La régression et la classification sont deux des domaines les plus fondamentaux et les plus importants de l’apprentissage automatique.
Il peut être difficile de faire la distinction entre les algorithmes de régression et de classification lorsque vous débutez dans l’apprentissage automatique. Comprendre le fonctionnement de ces algorithmes et savoir quand les utiliser peut s’avérer crucial pour faire des prédictions précises et prendre des décisions efficaces.
Tout d’abord, voyons ce qu’est l’apprentissage automatique.
Qu’est-ce que l’apprentissage automatique ?

L’apprentissage automatique est une méthode qui permet aux ordinateurs d’apprendre et de prendre des décisions sans être explicitement programmés. Il s’agit d’entraîner un modèle informatique sur un ensemble de données, ce qui permet au modèle de faire des prédictions ou de prendre des décisions sur la base de modèles et de relations dans les données.
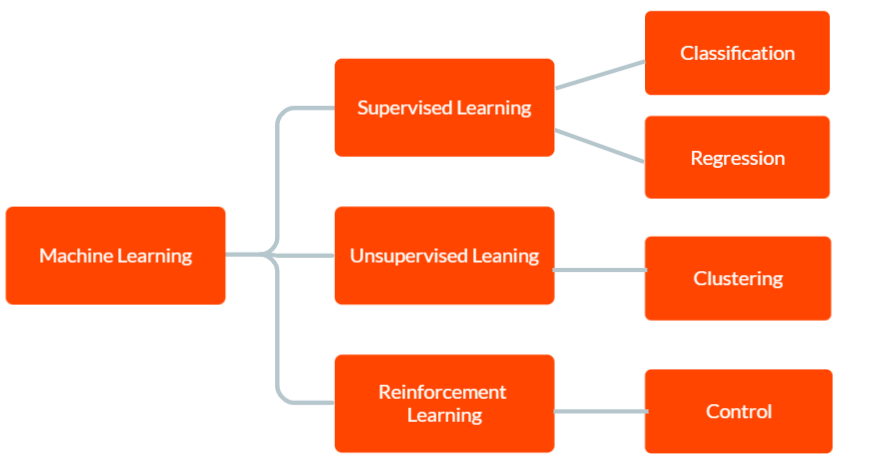
Il existe trois principaux types d’apprentissage automatique : l’apprentissage supervisé, l’apprentissage non supervisé et l’apprentissage par renforcement.
Dans l’apprentissage supervisé, le modèle reçoit des données d’apprentissage étiquetées, y compris des données d’entrée et les résultats corrects correspondants. L’objectif est de permettre au modèle de faire des prédictions sur la sortie pour de nouvelles données inédites en se basant sur les modèles qu’il a appris à partir des données d’apprentissage.
Dans l’apprentissage non supervisé, le modèle ne reçoit pas de données de formation étiquetées. Au lieu de cela, il est laissé libre de découvrir des modèles et des relations dans les données de manière indépendante. Cette méthode peut être utilisée pour identifier des groupes ou des grappes dans les données ou pour trouver des anomalies ou des modèles inhabituels.
Dans l’apprentissage par renforcement, un agent apprend à interagir avec son environnement pour maximiser une récompense. Il s’agit d’entraîner un modèle à prendre des décisions sur la base des informations qu’il reçoit de l’environnement.
L’apprentissage automatique est utilisé dans diverses applications, notamment la reconnaissance d’images et de la parole, le traitement du langage naturel, la détection des fraudes et les voitures autonomes. Il a le potentiel d’automatiser de nombreuses tâches et d’améliorer la prise de décision dans divers secteurs.
Cet article se concentre principalement sur les concepts de classification et de régression, qui relèvent de l’apprentissage automatique supervisé. Commençons par le commencement !
La classification dans l’apprentissage automatique

La classification est une technique d’apprentissage automatique qui consiste à entraîner un modèle à attribuer une étiquette de classe à une entrée donnée. Il s’agit d’une tâche d’apprentissage supervisé, ce qui signifie que le modèle est formé sur un ensemble de données étiquetées qui comprend des exemples de données d’entrée et les étiquettes de classe correspondantes.
Le modèle vise à apprendre la relation entre les données d’entrée et les étiquettes de classe afin de prédire l’étiquette de classe pour de nouvelles entrées inédites.
De nombreux algorithmes différents peuvent être utilisés pour la classification, notamment la régression logistique, les arbres de décision et les machines à vecteurs de support. Le choix de l’algorithme dépend des caractéristiques des données et des performances souhaitées pour le modèle.
Parmi les applications de classification les plus courantes, citons la détection des spams, l’analyse des sentiments et la détection des fraudes. Dans chacun de ces cas, les données d’entrée peuvent comprendre du texte, des valeurs numériques ou une combinaison des deux. Les étiquettes de classe peuvent être binaires (par exemple, spam ou non spam) ou multi-classes (par exemple, sentiment positif, neutre ou négatif).
Prenons l’exemple d’un ensemble de données d’avis de clients sur un produit. Les données d’entrée peuvent être le texte de l’avis et l’étiquette de classe peut être une note (par exemple, positive, neutre, négative). Le modèle serait formé sur un ensemble de données d’avis étiquetés et serait ensuite capable de prédire l’évaluation d’un nouvel avis qu’il n’aurait pas vu auparavant.
Types d’algorithmes de classification ML
Il existe plusieurs types d’algorithmes de classification en apprentissage automatique :
Régression logistique
Il s’agit d’un modèle linéaire utilisé pour la classification binaire. Il est utilisé pour prédire la probabilité qu’un certain événement se produise. L’objectif de la régression logistique est de trouver les meilleurs coefficients (poids) qui minimisent l’erreur entre la probabilité prédite et le résultat observé.
Pour ce faire, un algorithme d’optimisation, tel que la descente de gradient, est utilisé pour ajuster les coefficients jusqu’à ce que le modèle s’adapte le mieux possible aux données d’apprentissage.
Arbres de décision
Il s’agit de modèles arborescents qui prennent des décisions en fonction des valeurs des caractéristiques. Ils peuvent être utilisés pour la classification binaire et multi-classes. Les arbres de décision présentent plusieurs avantages, notamment leur simplicité et leur interopérabilité.
Ils sont également rapides à former et à faire des prédictions, et ils peuvent traiter à la fois des données numériques et catégorielles. Toutefois, ils peuvent être sujets à un surajustement, en particulier si l’arbre est profond et comporte de nombreuses branches.
Classification par forêt aléatoire
La classification par forêt aléatoire est une méthode d’ensemble qui combine les prédictions de plusieurs arbres de décision pour obtenir une prédiction plus précise et plus stable. Elle est moins sujette à l’overfitting qu’un arbre de décision unique car les prédictions des arbres individuels sont moyennées, ce qui réduit la variance dans le modèle.
AdaBoost
Il s’agit d’un algorithme de renforcement qui modifie de manière adaptative le poids des exemples mal classés dans l’ensemble d’apprentissage. Il est souvent utilisé pour la classification binaire.

Naïve Bayes
Naïve Bayes est basé sur le théorème de Bayes, qui permet de mettre à jour la probabilité d’un événement en fonction de nouvelles preuves. Il s’agit d’un classificateur probabiliste souvent utilisé pour la classification de textes et le filtrage de spam.
K-Voisins les plus proches
Les K-voisins les plus proches (KNN) sont utilisés pour les tâches de classification et de régression. Il s’agit d’une méthode non paramétrique qui classe un point de données en fonction de la classe de ses plus proches voisins. La méthode KNN présente plusieurs avantages, notamment sa simplicité et le fait qu’elle est facile à mettre en œuvre. Il peut également traiter des données numériques et catégorielles et ne fait aucune hypothèse sur la distribution sous-jacente des données.
Renforcement du gradient
Il s’agit d’ensembles d’apprenants faibles formés de manière séquentielle, chaque modèle essayant de corriger les erreurs du modèle précédent. Ils peuvent être utilisés pour la classification et la régression.
Régression dans l’apprentissage automatique

Dans l’apprentissage automatique, la régression est un type d’apprentissage supervisé dont l’objectif est de prédire une variable dépendante c sur la base d’une ou plusieurs caractéristiques d’entrée (également appelées prédicteurs ou variables indépendantes).
Les algorithmes de régression sont utilisés pour modéliser la relation entre les entrées et les sorties et faire des prédictions basées sur cette relation. La régression peut être utilisée pour des variables dépendantes continues ou catégorielles.
En général, l’objectif de la régression est de construire un modèle qui peut prédire avec précision la sortie sur la base des caractéristiques d’entrée et de comprendre la relation sous-jacente entre les caractéristiques d’entrée et la sortie.
L’analyse de régression est utilisée dans divers domaines, notamment l’économie, la finance, le marketing et la psychologie, pour comprendre et prédire les relations entre différentes variables. Il s’agit d’un outil fondamental dans l’analyse des données et l’apprentissage automatique, qui permet de faire des prédictions, d’identifier des tendances et de comprendre les mécanismes sous-jacents qui régissent les données.
Par exemple, dans un modèle de régression linéaire simple, l’objectif peut être de prédire le prix d’une maison en fonction de sa taille, de son emplacement et d’autres caractéristiques. La taille de la maison et son emplacement seraient les variables indépendantes, et le prix de la maison serait la variable dépendante.
Le modèle sera entraîné à partir de données d’entrée comprenant la taille et l’emplacement de plusieurs maisons, ainsi que les prix correspondants. Une fois le modèle entraîné, il peut être utilisé pour faire des prédictions sur le prix d’une maison, en fonction de sa taille et de son emplacement.
Types d’algorithmes de régression ML
Les algorithmes de régression sont disponibles sous différentes formes et l’utilisation de chaque algorithme dépend d’un certain nombre de paramètres, tels que le type de valeur d’attribut, le modèle de la ligne de tendance et le nombre de variables indépendantes. Les techniques de régression souvent utilisées sont les suivantes
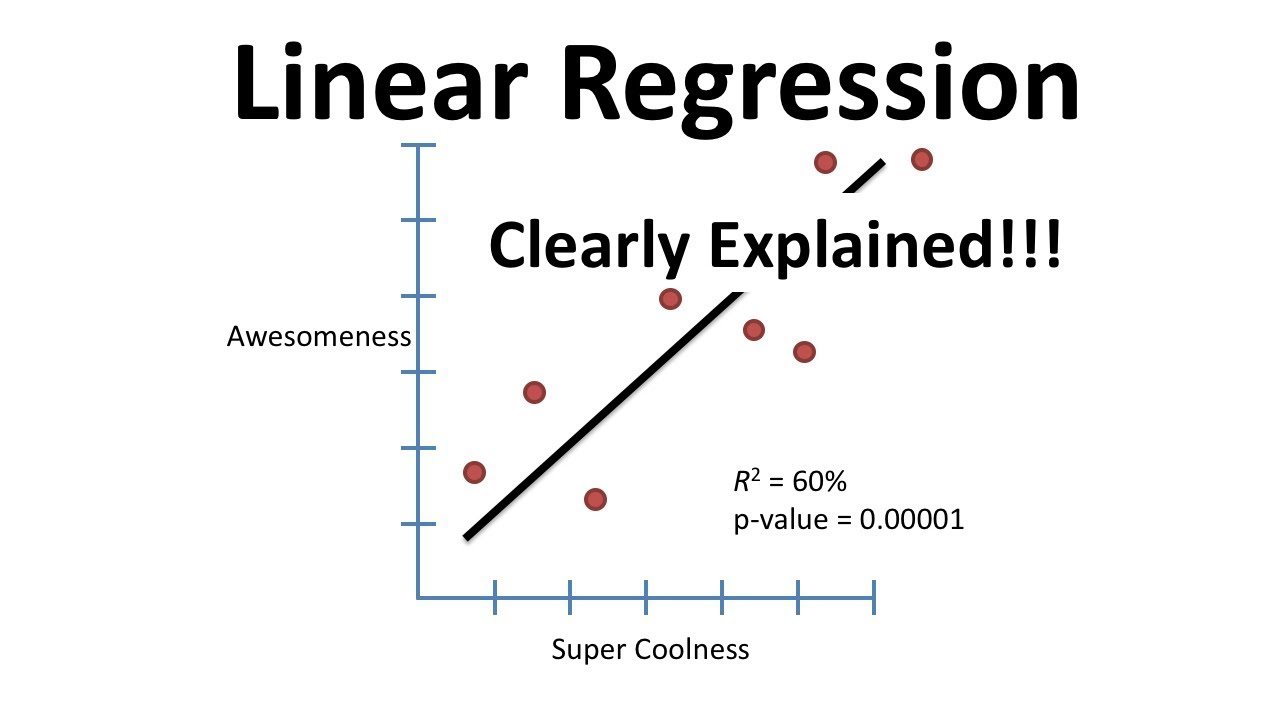
Régression linéaire
Ce modèle linéaire simple est utilisé pour prédire une valeur continue sur la base d’un ensemble de caractéristiques. Il permet de modéliser la relation entre les caractéristiques et la variable cible en ajustant une ligne aux données.
Régression polynomiale
Il s’agit d’un modèle non linéaire utilisé pour ajuster une courbe aux données. Il est utilisé pour modéliser les relations entre les caractéristiques et la variable cible lorsque la relation n’est pas linéaire. Il repose sur l’idée d’ajouter des termes d’ordre supérieur au modèle linéaire afin de saisir les relations non linéaires entre les variables dépendantes et indépendantes.
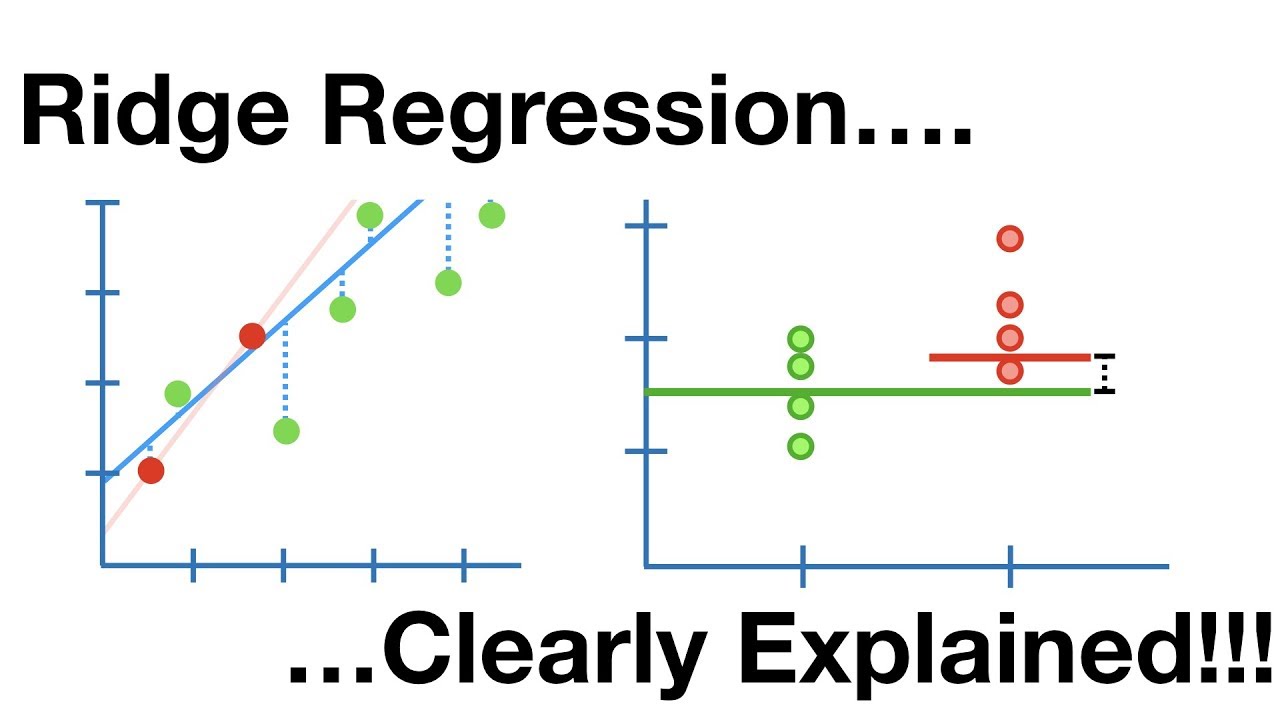
Régression de crête
Il s’agit d’un modèle linéaire qui permet de remédier à l’ajustement excessif de la régression linéaire. Il s’agit d’une version régularisée de la régression linéaire qui ajoute un terme de pénalité à la fonction de coût afin de réduire la complexité du modèle.
Régression vectorielle de soutien
Comme les SVM, la régression vectorielle de support est un modèle linéaire qui tente de s’adapter aux données en trouvant l’hyperplan qui maximise la marge entre les variables dépendantes et indépendantes.
Toutefois, contrairement aux SVM, qui sont utilisés pour la classification, le SVR est utilisé pour les tâches de régression, où l’objectif est de prédire une valeur continue plutôt qu’une étiquette de classe.
Régression Lasso
Il s’agit d’un autre modèle linéaire régularisé utilisé pour empêcher l’ajustement excessif dans la régression linéaire. Il ajoute un terme de pénalité à la fonction de coût en fonction de la valeur absolue des coefficients.
Régression linéaire bayésienne
La régression linéaire bayésienne est une approche probabiliste de la régression linéaire basée sur le théorème de Bayes, qui permet de mettre à jour la probabilité d’un événement en fonction de nouvelles preuves.
Ce modèle de régression vise à estimer la distribution postérieure des paramètres du modèle en fonction des données. Pour ce faire, on définit une distribution a priori des paramètres, puis on utilise le théorème de Bayes pour mettre à jour la distribution sur la base des données observées.
Régression et classification
La régression et la classification sont deux types d’apprentissage supervisé, ce qui signifie qu’elles sont utilisées pour prédire une sortie sur la base d’un ensemble de caractéristiques d’entrée. Il existe toutefois des différences essentielles entre ces deux types d’apprentissage :
| Régression | Classification | |
| Définition | Un type d’apprentissage supervisé qui prédit une valeur continue | Un type d’apprentissage supervisé qui prédit une valeur catégorielle |
| Type de sortie | Continue | Discret |
| Mesures d’évaluation | Erreur quadratique moyenne (MSE), erreur quadratique moyenne (RMSE) | Précision, exactitude, rappel, score F1 |
| Algorithmes | Régression linéaire, Lasso, Ridge, KNN, Arbre de décision | Régression logistique, SVM, Naïve Bayes, KNN, arbre de décision |
| Complexité du modèle | Modèles moins complexes | Modèles plus complexes |
| Hypothèses | Relation linéaire entre les caractéristiques et la cible | Pas d’hypothèses spécifiques sur la relation entre les caractéristiques et la cible |
| Déséquilibre des classes | Sans objet | Il peut s’agir d’un problème |
| Valeurs aberrantes | Peuvent affecter les performances du modèle | Ne pose généralement pas de problème |
| Importance des caractéristiques | Les caractéristiques sont classées par ordre d’importance | Les caractéristiques ne sont pas classées par ordre d’importance |
| Exemples d’applications | Prévision des prix, des températures, des quantités | Prédire si un courriel est un spam, prédire le taux de désabonnement des clients |
Ressources d’apprentissage
Il peut être difficile de choisir les meilleures ressources en ligne pour comprendre les concepts de l’apprentissage automatique. Nous avons examiné les cours populaires proposés par des plateformes fiables afin de vous présenter nos recommandations pour les meilleurs cours de ML sur la régression et la classification.
#1. Bootcamp d’apprentissage automatique de la classification en Python
Il s’agit d’un cours proposé sur la plateforme Udemy. Il couvre une variété d’algorithmes et de techniques de classification, y compris les arbres de décision et la régression logistique, ainsi que les machines à vecteurs de support.

Vous pouvez également en apprendre davantage sur des sujets tels que l’overfitting, le compromis biais-variance et l’évaluation des modèles. Le cours utilise des bibliothèques Python telles que sci-kit-learn et pandas pour mettre en œuvre et évaluer des modèles d’apprentissage automatique. Des connaissances de base en Python sont donc nécessaires pour commencer ce cours.
#2. Cours de maître sur l’apprentissage automatique de la régression en Python
Dans ce cours Udemy, le formateur couvre les bases et la théorie sous-jacente de divers algorithmes de régression, y compris la régression linéaire, la régression polynomiale et les techniques de régression Lasso et Ridge.
A la fin de ce cours, vous serez en mesure d’implémenter des algorithmes de régression et d’évaluer la performance des modèles d’apprentissage automatique formés à l’aide de divers indicateurs de performance clés.
Conclusion
Les algorithmes d’apprentissage automatique peuvent être très utiles dans de nombreuses applications, et ils peuvent aider à automatiser et à rationaliser de nombreux processus. Les algorithmes d’ apprentissage automatique utilisent des techniques statistiques pour apprendre des modèles dans les données et faire des prédictions ou prendre des décisions sur la base de ces modèles.
Ils peuvent être formés sur de grandes quantités de données et peuvent être utilisés pour effectuer des tâches qui seraient difficiles ou fastidieuses à réaliser manuellement par des humains.
Chaque algorithme de ML a ses forces et ses faiblesses, et le choix de l’algorithme dépend de la nature des données et des exigences de la tâche. Il est important de choisir l’algorithme ou la combinaison d’algorithmes appropriés pour le problème spécifique que vous essayez de résoudre.
Il est important de choisir le bon type d’algorithme pour votre problème, car l’utilisation d’un mauvais type d’algorithme peut entraîner des performances médiocres et des prédictions inexactes. Si vous ne savez pas quel algorithme utiliser, il peut être utile d’essayer les algorithmes de régression et de classification et de comparer leurs performances sur votre ensemble de données.
J’espère que cet article vous a été utile dans votre apprentissage de la régression et de la classification dans l’apprentissage automatique. Vous pourriez également être intéressé par les principaux modèles d’apprentissage automatique.