Federated Learning markiert einen Wandel in der Art und Weise, wie Modelle für maschinelles Lernen trainiert werden. Traditionell werden Daten aus vielen Quellen zum Trainieren der Modelle an einen zentralen Ort übertragen. Federated Learning kehrt den Prozess um – Modelle werden zu den Daten geschickt, lokal trainiert und nur die Aktualisierungen werden zurückgegeben. Dies schützt die Privatsphäre der Benutzer, da sensible Daten auf den Originalgeräten verbleiben.
Föderiertes Lernen in der KI hat erhebliche Vorteile für die Entwicklung des maschinellen Lernens. Es senkt die Kosten, indem es massive Datenübertragungen überflüssig macht, und ermöglicht oft das Training auf weniger leistungsfähigen Endgeräten.
Wie funktioniert föderiertes Lernen?
Das Lernen beim föderierten Lernen besteht aus einer Reihe von atomaren Schritten, die ein Modell erzeugen. Diese Schritte werden als Lernrunden bezeichnet. Ein typisches Lernsystem durchläuft diese Runden und verbessert das Modell bei jedem Schritt. Jede Lernrunde umfasst die folgenden Schritte.
Eine typische Lernrunde
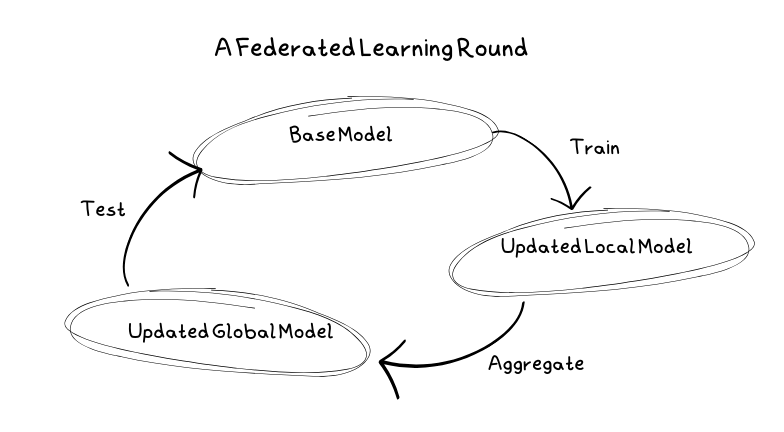
Zunächst wählt der Server das zu trainierende Modell und Hyperparameter wie die Anzahl der Runden, die zu verwendenden Client-Knoten und den Anteil der Knoten an jedem Knoten aus. Zu diesem Zeitpunkt wird das Modell auch mit den Anfangsparametern initialisiert, um das Basismodell zu bilden.
Als nächstes erhalten die Clients Kopien eines Basismodells zum Trainieren. Diese Clients können mobile Geräte, PCs oder Server sein. Sie trainieren das Modell auf ihren lokalen Daten und vermeiden so die gemeinsame Nutzung sensibler Daten mit den Servern.
Sobald die Clients das Modell mit ihren lokalen Daten trainiert haben, senden sie es als Update an den Server zurück. Wenn der Server das Update empfängt, wird es zusammen mit den Updates der anderen Clients gemittelt, um ein neues Basismodell zu erstellen. Da die Clients unzuverlässig sein können, kann es vorkommen, dass einige Clients ihre Aktualisierungen nicht einsenden. An diesem Punkt kümmert sich der Server um alle Fehler.
Bevor das Basismodell erneut bereitgestellt werden kann, muss es getestet werden. Der Server speichert jedoch keine Daten. Um das Modell zu testen, wird es daher an die Clients zurückgeschickt, wo es anhand ihrer lokalen Daten getestet wird. Wenn es besser ist als das vorherige Basismodell, wird es übernommen und stattdessen verwendet.
Hier finden Sie eine hilfreiche Anleitung zur Funktionsweise des föderierten Lernens vom Federated Learning Team bei Google AI.
Zentralisiert vs. Föderiert vs. Heterogen
In dieser Konfiguration gibt es einen zentralen Server, der für die Steuerung des Lernens verantwortlich ist. Diese Art der Einrichtung wird als Centralized Federated Learning bezeichnet.
Das Gegenteil von zentralisiertem Lernen ist dezentralisiertes föderiertes Lernen, bei dem sich die Clients peer-to-peer koordinieren.
Die andere Variante wird als Heterogenes Lernen bezeichnet. In diesem Fall haben die Clients nicht unbedingt die gleiche globale Modellarchitektur.
Vorteile des föderierten Lernens
- Der größte Vorteil des föderierten Lernens besteht darin, dass es dazu beiträgt, private Daten geheim zu halten. Die Clients teilen die Ergebnisse des Trainings, nicht die Daten, die für das Training verwendet wurden. Es können auch Protokolle eingerichtet werden, um die Ergebnisse zusammenzufassen, damit sie nicht mit einem bestimmten Client in Verbindung gebracht werden können.
- Außerdem wird die Netzwerkbandbreite reduziert, da keine Daten zwischen dem Client und dem Server ausgetauscht werden. Stattdessen werden die Modelle zwischen dem Client und dem Server ausgetauscht.
- Auch die Kosten für das Training der Modelle werden reduziert, da keine teure Trainingshardware gekauft werden muss. Stattdessen nutzen die Entwickler die Hardware des Clients, um Modelle zu trainieren. Da nur wenige Daten anfallen, wird das Gerät des Clients nicht belastet.
Nachteile von Federated Learning
- Dieses Modell hängt von der Beteiligung vieler verschiedener Knotenpunkte ab. Einige davon werden nicht vom Entwickler kontrolliert. Daher ist ihre Verfügbarkeit nicht garantiert. Das macht die Trainingshardware unzuverlässig.
- Die Clients, auf denen die Modelle trainiert werden, sind nicht gerade leistungsstarke GPUs. Stattdessen handelt es sich um normale Geräte wie Telefone. Diese Geräte sind, selbst in ihrer Gesamtheit, im Vergleich zu GPU-Clustern möglicherweise nicht leistungsstark genug.
- Föderiertes Lernen setzt auch voraus, dass alle Client-Knoten vertrauenswürdig sind und für das Gemeinwohl arbeiten. Einige sind es jedoch nicht, und sie könnten falsche Aktualisierungen vornehmen, die zu einer Modellabweichung führen.
Anwendungen des föderierten Lernens
Federated Learning ermöglicht Lernen unter Wahrung der Privatsphäre. Dies ist in vielen Situationen nützlich, wie z.B.:
- Vorhersage des nächsten Wortes auf Smartphone-Tastaturen.
- IoT-Geräte, die Modelle lokal auf die spezifischen Anforderungen der jeweiligen Situation trainieren können.
- Pharmazeutische Industrie und Gesundheitswesen.
- Auch die Verteidigungsindustrie würde davon profitieren, Modelle zu trainieren, ohne sensible Daten weiterzugeben.
Frameworks für föderiertes Lernen
Es gibt viele Frameworks für die Implementierung von Federated Learning-Mustern. Einige der besten davon sind NVFlare, FATE, Flower und PySft.