L’apprentissage automatique est une innovation technologique qui continue de faire ses preuves dans de nombreux secteurs.
L’apprentissage automatique est lié à l’intelligence artificielle et à l’apprentissage profond. Comme nous vivons dans une ère technologique en constante progression, il est désormais possible de prédire ce qui va suivre et de savoir comment changer notre approche grâce au ML.
Ainsi, vous n’êtes pas limité aux méthodes manuelles ; presque toutes les tâches sont aujourd’hui automatisées. Il existe différents algorithmes d’apprentissage automatique conçus pour différents travaux. Ces algorithmes peuvent résoudre des problèmes complexes et vous faire gagner des heures de travail.
Il peut s’agir, par exemple, de jouer aux échecs, de remplir des données, d’effectuer des opérations chirurgicales, de choisir la meilleure option dans une liste de courses, et bien d’autres choses encore.
Dans cet article, j’expliquerai en détail les algorithmes et les modèles d’apprentissage automatique.
Nous y voilà !
Qu’est-ce que l’apprentissage automatique ?

L’apprentissage automatique est une compétence ou une technologie dans laquelle une machine (un ordinateur, par exemple) doit acquérir la capacité d’apprendre et de s’adapter en utilisant des modèles statistiques et des algorithmes sans être hautement programmée.
Grâce à cela, les machines se comportent de la même manière que les humains. Il s’agit d’un type d’intelligence artificielle qui permet aux applications logicielles de devenir plus précises dans leurs prédictions et dans l’exécution de différentes tâches en exploitant les données et en s’améliorant.
Les technologies informatiques évoluant rapidement, l’apprentissage automatique d’aujourd’hui n’est plus le même que celui d’hier. L’apprentissage automatique prouve son existence à partir de la reconnaissance des formes et de la théorie de l’apprentissage de certaines tâches.
Avec l’apprentissage automatique, les ordinateurs apprennent des calculs précédents pour produire des décisions et des résultats reproductibles et fiables. En d’autres termes, l’apprentissage automatique est une science qui a pris un nouvel élan.
Bien que de nombreux algorithmes soient utilisés depuis longtemps, la capacité d’appliquer automatiquement des calculs complexes à des données volumineuses, de plus en plus rapidement et de manière répétée, est un développement récent.
Voici quelques exemples rendus publics :
- Recommandations de réductions et d’offres en ligne, telles que celles de Netflix et d’Amazon
- La voiture autonome de Google, qui a fait l’objet d’un grand battage médiatique
- Détection de la fraude et proposition de solutions pour contourner ces problèmes
Et bien d’autres encore.
Pourquoi avez-vous besoin de l’apprentissage automatique ?

L’apprentissage automatique est un concept important que chaque propriétaire d’entreprise met en œuvre dans ses applications logicielles pour connaître le comportement de ses clients, les modèles opérationnels de son entreprise, et bien plus encore. Il soutient le développement des produits les plus récents.
De nombreuses entreprises de premier plan, comme Google, Uber, Instagram, Amazon, etc. font de l’apprentissage automatique la partie centrale de leurs opérations. Cependant, les industries qui travaillent sur une grande quantité de données connaissent l’importance des modèles d’apprentissage automatique.
Les organisations sont en mesure de travailler efficacement grâce à cette technologie. Des secteurs comme les services financiers, le gouvernement, les soins de santé, la vente au détail, les transports et le pétrole-gaz utilisent des modèles d’apprentissage automatique pour fournir des résultats plus précieux aux clients.
Qui utilise l’apprentissage automatique ?

L’apprentissage automatique est aujourd’hui utilisé dans de nombreuses applications. L’exemple le plus connu est le moteur de recommandation sur Instagram, Facebook, Twitter, etc.
Facebook utilise l’apprentissage automatique pour personnaliser l’expérience des membres sur leur fil d’actualité. Si un utilisateur s’arrête fréquemment pour consulter la même catégorie de posts, le moteur de recommandation commence à afficher davantage de posts de la même catégorie.
Derrière l’écran, le moteur de recommandation tente d’étudier le comportement en ligne des membres à travers leurs habitudes. Le fil d’actualité s’ajuste automatiquement lorsque l’utilisateur change d’action.
En ce qui concerne les moteurs de recommandation, de nombreuses entreprises utilisent le même concept pour gérer leurs procédures commerciales essentielles. Il s’agit de
- Logiciel de gestion de la relation client (CRM): il utilise des modèles d’apprentissage automatique pour analyser les courriels des visiteurs et inciter l’équipe de vente à répondre immédiatement et en priorité aux messages les plus importants.
- Intelligence économique (BI) : Les fournisseurs de solutions d’analyse et de BI utilisent la technologie pour identifier les points de données essentiels, les modèles et les anomalies.
- Systèmes d’information sur les ressources humaines (SIRH): Il utilise des modèles d’apprentissage automatique dans son logiciel pour filtrer ses applications et reconnaître les meilleurs candidats pour le poste requis.
- Voitures auto-conduites: Les algorithmes d’apprentissage automatique permettent aux constructeurs automobiles d’identifier l’objet ou de détecter le comportement du conducteur afin d’alerter immédiatement pour éviter les accidents.
- Assistants virtuels : Les assistants virtuels sont des assistants intelligents qui combinent des modèles supervisés et non supervisés pour interpréter la parole et fournir un contexte.
Qu’est-ce qu’un modèle d’apprentissage automatique ?

Un modèle d’apprentissage automatique est un logiciel ou une application informatique formé pour juger et reconnaître certains modèles. Vous pouvez former le modèle à l’aide de données et lui fournir l’algorithme qui lui permettra d’apprendre à partir de ces données.
Par exemple, vous souhaitez créer une application qui reconnaît les émotions en fonction des expressions faciales de l’utilisateur. Pour cela, vous devez alimenter le modèle avec différentes images de visages étiquetés avec différentes émotions et bien entraîner votre modèle. Vous pouvez maintenant utiliser le même modèle dans votre application pour déterminer facilement l’humeur de l’utilisateur.
En termes simples, un modèle d’apprentissage automatique est une représentation simplifiée d’un processus. C’est la manière la plus simple de déterminer quelque chose ou de recommander quelque chose à un consommateur. Tout dans le modèle fonctionne comme une approximation.
Par exemple, lorsque nous dessinons ou fabriquons un globe terrestre, nous lui donnons la forme d’une sphère. Mais le globe réel n’est pas sphérique comme nous le savons. Ici, nous supposons la forme pour construire quelque chose. Les modèles ML fonctionnent de la même manière.
Voyons maintenant les différents modèles et algorithmes d’apprentissage automatique.
Types de modèles d’apprentissage automatique

Tous les modèles d’apprentissage automatique sont classés en trois catégories : l’apprentissage supervisé, l’apprentissage non supervisé et l’apprentissage par renforcement. L’apprentissage supervisé et l’apprentissage non supervisé sont classés en différents termes. Discutons de chacun d’entre eux en détail.
Apprentissage supervisé
L’apprentissage supervisé est un modèle d’apprentissage automatique simple qui implique l’apprentissage d’une fonction de base. Cette fonction associe une entrée à une sortie. Par exemple, si vous disposez d’un ensemble de données composé de deux variables, l’âge en entrée et la taille en sortie.
Avec un modèle d’apprentissage supervisé, vous pouvez facilement prédire la taille d’une personne en fonction de son âge. Pour comprendre ce modèle d’apprentissage, vous devez passer en revue les sous-catégories.
#1. La classification
La classification est une tâche de modélisation prédictive largement utilisée dans le domaine de l’apprentissage automatique, qui consiste à prédire une étiquette pour des données d’entrée données. Elle nécessite un ensemble de données d’entraînement avec un large éventail d’instances d’entrées et de sorties à partir desquelles le modèle apprend.
L’ensemble de données d’apprentissage est utilisé pour trouver la manière minimale de faire correspondre les échantillons de données d’entrée aux étiquettes de classe spécifiées. Enfin, l’ensemble de données d’apprentissage représente la question qui contient un grand nombre d’échantillons de sortie.

Il est utilisé pour le filtrage des spams, la recherche de documents, la reconnaissance des caractères manuscrits, la détection des fraudes, l’identification des langues et l’analyse des sentiments. Dans ce cas, le résultat est discret.
#2. Régression
Dans ce modèle, le résultat est toujours continu. L’analyse de régression est essentiellement une approche statistique qui modélise un lien entre une ou plusieurs variables indépendantes et une variable cible ou dépendante.
La régression permet de voir comment le nombre de la variable dépendante change en fonction de la variable indépendante alors que les autres variables indépendantes sont constantes. Elle est utilisée pour prédire le salaire, l’âge, la température, le prix et d’autres données réelles.
L’analyse de régression est une méthode de “meilleure estimation” qui génère une prévision à partir d’un ensemble de données. En d’autres termes, il s’agit d’ajuster différents points de données dans un graphique afin d’obtenir la valeur la plus précise.
Exemple: Prédire le prix d’un billet d’avion est un travail de régression courant.
Apprentissage non supervisé
L’apprentissage non supervisé est essentiellement utilisé pour tirer des conclusions et trouver des modèles à partir des données d’entrée sans aucune référence aux résultats étiquetés. Cette technique est utilisée pour découvrir des groupements de données et des modèles cachés sans nécessiter d’intervention humaine.
Elle permet de découvrir des différences et des similitudes dans les informations, ce qui la rend idéale pour la segmentation de la clientèle, l’analyse exploratoire des données, la reconnaissance des formes et des images et les stratégies de vente croisée.
L’apprentissage non supervisé est également utilisé pour réduire le nombre fini de caractéristiques d’un modèle à l’aide du processus de réduction de la dimensionnalité qui comprend deux approches : la décomposition de la valeur singulière et l’analyse en composantes principales.
#1. Le regroupement
Le clustering est un modèle d’apprentissage non supervisé qui inclut le regroupement des points de données. Il est fréquemment utilisé pour la détection des fraudes, la classification des documents et la segmentation de la clientèle.

Les algorithmes de clustering ou de regroupement les plus courants sont le clustering hiérarchique, le clustering basé sur la densité, le clustering par déplacement de la moyenne et le clustering par k-moyennes. Chaque algorithme est utilisé différemment pour trouver des grappes, mais l’objectif est le même dans tous les cas.
#2. Réduction de la dimensionnalité
Il s’agit d’une méthode de réduction des diverses variables aléatoires considérées pour obtenir un ensemble de variables principales. En d’autres termes, le processus de réduction de la dimension de l’ensemble de caractéristiques est appelé réduction de la dimensionnalité. L’algorithme le plus répandu de ce modèle est l’analyse en composantes principales.
La malédiction de ce modèle fait référence au fait d’ajouter plus de données aux activités de modélisation prédictive, ce qui les rend encore plus difficiles à modéliser. Il est généralement utilisé pour la visualisation des données.
Apprentissage par renforcement
L’apprentissage par renforcement est un paradigme d’apprentissage dans lequel un agent apprend à interagir avec l’environnement et reçoit occasionnellement une récompense pour l’ensemble des actions correctes.
Le modèle d’apprentissage par renforcement apprend au fur et à mesure qu’il progresse grâce à la méthode des essais et des erreurs. La séquence de résultats positifs force le modèle à élaborer la meilleure recommandation pour un problème donné. Cette méthode est souvent utilisée dans les jeux, la navigation, la robotique, etc.
Types d’algorithmes d’apprentissage automatique

#1. Régression linéaire
Ici, l’idée est de trouver une ligne qui s’adapte le mieux possible aux données dont vous avez besoin. Il existe des extensions du modèle de régression linéaire, notamment la régression linéaire multiple et la régression polynomiale. Il s’agit de trouver le meilleur plan qui s’ajuste aux données et la meilleure courbe qui s’ajuste aux données, respectivement.
#2. Régression logistique
La régression logistique est très similaire à l’algorithme de régression linéaire, mais elle est essentiellement utilisée pour obtenir un nombre fini de résultats, disons deux. La régression logistique est utilisée en lieu et place de la régression linéaire lorsqu’il s’agit de modéliser la probabilité des résultats.
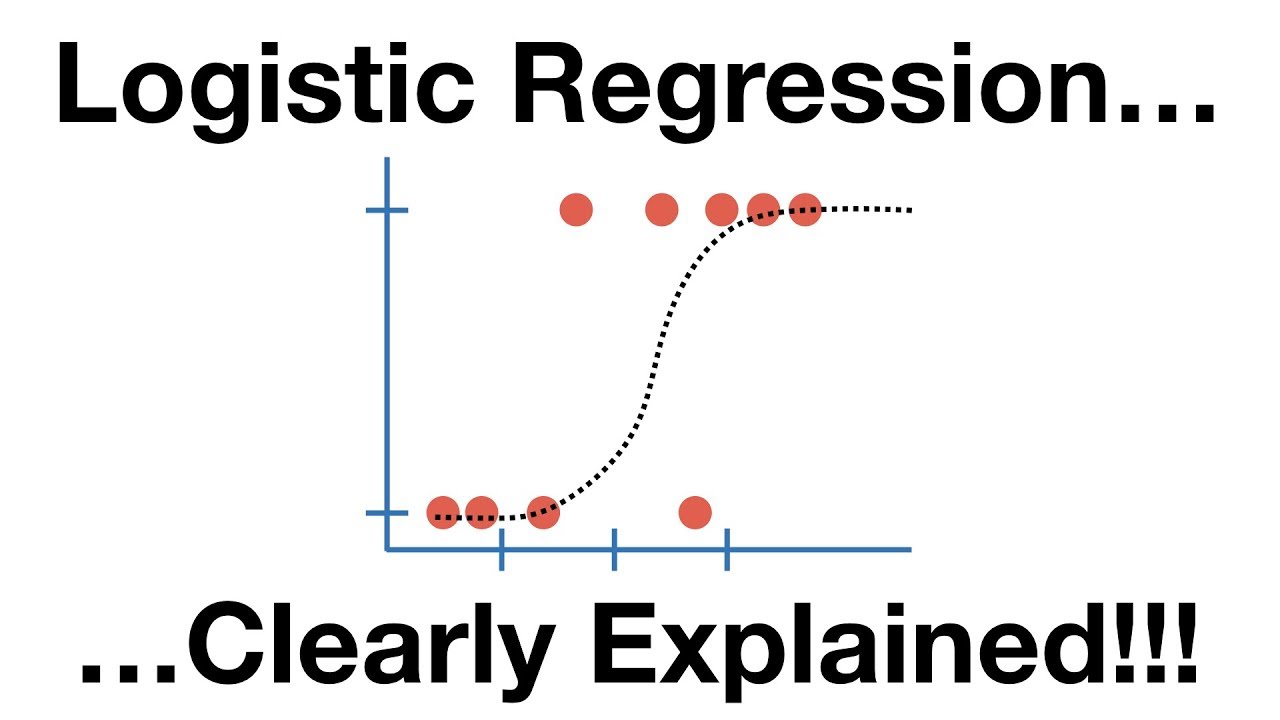
Ici, une équation logistique est construite de manière brillante afin que la variable de sortie soit comprise entre 0 et 1.
#3. Arbre de décision
Le modèle d’arbre de décision est largement utilisé dans la planification stratégique, l’apprentissage automatique et la recherche opérationnelle. Il se compose de nœuds. Si vous avez plus de nœuds, vous obtiendrez des résultats plus précis. Le dernier nœud de l’arbre de décision est constitué de données qui permettent de prendre des décisions plus rapidement.
C’est pourquoi les derniers nœuds sont également appelés les feuilles de l’arbre. Les arbres de décision sont faciles et intuitifs à construire, mais leur précision laisse à désirer.
#4. Forêt aléatoire
Il s’agit d’une technique d’apprentissage par ensemble. En termes simples, elle est construite à partir des arbres de décision. Le modèle des forêts aléatoires implique plusieurs arbres de décision en utilisant des ensembles de données bootstrappées des données réelles. Il sélectionne de manière aléatoire le sous-ensemble de variables à chaque étape de l’arbre.
Le modèle des forêts aléatoires sélectionne le mode de prédiction de chaque arbre de décision. Par conséquent, le fait de s’appuyer sur le modèle “la majorité l’emporte” réduit le risque d’erreur.
Par exemple, si vous créez un arbre de décision individuel et que le modèle prédit 0 à la fin, vous n’aurez rien. Mais si vous créez 4 arbres de décision à la fois, vous obtiendrez peut-être la valeur 1. C’est là toute la puissance du modèle d’apprentissage de la forêt aléatoire.
#5. Machine à vecteurs de support
Un Support Vector Machine (SVM) est un algorithme d’apprentissage automatique supervisé qui est compliqué mais intuitif lorsque l’on parle du niveau le plus fondamental.
Par exemple, s’il existe deux types de données ou de classes, l’algorithme SVM trouvera une frontière ou un hyperplan entre ces classes de données et maximisera la marge entre les deux. Il existe de nombreux plans ou frontières qui séparent deux classes, mais un seul plan peut maximiser la distance ou la marge entre les classes.
#6. Analyse en composantes principales (ACP)
L’analyse en composantes principales consiste à projeter des informations de dimensions supérieures, telles que 3 dimensions, dans un espace plus petit, tel que 2 dimensions. Il en résulte une dimension minimale des données. De cette façon, vous pouvez conserver les valeurs originales dans le modèle sans entraver la position, mais en réduisant les dimensions.
En d’autres termes, il s’agit d’un modèle de réduction des dimensions qui est spécialement utilisé pour ramener les multiples variables présentes dans l’ensemble des données à un minimum de variables. Cela peut se faire en regroupant les variables dont l’échelle de mesure est la même et qui présentent des corrélations plus élevées que les autres.
L’objectif principal de cet algorithme est de vous montrer les nouveaux groupes de variables et de vous donner suffisamment d’accès pour que vous puissiez effectuer votre travail.
Par exemple, l’ACP aide à interpréter les enquêtes qui comprennent de nombreuses questions ou variables, telles que les enquêtes sur le bien-être, la culture d’étude ou le comportement. Vous pouvez voir les variables minimales de ce modèle avec l’ACP.
#7. Naive Bayes
L’algorithme Naive Bayes est utilisé en science des données et est un modèle populaire utilisé dans de nombreux secteurs. L’idée est tirée du théorème de Bayes qui explique l’équation de probabilité comme “quelle est la probabilité de Q (variable de sortie) étant donné P”.
Il s’agit d’une explication mathématique utilisée dans l’ère technologique actuelle.
Par ailleurs, certains modèles mentionnés dans la partie consacrée à la régression, notamment l’arbre de décision, le réseau neuronal et la forêt aléatoire, relèvent également du modèle de classification. La seule différence entre les deux termes est que la sortie est discrète au lieu d’être continue.
#8. Réseau neuronal
Le réseau neuronal est encore une fois le modèle le plus utilisé dans l’industrie. Il s’agit essentiellement d’un réseau de diverses équations mathématiques. Il prend d’abord une ou plusieurs variables en entrée et passe par le réseau d’équations. Au final, il vous donne des résultats sous la forme d’une ou plusieurs variables de sortie.

En d’autres termes, un réseau neuronal prend un vecteur d’entrées et renvoie un vecteur de sorties. Il est similaire aux matrices en mathématiques. Il comporte des couches cachées au milieu des couches d’entrée et de sortie représentant des fonctions linéaires et d’activation.
#9. Algorithme des K-voisins les plus proches (KNN)
L’algorithme KNN est utilisé pour les problèmes de classification et de régression. Il est largement utilisé dans le secteur de la science des données pour résoudre les problèmes de classification. En outre, il stocke tous les cas disponibles et classe les cas à venir en prenant les votes de ses k voisins.
La fonction de distance effectue la mesure. Par exemple, si vous souhaitez obtenir des données sur une personne, vous devez vous adresser aux personnes les plus proches de cette personne, telles que ses amis, ses collègues, etc. L’algorithme KNN fonctionne de la même manière.
Vous devez tenir compte de trois éléments avant de choisir l’algorithme KNN.
- Les données doivent être prétraitées.
- Les variables doivent être normalisées, sinon des variables plus élevées peuvent fausser le modèle.
- Le KNN est coûteux en termes de calcul.
#10. K-Means Clustering
Il s’agit d’un modèle d’apprentissage automatique non supervisé qui résout les tâches de regroupement. Les ensembles de données sont classés et catégorisés en plusieurs grappes (disons K) de sorte que tous les points d’une grappe sont hétérogènes et homogènes par rapport aux données.
Les K-Means forment des grappes de cette manière :
- Les K-Means sélectionnent le nombre K de points de données, appelés centroïdes, pour chaque grappe.
- Chaque point de données forme une grappe avec la grappe la plus proche (centroïdes), c’est-à-dire K grappes.
- De nouveaux centroïdes sont ainsi créés.
- La distance la plus proche pour chaque point est alors déterminée. Ce processus se répète jusqu’à ce que les centroïdes ne changent plus.
Conclusion
Les modèles et algorithmes d’apprentissage automatique sont très décisifs pour les processus critiques. Ces algorithmes facilitent et simplifient notre vie quotidienne. Ainsi, il devient plus facile de mettre en œuvre les processus les plus gigantesques en quelques secondes.
Ainsi, la ML est un outil puissant que de nombreuses industries utilisent aujourd’hui, et sa demande ne cesse de croître. Et le jour n’est pas loin où nous pourrons obtenir des réponses encore plus précises à nos problèmes complexes.