Daten sind ein wichtiges Gut, das den Betrieb, die Effizienz, das Kundenerlebnis und die Entscheidungsfindung verbessern kann.
Zu diesem Zweck erzeugen, sammeln und speichern Unternehmen und Organisationen riesige Datenmengen aus verschiedenen Quellen. Da die Datenmengen jedoch zunehmen, kann es eine Herausforderung sein, die nützlichsten Informationen zu extrahieren, insbesondere wenn die Informationen ungeordnet und über verschiedene Standorte verstreut sind.
Eine Möglichkeit, diese Herausforderungen zu überwinden, besteht darin, Daten in einem geeigneten Datenspeicher zu speichern. So erhalten Sie eine einheitliche Datenquelle mit Informationen, die gefiltert und durchsuchbar sind und für Analysen und Berichte zur Verfügung stehen.
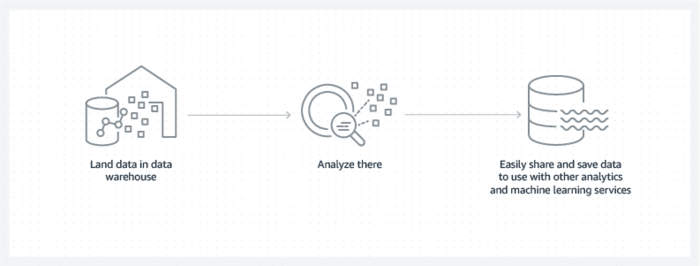
In diesem Artikel werden wir das Daten-Repository definieren und seine Vorteile, die verschiedenen Typen und bewährte Verfahren kennenlernen.
Was ist ein Daten-Repository?
Ein Data Repository ist eine Bibliothek oder ein Archiv, das Daten zur Unterstützung von Analyse- und Berichtsfunktionen in der Forschung oder im Geschäftsbetrieb enthält. In der Praxis ist ein Datenspeicher ein allgemeiner Begriff, der sich auf den zentralen Ort bezieht, an dem die Daten gespeichert werden. Dabei kann es sich um ein einzelnes Speichergerät oder um eine Reihe von Datenbanken handeln, die sich über verschiedene Geräte erstrecken.
In einem typischen Betrieb sammeln Unternehmen möglicherweise unterschiedliche Daten aus Verkaufsstellen, CRM, ERP, Tabellenkalkulationen und anderen Quellen. Diese Daten werden dann in ein Daten-Repository übertragen, wo sie sortiert, bereinigt, validiert, formatiert, organisiert und gespeichert werden.
In der Regel können Unternehmen bestimmte Datentypen für Analyse- oder Berichtszwecke isolieren und im Repository speichern. Und da es sich um eine langfristige Speicherung handelt, können sie die Daten mehrmals wiederverwenden, um verschiedene Arten von Analysen durchzuführen.
Ein typisches Daten-Repository besteht aus drei Hauptebenen.
- Datenquellen-Schicht
- Datenverarbeitungsschicht oder Warehouse
- Die Zielanwendungsschicht, die z.B. aus Benutzern, Analysten und Berichterstattern besteht
Warum brauchen Sie ein Data Repository?
Daten sind über Kundenkontaktpunkte, das Internet, Forschung, Marketing, Anwendungen und viele andere Quellen verfügbar. Sie liegen jedoch in der Regel im Rohformat vor, und Unternehmen benötigen geeignete Tools, um nützliche Informationen zu extrahieren, die ihnen helfen, ihre Ziele zu erreichen. Eine gute Praxis ist die Einrichtung eines Datenspeichers, um die Daten zu organisieren und sie für Analysen und andere Anwendungen verfügbar zu machen.
Das Repository ermöglicht es autorisierten Benutzern, mit Hilfe von Such-, Abfrage- und anderen Tools einfach und schnell auf Daten zuzugreifen, sie abzurufen und zu verwalten. So können Benutzer und Unternehmen Analysen, Recherchen, gemeinsame Nutzung und Berichterstattung durchführen. So können sie ihre Abläufe optimieren und bessere datengestützte Entscheidungen treffen.
Angenommen, Sie möchten feststellen, welche Abteilung in Ihrem Unternehmen die meisten Betriebskosten verursacht. Sie können einen Datenspeicher für die Mieten, die Sicherheit, die Energiekosten, die Versorgungsleistungen und andere Ausgaben einrichten. Wenn Sie die Daten an einem zentralen Ort aufbewahren, können Sie die Abteilung mit den meisten Ausgaben analysieren und identifizieren und somit fundiertere und gezieltere Entscheidungen treffen, wenn Sie die Kosten senken wollen.
Obwohl Data Repositories in der Regel von Forschungs- und Wissenschaftseinrichtungen genutzt werden, sind sie auch für allgemeine Organisationen und Unternehmen geeignet.
Vorteile von Data Repositories
Heute nutzen die meisten Organisationen Daten-Repositories als Mittel zur effizienteren Verwaltung und Nutzung ihrer Daten. Das Konzept der Daten-Repositories erfreut sich immer größerer Beliebtheit, da es einen einfachen Zugriff auf Informationen, deren Verwaltung, Analyse und Berichterstattung ermöglicht.
Weitere Vorteile sind:
- Bessere Sichtbarkeit: Die Speicherung von Daten an einem zentralen, zuverlässigen Ort macht sie jederzeit zugänglich. Wenn Sie die Daten dagegen in nicht gemeinsam genutzten Anwendungen oder lokalen Silos aufbewahren, sind sie nur für eine oder wenige Personen zugänglich. Dies verringert die Sichtbarkeit und Nutzbarkeit der Daten. Infolgedessen benötigen Teams möglicherweise mehr Zeit und zusätzliche Ressourcen, um auf die Daten zuzugreifen.
- Einfacher Zugang zu nützlichen Daten: Daten in digitaler Form sind leicht zu durchsuchen und zugänglich. Durch das Hinzufügen von Metadaten zu den Daten im Repository können die Benutzer die Daten viel besser verstehen und nutzen.
- Einfache Sicherung von Daten und Einhaltung von Standards: Es ist viel einfacher, Daten an einem zentralen Ort zu schützen, als wenn sie an verschiedenen Orten verstreut sind. Außerdem ist es mit einem Datenspeicher einfacher und weniger kostspielig, verschiedene gesetzliche Standards einzuhalten.
- Wiederverwendbare Daten: Das Daten-Repository enthält eine Vielzahl von Daten für Analysen und Berichte. Analysten und Forscher können dieselben Daten verwenden, um verschiedene Arten von Berichten zu erstellen.
- Bietet nützliche Einblicke: Die Verwendung geeigneter Tools auf Daten-Repositories ermöglicht Ihnen eine mehrdimensionale Sicht auf die Daten, im Gegensatz zur Analyse von Informationen an verschiedenen Orten.
Arten von Daten-Repositories
Data Repository ist ein allgemeiner Begriff, der sich auf das Informationsarchiv bezieht. Je nach Zielanwendung oder Zielsetzung gibt es jedoch unterschiedliche Repositories. Im Folgenden finden Sie die vier wichtigsten Arten von Datenspeichern.
#1. Data Warehouse
Das Data Warehouse ist eine der größten Arten von Datenspeichern. In dieser Kategorie können Unternehmen Daten aus verschiedenen Quellen und in unterschiedlichen Formaten sammeln. Ein typisches Data Warehouse speichert große Mengen von Daten aus verschiedenen Quellen. Seine Struktur ermöglicht es Unternehmen, die Daten einfach zu organisieren, zu analysieren und Berichte zu erstellen. Dies ermöglicht es den Teams, bessere datengestützte Entscheidungen zu treffen.
Die Informationen in einem Data Warehouse können mehrere Themen abdecken und werden in der Regel bereinigt, gefiltert und für eine bestimmte Verwendung definiert.
#2. Data Mart

Ein Data Mart ist ein abgetrennter Bereich eines Data Warehouse. Der themenorientierte Datenspeicher speichert eine Teilmenge von Daten, die sich auf eine bestimmte Geschäftsfunktion oder Abteilung konzentrieren, z.B. Finanzen, Support, Einkauf oder Marketing.
In der Regel ist ein Data Mart kleiner. Dies trägt zur Beschleunigung von Geschäftsprozessen bei, da der Zugriff auf die relevanten Daten innerhalb eines kürzeren Zeitraums möglich ist. Dies ist ein kostengünstiges Mittel, um schnell umsetzbare Erkenntnisse zu gewinnen.
#3. Data Lake
Ein Data Lake ist ein großes Archiv, das Daten in jeder Form enthält. Dazu gehören unstrukturierte, halbstrukturierte und strukturierte Daten. Er verwendet Metadaten, um die weitgehend unstrukturierten Daten zu kategorisieren und zu kennzeichnen. Ein Data Lake bietet vollständige Kontrolle und eine bessere Datenverwaltung als ein Data Warehouse.
#4. Datenwürfel
Data Cubes sind mehrdimensionale Datenspeicher, die sich eher auf komplexe Daten konzentrieren, die von den anderen Typen nicht unterstützt werden. Sie haben drei oder mehr Dimensionen, die jeweils ein bestimmtes Merkmal darstellen, z.B. tägliche, monatliche oder jährliche Kosten oder Umsätze. Data Lakes ermöglichen es Forschern, Daten unter verschiedenen Gesichtspunkten zu bewerten.
Lesen Sie auch: Data Lake vs. Data Warehouse: Was sind die Unterschiede?
Bewährte Praktiken für die Entwicklung und Pflege von Data Repositories
Ein typisches Daten-Repository verfügt über Tools zum Speichern, Verwalten und Sichern der Informationen. Es verfügt über Funktionen wie Zugriffskontrolle, Indizierung, Komprimierung, Berichterstattung, Verschlüsselung und mehr.
Bei der Konzeption und Erstellung eines Datenspeichers müssen Sie verschiedene Hardware- und Softwarefaktoren berücksichtigen und mit Datenpipeline-Ingenieuren, Datenanalysten und anderen Experten zusammenarbeiten. Je nach Bereich müssen Sie Branchenexperten hinzuziehen. Wenn Sie zum Beispiel ein Repository für klinische Daten erstellen, werden Sie mit Ärzten und anderen medizinischen Fachleuten zusammenarbeiten.
Eine effektive Datenverwaltungsstrategie umfasst Folgendes:
✅ Organisieren von Dateien
✅ Sichere Speicherung und angemessene Zugriffskontrolle
✅ Versions- und Dokumentationskontrolle
✅ Unterstützt die Zusammenarbeit
✅ Klare Richtlinien für die Wiederverwendung und gemeinsame Nutzung
✅ Archivierung und Aufbewahrung der Daten für eine spätere Verwendung oder Referenz.
Die Schritte zur Konzeption, Erstellung und Verwaltung eines Datenspeichers können sich zwar von Branche zu Branche oder von Unternehmen zu Unternehmen unterscheiden, doch im Folgenden finden Sie einige bewährte Verfahren.
Beschränken Sie den Umfang in der Anfangsphase
Zu Beginn empfiehlt es sich, den Umfang des Datenspeichers zu begrenzen. Eine Strategie besteht darin, eine kleinere Anzahl von Themenbereichen und Datensätzen zu verwenden und den Umfang schrittweise zu erhöhen.
Wählen Sie die richtigen Tools
Tools sind entscheidend für die Erstellung, Speicherung, gemeinsame Nutzung, Analyse und Verwaltung von Datenbeständen. Die Datenqualität und -analyse hängt also von den von Ihnen verwendeten Tools ab. Da es verschiedene Arten von Tools mit unterschiedlichen Funktionen gibt, sollten Sie sicherstellen, dass Ihre Wahl Ihren Anforderungen entspricht.
Automatisieren Sie so viele Prozesse wie möglich
Wenn möglich, automatisieren Sie die Lade- und Wartungsaufgaben, um die Effizienz zu steigern, Zeitverluste zu vermeiden und das Fehlerrisiko zu verringern.
Entwerfen Sie ein flexibles und skalierbares Repository
Um den wachsenden Datenmengen, den sich entwickelnden Datentypen und -formaten gerecht zu werden, empfiehlt es sich, ein skalierbares Repository zu entwerfen und zu erstellen. Ein solches System wird den aktuellen Anforderungen gerecht und lässt sich so skalieren, dass es in Zukunft weitere Datentypen und -mengen unterstützen kann. Außerdem sollte es flexibel sein, um mit verschiedenen Tools und neuen Technologien arbeiten zu können.
Schützen Sie die Daten zu jeder Zeit
Sorgen Sie für die Integrität und Sicherheit der Daten, da Unstimmigkeiten, Kompromisse oder Diebstahl zu ungenauen Analyseergebnissen und schlechten Entscheidungen führen können. Legen Sie angemessene Zugriffsregeln fest und erteilen Sie autorisierten Benutzern nur die Berechtigungen, die sie für die Erfüllung ihrer Aufgaben benötigen. Verschlüsseln Sie außerdem die Daten im Ruhezustand und bei der Übertragung. Ziehen Sie weitere Maßnahmen wie die Multi-Faktor-Authentifizierung in Betracht, um eine zusätzliche Schutzschicht zu schaffen.
Verwenden Sie Standard-Datenmodelle
Die Datenmodellierung hilft bei der Umwandlung von Daten in wertvolle Informationen, die Forscher und Führungskräfte besser verstehen können. Normalerweise sind die Informationen in einem Datenspeicher wiederverwendbar.
Unternehmen können dieselben Daten verwenden, um nützliche Informationen in verschiedenen Bereichen zu extrahieren. Daten haben viele Kontexte, je nachdem, wie sie in verschiedenen Prozessen und analytischen Anwendungen verwendet werden. Daher kann ein Unternehmen mehrere Datenmodelle verwenden, um verschiedenen analytischen Anforderungen gerecht zu werden.
Indizierung von Daten
Die Erstellung von Indizes für die Tabellen des Datenspeichers verbessert die Abfrageleistung und sollte zur Standardpraxis gehören. Er verbessert die Abfragegeschwindigkeit, indem er eine organisierte Nachschlagetabelle auf der Grundlage bestimmter Attribute und mit Einträgen, die auf bestimmte Datenorte verweisen, bereitstellt.
Die Indizierung von Daten-Repositories kann je nach Verwendung variieren. Sie kann leicht oder umfangreich sein, je nach Verwendung. Im Idealfall sollte sich die Indizierungsstrategie darauf konzentrieren, die ETL-Prozesse zu beschleunigen. Eine bewährte Vorgehensweise bei der Transformation der Daten besteht darin, sicherzustellen, dass der Index die erforderlichen Informationen liefert, ohne dass nützliche Daten fehlen und er unnötig groß ist.
Es ist auch wichtig, den Kompromiss zwischen der verbesserten Abfrageleistung des Datenspeichers und den damit verbundenen Gemeinkosten und Wartungskosten der Indizierung abzuwägen.
Lesen Sie auch: Die besten ETL-Tools für kleine und mittlere Unternehmen.
Beispiele für Daten-Repositories
Daten-Repositories fallen unter verschiedene Kategorien:
- Institutionelle Repositorien (IRs) für die Institutionen von Forschern, wie das Texas Data Repository der Texas A&M University Libraries.
- Disziplinäre oder domänenspezifische Repositorien (DRs): Diese sind domänenspezifisch und werden von einem Forscherkonsortium oder einer Fachorganisation betrieben, wie z.B. das Registry of Research Data Repositories (re3data) von DataCite und das Directory of Open Access Repositories (OpenDOAR), das aus mehreren akademischen Open-Access-Repositories besteht.
- Offene oder allgemein zugängliche Repositorien wie Dryad, Figshare und Harvard Dataverse.
Anwendungsfälle von Datenrepositorien
Fintech, Gesundheitswesen, E-Commerce, Lieferketten und andere Branchen können von der Nutzung von Daten-Repositories profitieren. Indem sie die großen Datenmengen, die sie sammeln und generieren, voll ausschöpfen, können sie bessere Erkenntnisse gewinnen, um ihre Dienstleistungen zu optimieren und bessere und schnellere Services zu liefern.
Klinische Forschung
Die klinische Forschung ist ein datenintensiver Bereich. Die optimale Nutzung der Daten trägt dazu bei, die Gesundheitsbranche in die richtige Richtung zu lenken. Die Analyse von Big Data ermöglicht es Wissenschaftlern und anderen Fachleuten, tief in klinische Studien einzudringen und Erkenntnisse zu gewinnen, die dazu beitragen, die Gesundheitsversorgung zu verbessern und Leben zu retten.
Finanzdienstleistungen

Die Finanzdienstleistungsbranche kann von der Analyse großer Datenmengen profitieren. Die Analyse liefert ihnen Erkenntnisse, die sie zur Verbesserung von Dienstleistungen, Effizienz und Erträgen nutzen können. Einige der Bereiche, in denen Finanzinstitute Daten-Repositories nutzen können, sind:
- Zur Erstellung von Finanzberichten durch Analyse der Daten von einem zentralen Ort aus.
- Ermöglicht KI-gestützte automatisierte Entscheidungsfindung.
Abschließende Worte
Daten sind ein wesentlicher Bestandteil der Entscheidungsfindung. Unternehmen, die große Datenmengen speichern, benötigen jedoch die richtigen Lösungen zum Sammeln, Speichern, Verwalten und Analysieren der Daten.
Zu diesem Zweck bietet ein Daten-Repository eine Lösung zur Konsolidierung und Verwaltung wichtiger Daten. Die Repositories ermöglichen es Unternehmen, Daten zu analysieren, Erkenntnisse zu gewinnen und bessere datengestützte Entscheidungen zu treffen.
Ein Daten-Repository bietet eine zentrale Speicherung verschiedener Arten von Informationen, jedoch in einer logischen Form, die den Zugriff, die Suche, die Analyse und die Verwaltung erleichtert. Außerdem hilft es Unternehmen, die Integrität und Qualität von Daten zu sichern, gemeinsam zu nutzen, zu pflegen und zu gewährleisten und die gesetzlichen Vorschriften einzuhalten.
Sehen Sie sich als nächstes die besten Datenmanagement-Tools für mittlere bis große Unternehmen an.