
Google Search Console, ou GSC, est une arme puissante dans les mains des SEO specialists🧑💻 pour interpréter les performances d’un site web.
L’introduction de REGEX a amélioré la façon d’obtenir des informations utiles à partir du contenu et, en même temps, de générer de nouvelles idées de création.
La fonction REGEX était très attendue dans le domaine de l’analyse web. Elle a permis de filtrer des éléments particuliers à partir de n’importe quelle URL, ce qui était autrement difficile, voire impossible.
Ici, j’attire votre attention sur les trucs et astuces pour utiliser REGEX sur Google Search Console. Vous découvrirez également les différents ensembles d’opérateurs à utiliser en combinaison avec les codes REGEX pour obtenir l’interprétation souhaitée.
REGEX ou expression régulière : Vue d’ensemble

Google Search Console est un service entièrement gratuit proposé aux webmasters dans le but de gérer les performances de leur site web. Il fournit des rapports détaillés sur le taux de clics, les impressions, clicks🖱️ et le classement des mots-clés d’un site web, ce qui permet de comprendre le succès des campagnes de référencement.
Toutefois, le filtrage du taux de réussite d’une URL présentait des limites. Le SGC permet d’exporter un maximum de 1000 lignes pour l’analyse. Il n’était possible de filtrer que des sections spécifiques d’une URL, telles que la définition du chemin, la propriété du domaine ou les préfixes, alors que les chaînes complexes et les variations étaient absentes.
L’expression régulière ou Regex est un ajout efficace au GSC. L’objectif est de fournir un système permettant aux experts en référencement d’ utiliser le GSC pour obtenir davantage d’informations sur le fonctionnement et les performances d’un site web.
Regex permet de trouver des détails critiques sur le référencement d’un site web en appliquant ces codes sur les pages ou les filtres de requête. Les codes sont constitués de métacaractères entourant une chaîne de caractères liée au paramètre de filtrage. Lorsque vous saisissez la Regex sur le panneau, il affiche le résultat, que vous pouvez sauvegarder pour référence.
Avantages de l’utilisation de Regex sur GSC
Le but de travailler sur Google Search Console est d’analyser le site web d’un point de vue technique. L’équipe SEO travaille avec de nombreux outils et techniques de ce type pour une stratégie d’optimisation grâce à laquelle le site web se positionne en bonne place📈 sur les moteurs de recherche et génère du trafic.
Regex fournit un avantage supplémentaire en facilitant le processus de collecte de données utiles, qui peuvent être utilisées ultérieurement pour améliorer les plans d’optimisation. Voici ce que vous pouvez interpréter avec le rapport Regex.
en utilisant les codes Regex sur les requêtes, vous pouvez connaître le volume de recherches sur des mots-clés/expressions spécifiques. Cela vous aidera à créer de nouvelles idées de contenu pour votre blog et à générer plus de trafic.
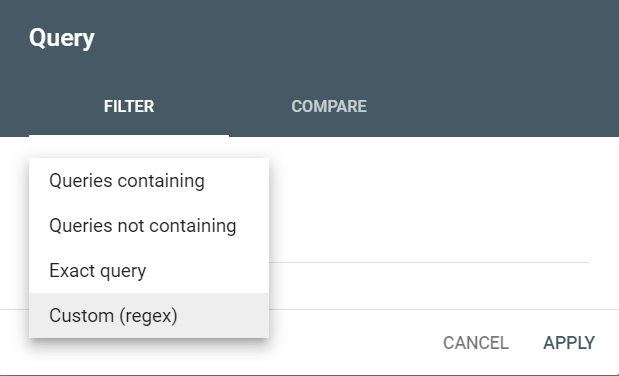
✨ Les codes Regex font gagner beaucoup de temps aux référenceurs qui travaillent dans de grandes entreprises et traitent d’énormes volumes de données web. Il suffit de quelques métacaractères et chaînes de caractères dans la bonne syntaxe pour trier des requêtes ou des pages en fonction d’exigences particulières.
l’un de ses principaux avantages est de travailler sur une combinaison typique de mots, de phrases et d’URL. Ces caractères doivent être placés dans la bonne séquence pour former un code Regex exploitable.
✨ Il ne fait aucun doute qu’il fournit de meilleures informations sur votre site web, notamment sur les pages les plus performantes et les moins performantes, ainsi que sur les tendances.
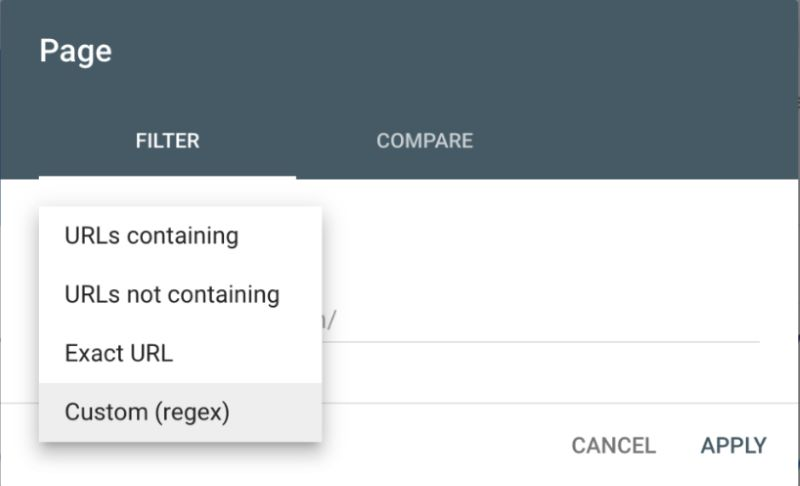
✨ Vous pouvez appliquer les codes Regex à des rapports personnalisés pour suivre le flux de trafic sur les pages web pour des requêtes particulières. Par la suite, vous pouvez demander à l’équipe de travailler en conséquence dans une direction spécifique.
Vous pouvez définir plusieurs combinaisons de caractères Regex pour définir un code et l’utiliser pour interpréter une solution d’optimisation de votre site web.
Où appliquer la fonction Regex dans Google Search Console ?
Pour utiliser la fonction Regex sur GSC, vous devez d’abord avoir accès à la propriété de votre site web. Il s’agit d’une condition impérative car vous ne pourrez pas l’attacher comme votre propriété sur Google Search Console pour toute autre procédure d’analyse.

Vous devez vous connecter à Google Search Console avec votre identifiant Gmail et commencer par ajouter la propriété à partir de l’option proposée dans la barre latérale. La propriété est le site web que vous possédez ou auquel vous avez l’autorisation d’accéder dans la console.

Une fois que vous avez ajouté le site Web ou toute URL dans l’option donnée, le panneau vous demandera de le vérifier✅. La procédure de vérification est répertoriée dans la colonne, et une fois qu’il est fait, vous pouvez sélectionner votre propriété pour les procédures ultérieures.
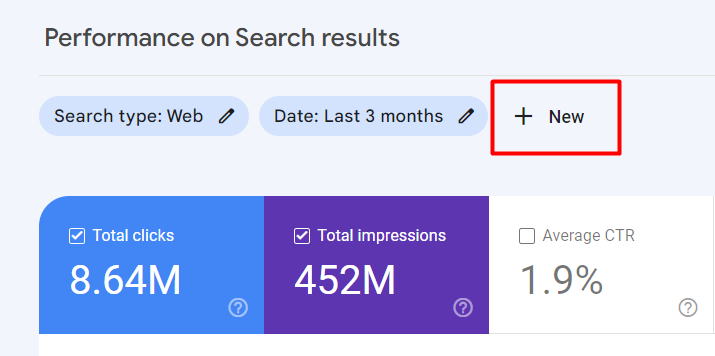
Sous le nom de la propriété listée, cliquez sur le paramètre “Performance” et appuyez sur le bouton “Nouveau” au-dessus du graphique pour les options de filtrage.
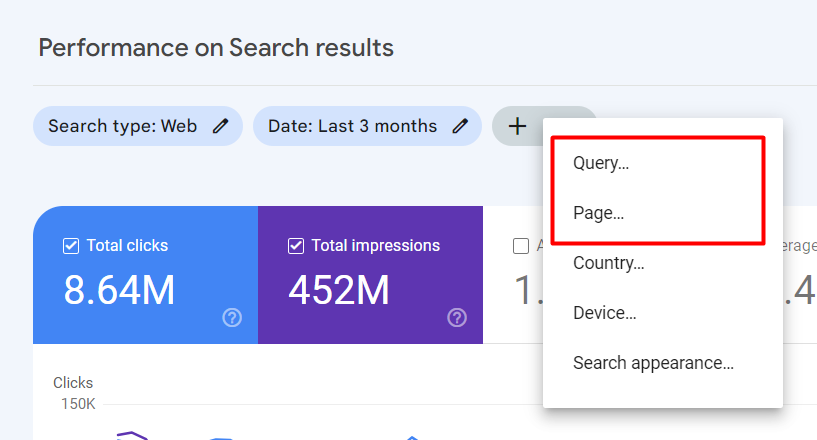
Vous pouvez choisir Query ou Pages pour utiliser le code Regex pour filtrer les résultats.
Explication des caractères Regex
Il existe plusieurs jeux de caractères utilisés comme Regex pour filtrer les requêtes et les pages dans Google Search Console. Chaque métacaractère a une signification différente pour le filtre. Si vous les comprenez bien, il ne sera pas difficile d’effectuer une analyse sur GSC à l’aide de Regex.
Dans le tableau ci-dessous, j’ai expliqué certains symboles et caractères utilisés dans le code Regex avec un exemple approprié.
| Caractères | Utilisation |
|---|---|
| () | Ces parenthèses sont utilisées pour regrouper des caractères ou des expressions, également connus sous le nom de groupes de capture. |
| (Geek) | Vous obtiendrez toutes les pages web contenant le mot “Mobile” au début du titre ou de la balise. [^\mobile] Si la barre oblique inverse suit le caret, cela filtrera les URLs avec le mot mobile donné. |
| | | Il s’agit d’un symbole OR utilisé simplement pour appliquer des choix dans le code. |
| Mobile|PC | Le rapport recherchera toutes les pages contenant l’un des deux mots. |
| ^ | Le symbole de la caret ne correspondra qu’au mot ou à l’expression au début d’une chaîne. |
| ^Mobile | Vous obtiendrez toutes les pages web contenant le mot “Mobile” au début du titre ou de la balise. [Si la barre oblique inverse suit la barre oblique, elle filtrera les URL contenant le mot “mobile”. |
| $ | Le symbole du dollar ne correspond qu’au mot ou à l’expression à la fin d’une chaîne. |
| Mobile$ | Vous obtiendrez toutes les pages web contenant le mot “Mobile” au début du titre ou de la balise. [^\mobile] Si la barre oblique inverse suit le curseur, cela filtrera les URL contenant le mot “mobile”. |
| . | Le symbole du point est utilisé pour faire correspondre un seul caractère dans une chaîne. |
| à. | Vous obtiendrez toutes les pages web contenant le mot “Mobile” à la fin du titre ou de la balise. |
| \ | La barre oblique inverse est utilisée pour ignorer le sens littéral des caractères. |
| \d | Cette option permet de trouver les pages contenant les chiffres 0 à 9. |
| Ce code RegEx correspondra à la requête contenant un ou tous les caractères suivants entre crochets : x, y ou z. | |
| Mobile | Ce code correspondra aux pages contenant tous les mots d’une combinaison de mobile avec x, y ou z, comme mobilex, mobilezy et mobilezxy. |
| [c-m] | Ce code RegEx correspondra à la requête avec toute lettre minuscule ou majuscule comprise entre c et m. |
| Mobile[c-m] | Ce code correspondra aux pages contenant tous les mots d’une combinaison de mobile avec des lettres comprises entre c et m ; par exemple, mobilecjg, mobileeel, mobilecdf. |
| [3-7] | Ce code RegEx correspondra à la requête avec des nombres compris entre 3 et 7. |
| Mobile[0-9] | Ce code correspondra aux pages contenant tous les mots de la combinaison mobile et des nombres compris entre 3 et 7 ; par exemple, mobile73, mobile654, mobile445. |
| [\w] | Ce code correspondra à tous les mots des pages web contenant les lettres “to”, comme towards, into, to. |
| [\w]*Mobile[\w] | Barre oblique inverse suivie de la lettre “w” en minuscule à l’intérieur de la parenthèse. Cela correspond à n’importe quel mot ou caractère, comme une lettre (minuscule ou majuscule), un chiffre ou un trait de soulignement. |
| [\W] | Ce code Regex correspondra aux pages contenant le mot “mobile” avec d’autres mots, que ce soit dans le titre, les méta ou l’article, tels que téléphone mobile, application mobile |
| [\W]*Mobile[\W] | Barre oblique inverse suivie de la lettre “W” en majuscule à l’intérieur de la parenthèse. Ce mot correspond à tout ce qui n’est pas une lettre ou un chiffre. Il s’agit des caractères d’espacement et des symboles tels que ; ?:#@$%. |
Vous pouvez créer plusieurs codes avec ces caractères pour filtrer des requêtes complexes sur GSC.
Regex spécifiques sur Google Search Console
Vous pouvez utiliser les métacaractères de Google Search Console pour créer des modèles ou des codes uniques à des fins spécifiques. En voici quelques-uns, que vous pouvez essayer sur votre portail GSC.
🔶 ^[\W\s\S]{70,}$
Séquentiellement, le code correspondra à tous les mots, chiffres, caractères non verbaux ou spéciaux, symboles, espaces blancs, lignes non blanches ou nouvelles lignes de la page. Le quantificateur “70” signifie que la chaîne est longue ou qu’elle comporte au moins 70 caractères.
Exemple : Ces types de codes sont applicables à la vérification des mots de passe, au tri des listes de produits avec une description élaborée, ou ailleurs.
🔶 (\w \s){6,}\w
Ce code Regex comporte trois sections. Il vise à faire correspondre des mots et des nombres séparés par des espaces. Par conséquent, le code récupère les chaînes d’au moins 6 mots ou plus, comme dans la phrase suivante : “Les chaînes d’au moins 6 mots ou plus”
Exemple : Ces codes sont applicables pour filtrer les articles dont les titres sont plus longs, les commentaires sur les médias sociaux plus longs, etc.
🔶 ^(qui|quoi|où|quand|pourquoi|comment)[” “]
Ce code Regex est simple et assez bénéfique pour les blogueurs et les experts en référencement. Il est facile de comprendre qu’il correspondra à toutes les requêtes sur les moteurs de recherche qui commencent par l’un de ces mots ; qui, ou quoi, ou où, et d’autres entre parenthèses. La chaîne de caractères doit commencer par l’un de ces mots, suivi d’un espace. Par conséquent, la recherche ne portera pas sur des mots tels que “cependant”, “entier”, etc.
Exemple : Ces codes permettent de comprendre les tendances du marché et les discussions des utilisateurs afin d’obtenir de nouvelles idées de contenu.
🔶 “qui|quoi|où|quand|pourquoi|comment”
Il est similaire au code Regex discuté ci-dessus, mais ici, la fonction correspondra à toutes les chaînes qui contiennent l’un de ces mots, indépendamment du fait que la chaîne commence par ces mots ou non.
Exemple : Ce code convient pour mettre en évidence les déclarations douteuses, filtrer les entrées utilisateur, etc.
🔶 .*
Le métacaractère point suivi d’un astérisque est souvent appelé expression générique, car vous pouvez l’utiliser pour faire correspondre n’importe quelle chaîne spécifique en la plaçant sous ce code.
Exemple : L’expression rationnelle .*Android.* permet de rechercher toutes les pages de votre site qui contiennent le mot Android. En utilisant directement le code .* sur le filtre, il extraira toutes les pages apparaissant sur le moteur de recherche au cours d’un mois.
🔶 [^\/\.\-:0-9A-Za-z_]
Le symbole de la caret est suivi d’une barre oblique inverse qui exclut les caractères indiqués dans le code. Ici, le code correspondra aux chaînes qui ne contiennent pas de barre oblique, de chiffres, de point, de deux-points, de trait d’union et tous les alphabets en majuscules et en minuscules.
Exemple : Par conséquent, le code s’applique à la capture des URL, des méta-descriptions ou du contenu qui comporte des caractères spéciaux comme &%$@.
🔶 ?i)(((is|are).(brand|site|company)|(brand|site|company).(is|are)).*(scum|reliable))
Il s’agit d’un long code Regex avec des sections spécifiques. Le caractère “?i” utilisé au début du code correspond à un indicateur insensible à la casse. Cela signifie que le code correspondra aux chaînes de caractères, qu’elles soient en majuscules ou en minuscules. Les parenthèses qui suivent contiennent des mots séparés par des caractères de type pipe (OR).
Le code Regex détectera les requêtes indépendamment de la casse des lettres impliquées, qui comprennent les mots is ou are, brand, company ou site, ainsi que scum ou reliable.
Exemple : Ce code Regex peut être utilisé avec précaution pour trouver le modèle des requêtes des clients. Vous pourrez ainsi savoir si votre site web fait l’objet d’avis positifs ou négatifs.
🔶 (kwd1|kwd2).*
Il s’agit d’une utilisation simplifiée du code regex de disjonction dans lequel le SGC filtrera les pages ou les requêtes contenant le mot kwd1 ou kwd2, suivi d’une autre lettre ou d’un autre chiffre.
Exemple : Vous pouvez utiliser ce modèle pour extraire les pages de votre site web dont l’URL, le titre, les méta ou le contenu contiennent l’un de ces mots associé à d’autres mots ou chiffres.
🔶 (Mot-clé1 ET Mot-clé2)
Ce code est un exemple clair d’expression de conjonction. “AND” est un opérateur utilisé dans le code Regex. Il est utilisé pour obtenir les pages qui ont ces deux mots donnés dans la même séquence.
Exemple : Vous pouvez appliquer le code sur GSC pour obtenir des pages, des titres ou des méta contenant deux mots spécifiques dans le même ordre.
🔶 “mot-clé1 mot-clé2”
Ce code permet de faire correspondre une phrase ou un ordre exact de mots sur la page web.
Exemple : Appliquez le code sur GSC pour trouver les pages dont le titre, la description ou le contenu contient une expression spécifique.
🔶 (Mot-clé1 | Mot-clé2)
Ce code se compose de deux mots et d’un caractère “pipe”. Il signifie que le SGC affichera les pages de votre site web qui contiennent soit le “Mot-clé1”, soit le “Mot-clé2”, mais pas les deux.
Exemple : Appliquez le code pour extraire les pages de votre site web qui contiennent l’un des deux mots ou plus séparés par le caractère “pipe”.
🔶 (Mot-clé1)\b(Mot-clé2)\b
Ce code Regex contient deux mots spécifiques avec le caractère “\b” qui est un symbole de limite de mot. Il fournira des pages contenant ces deux mots et aucun autre mot, chiffre ou caractère entre eux.
Exemple : Utilisez ce code dans votre filtre GSC pour connaître les pages qui contiennent deux mots distincts à la suite.
🔶 (Mot-clé1)\w (Mot-clé2)
Le code inclut deux mots avec le métacaractère “\w ” entre les deux, où “w” est en minuscule. Par conséquent, il recherchera toutes les pages qui contiennent ces deux mots, que ce soit dans le titre, la description ou le contenu, quel que soit le nombre de mots entre les deux.
Exemple : Vous pouvez appliquer ce code pour extraire toutes les pages de votre site web qui contiennent au moins ces deux mots n’importe où dans le titre, le contenu ou les méta.
🔶 (Mot-clé)\bphrase
Il s’agit d’un simple code Regex qui correspond à la chaîne contenant le mot entre parenthèses suivi du mot phrase. Le métacaractère “\b” signifie la limite du mot ou l’absence de tout autre caractère entre les mots donnés.
Exemple : Ce code Regex sur votre SGC vous fournira les pages qui contiennent les mots donnés en série n’importe où dans l’article, comme “phrase de mot-clé”
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j-url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Ce code Regex énumère plusieurs URL “a,b,c,e,g…..” séparées par le caractère pipe. Il filtrera donc les chaînes contenant l’une de ces URL.
Exemple : Vous pouvez appliquer de tels motifs à votre tableau de bord GSC pour obtenir des pages web dont le titre ou l’article contient des URL spécifiques.
🔶 ^(pomme|ball|cat|ferme de canards)$
Le code donné implique de faire correspondre le début d’une chaîne avec l’un de ces mots, “apple, ball, cat, or duck farm” parce que le caractère pipe les sépare. Il garantit également qu’il n’y a pas d’autre mot ou caractère.
Exemple : Vous pouvez utiliser le code pour obtenir des détails sur les pages qui contiennent des mots-clés spécifiques au début.
🔶 .*\/$
Le code Regex donné vise à capturer chaque chaîne, qu’il s’agisse de mots ou de chiffres, mais elle doit se terminer par une barre oblique.
Exemple : Vous pouvez l’utiliser pour rechercher les pages dont l’URL se termine par une barre oblique.
🔶 .(best|top|vs|review).*
Ce code correspondra aux chaînes de caractères qui ont un point au début, un des mots donnés (séparés par un caractère pipe) et d’autres mots, nombres ou caractères spéciaux à la suite.
Exemple : Vous pouvez utiliser de tels modèles de Regex dans des rapports commerciaux pour comprendre les tendances du marché.
🔶 (buy|cheap|price|purchase|order).
Ce code correspondra aux chaînes dont l’un des mots donnés est séparé par un caractère pipe et suivi d’autres mots, chiffres ou caractères.
Exemple : Ces codes sont utiles pour faire correspondre des recherches transactionnelles ou des requêtes liées aux produits de votre site web.
🔶 (face(b|be)ook) 🔶 (f( a|e)ce(b|be)ook 🔶 ( fa(c|s)(e|i)book)
Ces codes contiennent une combinaison de mots entre parenthèses ainsi que des caractères pipe entre eux.
La première expression rationnelle correspondra aux chaînes de caractères contenant le mot “face” suivi de “b” ou “be” et se terminant par “ook”. Ainsi, les pages extraites contiendront le mot “facebook” ou “facebeook”.
La seconde Regex correspondra aux chaînes contenant le mot “f” suivi de “a” ou “e” suivi de “ce” suivi de “b” ou “be” et se terminant par “ook”. Ainsi, les pages extraites présenteront n’importe quelle combinaison, telle que facebook, fecebook, facebeook ou fecebeook.
La troisième regex correspondra aux chaînes contenant le mot “fa” suivi de “c” ou “s” suivi de “e” ou “I” et se terminant par “book”. Ainsi, les pages recherchées auront n’importe quelle combinaison, comme facebook, facibook, fasebook, ou fasibook.
Exemple : Vous pouvez utiliser ce type de code pour repérer d’éventuelles fautes d’orthographe dans vos pages web.
🔶 .wp-.
Le code donné correspondra aux chaînes contenant un point suivi de “wp-” et d’autres caractères.
Exemple : Ce code permet d’extraire les pages dont l’URL est WordPress.
🔶 .*/url-1/.* vs .*/url-2/.*
Le code donné contient deux URL différentes avec un caractère Regex de comparaison. Il va chercher deux URLs spécifiques de votre site web pour comparer leurs métriques.
Exemple : Vous pouvez appliquer ce code pour comparer le trafic, le nombre d’utilisateurs et d’autres progrès entre deux pages web spécifiques de votre site.
Autres expressions rationnelles peu courantes
🔺 (?i)\bkeyword\b
Ce code correspondra à une chaîne contenant le mot “mot-clé” La recherche ne tient pas compte de la sensibilité à la casse du mot dans les pages web.
🔺 “phrase”
Ce code recherchera simplement les pages contenant le mot “phrase”.
🔺 \w{5}
Ce code correspondra aux requêtes contenant des caractères de 5 mots.
🔺 \d{3}
Ce code correspond aux requêtes comportant exactement 3 chiffres.
🔺 ([^” “]*)
Ce code Regex correspond aux chaînes de caractères qui ne contiennent aucun caractère entre guillemets.
🔺 (?i)\b(mot-clé1|mot-clé2|mot-clé3)\b
Ce code correspondra aux chaînes dont l’un des mots est séparé par un caractère pipe et qui sont en majuscules ou en minuscules.
🔺 \W
Le code correspondra à n’importe quel nombre de caractères autres que des mots, généralement des caractères spéciaux.
🔺 \d{3 ,5}
Le code correspondra à toutes les chaînes dont les numéros sont composés de 3 chiffres et de 5 chiffres au maximum.
🔺 \b\w \b
Le code correspondra à n’importe quel nombre de caractères de mots avec des limites de mots.
Derniers mots
Le moteur de recherche de Google est devenu une source d’informations précieuses après l’introduction des codes Regex dans les filtres de performance. Il suffit de comprendre la structure des codes pour extraire les rapports analytiques.
Vous pouvez créer plusieurs codes Regex sur votre panel pour obtenir des détails particuliers sur les performances de votre site web et les utiliser pour améliorer les résultats.
Ensuite, consultez les astuces de recherche de Google pour vous aider à améliorer vos recherches en ligne.