Der Cloud GPU-Anbieter ermöglicht es Firmen und Unternehmen, Rechenleistung nach Bedarf zu nutzen (über Cloud Graphical Units), ohne in eine High-Performance-Computing-Infrastruktur zu investieren.
Unternehmen nutzen Cloud-GPU-Anbieter, um verschiedene KI-Workloads auszuführen, darunter:
- Datenverarbeitungs-Workloads: Zur Reinigung, Verarbeitung und Vorbereitung von Daten für das Modelllernen.
- Workloads für maschinelles Lernen: Für das Training, die Entwicklung und den Einsatz von ML-Algorithmen.
- Verarbeitung natürlicher Sprache (NLP): FürAlgorithmen, die Maschinen beibringen, menschliche Sprache zu verstehen, zu erzeugen und zu interpretieren.
- Deep Learning-Workloads: Für das Training und den Einsatz von neuronalen Netzwerken.
- Generative KI: Für das Training von generativen KI-Modellen wie Large Language Models (LLMs), die neue Inhalte, einschließlich Bilder, Texte und Videos, erstellen können.
- Computer Vision: Für das Training von Maschinen zur Interpretation visueller Daten für die Entscheidungsfindung.
Durch die Verlagerung von KI-Arbeitslasten zu Cloud-GPU-Anbietern erhalten Unternehmen die folgenden Vorteile:
- Bessere Entscheidungsfindung auf der Grundlage von Daten.
- Verbesserte Effizienz durch die Automatisierung von sich wiederholenden Aufgaben
- Die Fähigkeit, komplexe Probleme zu lösen, Dienstleistungen zu verbessern und neue Produkte mit fortschrittlichen KI-Algorithmen zu entwickeln.
Das Geekflare-Team hat die besten Cloud-GPU-Anbieter anhand von Faktoren wie GPU-Modell, Leistung, Preisgestaltung, Skalierbarkeit, Integration und Sicherheit untersucht und aufgelistet.
- 1. Google Cloud GPUs
- 2. Amazon Web Services (AWS)
- 3. Hyperstack
- 4. Seeweb
- 5. IBM Cloud
- 6. Latitude.sh
- 7. Genesis Cloud
- 8. Paperspace CORE
- 9. OVHcloud
- 10. RunPod
- 11. Lambda GPU
- 12. TensorDock
- 13. Ori
- 14. Nebius
- Show less
1. Google Cloud GPUs
Google Cloud GPUs bieten Hochleistungs-GPUs, die sich ideal für Rechenaufgaben wie 3D-Virtualisierung, generative KI und High-Performance-Computing (HPC) eignen. Unternehmen können aus einer großen Auswahl an GPUs wählen, darunter:
- NVIDIA H100
- L4
- P100
- P4
- V100
- T4
- A100

Diese sind anpassbar und bieten flexible Leistung mit leistungsstarken Festplatten, Speicher und Prozessoren. Jede Instanz unterstützt 8 GPUs, und Sie müssen nur für die Nutzung zahlen, die Sie mit sekundengenauer Abrechnung nutzen.
Darüber hinaus können Unternehmen, die Google Cloud GPUs nutzen, die Vorteile der GCP-Infrastruktur nutzen, einschließlich ihrer Netzwerk-, Speicher- und Datenanalysefunktionen.
Google Cloud GPU-Preise
Die GCP-GPUs bieten die folgende Preisgestaltung nach Aufwand:
- NVIDIA T4: Beginnt bei $0,35 pro GPU (1 GPU und 16 GB GDDR6).
- NVIDIA P4: Beginnt bei $.60 pro Grafikkarte (1 Grafikkarte und 8 GB GDDR6).
- NVIDIA V100: Beginnt bei $2,48 pro Grafikkarte (1 Grafikkarte und 16 GB HBM2).
- NVIDIA P100: Ab $1,46 pro Grafikprozessor (1 Grafikprozessor und 16 GB HBM2).
- NVIDIA T4 Virtuelle Arbeitsstation: Ab $0,55 pro GPU (1 GPU und 16 GB GDDR6).
- NVIDIA P4 Virtuelle Workstation: Ab $0,80 pro GPU (1 GPU und 8 GB GDDR5).
- NVIDIA P100: Ab $1,66 pro Grafikprozessor (1 Grafikprozessor und 16 GB HBM2).
Sie erhalten einen günstigeren Preis für längere Laufzeiten (1 Jahr und 3 Jahre).
2. Amazon Web Services (AWS)
AWS bietet in Zusammenarbeit mit NVIDIA Cloud-GPUs an und bietet damit kostengünstige, flexible und leistungsstarke GPU-basierte Lösungen.

AWS bietet die folgenden Lösungen:
- NVIDIA AI Enterprises: Eine durchgängige Cloud-native Softwareplattform, die vortrainierte Modelle anbietet, Data-Science-Pipelines beschleunigt und Datenwissenschaftlern die Werkzeuge an die Hand gibt, um produktionsreife KI-Anwendungen zu entwickeln und bereitzustellen. Außerdem bietet sie Tools für die Verwaltung und Orchestrierung, die Sicherheit, Leistung und Zuverlässigkeit gewährleisten.
- EC2 P5-Instanzen: Die leistungsstarken EC2 P5-Instanzen von Amazon sind ebenfalls mit G4dn (NVIDIA-GPUs) oder G4ad (AMD-GPUs) ausgestattet. Wissenschaftler und Ingenieure können diese HPC-Instanzen nutzen, um rechenintensive Probleme mit Hilfe von schnellen Cloud-GPUs, Netzwerkleistung, großen Mengen an Arbeitsspeicher und schnellem Speicher auszuführen.
- NVIDIA DeepStream und AWS IoT Greengrass: Mit DeepStream können Teams bei der Arbeit mit IoT-Geräten die Beschränkungen hinsichtlich Größe und Komplexität von ML-Modellen überwinden. Außerdem kann AWS IoT Greengrass die AWS-Cloud-Services auf NVIDIA-basierte Edge-Geräte erweitern.
- NVIDIA Omniverse: Bietet Teams eine Computing-Plattform für die Entwicklung von 3D-basierten Workflows und Anwendungen mit realitätsnaher Simulation und Verständnis. Es hilft auch, die Zusammenarbeit und Aspekte wie Fernüberwachung oder virtuelles Prototyping zu verbessern.
- Virtuelle Workstations: Die AWS Cloud-Lösungen bieten auch leistungsstarke virtuelle Workstations, die von NVIDIA betrieben werden. Teams können sie für komplexe Videobearbeitung, 3D-Modellierung und KI-Entwicklung nutzen.
AWS-Preise
AWS bietet eine kostenlose Stufe, mit der Sie die Cloud GPU-Services testen können. Für ein genaues Angebot wenden Sie sich bitte an den Vertrieb.
3. Hyperstack
Hyperstack ist eine hochmoderne GPU-as-a-Service (GPUaaS) Plattform, mit der Benutzer mühelos Workloads in der Cloud bereitstellen können. Unter der Haube nutzt Hyperstack die neueste NVIDIA-Hardware. Außerdem ist es im Vergleich zu öffentlichen Cloud-Anbietern wie AWS und Google Cloud günstiger.
Mit Hyperstack zahlen Sie nur für das, was Sie verbrauchen, was es zu einer wirtschaftlichen Wahl für Unternehmen jeder Größe macht. Die Plattform bietet hervorragende Geschwindigkeit und Leistung durch ihre virtuellen Maschinen, die für rechenintensive Aufgaben optimiert sind.
Hyperstack richtet sich an ein breites Spektrum von Nutzern, von Technikbegeisterten und KMUs bis hin zu großen Unternehmen und Managed Service Providern (MSPs). Diese Skalierbarkeit ist eine direkte Folge der Einfachheit und Benutzerfreundlichkeit von Hyperstack.
Die Plattform wird mit 100 % erneuerbarer Energie betrieben und bietet gleichzeitig eine erstklassige Leistung. Im Rahmen von NVIDIAs Inception-Programm unterstützt Hyperstack auch einige der vielversprechendsten KI-Startups und bietet ihnen GPU-Beschleunigung auf Unternehmensniveau. Das Unternehmen verfügt über Rechenzentren in Nordamerika und Europa.
Damit ist Hyperstack die ideale Wahl für Unternehmen, die eine leistungsstarke, skalierbare GPU-Infrastruktur nutzen und gleichzeitig einen Beitrag zu einer nachhaltigeren Zukunft leisten möchten.
Hyperstack Preisgestaltung
Die Preise von Hyperstack hängen von der Wahl Ihres GPU-Modells ab. Derzeit stehen 9 GPUs zur Auswahl, darunter das Modell Nvidia H100 SXM 80 GB, das bei $2,25/Stunde beginnt.
4. Seeweb
Seeweb unterstützt Sie bei der Verwaltung von KI- und Machine Learning-Projekten mit seinem Arsenal an Cloud-GPU-Services. Mit Seeweb können Sie mit zahlreichen Anwendungsfällen arbeiten, darunter NLP, VDI, Big Data, Videoverarbeitung, CUDA-Anwendungen, Genomik, seismische Analysen und mehr.

Seeweb hat seinen Sitz in Italien und verfügt über Rechenzentren in der gesamten Europäischen Union, um den GDPR-konformen Datenschutz und minimale Latenzzeiten zu gewährleisten. Außerdem bietet es mit seiner dedizierten Hardware eine überragende Leistung und hält die Kosten mit seiner stundenweisen und bedarfsabhängigen Abrechnung wirtschaftlich.
Seeweb verfügt über einen einsatzbereiten Technologie-Stack, der auf leistungsstarken Grafikkarten basiert, darunter NVIDIA A100, Quadro RTX A6000, RTX6000, A30 (MIG) und L4.
Die IaC (Terraform)-Unterstützung von Seeweb ermöglicht eine nahtlose Verwaltung der Infrastruktur, indem Sie Ihre GPU-Ressourcen über Code definieren und steuern können. Außerdem lässt sich die Plattform in Kubernetes integrieren und ermöglicht so eine optimierte Container-Orchestrierung, um unterschiedliche Arbeitslasten effektiv zu bewältigen.
Darüber hinaus nutzt Seeweb erneuerbare Energieressourcen und engagiert sich mit seinen DNSH- und ISO 14001-Zertifizierungen für ökologische Nachhaltigkeit.
Im Hinblick auf Sicherheit und Datenschutz ist die Cloud-Infrastruktur von Seeweb nach ISO/IEC 27001, 27017, 27018 und 27701 zertifiziert und damit ideal für das Hosting sensibler Gesundheits-, Finanz- und anderer Geschäftsdaten.
Die Plattform bietet eine Betriebszeitgarantie (SLA) von 99,99%, ständige Überwachung, technischen Support rund um die Uhr (24/7/365) und Schutz vor Internet-Bedrohungen wie DDoS-Angriffen.
Seeweb Preisgestaltung
Seeweb bietet die folgenden Preise an:
- Cloud Server GPU: Zugriff auf mehrere GPUs (CS GPU L4, CS GPU L40S, etc.) mit Preisen ab 0,38 €/Stunde (279 €/Monat).
- Serverlose GPU: Zugriff auf mehrere GPUs (H100, A100, usw.) mit Preisen ab 0,42 €/Stunde.
- Cloud Server NPU: Zugriff auf CS NPU1 und CS NPU 2 zu Preisen ab 0,07 €/Stunde.
5. IBM Cloud
IBM Cloud bietet Flexibilität, Leistung und GPU-Optionen, die von NVIDIA unterstützt werden. Sie bietet eine nahtlose Integration mit der IBM Cloud-Architektur, Anwendungen und APIs sowie ein verteiltes Netzwerk von Rechenzentren auf der ganzen Welt.
Die Plattform nutzt NVIDIA GPUs zur Ausführung von Aufgaben, einschließlich traditioneller KI, HPC und generativer KI. Mit IBM Cloud können Sie mithilfe der optimierten Infrastruktur für KI-Workflows trainieren, feinabstimmen und Inferenzen durchführen. Die KI-Infrastruktur von IBM bietet Zugang zu zahlreichen Grafikprozessoren, darunter NVIDIA L4, L40S und Tesla V100, mit 64 bis 320 GB RAM und einer Bandbreite von 16 bis 128 Gbit/s.
IBM Cloud bietet einen hybriden Design-Stack für die KI-Bereitstellung mit Zugriff auf KI-Assistenten, KI-Plattform, Datenplattform, Hybrid-Cloud-Plattform und GPU-Infrastruktur.
IBM Cloud Preisgestaltung
IBM Cloud bietet ein praktisches Tool zur Preiskalkulation. Der günstigste Preis für GVP V100 liegt bei $3,024/Stunde, wobei Sie Zugang zu 8 vCPUs, 64 GB RAM und 16 Gbps Bandbreite erhalten.
6. Latitude.sh
Latitude.sh wurde speziell entwickelt, um KI- und Machine-Learning-Workloads zu beschleunigen. Angetrieben von NVIDIAs H100-GPUs bietet die Latitude.sh-Infrastruktur bis zu 2x schnelleres Modelltraining im Vergleich zu konkurrierenden GPUs wie dem A100.
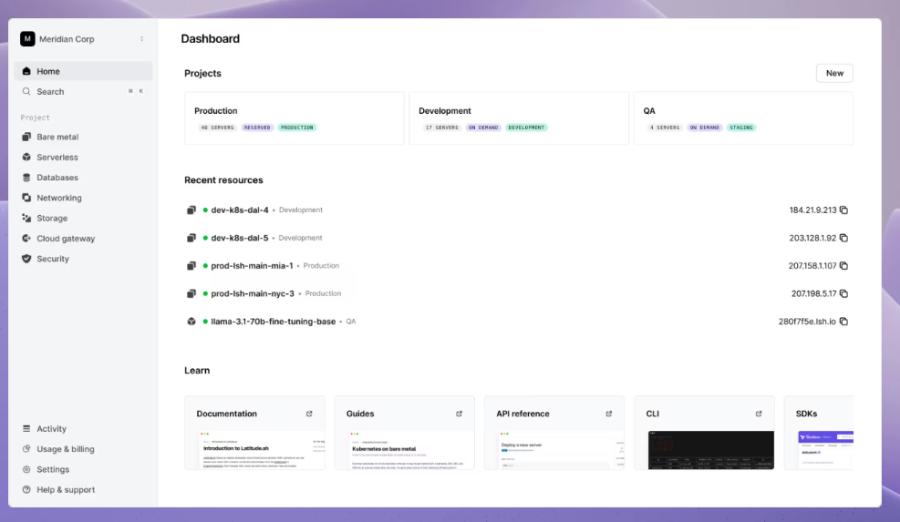
Wenn Sie sich für Latitude.sh entscheiden, können Sie hochleistungsfähige dedizierte Server an 18 globalen Standorten (z.B. Sydney, Frankfurt, Tokio und anderen) einsetzen und so minimale Latenzzeiten und optimale Leistung gewährleisten.
Jede Instanz ist für KI-Workloads optimiert und wird mit Deep Learning-Tools wie TensorFlow, PyTorch und Jupyter vorinstalliert.
Der API-first-Ansatz von Latitude.sh vereinfacht die Automatisierung und macht die Integration mit Tools wie Terraform mühelos. Mit dem intuitiven Dashboard von Latitude.sh können Sie mit nur wenigen Klicks Ansichten erstellen, Projekte verwalten und Ressourcen hinzufügen.
Latitude.sh Preisgestaltung
Die Preise für die Cloud-GPUs von Latitude.sh beginnen bei $3/Stunde, und Sie erhalten Zugang zu 1 x NVIDIA H100 80 GB, 2 x 3,7 TB NVME und 2 x 10 Gbps Netzwerk.
7. Genesis Cloud
Genesis Cloud ist ein erstklassiger KI-Cloud-Anbieter, der erschwinglich, äußerst zuverlässig und sicher ist. Seine beschleunigte GPU-Cloud ist auch günstig, mit Preisen von bis zu 80% im Vergleich zu herkömmlichen Clouds.
Ihre Genesis Enterprise AI Cloud bietet Unternehmen eine End-to-End-Plattform für maschinelles Lernen und fortschrittliches Datenmanagement. Sie haben auch Zugang zu vielen effizienten Rechenzentren weltweit, mit denen sie zusammenarbeiten, um eine breite Palette von Anwendungen anzubieten.
Genesis Cloud bietet umfangreiche GPU-Optionen, wie den HGX H100 und die kommenden NVIDIA Blackwell-Architektur-GPUs, darunter B200, GB200 und GB200 NVL72.
Um optimale Effizienz zu gewährleisten, bieten sie außerdem:
- KI-optimierte Speicherlösungen ohne Ingress- oder Egress-Gebühren.
- Schnelle, skalierbare und elastische Netzwerke für KI mit Multi-Node-Unterstützung.
- Tier 3-Rechenzentren mit einer Betriebszeitgarantie von 99,9%.
- Besserer Datenschutz und mehr Sicherheit mit ISO270001-Zertifizierung.
- 100% grüne Energie und niedriger PUE-Wert zum Schutz der Umwelt und zur Einsparung von Geschäftskosten.
Genesis Cloud-Preise
Der Preis von Genesis Cloud ist wie folgt.
| Plan | Stündlicher Preis | Angebote |
|---|---|---|
| Inferenz-Workload | Beginnt bei $0.20/h | Sie haben die Möglichkeit, aus einer Vielzahl von GPUs zu wählen. |
| NVIDIA HGX H100/H200 | Beginnt bei $2.00/h | Ideal für langfristige Verträge mit individuellen Konfigurationen. |
8. Paperspace CORE
Paperspace CORE bietet eine beschleunigte Recheninfrastruktur der nächsten Generation mit einem schnellen Netzwerk, 3D-App-Unterstützung und sofortigem provisorischem und vollem API-Zugang. Außerdem ist es einfach zu bedienen und bietet unkomplizierte Interferenzen für das Onboarding.

Mit Paperspace CORE können Sie KI/ML-Modelle mit NVIDIA H100 GPUs auf DigitalOcean erstellen und ausführen (DigitalOcean hat Paperspace Core im Jahr 2023 übernommen).
Zu den wichtigsten Funktionen von Paperspace CORE gehören die folgenden:
- Bietet eine konfigurationsfreie Notebook-IDE mit Kollaborationsfunktion.
- Sparen Sie bis zu 70% Rechenkosten im Vergleich zu den großen öffentlichen Clouds.
- Bietet Abstraktion der Infrastruktur mit Job Scheduling, Ressourcenbereitstellung und mehr.
- Bietet Einblicke zur Verbesserung des Gesamtprozesses, einschließlich Berechtigungen, Teamauslastung und mehr.
- Leistungsstarke Verwaltungskonsole, mit der Sie Aufgaben wie das Hinzufügen von VPN und die Verwaltung von Netzwerkkonfigurationen schnell erledigen können.
Paperspace CORE Preisgestaltung
Paperspace CORE bietet Platform- und Compute-Tarife an. Die Plattform-Tarife sind unten aufgeführt.
| Plan | Monatlicher Preis | Angebote |
|---|---|---|
| Kostenlos | $0 | Ideal für Anfänger, die öffentliche Projekte und einfache Instanzen nutzen möchten. |
| Pro | $8 | Ideal für ML/AI-Ingenieure und Forscher mit privaten Projekten und Instanzen mittlerer Größe. |
| Wachstum | $39 | Ideal für Teams, Forschungsgruppen und Startups, die viel Speicherplatz und High-End-Instanzen benötigen. |
Sie bieten auch On-Demand-Rechenleistung zu Preisen zwischen $0,76/Stunde (A4000) und $2,24/Stunde (H100).
9. OVHcloud
OVHcloud bietet Cloud-Server, die für die Verarbeitung massiv paralleler Arbeitslasten ausgelegt sind. Die GPUs haben viele Instanzen mit NVIDIA Tesla V100 Grafikprozessoren integriert, um die Anforderungen von Deep Learning und Machine Learning zu erfüllen.

Sie helfen bei der Beschleunigung von Grafik-Computing und künstlicher Intelligenz. OVHcloud arbeitet mit NVIDIA zusammen, um die beste GPU-beschleunigte Plattform für High-Performance-Computing, KI und Deep Learning anzubieten.
Die Plattform bietet einen vollständigen Katalog für die einfache Bereitstellung und Verwaltung von GPU-beschleunigten Containern. Entwickler können eine von vier Grafikkarten direkt über PCI Passthrough für die Instanzen verwenden, ohne dass eine Virtualisierungsschicht erforderlich ist, um die gesamte Leistung für Ihre Zwecke bereitzustellen.
Was die Zertifizierungen angeht, so sind die Dienste und Infrastrukturen von OVHcloud nach ISO/IEC 27017, 27001, 27701 und 27018 zertifiziert. Die Zertifizierungen zeigen, dass OVHcloud über ein Informationssicherheitsmanagementsystem (ISMS) verfügt, um Schwachstellen zu verwalten, Geschäftskontinuität zu implementieren, Risiken zu verwalten und ein Datenschutzmanagementsystem (PIMS) zu implementieren.
Unternehmen mit hoher Rechenleistung können die Cloud GPU von OVHcloud für:
- Bilderkennung, Klassifizierung von Daten aus Bildern.
- Situationsanalyse in Echtzeit, z. B. bei selbstfahrenden Autos und der Analyse des Internet-Netzwerkverkehrs.
- Interaktionen, wie Maschinen über Ton und Video mit Menschen kommunizieren.
- Trainieren und optimieren Sie KI-Modelle mit GPU-Computing-Ressourcen.
OVHcloud Preise
Es gibt keine festen Preispläne für OVHcloud. Um ein maßgeschneidertes Angebot zu erhalten, müssen Sie das Vertriebsteam mit Ihren Anforderungen kontaktieren.
10. RunPod
RunPod ist eine All-in-One-Cloud, mit der Ingenieure problemlos KI-Modelle entwickeln, trainieren und skalieren können. Sie bietet eine global verteilte GPU-Cloud in 30 Regionen, die Ihnen die notwendige Infrastruktur zum Trainieren, Erstellen und Bereitstellen von ML-Modellen bietet.

Mit RunPod können Sie GPU-Pods in Sekundenschnelle aufsetzen und einsetzen. Die 50 Vorlagen, wie PyTorch, Docker und andere, bieten Ihnen einsatzbereite Maschinen. Es unterstützt auch benutzerdefinierte Container – alles über eine einfach zu bedienende CLI.
Zu den wichtigsten Funktionen von RunPod gehören:
- Keine Gebühren für den Ausstieg/Einstieg.
- 99.99% Betriebszeit-Garantie.
- Globale Interoperabilität.
- Günstiger Netzwerkspeicher mit 10 PB Kapazität.
- Unterstützt serverlose ML-Inferenz-Skalierung.
- Erhalten Sie Echtzeit-Analysen zur Nutzung aller Endpunkte.
- Einfaches Debuggen von Endpunkten mit Analyse der Ausführungszeit und Echtzeitprotokollen.
- Bietet automatische Skalierung in 8 Regionen.
- Unternehmenstauglich mit sicherer Infrastruktur und erstklassiger Compliance.
RunPod-Preise
RunPod bietet ein Pay-per-Use-Modell. Um die Cloud-GPUs von RunPod zu nutzen, müssen Sie ein Guthaben hinzufügen oder die Zahlungen über eine Kreditkarte automatisieren. Außerdem gibt es ein Ausgabenlimit. Sie müssen ein Konto einrichten und Ihre Anforderungen eingeben, um die genauen Kosten zu erfahren.
11. Lambda GPU
Lambda GPU Cloud bietet NVIDIA-GPUs zum Trainieren von Deep Learning-, ML- und KI-Modellen und zur einfachen Skalierung von einer Maschine auf die Gesamtzahl der VMs.
Es bietet einen kompletten Lambda Stack mit der gesamten erforderlichen KI-Software. Dazu gehören vorinstallierte Frameworks wie Ubuntu, PyTorch und NVIDIA CUDA sowie die neueste Version des Lambda Stack, die CUDA-Treiber und Deep Learning Frameworks enthält. Außerdem haben Sie mit einem Klick Zugriff auf Jupyter vom Browser aus.
Zu den wichtigsten Funktionen von Lambda GPU gehören:
- NVIDIA H100s auf Abruf.
- Kommt mit 1-Klick-Clustern mit Quantum-2 InfiniBand und NVIDIA H100 Tensor Core GPUs.
- Verwenden Sie SSH direkt mit einem der SSH-Schlüssel oder verbinden Sie sich über das Web-Terminal im Cloud-Dashboard für den direkten Zugriff.
- Unterstützt eine maximale Bandbreite von 10 Gbps zwischen den Knoten, ideal für Frameworks, die verstreutes Training unterstützen, wie z.B. Horovod.
- Einsparungen von bis zu 50% beim Computing mit reduzierten Cloud-TCO.
Lambda GPU-Preise
Lambda GPU bietet GPUs auf Abruf und reserviert. Die Preise für Cloud-GPUs auf Abruf reichen von $0,50/GPU/Stunde (NVIDIA Quadro RTX 6000) bis $2,99/GPU/Stunde (8x NVIDIA H100 SXM). Für reservierte GPUs müssen Sie den Vertrieb kontaktieren.
12. TensorDock
TensorDock ist die ideale Wahl für Unternehmen, die nach erschwinglichen GPU-Servern suchen. Es bietet GPU-Ressourcen auf Abruf zu niedrigen Preisen und die Möglichkeit, den Server in 30 Sekunden zu erstellen.

Unternehmen können außerdem aus der großen Auswahl von 45 verfügbaren GPU-Modellen wählen, darunter die preisgünstige RTX 4090 und hochwertigere Hochleistungs-GPUs wie die HGX H100s.
Außerdem unterstützt TensorDock KVM-Virtualisierung mit vollständigem Root-Zugriff. Es unterstützt auch Windows 10, Multithreading und eine optimierte End-to-End VM-Bereitstellungsgeschwindigkeit.
Zu den wichtigsten Funktionen von TensorDock gehören:
- Zugang zu VM-Vorlagen wie Docker für eine einfache Bereitstellung.
- Bis zu 30.000 GPUs sind an 100 Standorten verfügbar.
- Gut dokumentierte API.
- Ausgezeichnete Zuverlässigkeit mit einer Betriebszeit von 99,99%.
- Sofort vorkonfigurierte VMs, die in Sekundenschnelle bereitgestellt werden können.
TensorDock Preisgestaltung
TensorDock bietet Cloud-GPUs für Deep Learning, Rendering und Consumer-Grade-Nutzung. Die Preise reichen von 0,08 $/Stunde (GTX 1070) bis 2,42 $/Stunde (H100 SXM5).
13. Ori
Ori ist ein KI-nativer GPU-Cloud-Anbieter, der kostengünstige, anpassbare und benutzerfreundliche Dienste anbietet. Er bietet eine Reihe von Diensten an, darunter Bare Metal und Serverless Kubernetes.

Ori bietet Zugang zu den gängigen NVIDIA GPU-Architekturen, einschließlich NVIDIA B100, B200 und GB200. Die Plattform hat auch behauptet, dass sie in naher Zukunft die NVIDIA Blackwell Architektur in ihre Reihen aufnehmen wird.
Zu den wichtigsten Funktionen von Ori Cloud gehören:
- Speziell entwickelte, optimierte GPU-Server, ideal für eine breite Palette von KI/ML-Anwendungen.
- Ein breites Spektrum an GPU-Ressourcen, die für die Bereitstellung verfügbar sind.
- Bietet Zugang zu verschiedenen Compute-Varianten, einschließlich serverlosem Kubernetes und Bare Metal.
Ori Preisgestaltung
Die Preise für die Ori GPU Cloud reichen von $0,95/Stunde (NVIDIA V100s) bis $3,80/Stunde (NVIDIA H100 SXM). Es werden nur On-Demand-Pläne angeboten.
14. Nebius
Mit Nebious können Sie KI-Modelle erstellen, abstimmen und ausführen und dabei die top-verwaltete NVIDIA GPU-Infrastruktur nutzen, einschließlich der neuesten H100/H200 GPU-Cluster.

Es bietet eine umfassende KI-Plattform, die Folgendes umfasst:
- KI-Plattform und Marktplatz: Listet beliebte MLOps-Lösungen auf, darunter Kuberflow, Airflow, Ray und andere. Dazu gehören auch Managed PostgreSQL, Managed MLflow und Managed Spark.
- KI-Cloud: Bietet Zugang zu skalierbaren Clustern mit Speicher-, Netzwerk- und Orchestrierungslösungen, einschließlich GPU-Clustern, verwalteten K8s, Compute, Storage und mehr.
- Hardware und Rechenzentrum: Zugriff auf ein energieeffizientes Rechenzentrum, ein 3,2 Tbit/s InfiniBand-Netzwerk und NVIDIA-GPUs (H100, H200, L40s).
Außerdem können Sie die Infrastruktur als Code über CLI, API und Terraform verwalten. Nebius bietet außerdem Zugang zu 24/7-Support durch Experten.
Nebius Preisgestaltung
Die Preise von Nebius reichen von $1,18/Std. (12-Monats-Reserve L40s) bis $3,5/Std. (6-Monats-Reserve H200).
Was sind die Vorteile von Cloud GPU?
Es gibt 5 Hauptvorteile der Nutzung von Cloud-GPUs, wie unten dargestellt.
- Verbesserte datenintensive Aufgaben: Cloud-GPUs geben Unternehmen (insbesondere in kritischen Echtzeit-Datenverarbeitungsbranchen wie dem Gesundheitswesen) die Möglichkeit, datenintensive Aufgaben mit verbesserter Leistung zu bewältigen. So können Cloud-GPUs beispielsweise komplexe Big-Data-Analysen, maschinelles Lernen und KI bewältigen. Dies führt zu einer schnelleren und besseren Entscheidungsfindung und einem Wettbewerbsvorteil gegenüber der Konkurrenz.
- Kosteneffizienz: Mit Cloud GPU entfällt die Notwendigkeit, eine GPU-Infrastruktur aufzubauen, zu verwalten und zu warten, was die Kosteneffizienz für wachsende Unternehmen sicherstellt. Die meisten Cloud GPU-Anbieter bieten Pay-as-you-go-Preise an, was die Kosten weiter senkt. Außerdem müssen sich Unternehmen keine Gedanken über Upgrades oder steigende Energiekosten machen.
- Schnellere Markteinführung: Durch den Einsatz von Cloud-GPUs können Unternehmen ihre Produkte/Dienstleistungen schneller auf den Markt bringen.
- Verbesserte Skalierbarkeit: Wachsende Unternehmen können von Skalierungsoptionen profitieren, da die meisten Cloud-GPUs eine horizontale und vertikale Skalierung mit der Option bieten, die Leistung bei Bedarf zu reduzieren.
- Verbesserte Zusammenarbeit und Zugänglichkeit: Cloud-basiertes GPU-Computing bringt Teams zusammen, um gemeinsam an Problemen zu arbeiten, ohne geografische Einschränkungen.