Apache Parquet bietet mehrere Vorteile für die Speicherung und den Abruf von Daten im Vergleich zu herkömmlichen Methoden wie CSV.
Das Parquet-Format wurde für die schnellere Verarbeitung komplexer Datenarten entwickelt. In diesem Artikel sprechen wir darüber, wie das Parquet-Format für die ständig wachsenden Datenanforderungen von heute geeignet ist.
Bevor wir uns mit den Details des Parquet-Formats befassen, sollten wir verstehen, was CSV-Daten sind und welche Herausforderungen sie für die Datenspeicherung mit sich bringen.
Was ist CSV-Speicherung?
Wir alle haben schon viel über CSV(Comma Separated Values) gehört – eine der gängigsten Methoden zur Organisation und Formatierung von Daten. Die CSV-Datenspeicherung ist zeilenbasiert. CSV-Dateien werden mit der Erweiterung .csv gespeichert. Wir können CSV-Daten mit Excel, Google Sheets oder einem beliebigen Texteditor speichern und öffnen. Die Daten sind sofort sichtbar, sobald die Datei geöffnet ist.
Nun, das ist nicht gut – jedenfalls nicht für ein Datenbankformat.
Außerdem wird es mit zunehmender Datenmenge immer schwieriger, diese abzufragen, zu verwalten und abzurufen.
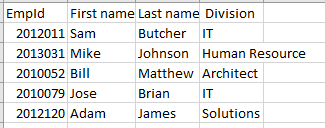
Hier ein Beispiel für Daten, die in einer .CSV-Datei gespeichert sind:
EmpId,Vorname,Nachname, Abteilung
2012011,Sam,Butcher,IT
2013031,Mike,Johnson,Personalwesen
2010052,Bill,Matthew,Architekt
2010079,Jose,Brian,IT
2012120,Adam,James,Lösungen
Wenn wir sie in Excel betrachten, sehen wir eine Zeilen-Spalten-Struktur wie unten:
Herausforderungen bei der CSV-Speicherung
Zeilenbasierte Speicher wie CSV sind für die Operationen Erstellen, Aktualisierenund Löschengeeignet.
Was ist dann mit dem Lesenin CRUD?
Stellen Sie sich eine Million Zeilen in der obigen .csv-Datei vor. Es würde eine ganze Weile dauern, die Datei zu öffnen und nach den gewünschten Daten zu suchen. Nicht so cool. Die meisten Cloud-Anbieter wie AWS berechnen Unternehmen auf der Grundlage der gescannten oder gespeicherten Datenmenge – auch hier verbrauchen CSV-Dateien eine Menge Platz.
CSV-Speicher haben keine exklusive Option zum Speichern von Metadaten, was das Scannen von Daten zu einer mühsamen Aufgabe macht.
Was ist also die kosteneffiziente und optimale Lösung für die Durchführung aller CRUD-Vorgänge? Lassen Sie uns das erkunden.
Was ist die Parquet Datenspeicherung?
Parquet ist ein Open-Source-Speicherformat zum Speichern von Daten. Es wird häufig in den Ökosystemen von Hadoop und Spark verwendet. Parquet-Dateien werden mit der Erweiterung .parquet gespeichert.
Parquet ist ein stark strukturiertes Format. Es kann auch zur Optimierung komplexer Rohdaten verwendet werden, die in großen Mengen in Data Lakes vorhanden sind. Dadurch kann die Abfragezeit erheblich reduziert werden.
Parquet macht die Datenspeicherung effizient und den Abruf schneller, da es eine Mischung aus zeilen- und spaltenbasierten (hybriden) Speicherformaten ist. In diesem Format sind die Daten sowohl horizontal als auch vertikal partitioniert. Das Parquet-Format eliminiert auch weitgehend den Parsing-Overhead.
Das Format schränkt die Gesamtzahl der E/A-Operationen und damit die Kosten ein.
Parquet speichert auch die Metadaten, die Informationen über Daten wie das Datenschema, die Anzahl der Werte, die Position der Spalten, den Mindestwert, den Höchstwert, die Anzahl der Zeilengruppen, die Art der Kodierung usw. enthalten. Die Metadaten werden auf verschiedenen Ebenen in der Datei gespeichert, wodurch der Datenzugriff schneller wird.
Bei einem zeilenbasierten Zugriff wie CSV dauert der Datenabruf länger, da die Abfrage durch jede Zeile navigieren und die jeweiligen Spaltenwerte abrufen muss. Mit der Parquet-Speicherung kann auf alle benötigten Spalten auf einmal zugegriffen werden.
Zusammengefasst,
- Parquet basiert auf einer Spaltenstruktur für die Datenspeicherung
- Es ist ein optimiertes Datenformat für die Speicherung komplexer Daten in großen Mengen in Speichersystemen
- Das Parquet-Format umfasst verschiedene Methoden zur Datenkomprimierung und -kodierung
- Es verkürzt die Zeit für das Scannen und Abfragen von Daten erheblich und benötigt im Vergleich zu anderen Speicherformaten wie CSV weniger Speicherplatz
- Minimiert die Anzahl der IO-Operationen und senkt so die Kosten für die Speicherung und die Ausführung von Abfragen
- Enthält Metadaten, die das Auffinden von Daten erleichtern
- Bietet Open-Source-Unterstützung
Parquet Datenformat
Bevor wir auf ein Beispiel eingehen, sollten wir uns genauer ansehen, wie Daten im Parquet-Format gespeichert werden:
Wir können in einer Datei mehrere horizontale Partitionen haben, die als Zeilengruppen bezeichnet werden. Innerhalb jeder Zeilengruppe wird eine vertikale Partitionierung vorgenommen. Die Spalten werden in mehrere Spaltenblöcke aufgeteilt. Die Daten werden als Seiten innerhalb der Spaltenblöcke gespeichert. Jede Seite enthält die kodierten Datenwerte und Metadaten. Wie wir bereits erwähnt haben, werden die Metadaten für die gesamte Datei auch in der Fußzeile der Datei auf der Ebene der Zeilengruppe gespeichert.
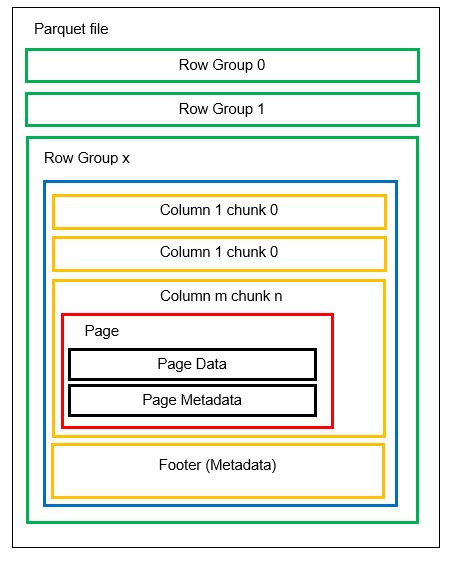
Da die Daten in Spaltenchunks aufgeteilt sind, ist es auch einfach, neue Daten hinzuzufügen, indem Sie die neuen Werte in einen neuen Chunk und eine neue Datei kodieren. Die Metadaten werden dann für die betroffenen Dateien und Zeilengruppen aktualisiert. Wir können also sagen, dass Parquet ein flexibles Format ist.
Parquet unterstützt von Haus aus die Komprimierung von Daten mithilfe von Seitenkomprimierung und Wörterbuchkodierungstechniken. Sehen wir uns ein einfaches Beispiel für die Wörterbuchkomprimierung an:
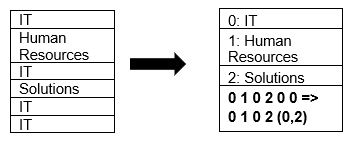
Beachten Sie, dass in dem obigen Beispiel die IT-Division 4 Mal vorkommt. Beim Speichern im Wörterbuch kodiert das Format die Daten also mit einem anderen, leicht zu speichernden Wert (0,1,2…) zusammen mit der Anzahl der ständigen Wiederholungen – IT, IT wird in 0,2 geändert, um mehr Platz zu sparen. Die Abfrage von komprimierten Daten nimmt weniger Zeit in Anspruch.
Kopf-an-Kopf-Vergleich
Nun, da wir eine Vorstellung davon haben, wie die Formate CSV und Parquet aussehen, ist es an der Zeit, beide Formate anhand einiger Statistiken zu vergleichen:
| CSV | Parquet |
| Zeilenbasiertes Speicherformat. | Eine Mischung aus zeilenbasierten und spaltenbasierten Speicherformaten. |
| Es verbraucht viel Platz, da keine Standardkomprimierungsoption verfügbar ist. Eine 1 TB große Datei nimmt beispielsweise den gleichen Platz ein, wenn sie auf Amazon S3 oder einer anderen Cloud gespeichert wird. | Komprimiert die Daten beim Speichern und verbraucht so weniger Platz. Eine 1 TB große Datei, die im Parquet-Format gespeichert ist, nimmt nur 130 GB Platz in Anspruch. |
| Die Laufzeit der Abfrage ist aufgrund der zeilenbasierten Suche langsam. Für jede Spalte muss jede Zeile der Daten abgerufen werden. | Die Abfragezeit ist aufgrund der spaltenbasierten Speicherung und des Vorhandenseins von Metadaten etwa 34 Mal schneller. |
| Pro Abfrage müssen mehr Daten gescannt werden. | Für die Ausführung der Abfrage werden etwa 99% weniger Daten gescannt, wodurch die Leistung optimiert wird. |
| Die meisten Speichergeräte berechnen den Speicherplatz, so dass das CSV-Format hohe Speicherkosten verursacht. | Geringere Speicherkosten, da die Daten in einem komprimierten, verschlüsselten Format gespeichert werden. |
| Das Dateischema muss entweder abgeleitet (was zu Fehlern führt) oder bereitgestellt werden (mühsam). | Das Dateischema ist in den Metadaten gespeichert. |
| Das Format ist für einfache Datentypen geeignet. | Parquet eignet sich auch für komplexe Typen wie verschachtelte Schemata, Arrays und Wörterbücher. |
Fazit 👩💻
Wir haben anhand von Beispielen gesehen, dass Parquet in Bezug auf Kosten, Flexibilität und Leistung effizienter ist als CSV. Es ist ein effektiver Mechanismus für die Speicherung und den Abruf von Daten, vor allem in einer Zeit, in der sich die ganze Welt in Richtung Cloud-Speicher und Platzoptimierung bewegt. Alle wichtigen Plattformen wie Azure, AWS und BigQuery unterstützen das Parquet-Format.