraitement dans cette étape. Sinon, notre article serait trop volumineux. Dans les problèmes réels, il est préférable d’effectuer un prétraitement pour que les données soient adaptées à la modélisation.
Maintenant, écrivez les points de données préparés dans un fichier .txt.
avec open('train_fasttext.txt','w') as f :
pour point de données dans prep_datapoints :
f.write(datapoint)
f.write('n')
f.close()
Entraînons notre modèle.
model = fasttext.train_supervised('train_fasttext.txt')Nous obtiendrons des prédictions de notre modèle.

Le modèle prédit l’étiquette et lui attribue un score de confiance.
Comme pour tout autre modèle, les performances de celui-ci dépendent de plusieurs variables, mais si vous souhaitez avoir une idée rapide de la précision attendue, FastText peut être une bonne option.
Conclusion
En conclusion, les méthodes de vectorisation de texte telles que Bag of Words (BoW), TF-IDF, Word2Vec, GloVe et FastText offrent de nombreuses possibilités pour les tâches de TAL.
Alors que Word2Vec capture la sémantique des mots et s’adapte à diverses tâches de TAL, BoW et TF-IDF sont simples et conviennent à la classification et à la recommandation de textes.
Pour des applications telles que l’analyse des sentiments, GloVe propose des enchâssements pré-entraînés, et FastText est efficace pour l’analyse au niveau des sous-mots, ce qui le rend utile pour les langues à structure affluente et la reconnaissance d’entités.
Le choix de la technique dépend de la tâche, des données et des ressources. Nous aborderons plus en détail les complexités du NLP au fur et à mesure de l’avancement de cette série. Bon apprentissage !
Ensuite, consultez les meilleurs cours de TAL pour apprendre le traitement du langage naturel.