
Le monde dans lequel nous vivons est régi par les données. L’obtention d’informations puissantes en temps réel sur les données du monde réel permet à votre entreprise d’avoir une longueur d’avance. Le streaming de données permet de capturer et de traiter en continu des données provenant de diverses sources, d’où l’importance des plateformes de streaming de données.
Les plateformes de streaming de données sont des systèmes évolutifs, distribués et très efficaces qui garantissent un traitement fiable des flux de données. Elles prennent en charge l’agrégation et l’analyse des données et s’accompagnent souvent d’un tableau de bord unifié pour visualiser vos données.

Vous pouvez choisir parmi une large gamme de plateformes et de solutions de streaming de données – des systèmes entièrement gérés comme Confluent Cloud et Amazon Kinesis aux solutions open-source comme Arroyo et Fluvio.
Quels sont les cas d’utilisation du streaming de données ?
Les plateformes de streaming de données couvrent un large éventail de cas d’utilisation. Passons rapidement en revue quelques-uns d’entre eux :
- La détection des fraudes est assurée par l’analyse continue des transactions, du comportement des utilisateurs et des modèles.
- Les données relatives aux transactions boursières sont capturées par de multiples systèmes qui effectuent des transactions à haut volume à une vitesse fulgurante sur la base d’une analyse du marché.
- Les informations personnalisées obtenues grâce aux données du marché en temps réel permettent aux places de marché du commerce électronique de cibler leurs produits en fonction du public visé.
- Des millions de capteurs installés dans divers systèmes fournissent des données sur le monde réel et contribuent à l’élaboration d’informations prédictives telles que les prévisions météorologiques.
Voici les meilleures plateformes de données pour tous vos besoins en matière d’analyse en temps réel et de traitement des flux.
Confluent Cloud

Offre entièrement cloud-native d’Apache Kafka, Confluent Cloud offre résilience, évolutivité et haute performance. Vous bénéficiez de la puissance du moteur Kora, conçu sur mesure, qui offre des performances 10 fois supérieures à celles de votre propre cluster Kafka. Il vous apporte les fonctionnalités suivantes :
- Les clusters sans serveur vous offrent évolutivité et élasticité. Vous pouvez répondre instantanément à vos besoins en matière de flux de données grâce à une mise à l’échelle et une réduction automatiques à la demande.
- Vos besoins en matière de stockage de données sont satisfaits grâce à la conservation et à l’intégrité infinies des données. Sans problème de durabilité, vous pouvez faire de Confluent Cloud votre source de vérité.
- Confluent Cloud offre un SLA de 99,99%, l’un des meilleurs de l’industrie. Associé à la réplication multizone, vous êtes protégé contre la corruption ou la perte de données.
Le concepteur de flux vous permet de créer visuellement votre pipeline de traitement à l’aide d’une interface utilisateur de type glisser-déposer. De plus, les connecteurs Kafka prédéfinis vous permettent de vous connecter à n’importe quelle application ou fournisseur de données.
Confluent Cloud vous offre Stream Governance, la seule suite de gouvernance de données entièrement gérée du secteur. La sécurité et la conformité du cloud vous permettent de protéger vos données et d’en contrôler l’accès.
Confluent Cloud propose différentes options tarifaires. Il offre également un large éventail de ressources pour vous aider à plonger dans l’action.
Aiven

Aiven vous aide à répondre à vos besoins en matière de flux de données dans un service cloud Apache Kafka entièrement géré. Il prend en charge tous les principaux fournisseurs de cloud, y compris AWS, Google Cloud, Microsoft Azure, Digital Ocean et UpCloud.
Configurez votre propre service Kafka en moins de 10 minutes à l’aide de la console web ou de manière programmatique via l’API et l’interface de programmation. En outre, vous avez la possibilité de l’exécuter dans des conteneurs.
Ne vous souciez plus de la gestion de Kafka grâce à un service cloud entièrement géré. Vous pouvez rapidement mettre en place votre pipeline de données ainsi qu’un tableau de bord de surveillance. Jetons un coup d’œil aux avantages dont vous bénéficierez :
- Recevez des mises à jour automatiques pour votre cluster et gérez vos mises à niveau et votre maintenance en quelques clics.
- Aiven vous offre un temps de disponibilité de 99,99 % et des interruptions quasi nulles.
- Augmentez votre stockage à la demande, ajoutez des nœuds Kafka supplémentaires ou déployez dans différentes régions.
Les tarifs mensuels d’Aiven commencent à 200 $ et varient en fonction de votre localisation et du fournisseur de cloud pour lequel vous optez.
Arroyo
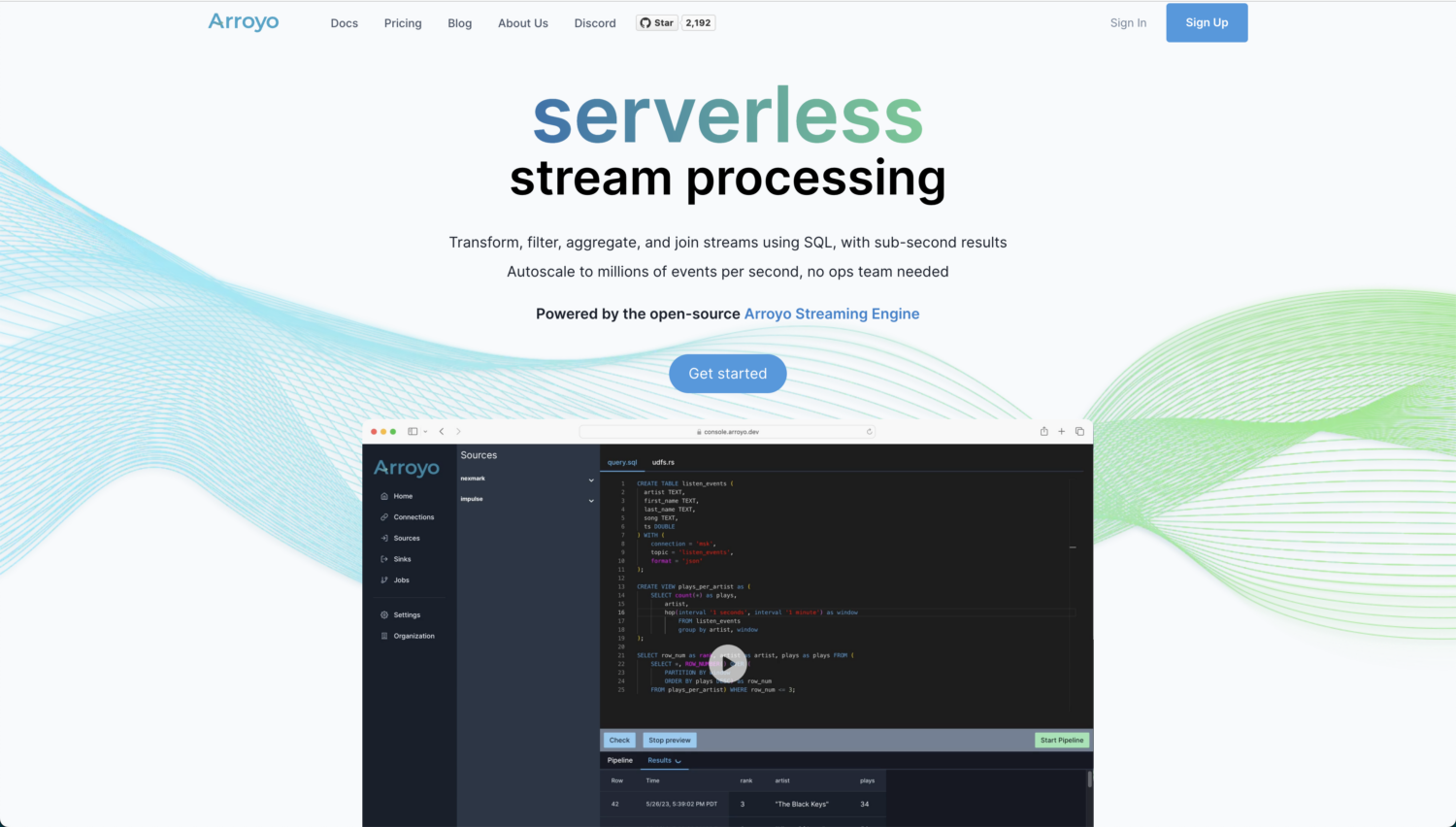
Si vous êtes à la recherche d’une solution open-source et véritablement cloud-native pour vos analyses et traitements en temps réel, Arroyo est un excellent outil. Il est alimenté par le moteur de streaming Arroyo – une solution de traitement de flux distribué qui brille lorsqu’il s’agit de rechercher des données en temps réel avec des résultats inférieurs à la seconde.
Arroyo est conçu pour rendre le traitement en temps réel aussi facile que le traitement par lots. Sa conception étant très conviviale, vous n’avez pas besoin d’être un expert pour construire votre pipeline. Voici ce que vous obtenez avec Arroyo :
- Il y a un support natif pour différents connecteurs, y compris Kafka, Pulsar, Redpanda, WebSockets, et Server Sent Events.
- Après l’ingestion et le traitement des données, les résultats sortants peuvent être écrits dans différents systèmes – comme Kafka, Amazon S3, et Postgres.
- Vous bénéficiez d’un compilateur de pointe, efficace et performant qui transforme vos requêtes SQL pour qu’elles s’exécutent avec une efficacité maximale.
- Le flux de données pour vos plateformes de données peut évoluer horizontalement pour prendre en charge des millions d’événements par seconde.
Vous pouvez exploiter votre propre instance d’Arroyo, qui est gratuite, ou bénéficier de l’aide d’Arroyo Cloud, à partir de 200 dollars par mois. Toutefois, Arroyo est actuellement en phase alpha et peut présenter des fonctionnalités manquantes.
Amazon Kinesis

Amazon Kinesis Data Streams vous permet de collecter et de traiter de grands flux de données pour une ingestion rapide et continue. Il offre une évolutivité massive, une durabilité et un faible coût. Examinons les principales fonctionnalités dont vous bénéficiez :
- Amazon Kinesis s’exécute sur le cloud AWS en mode sans serveur à la demande. En quelques clics depuis la console de gestion AWS, vous pouvez faire fonctionner vos flux de données Kinesis.
- Vous pouvez faire fonctionner Kinesis dans un maximum de 3 zones de disponibilité (AZ). Il offre également 365 jours de rétention des données.
- Les flux de données Kinesis vous permettent d’attacher jusqu’à 20 consommateurs. De plus, chaque consommateur dispose de son propre débit de lecture dédié et peut publier dans les 70 millisecondes suivant l’ingestion.
- Répondez à vos exigences en matière de sécurité en chiffrant vos données à l’aide d’un chiffrement côté serveur.
- L’appartenance à AWS permet à Kinesis de s’intégrer de manière transparente à d’autres services AWS tels que Cloudwatch, DynamoDB et AWS Lambda.
Avec Amazon Kinesis, vous payez pour ce que vous utilisez. Si l’on considère 1000 enregistrements/seconde de 3 Ko chacun, votre coût quotidien pour un mode à la demande sera d’environ 30,61 $. Vous pouvez utiliser la calculatrice AWS pour connaître votre coût basé sur l’utilisation.
Databricks

Si vous recherchez une plateforme de données unique pour le traitement par lots et par flux, la plateforme Databricks Lakehouse est un excellent choix. En outre, vous bénéficiez d’analyses en temps réel, d’apprentissage automatique et d’applications sur une seule plateforme.
La plateforme Databricks Lakehouse dispose de sa propre vue des données, appelée Delta Live Tables (DLT), qui présente les avantages suivants :
- DLT vous permet de définir facilement votre pipeline de données de bout en bout.
- Vous bénéficiez d’un test automatique de la qualité des données. Simultanément, vous pouvez surveiller les tendances de la qualité des données au fil du temps.
- Si votre charge de travail est imprévisible, la mise à l’échelle automatique améliorée de DLT s’en charge.
Vous bénéficiez du meilleur endroit pour exécuter vos charges de travail Apache Spark, avec Spark Structured Streaming comme technologie de base. À cela s’ajoute Delta Lake, la seule plateforme de stockage open-source qui prend en charge à la fois les données en continu et les données par lots.
Avec la plateforme Databricks Lakehouse, vous pouvez bénéficier d’une période d’essai gratuite de 14 jours, à l’issue de laquelle vous serez automatiquement abonné au plan que vous avez choisi.
Qlik Data Streaming (CDC)

CDC ou Change Data Capture est la technique par laquelle tout changement de données est notifié à d’autres systèmes. Solution simple et universelle, Qlik Data Streaming (CDC) vous permet de déplacer facilement vos données de la source à la destination en temps réel. Vous pouvez tout gérer à travers une interface graphique simple.
Qlik Data Streaming (CDC) offre une configuration rationalisée et automatique. Ainsi, vous pouvez facilement mettre en place, contrôler et surveiller votre pipeline de données en temps réel.
Vous bénéficiez de la prise en charge d’un large éventail de sources, de cibles et de plateformes. Cela vous permet non seulement d’ingérer une grande variété de données, mais aussi de synchroniser des données sur site, dans le nuage et hybrides.
Qlik Enterprise Manager est votre centre de commande central qui vous permet d’évoluer facilement et de surveiller le flux de données par le biais d’alertes.
Il existe une option de déploiement flexible lorsqu’il s’agit de choisir la manière dont vous souhaitez gérer votre pipeline CDC. En fonction de vos besoins, vous pouvez choisir entre les options suivantes :
- Si vous recherchez une plateforme en tant que service, optez pour Qlik Cloud Data Integration
- Si vous préférez la gérer vous-même, vous pouvez installer Qlik Data Integration sur site.
Vous pouvez commencer par un essai gratuit sans télécharger ni installer quoi que ce soit.
Fluvio
Vous êtes à la recherche d’une solution de streaming open-source native dans le nuage, avec une faible latence et de hautes performances ? Fluvio répond à cette description. Vous avez la possibilité d’effectuer des calculs en ligne à l’aide de SmartModules qui améliorent les fonctionnalités de la plateforme Fluvio.
Fluvio dispose d’un traitement de flux distribué avec des contrôles pour éviter les pertes de données et les temps d’arrêt. En outre, il existe un support API natif pour les langages de programmation populaires tels que Rust, Node.js, Python, Java et Go. Jetons un coup d’œil à ce que la plateforme a en réserve pour vous :
- La puissance de la combinaison du calcul et du streaming dans un cluster unifié vous permet de minimiser les délais.
- Fluvio charge dynamiquement des modules personnalisés qui étendent les capacités de calcul.
- Vous bénéficiez d’une grande évolutivité qui va des petits appareils IoT aux systèmes multicœurs.
- Il dispose de capacités d’auto-réparation utilisant la gestion déclarative, la réconciliation et la réplication.
- Parce qu’il a été conçu en pensant à la communauté des développeurs, vous bénéficiez d’une interface de programmation puissante pour plus d’efficacité.
Qu’il s’agisse de votre ordinateur portable, du centre de données de votre entreprise ou du nuage public de votre choix, vous pouvez installer Fluvio sur n’importe quelle plateforme.
Comme il s’agit d’un logiciel libre, l’utilisation de Fluvio est gratuite.
Cloudera Stream Processing (CSP)

Alimenté par Apache Flink et Apache Kafka, Cloudera Stream Processing (CSP ) vous offre des capacités d’analyse pour obtenir des informations sur vos données en continu. Il prend en charge en mode natif des technologies standard telles que SQL et REST. En outre, vous bénéficiez d’une solution complète de gestion des flux combinée à un traitement avec état, conçue pour les entreprises.
Cloudera Stream Processing lit et analyse de grands volumes de données en temps réel pour produire des résultats avec des temps de latence inférieurs à la seconde. Bénéficiez d’une prise en charge du multi-cloud et du cloud hybride, ainsi que des outils nécessaires à l’élaboration d’analyses hautement sophistiquées basées sur les données. Profitez des outils et fonctionnalités suivants :
- La prise en charge de millions de messages par seconde vous permet de répondre à vos besoins en constante évolution grâce à une diffusion en continu hautement évolutive.
- Streams Messaging Manager offre une vue de bout en bout de la manière dont vos données se déplacent dans votre pipeline de traitement des données.
- Streams Replication Manager assure la réplication, la disponibilité et la reprise après sinistre.
- Réduisez les incohérences de schémas et les interruptions grâce à Schema Registry, qui vous permet de tout gérer dans un référentiel partagé.
- Grâce à une sécurité centralisée appliquée automatiquement, Cloudera SDX offre un contrôle et une gouvernance unifiés sur l’ensemble de vos composants.
Avec Cloudera Stream Processing en moins de 10 minutes, vous pouvez démarrer votre pipeline de traitement de flux sur la plateforme cloud de votre choix – que ce soit AWS, Azure ou Google Cloud Platform.
Striim Cloud

Votre plateforme de données et votre analyse en temps réel nécessitent une grande variété de producteurs et de consommateurs de données ? Striim Cloud, avec son support intégré de 100 connecteurs, peut être le choix idéal. Intégrez facilement vos données existantes et diffusez des données en temps réel à l’aide d’une plateforme SaaS entièrement gérée et conçue pour le cloud.
Striim Cloud offre une interface simple de type ” glisser-déposer “, qui permet non seulement de construire votre pipeline mais aussi d’obtenir des informations sur vos données. Elle prend en charge les outils d’analyse les plus populaires, notamment Google BigQuery, Snowflake, Azure Synapse et Databricks. En outre, vous bénéficiez des avantages suivants :
- Vos inquiétudes concernant les changements dans la structure des données sont gérées par les capacités d’évolution du schéma de Striim. Vous pouvez la configurer pour une résolution automatique ou une intervention manuelle.
- Construit sur une plateforme distribuée de streaming SQL, Striim vous permet d’exécuter des requêtes en continu.
- Striim offre une grande évolutivité et un débit élevé. Par conséquent, vous pouvez faire évoluer votre pipeline sans aucune planification ou coût supplémentaire.
- La méthode ‘ReadOnlyWriteMany’ vous permet d’ajouter et de supprimer de nouvelles cibles sans aucun impact sur vos magasins de données.
Ne payez que ce que vous utilisez. L’environnement de développement Striim est gratuit et vous permet de tester la plateforme avec 10 millions d’événements par mois. Pour une solution en nuage à l’échelle de l’entreprise, le prix commence à 2500 $/mois.
Plateforme de données en continu VK

Vertical Knowledge (VK) aide les particuliers et les entreprises à prendre de bonnes décisions à grande échelle grâce à des produits de données et des informations de la plus haute qualité. La plateforme de données en continu VK vous permet de traiter des quantités massives de données grâce à un environnement de données en continu basé sur le web.
Obtenez des informations exploitables grâce à la découverte automatisée des données. Voici les principaux avantages de la plateforme de données en continu de VK :
- Vous bénéficiez d’une cybersécurité solide grâce à l’infrastructure stable de VK qui vous protège des contenus malveillants. Vous pouvez également télécharger des données dans un environnement virtuel.
- Les flux de données automatisés vous permettent d’opérer facilement à travers de multiples sources de données.
- Grâce à la découverte rapide, vous pouvez réduire les processus manuels, qui prennent souvent beaucoup de temps.
- Générez des collections de données approfondies en exécutant des pipelines simultanés à partir de sources multiples. Vous pouvez ainsi générer des résultats globaux pour des mots-clés sélectionnés.
- Vous pouvez exporter vos collections de données au format brut JSON ou CSV ou utiliser des API pour les intégrer à des systèmes tiers.
Plate-forme HStream
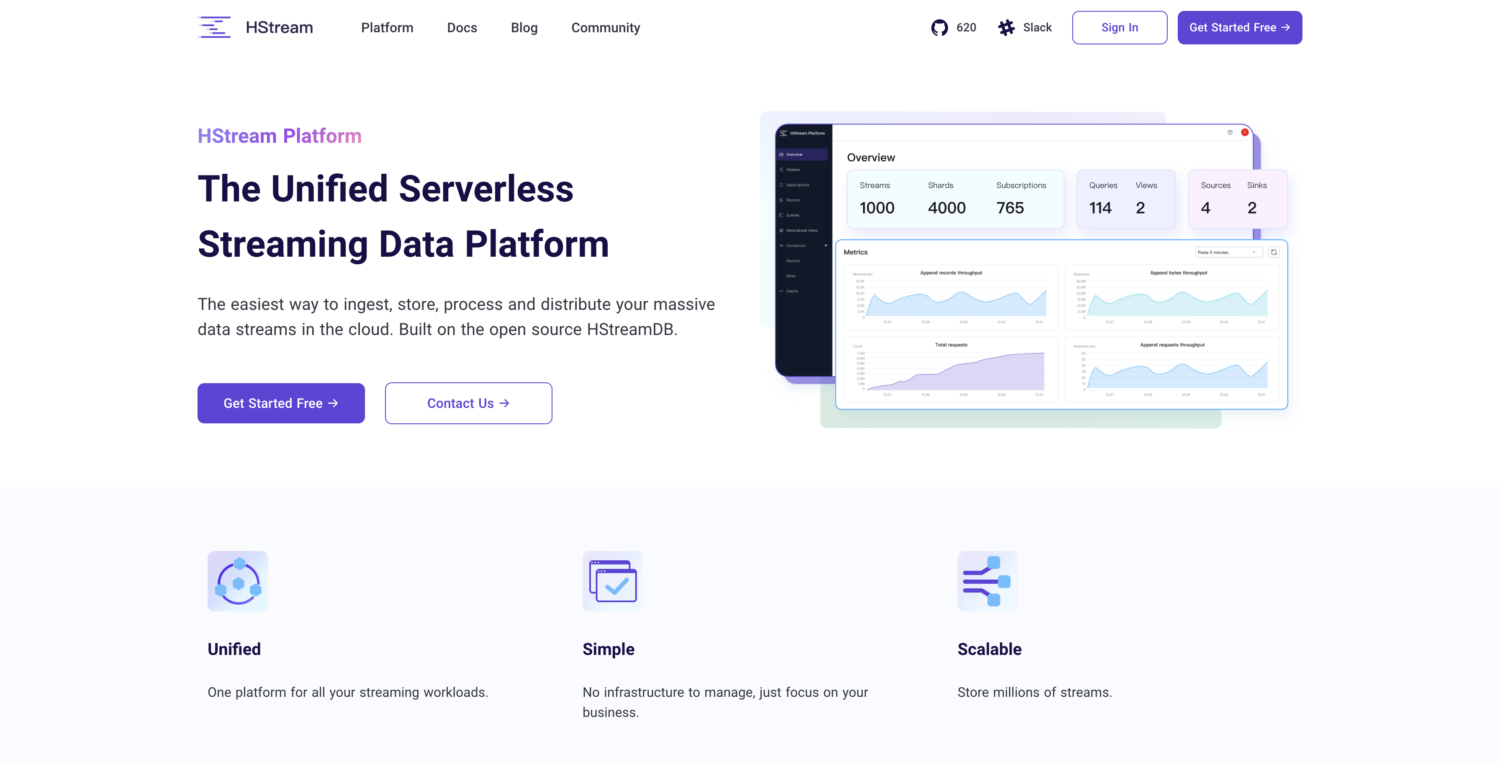
Construite sur la base du logiciel libre HStreamDB, la plateforme HStream offre une plateforme de données en continu sans serveur. Vous pouvez ingérer des quantités massives de données et stocker de manière fiable des millions de flux de données. HStreamDB est aussi rapide que Kafka. En outre, vous pouvez rejouer des données historiques
Vous pouvez utiliser SQL pour filtrer, transformer, agréger et même joindre plusieurs vues de données. Vous obtenez ainsi des informations en temps réel sur vos données. La plateforme HStream vous permet de démarrer à petite échelle et est légère. Voici ses principales caractéristiques :
- Comme elle est sans serveur, elle est prête à l’emploi dès le départ.
- Vous n’avez pas besoin de Kafka pour vos besoins en streaming.
- Vous bénéficiez d’un traitement de flux sur place à l’aide de SQL standard.
- Consommez et produisez à partir de différents systèmes, qu’il s’agisse de bases de données, d’entrepôts de données ou de lacs de données. Vous n’avez donc pas besoin d’outils ETL supplémentaires.
- Vous pouvez gérer efficacement toute votre charge de travail au sein d’une plateforme de streaming unifiée.
- L’architecture “cloud-native” vous permet de faire évoluer vos besoins en matière de calcul et de stockage de manière indépendante.
HStream Platform est actuellement en version bêta publique. Son utilisation est gratuite – il vous suffit de vous inscrire.
Conclusion
Le choix d’une bonne plateforme de streaming de données dépend de votre échelle, de vos besoins en matière de connecteurs, de disponibilité et de fiabilité.
Alors que certaines plateformes sont des services entièrement gérés, d’autres sont open-source et vous offrent diverses possibilités de personnalisation. Examinez vos besoins et votre budget et choisissez celle qui vous convient le mieux.
Vous vous demandez toujours comment utiliser au mieux toutes ces données ? Essayez les outils de prévision et de prédiction des données alimentés par l’IA pour les entreprises.