Sora AI ist ein Text-zu-Video-Modell, das von OpenAI entwickelt wurde – den Köpfen hinter ChatGPT. Sora AI befindet sich noch in der Entwicklung, daher müssen Sie sich mit dem Zugang zu Sora noch etwas gedulden – vorerst. Trotzdem ist es wichtig, sich anzusehen, wie es im Vergleich zu anderen Text-zu-Video-Generatoren abschneidet, um die Zukunft der KI-Inhaltserstellung zu erkunden.
Die Beispielvideos von OpenAI zeigen, dass Sora AI in der Lage ist, fotorealistisches Bildmaterial zu erzeugen. Außerdem scheint es keine Probleme zu geben, visuell ansprechende, cartoonartige Animationen zu erstellen. Die Bewegungen der Charaktere, die Beleuchtung, die Proportionen und die kleinsten Details (wie z.B. Gesichtsflecken und Felltextur) sind ziemlich präzise. Damit entwickelt sich Sora AI zu einem idealen Modell für die Text-zu-Video-KI.
Die besten derzeit verfügbaren Generatoren für Text-zu-Video-KI sind einfach zu bedienen und erstellen hochwertige Inhalte – wenn auch mit deutlichen Einschränkungen. Bislang können selbst die meistgenutzten Generatoren nur menschliche Gesichter, Torsi und Stimmen präzise erzeugen. OpenAI scheint einzigartige Funktionen zu entwickeln, die sich von der Konkurrenz abheben.

Die Entwicklung neuerer, komplexerer und zunehmend beeindruckender KI-Modelle ist zu einem Wettrüsten geworden. Während die KI-Programmierer hart daran arbeiten, neue und nützliche Tools zu erfinden, müssen auch Sicherheitsprotokolle implementiert werden.
Es muss verhindert werden, dass leistungsstarke Modelle wie Sora für die Erstellung unangemessener Animationen (Hass, Urheberrechtsverletzungen und andere negative Möglichkeiten) verwendet werden. Nicht nur zu unserer Sicherheit, sondern auch um vernünftige Best Practices in der Branche durchzusetzen – was OpenAI sehr ernst nimmt.
Wie man auf Sora AI zugreift
Derzeit gibt es keinen öffentlichen Zugang zu Sora AI. Nur wenige Personen können dieses Text-zu-Video-Modell nutzen. Neben “Red Teamern”, die erforschen, wie die Nutzung so sicher wie möglich gestaltet werden kann, hat OpenAI einigen Künstlern, Designern und Filmemachern zu Testzwecken Zugang gewährt.
In einem kürzlich erschienenen FAQ-Artikel von OpenAI über den Zugang zu Sora erklärte das Unternehmen, dass es keinen Zeitplan für die öffentliche Verfügbarkeit gibt. Außerdem gibt OpenAI keine Details darüber bekannt, wer außerhalb seiner Büros daran beteiligt ist. Sie erwähnten vage, dass sie mit politischen Entscheidungsträgern, Pädagogen und anderen Personen zusammenarbeiten, um Feedback zur verantwortungsvollen Entwicklung und Nutzung von Sora zu erhalten.
Können Sie ein Sora-KI-Tester werden?
Bislang gibt es keine offizielle Möglichkeit, Tester für Sora zu werden – oderMitglied der “Red Teamer” von OpenAI Im Community-Forum von OpenAI gibt es viele Threads zu solchen Fragen. Die Moderatoren erinnern die Benutzer jedoch schnell daran, dass es keinen offiziellen Weg gibt, sich für Sora-Tests anzumelden. Nach solchen Erinnerungen werden die Threads geschlossen, um andere Benutzer nicht zu verwirren.
OpenAI ist entschlossen, Sora so sicher wie möglich zu machen, bevor die Öffentlichkeit dieses komplexe KI-Modell in die Hände bekommt. Der Hauptgrund für das Fehlen von Details ist ebenfalls die Sicherheit. Die Herausgabe von Informationen über die Tester ist unsicher, da sie ins Visier genommen werden könnten.
Daher könnte es noch eine Weile dauern, bis die Öffentlichkeit Zugang zu Sora erhält. OpenAI preist die Qualität seines in der Entwicklung befindlichen KI-Modells an, so dass eine allgemeine Veröffentlichung nicht mehr allzu lange auf sich warten lassen dürfte. Die meisten Unternehmen neigen dazu, ihre Dienstleistungen und Produkte lange vor der Markteinführung zu vermarkten – aber normalerweise nicht Jahre im Voraus. Daher wäre eine vernünftige Spekulation für die öffentliche Freigabe von Sora AI später im Jahr 2024 oder 2025.
Beispiele für die Funktionsweise von Sora AI
Sora bietet in vielen Bereichen branchenführende Animationen (Beleuchtung, kleinste Details und mehr), hat aber mit den üblichen KI-Fallen zu kämpfen.
Was Sora AI noch nicht kann
Es gibt einige Probleme bei der Interpretation von Konzepten und Anweisungen. Wenn Sie z.B. die Anweisung erhalten, einen “Einsiedlerkrebs mit einer Glühbirne als Panzer” zu animieren, produziert Sora Bilder einer krabbenähnlichen Kreatur mit einem gewöhnlichen Panzer auf dem Rücken, die eine Glühbirne am Hinterteil hat.
In dieser stundenlangen Animation wird deutlich, dass die Figur nur eine vage Ähnlichkeit mit einer Krabbe hat. Ja, sie hat Beine und Klauen, aber keine lebende Krabbenart (oder krabbenähnliche Tiere) hat einen Panzer wie der in Soras Bild. Außerdem wird die Glühbirne nicht als Panzer verwendet, sondern ist lediglich an der Rückseite des Rahmens der Figur befestigt.
Ein weiteres Beispiel finden Sie auf der OpenAI-Webseite über Sora. In einem der fünf Videos, in denen Soras derzeitige Schwächen beschrieben werden, zeigt ein prominentes Video einen Mann, der rückwärts auf einem Laufband läuft. Kriterien wie die Richtungen – oben, unten, links und rechts – sind für Sora derzeit schwer zu analysieren. OpenAI hat transparent und ehrlich dargelegt, wo ihr in der Entwicklung befindliches Text-Videomodell noch Schwächen aufweist. Das scheint ein Zeichen dafür zu sein, dass sie wissen, wo und wie sie sich verbessern können.

Insgesamt gibt es 5 (bekannte) Hauptprobleme mit den Grafiken von Sora AI:
- Richtungsabhängige Interpretation
- Charaktere und Objekte erscheinen und verschwinden
- Objekte und Charaktere bewegen sich durcheinander
- Definieren, wann Objekte starr oder weich sein sollen
- Bestimmung der Ergebnisse von physischen Interaktionen zwischen Charakteren und Objekten
Vergessen Sie nicht, dass die Sora KI noch einen langen Weg vor sich hat, bevor sie für die Öffentlichkeit bereit ist. Daher werden die derzeitigen Schwächen zwangsläufig angegangen und korrigiert werden – zumindest bis zu einem gewissen Grad.
Was Sora AI gut macht
Während der kommende Text-to-Video-Generator von OpenAI nicht alle Aspekte der Interaktionen zwischen Charakteren und Objekten bewältigen kann, ist die visuelle Darstellung nahezu makellos, wenn der Fokus auf der Umgebung liegt.
Schwungvolle Kamerafahrten, die Küstenlandschaften und verschneite Vogelperspektiven von Tokiozeigen, sind wunderbar realistisch. Auch die Aufnahmen aus der Tierwelt sehen überzeugend aus.
Darüber hinaus ist Sora sehr geschickt darin, organische und anorganische Komponenten zu kombinieren, wenn die Anweisungen vage sind. Im Gegensatz zu komplexen und einzigartigen Aufforderungen wie “Gib einem Einsiedlerkrebs eine Glühbirne als Panzer” liefern einfachere Aufforderungen mit mehr Freiheiten wie “Kybernetischer Deutscher Schäferhund” ansprechendere Ergebnisse.
Denken Sie daran, dass KI-Modelle durch die Aufnahme von Daten lernen müssen. Es gibt viel mehr visuelle Beispiele von Hunden mit Prothesen als Bilder von Einsiedlerkrebsen mit Glasobjekten auf dem Rücken.
Ähnlich verhält es sich mit der Sora KI, die auf eine Fülle von Naturaufnahmen zugreifen kann, um Animationen im dokumentarischen Stil zu erstellen, die kaum vom echten Leben zu unterscheiden sind. Die Generierung von Bildern wie einem Schmetterling, der sich auf einer Blume ausruht, ist konsistent und elegant.
Aus umgekehrten Gründen kann Sora beeindruckend ästhetische Inhalte in völlig fiktiven Umgebungen erstellen. Wenn weniger reale physikalische Gegebenheiten zu berücksichtigen sind, füllen KI-Modelle, die Text in Video umwandeln, oft logisch die Lücken in den prompten Informationen aus. Daher sehen Simulationen, die Science-Fiction-Konzepte wie Drohnenrennen auf dem Planeten Mars darstellen, großartig aus – auch wenn sie nicht realistisch sind (aufgrund der Art der Aufforderung).
Die Entwicklung eines Prompts für eine eher cartoonartige Animation profitiert von dieser Freiheit. Wenn der Wortlaut einer Eingabeaufforderung gut abgestimmt ist, kann Sora einen Absatz Text in eine Animation verwandeln, die sich mit der von Pixar und anderen namhaften Animationsstudios messen kann. Das Ergebnis könnte das bezaubernde Herumtollen eines kugelförmigen Eichhörnchens sein – oderalles andere, was der Benutzer sich wünscht.
Die verrückte Welt der Text-zu-Video-Generatoren
Neben denjenigen, die KI-Videogeneratoren für Design- und Filmzwecke nutzen, gibt es auch einige, die Sora nur zum Spaß benutzen. Wenn die Benutzer die Grenzen der Eingabeaufforderung ausreizen, können sie witzige und bizarre Inhalte erstellen. Von surrealistischen Fahrradrennen über Ozeane bis hin zur Verschmelzung mit einer Decke auf einem Bett– manche Ergebnisse werden eher wegen ihres komödiantischen Werts als zu künstlerischen Zwecken genossen.
Einerseits sind die phantastischen Aspekte verlockend für kreative Typen, die sich amüsieren wollen. Auf der anderen Seite erleichtern solche Bilder die Entwicklung von Filmen. Wenn ein Regisseur beispielsweise eine Szene drehen möchte, die in einer alternativen Realität spielt , in der Tiere Schmuck essen, gäbe es eine Menge Probleme mit dem Tierschutz – gelinde gesagt. Mit dem Zugang zur Sora-KI können solche Szenen jedoch ohne jedes Risiko auf einem Computer erzeugt werden.
Heutzutage ist die Filmindustrie viel besser als früher in der Lage, nichtmenschliche Tiere am Set mit Mitgefühl zu behandeln. Wenn das nicht so wäre, hätte dieser Golden Retriever-Podcast sicher etwas dazu zu sagen! Ganz im Ernst: Text-to-Video-Generatoren werden die Art und Weise, wie Filme gemacht werden, revolutionieren.
Ein Blick in die technischen Abläufe von Sora AI
Um zu verstehen, wie Sora atemberaubende Aussichten schaffen und Zaubertricks mit einem Löffel ausführen kann, werfen Sie einen Blick in den technischen Bericht von OpenAI.
Der Prozess beginnt mit der Komprimierung von Bilddaten in Raumzeit-Patches, die als Transformator-Token fungieren. Laienhaft ausgedrückt: Raum-Zeit-Felder (in diesem Fall) sind kleine Abschnitte visueller Informationen, die mit Zeitmarkierungen versehen sind. Transformator-Token sind die kleinste Ebene von Dateneinheiten, die beim KI-Training verwendet werden – jeder Patch ist ein Token.
Brechen Sie den Prozess weiter herunter:
- Bildeingaben werden identifiziert
- Die Bildeingaben werden in Flecken zerlegt
- Zufällige Patches (Tokens) werden analysiert, bis alle verarbeitet wurden
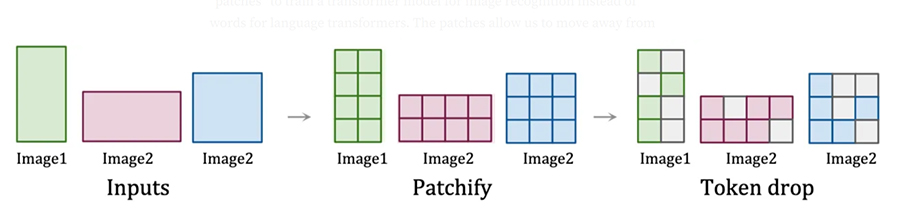
Der Prozess des Aufteilens und anschließenden Umwandelns visueller Daten in Token ermöglicht es KI-Modellen, effizient zu lernen. So kann Sora feststellen, wie Elemente zusammenhängen, wann Aktionen stattfinden sollen und vieles mehr. Außerdem kann Sora auf diese Weise visuelle Daten mit verschiedenen Auflösungen und Seitenverhältnissen verarbeiten. Insbesondere die Aufnahme von Bildern und Videos in ihren nativen Formaten schult die KI-Modelle darin, verschiedene visuelle Aspekte durch den Vergleich der Unterschiede zwischen den einzelnen Token genauer zu beurteilen.
Doch damit ist der Prozess noch nicht zu Ende! Nachdem die Token verschlungen wurden, werden komplexe Berechnungen mehrmals pro Sequenz der Inhaltserstellung durchgeführt. Zu Beginn (bei der Basisberechnung) sieht das erstellte Video abstrakt aus. Mit zunehmender Trainingsberechnung wird Sora jedoch immer besser in der Lage sein, Bilder zu erzeugen, die dem echten Leben entsprechen.

Opinión del autor
Was wir bisher von Sora gesehen haben, lässt die Konkurrenz weit hinter sich. Bestehende Text-zu-Video-Generatoren sind nur geeignet, um einen menschlichen Moderator in Inhalte einzufügen. Nichts, was derzeit auf dem Markt ist, kann komplexe, atemberaubende und (meist) realistische Videos aus reinen Textanweisungen erstellen.
Um die Waage auszugleichen: Die Sora KI hat noch einen langen Weg vor sich, bevor sie der Öffentlichkeit zugänglich gemacht werden sollte. Dennoch ist sie für viele künstlerische und wissenschaftliche Zwecke unglaublich vielversprechend. Sie kann nicht nur ein fantastisches Werkzeug für das Filmemachen sein, sondern sie könnte es Wissenschaftlern eines Tages ermöglichen, bisher unmögliche Szenarien zu simulieren. Ja, Soras physikalisches Konzept muss noch stark verbessert werden, bevor es für den letztgenannten Zweck eingesetzt werden kann, aber es – und andere KI-Modelle wie dieses – werden wahrscheinlich in ein paar Jahren so weit sein.
Stellen Sie sich zum Beispiel eine Welt vor, in der die klügsten Köpfe mit Hilfe von Text-zu-Video-Generatoren die Folgen verschiedener Unfälle simulieren können. Auf diese Weise können Forscher Sicherheitsanzüge von unvergleichlicher Qualität zu einem Bruchteil des bisherigen Budgets herstellen. Das wiederum würde die Zahl der Verletzungen, der Arztrechnungen und der Kosten für Krankenhausoperationen senken – was alles der Gesellschaft zugute käme.
Aber das ist noch ein weiter Weg. Während die führenden Köpfe der Branche daran arbeiten, das Verständnis von Sora und ähnlichen Modellen zu vertiefen, gibt es genug verrückte KI-Videos, die Sie genießen können. Bis dahin können Sie sich zurücklehnen, entspannen und für die Zukunft planen.