
Der Aufbau eines automatisierten Softwaresystems bedeutete über viele Jahre hinweg die Einrichtung mehrerer Server mit dedizierter CPU-Konfiguration, Arbeitsspeicher, Speicher und anderen Ressourcen. Als nächstes wurde ein Team von Administratoren gebildet, um diese Systeme zu verwalten. Dann übernahm das Entwicklungsteam die Infrastruktur und begann, Prozesse zu erstellen, die die Server miteinander verbinden.
Dieser Prozess kann kompliziert sein, weil viele verschiedene Gruppen zusammen auf ein gemeinsames Ziel hinarbeiten müssen. Diese Interessenkonflikte können dann zu einem Problem werden.
Es kann auch ziemlich kostspielig sein. Sie müssen dafür Administratoren auf Ihrer Gehaltsliste haben. Server, die ständig laufen, verbrauchen Ressourcen, obwohl sie nicht genutzt werden.
Um im Laufe der Zeit die beste Leistung aufrechtzuerhalten, benötigen Sie eine Auto-Scaling-Lösung, die die Serverressourcen automatisch skaliert.

Die Cloud-Plattform hat einen Vorteil: Sie ermöglicht es Ihnen, eine End-to-End-Architektur zu erstellen, ohne dass Sie Server-Cluster einrichten müssen. Aus der Sicht der Verwaltung gibt es nichts zu pflegen.
Dies ist eine kosteneffiziente Option für Startups und die MVP-Phase (Minimum Viable Product) von Projekten. Sie ist ein guter Ausgangspunkt, wenn es schwierig ist, die zukünftige Produktionslast und Benutzeraktivität vorherzusagen. Hier kann es eine Herausforderung sein, die Konfiguration von Cluster-Servern zu bestimmen.
Die Automatisierung von Prozessen durch serverlose Cloud-Dienste ist das, was die serverlose Architektur auszeichnet. Sie verbindet Dienste und erzeugt Ergebnisse, die denen herkömmlicher Cluster-Server ähneln.
Dies ist ein Beispiel für den Aufbau einer solchen Architektur, die nur native AWS-Services verwendet.
Aufgreifen der Services Serverless Flow
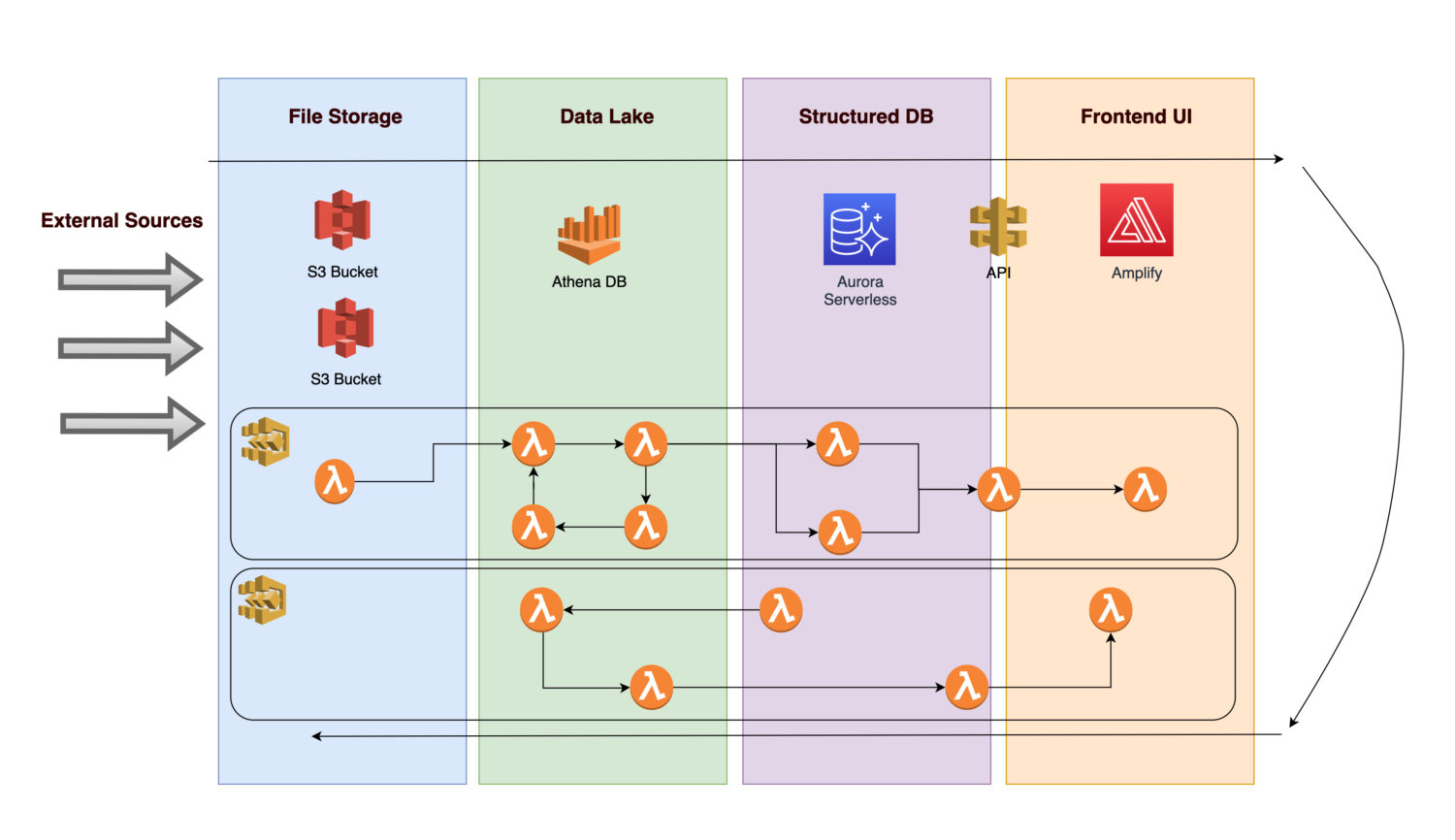
Stellen Sie sich vor, Sie möchten eine Plattform zum Sammeln verschiedener Daten und Bilder (oder Fotos) von der Infrastruktur konkreter Anlagen (dies kann jede Produktions- oder Versorgungsanlage sein) erstellen.
- Um spätere Analysen zu ermöglichen, müssen die eingehenden Daten zunächst erfasst werden.
- Nach der Anwendung von Geschäftsregeln speichert ein Back-End-Verfahren die berechneten Ergebnisse als normalisierte Informationen in einer relationalen Datenbank.
- Ein Anwendungs-Frontend, das normalisierte, saubere Daten anzeigt, ermöglicht es den Benutzern, die Ergebnisse zu betrachten.
Schauen wir uns an, welche Komponenten die Architektur umfassen könnte.
AWS S3-Buckets
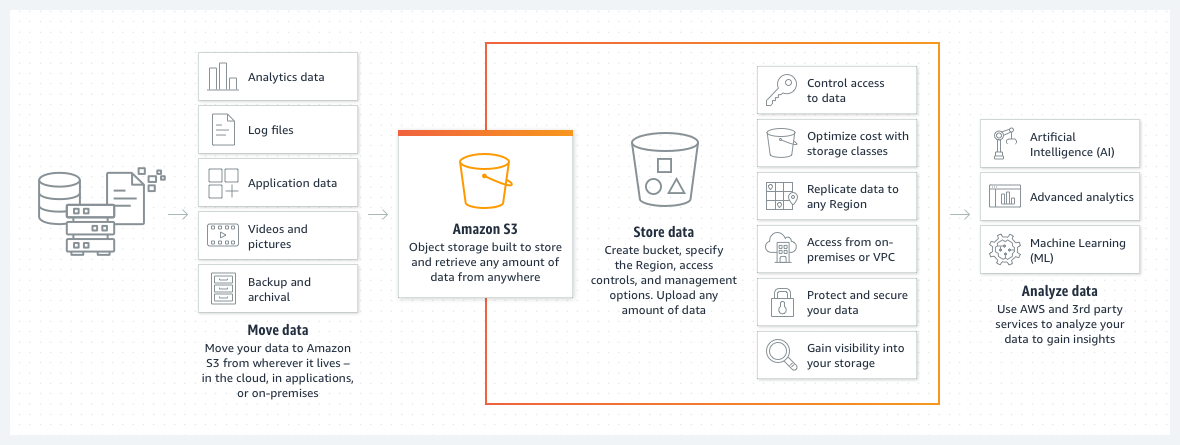
Amazon S3 Buckets sind eine großartige Möglichkeit, um Dateien oder Bilder in der AWS-Cloud zu speichern. Der Preis für den Speicherplatz in einem S3-Bucket ist bemerkenswert niedrig. Und durch die Einführung einer S3-Bucket-Lebenszyklusrichtlinie wird dieser Preis noch weiter gesenkt.
Eine solche Richtlinie verschiebt ältere Dateien automatisch in verschiedene Klassen von S3-Buckets, z. B. in ein Archiv oder einen tiefen Archivzugriff. Die Klassen unterscheiden sich dann auch in der Geschwindigkeit der Zugriffszeit, aber für alte Daten ist das weniger ein Problem. Sie dient hauptsächlich dem Zugriff auf die archivierten Daten im Falle eines dringenden Ereignisses und nicht für den normalen Betriebsbedarf.
- Sie können Ihre Daten in Unterordnern organisieren.
- Sie sollten entsprechende Berechtigungseinschränkungen festlegen.
- Fügen Sie den Buckets Tags hinzu, damit sie leicht zu identifizieren sind und für eine mögliche Verwendung innerhalb dynamischer S3-Bucket-Richtlinien.
- Der Bucket ist vom Design her serverlos. Er ist einfach ein Speicherplatz für Ihre Daten.
Ein S3-Bucket ist von Haus aus serverlos. Er ist einfach nur ein Speicherplatz für Ihre Daten.
AWS Athena Datenbank
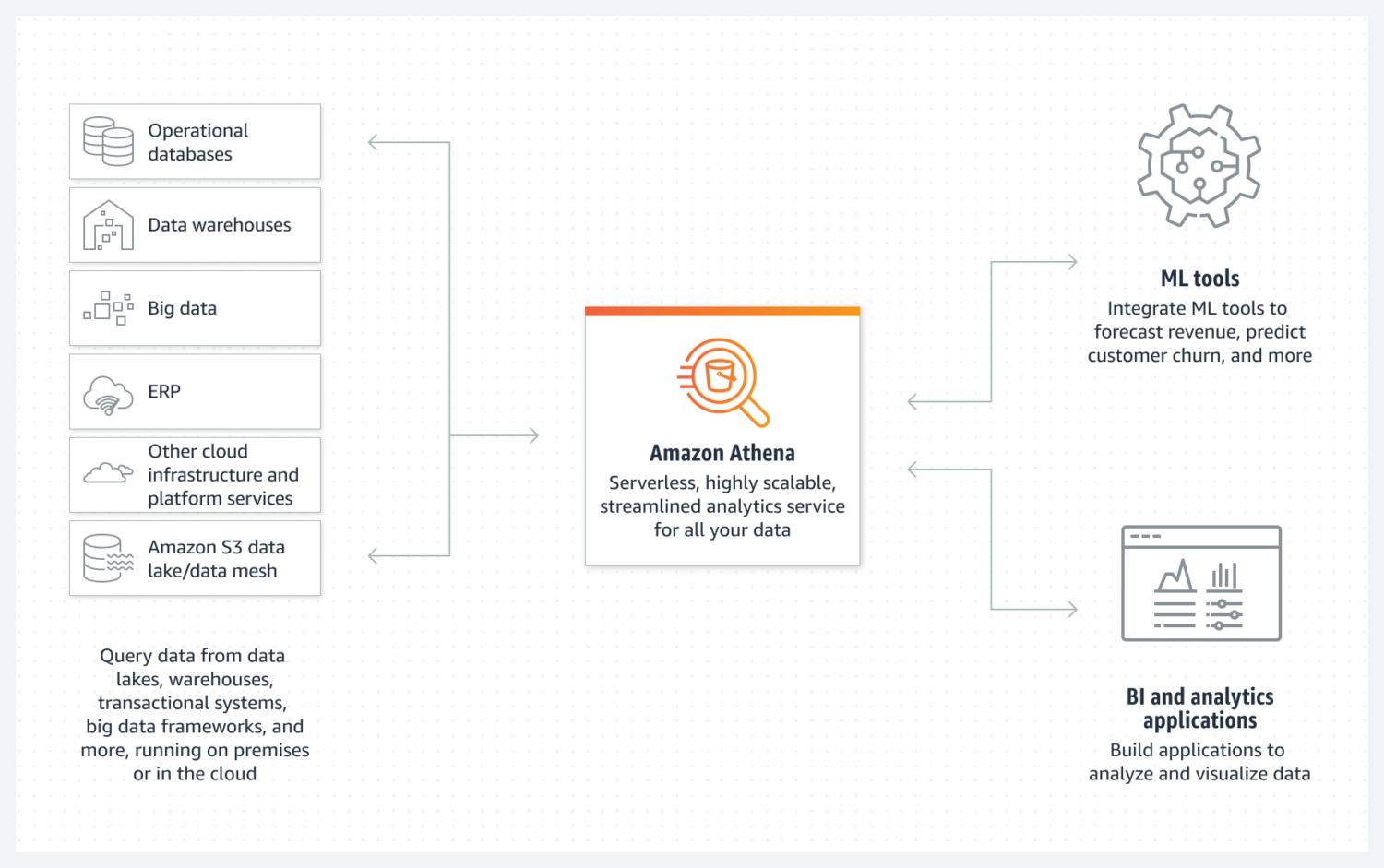
Mit Athena können Sie ganz einfach einen einfachen AWS Data Lake erstellen. Es handelt sich um eine Datenbank ohne Server, die einen S3-Bucket zum Speichern ihrer Daten verwendet. Die Datenorganisation erfolgt über strukturierte Dateiformate wie Parquet- oderCSV-Dateien (Comma-Separated Value). Der S3-Bucket enthält die Dateien, und Athena bezieht sich auf sie, wenn Prozesse die Daten aus der Datenbank auswählen.
Beachten Sie jedoch, dass Athena verschiedene Funktionen nicht unterstützt, die sonst als Standard gelten, z.B. Update-Anweisungen. Deshalb müssen Sie Athena als eine sehr einfache Option betrachten.
Allerdings unterstützt es Indizierung und Partitionierung. Es kann auch sehr einfach horizontal skaliert werden, da dies so komplex ist wie das Hinzufügen neuer Buckets zur Infrastruktur. Für eine einfache, aber funktionale Data Lake-Erstellung kann dies in den meisten Fällen ausreichen.
Für eine gute Leistung ist die Auswahl des besten Datendesigns mit Blick auf die zukünftige Nutzung von entscheidender Bedeutung. Es ist wichtig, dass Sie sich über die Art und Weise, wie Sie Daten auswählen möchten, im Klaren sind. Es ist schwierig, Tabellen später neu zu erstellen, wenn sie bereits existieren und mit vielen Daten gefüllt sind.
Athena DB ist eine gute Wahl und passt gut zu Ihrem Ziel, wenn Sie einen einfachen und unveränderlichen Datenpool erstellen möchten, der sich im Laufe der Zeit leicht horizontal skalieren lässt.
AWS Aurora-Datenbank
Athena DB eignet sich hervorragend für die Speicherung unkuratierter Daten. So wollen Sie Ihre ursprünglichen Inhalte speichern, um deren zukünftige Wiederverwendung zu maximieren. Allerdings ist sie langsam, wenn es darum geht, einer Front-End-Applikation ausgewählte Ergebnisse zur Verfügung zu stellen.
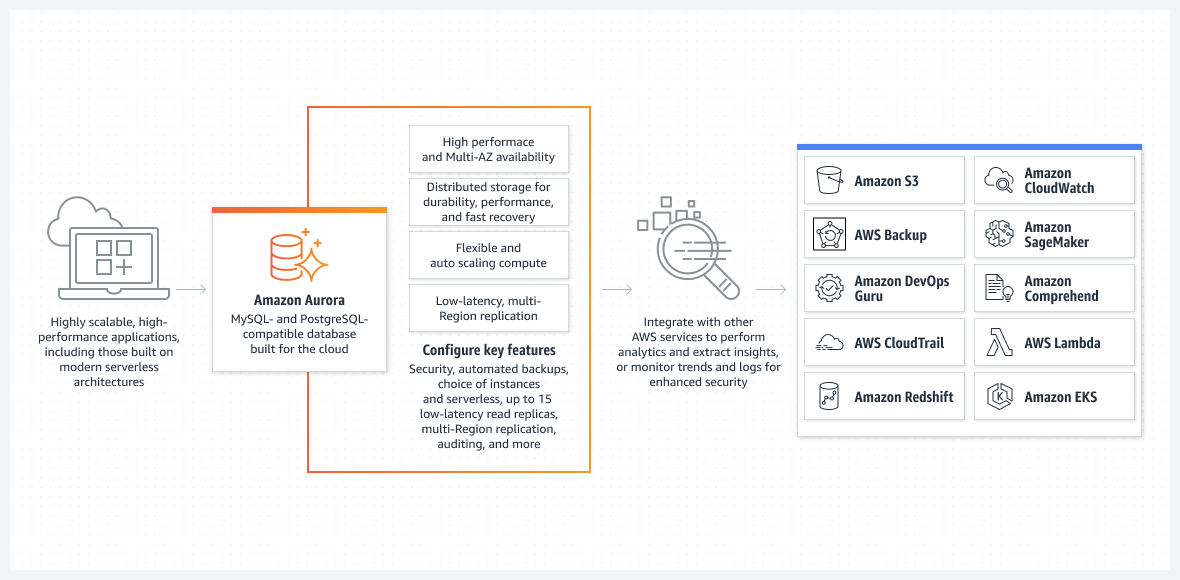
Eine der besten Optionen, vor allem aus der Perspektive einer einfach auszuführenden Einrichtung, ist die Aurora-Datenbank, die im serverlosen Modus läuft.
Aurora ist alles andere als eine einfache Datenbank. Sie ist eine der fortschrittlichsten nativen relationalen Datenbanklösungen in AWS. Es handelt sich auch um eine hochkomplexe native relationale Datenbanklösung, die mit jeder Version verbessert wird.
Aurora ist einzigartig, weil es im serverlosen Modus ausgeführt werden kann, wodurch es sich von anderen relationalen Services abhebt. So funktioniert der Modus:
- Um den Aurora-Cluster zu konfigurieren, verwenden Sie die AWS-Konsole. Sie müssen die Standardwerte für CPU und RAM sowie das maximale Intervall für die Auto-Scale-Funktion festlegen. Dies hat Auswirkungen auf die Leistung, die der Aurora-Cluster dynamisch hinzufügen oder entfernen kann. Anhand der aktuellen Auslastung der Datenbank entscheidet AWS, ob die Skalierung nach oben oder unten erfolgen soll.
- Der Aurora-Cluster wird nur dann gestartet, wenn der Benutzer oder der Prozess eine echte Anforderung auslöst. Zum Beispiel, wenn die geplante Batch-Verarbeitung beginnt. Oder wenn die Anwendung einen Back-End-API-Aufruf durchführt, um Daten aus einer Datenbank abzurufen. Die Datenbank wird automatisch geöffnet und bleibt für eine bestimmte Zeit nach Abschluss der Anfrageprozesse aktiv.
- Der Aurora-Cluster wird automatisch heruntergefahren, wenn keine Arbeit mehr in der Datenbank vorhanden ist.
Um es noch einmal zu betonen: Die serverlose Aurora DB läuft nur, wenn sie wirklich arbeiten muss. Der automatisch gestartete Cluster wird wieder heruntergefahren, wenn er keine Arbeit verarbeitet. Die tatsächliche Arbeit ist das, wofür Sie bezahlen und nicht Ihre Leerlaufzeit.
Das serverlose Aurora wird vollständig von AWS verwaltet und erfordert keinen Administrator.
AWS Amplify
Amplify bietet eine serverlose Plattform für die schnelle Bereitstellung von Front-End-Anwendungen, die mit JavaScript und React-Bibliotheken erstellt wurden. Es ist nicht notwendig, Cluster-Server einzurichten. Verwenden Sie die AWS-Konsole, um den Code direkt bereitzustellen, oder verwenden Sie eine automatisierte DevOps-Pipeline.
Sie können Back-End-APIs aufrufen, um auf in Datenbanken gespeicherte Daten zuzugreifen. Diese Aufrufe ermöglichen Ihnen den Zugriff auf die tatsächlichen Daten in der Front-End-Anwendung. Die Hauptoptimierung der Leistung im Back-End sollte vom Team vorgenommen werden. Sie können die Möglichkeit einer langsamen Reaktion in der Benutzeroberfläche sogar noch weiter reduzieren, wenn Sie effektive Select-Anweisungen direkt in den API-Aufrufen entwerfen.
AWS Schritt-Funktionen
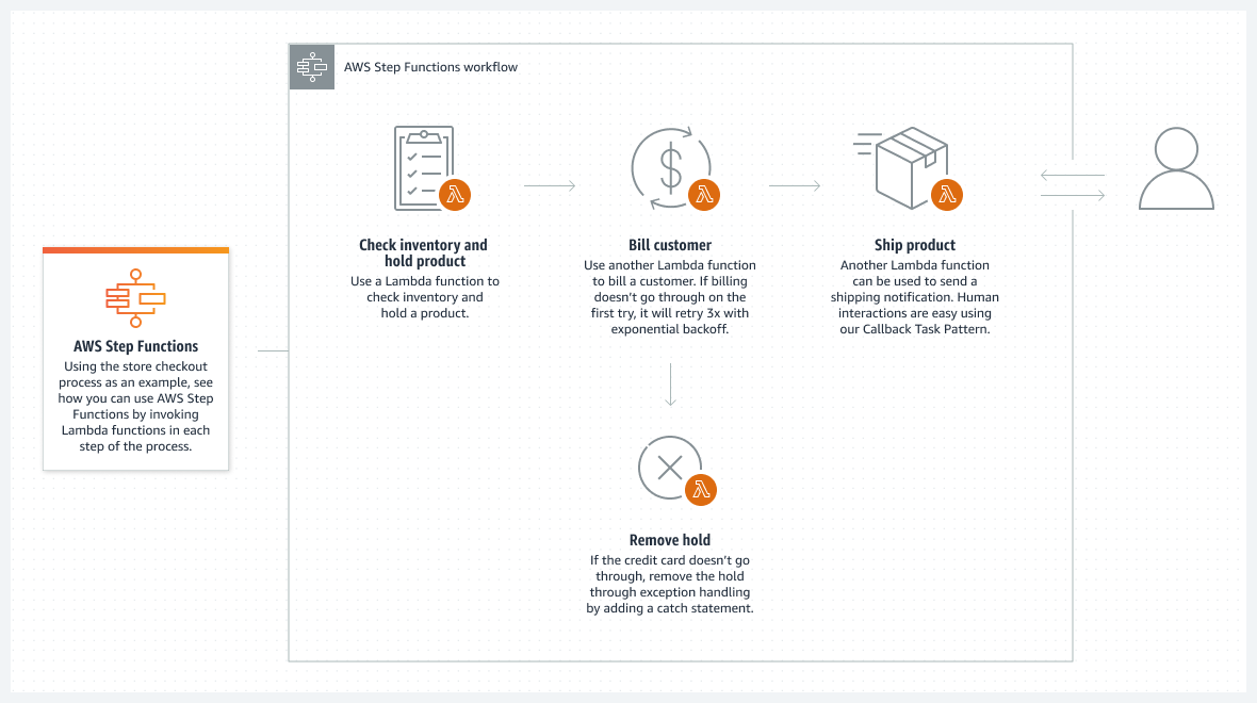
Auch wenn alle wichtigen Komponenten eines Systems serverlos sind, garantiert dies keine vollständig serverlose Architektur. Dies ist nur möglich, wenn alle Batch-Prozesse zwischen den Komponenten serverlos sind.
AWS Step-Funktionen bieten die beste Lösung in der AWS-Cloud. Eine zusammenhängende Liste von AWS Lambda-Funktionen bildet die Step-Funktion. Diese Funktionen erstellen ein Flussdiagramm, das klare Start- und Endzustände hat. Eine Lambda-Funktion, die in der Regel in den Sprachen Python oder Node JS geschrieben wird, ist ein ausführbares Stück Code, das alles verarbeitet, was benötigt wird.
Im Folgenden finden Sie ein Beispiel dafür, wie Sie eine Schrittfunktion ausführen könnten:
- AWS löst eine automatische Lambda-Funktion aus, sobald eine neue Datei im S3-Ordner eingeht. Nach dem Parsen der Datei lädt die Lambda-Funktion diese in Athena. Der Lambda speichert seine Ergebnisse entweder in einem CSV-Format in einem S3-Bucket (oder in einer Datenbank-Tracking-Tabelle), bevor er geschlossen wird.
- Dieses Ergebnis wird dann vom nächsten Lambda verwendet, um die nächsten Schritte auszuführen. Dazu kann der Aufruf eines maschinellen Lernmodells und die Umwandlung einer Teilmenge der neuen Daten in normalisierte Tabellen gehören. Der letzte Schritt kann das Laden der Daten in die Aurora-Datenbank sein.
- Eine Schrittfunktion verknüpft diese Lambdas zu einem Batchflow. Es ist sogar möglich, eine andere Schrittfunktion anstelle eines Schritts einer anderen Stammschrittfunktion ausführen zu lassen. Auf diese Weise ist es möglich, viele Szenarien abzudecken.
Dieser serverlose Ablauf hat einen großen Nachteil: Jede Lambda-Funktion kann nur maximal 15 Minuten lang ausgeführt werden. Daher kann die Aufteilung des Ablaufs in kleinere Lambda-Funktionen dieses Problem entschärfen.
Es ist möglich, mehrere Lambda-Funktionen gleichzeitig in einem Schritt aufzurufen, was im Grunde bedeutet, dass ein Schritt mit mehreren gleichzeitig ausgeführten Lambdas parallelisiert wird. Warten Sie einfach, bis alle parallelen Lambda-Verarbeitungen abgeschlossen sind, bevor Sie fortfahren. Dann fahren Sie mit der nächsten Lambda-Verarbeitung fort.
Abschließende Worte
Die serverlose Architektur bietet eine einzigartige Möglichkeit, eine Cloud-Plattform zu schaffen, die die gesamte Systemlandschaft abdeckt. Diese Plattform ist horizontal skalierbar und hat dabei niedrige Betriebskosten.
Sie ist die perfekte Lösung für Projekte mit beschränktem Budget. Sie ist eine hervorragende Option zur Erkundung, wenn noch niemand die tatsächliche Produktionslast kennt. Dies ist besonders wichtig, nachdem Sie alle Benutzer erfolgreich an Bord geholt haben. Die Projektteams können sich immer noch einen Überblick darüber verschaffen, wie das System funktioniert. Sie können all diese Vorteile haben und müssen trotzdem keine Kompromisse eingehen.
Diese Abdeckung wird nicht für alle Fälle ausreichen, insbesondere nicht für solche, die eine hohe CPU-Auslastung erfordern. Die AWS-Cloud entwickelt sich jedoch ständig weiter, was die serverlosen Anwendungsfälle angeht. Es ist in der Regel eine gute Idee, gründlich zu recherchieren, bevor Sie sich für die serverlose Option für Ihr nächstes AWS-Cloud-Projekt entscheiden.
Sehen Sie sich als nächstes die besten serverlosen Datenbanken für moderne Anwendungen an.