Prometheus ist ein auf Metriken basierendes Open-Source-Überwachungssystem. Es sammelt Daten von Diensten und Hosts, indem es HTTP-Anfragen an Metrik-Endpunkte sendet. Anschließend speichert es die Ergebnisse in einer Zeitseriendatenbank und stellt sie für Analysen und Warnmeldungen zur Verfügung.
Warum überwachen?
- Ermöglicht Warnungen, wenn etwas schief läuft, vorzugsweise bevor es schief läuft. Damit jemand einen Blick darauf werfen kann.
- Es bietet Einblicke, die eine Analyse, Fehlersuche und Problemlösung ermöglichen.
- Es ermöglicht Ihnen, Trends/Veränderungen im Laufe der Zeit zu erkennen. Zum Beispiel, wie viele aktive Sitzungen zu einem bestimmten Zeitpunkt stattfinden. Dies hilft bei Designentscheidungen und der Kapazitätsplanung.
Die Überwachung bezieht sich in der Regel auf Ereignisse. Ein Ereignis kann der Empfang einer HTTP-Anfrage, das Senden einer Antwort, das Lesen von der Festplatte oder eine Benutzeranmeldung sein. Die Überwachung eines Systems kann Profiling, Logging, Tracing, Metriken, Alerting und Visualisierung umfassen.
Blackbox vs. Whitebox-Überwachung
Die Überwachung fällt unter zwei Hauptkategorien:
Blackbox-Überwachung
Bei der Blackbox-Überwachung erfolgt die Überwachung auf Anwendungs- oder Host-Ebene, da diese von außen beobachtet werden. Dies kann ziemlich einschränkend sein.
Whitebox-Überwachung
Whitebox-Monitoring bedeutet die Überwachung der Interna eines Dienstes. Sie würde Daten über den Zustand und die Leistung der internen Komponenten offenlegen.
Die vier goldenen Signale
Laut Google sollten Sie sich, wenn Sie nur vier Metriken Ihres nutzerorientierten Systems messen können, auf die folgenden vier konzentrieren, die so genannten vier goldenen Signale:
#1. Latenz
Die Zeit, die benötigt wird, um eine Anfrage zu bedienen – erfolgreich oder fehlgeschlagen. Es ist wichtig, nicht nur die erfolgreichen, sondern auch die fehlgeschlagenen Anfragen zu verfolgen.
#2. Verkehr
Ein Maß dafür, wie viele Anforderungen an Ihr System gestellt werden. Bei einem Webdienst sind dies in der Regel HTTP-Anfragen pro Sekunde.
#3. Fehler
Die Anzahl der Anfragen, die fehlschlagen.
#4. Sättigung
Wie voll Ihr Dienst ist. Der Anstieg der Latenz ist oft ein wichtiger Indikator für Sättigung. Bei vielen Systemen lässt die Leistung nach, lange bevor sie eine 100%ige Auslastung erreichen.
Arten von Prometheus-Metriken
Prometheus-Metriken gibt es in vier Haupttypen:
#1. Zähler
Der Wert eines Zählers wird immer größer. Er kann niemals sinken, aber er kann auf Null zurückgesetzt werden. Wenn also ein Scrape fehlschlägt, bedeutet das nur, dass ein Datenpunkt fehlt. Der kumulative Anstieg wäre beim nächsten Lesen verfügbar. Beispiele:
- Gesamtzahl der empfangenen HTTP-Anfragen
- Die Anzahl der Ausnahmen.
#2. Messgerät
Ein Gauge ist eine Momentaufnahme zu einem bestimmten Zeitpunkt. Sie kann sowohl steigen als auch fallen. Wenn ein Datenabruf fehlschlägt, verlieren Sie eine Stichprobe. Der nächste Abruf könnte einen anderen Wert anzeigen: Beispiele für Festplattenspeicher, Speichernutzung.
#3. Histogramm
Ein Histogramm fasst Beobachtungen zusammen und zählt sie in konfigurierbaren Bereichen. Sie werden für Dinge wie Anfragedauer oder Antwortgrößen verwendet. Sie könnten zum Beispiel die Dauer einer bestimmten HTTP-Anfrage messen. Das Histogramm enthält eine Reihe von Bereichen, z.B. 1 ms, 10 ms und 25 ms. Anstatt jede Dauer für jede Anfrage zu speichern, speichert Prometheus die Häufigkeit der Anfragen, die in einen bestimmten Bereich fallen.
#4. Zusammenfassung
Ähnlich wie beim Histogramm werden Beobachtungen, typischerweise Anfragedauern oder Antwortgrößen, zusammengefasst. Es liefert eine Gesamtzahl der Beobachtungen und eine Summe aller beobachteten Werte, so dass Sie den Durchschnitt der beobachteten Werte berechnen können. Ein Beispiel: In einer Minute hatten Sie drei Anfragen, die 2, 3 und 4 Sekunden dauerten. Die Summe wäre 9 und die Anzahl wäre 3. Die Latenzzeit würde 3 Sekunden betragen.
Komponenten des Prometheus-Ökosystems
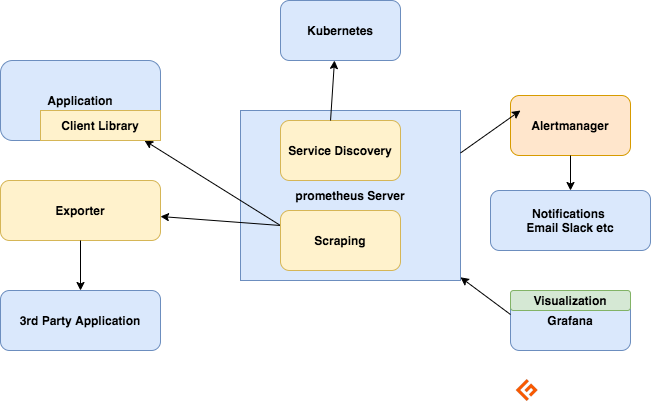
Der Prometheus-Server
Sammelt Metriken, speichert sie und stellt sie für Abfragen zur Verfügung, sendet Warnmeldungen auf der Grundlage der gesammelten Metriken.
Scraping
Prometheus ist ein Pull-basiertes System. Um Metriken abzurufen, sendet Prometheus eine HTTP-Anfrage, die als Scraping bezeichnet wird. Es sendet Scrapes an Ziele, die auf seiner Konfiguration basieren.
Jedes Ziel (statisch definiert oder dynamisch ermittelt) wird in einem regelmäßigen Intervall (Scrape-Intervall) abgefragt. Jeder Scrape liest den HTTP-Endpunkt /metrics, um den aktuellen Stand der Client-Metriken zu ermitteln und die Werte in der Prometheus-Zeitseriendatenbank zu speichern.
Es gibt noch weitere Zeitseriendatenbanken für Überwachungslösungen, die Sie vielleicht kennenlernen möchten.
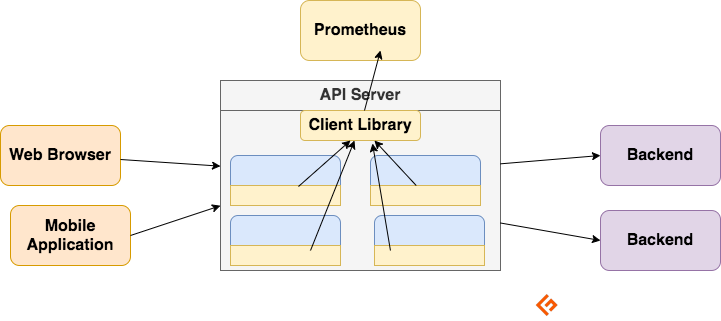
Client-Bibliotheken
Um einen Dienst zu überwachen, müssen Sie Ihren Code mit Instrumenten versehen. Es gibt Client-Bibliotheken für alle gängigen Sprachen und Laufzeiten. Wenn Sie diese Bibliotheken verwenden und ein paar Zeilen Code hinzufügen, kann Ihr Code bereits Metriken ausgeben. Dies wird als direkte Instrumentierung bezeichnet. Diese Bibliotheken ermöglichen es Ihnen, interne Metriken zu definieren und sie über einen HTTP-Endpunkt offenzulegen. Wenn Prometheus den HTTP-Endpunkt für Metriken abruft, sendet die Client-Bibliothek die Metriken an den Server.
Offizielle Client-Bibliotheken werden von Prometheus für Go, Java, Python und Ruby angeboten. Prometheus hat ein offenes Ökosystem. Es gibt auch von der Community entwickelte Client-Bibliotheken für C, PHP, Node.js, C#/.NET und viele andere.
Exporteure
Viele Anwendungen stellen Metriken in einem Nicht-Prometheus-Format bereit. Für diese und für Anwendungen, die Sie nicht besitzen oder für die Sie keinen Zugang zum Code haben, können Sie keine direkte Instrumentierung hinzufügen. Zum Beispiel MySQL, Kafka, JMX, HAProxy und NGINX Server. In diesen Szenarien verwenden Sie Exporteure.
Ein Exporter ist ein Tool, das Sie zusammen mit der Anwendung einsetzen, von der Sie Metriken wünschen. Ein Exporter fungiert wie ein Proxy zwischen der Anwendung und Prometheus. Er empfängt Anfragen vom Prometheus-Server, sammelt Daten aus den Zugriffsprotokollen und Fehlerprotokollen der Anwendung, wandelt sie in das richtige Format um und sendet sie schließlich an den Prometheus-Server zurück.
Einige der beliebtesten Exporteure sind:
- Windows – für Windows-Server-Metriken
- Node – für Linux-Server-Metriken
- Blackbox – für DNS- und Website-Leistungskennzahlen
- JMX – für Metriken zu Java-basierten Anwendungen
Sobald die Anwendungen instrumentiert oder die Exporter eingerichtet sind, müssen Sie Prometheus mitteilen, wo sie sich befinden. Dies kann über eine statische Konfiguration geschehen. Bei dynamischen Umgebungen ist dies nicht möglich, daher wird die Diensterkennung verwendet.
Alarmierung
Das Alerting mit Prometheus besteht aus zwei Teilen –
Alerting-Regeln senden Alarme an den Alertmanager.
Der Alertmanager verwaltet dann diese Alarme. Er versendet Benachrichtigungen über viele sofort einsatzbereite Integrationen wie E-Mail, Slack, Hipchat und PagerDuty. Der Alertmanager kann auch die Anzahl der Benachrichtigungen reduzieren, indem er sie unterdrückt oder zusammenfasst.
Hier finden Sie die Anleitung zur Überwachung des Linux-Servers mit Prometheus und Dashboard.
Visualisierung mit Dashboards
Prometheus verfügt über eine Reihe von APIs, mit denen PromQL-Abfragen Rohdaten für Visualisierungen erzeugen können.
Obwohl Prometheus einen Expression Browser enthält, der für Ad-hoc-Abfragen verwendet werden kann, ist Grafana das beste verfügbare Tool. Grafana ist vollständig mit Prometheus integriert und kann eine Vielzahl von Dashboards erstellen.
Sie müssen Prometheus als Datenquelle für Grafana konfigurieren.
Sie können Dashboards hinzufügen, indem Sie:
- Importieren von Dashboards, die von der Community erstellt wurden
- Ihr eigenes erstellen
- Verwendung eines vordefinierten Dashboards.
So sieht ein vordefiniertes Node-Exporter-Dashboard aus:
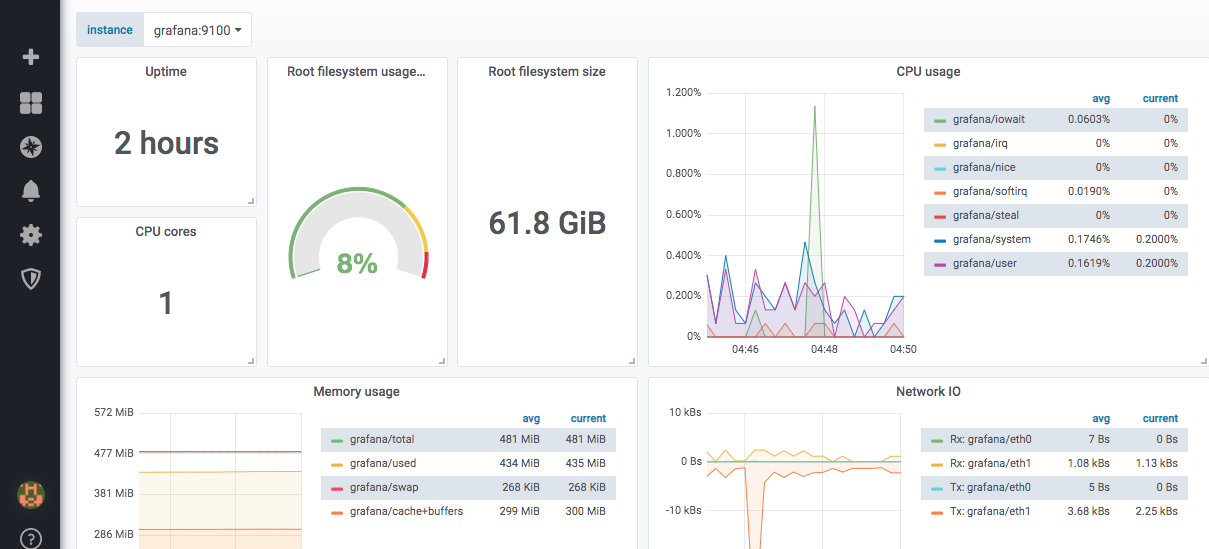
Grafana verfügt über ein worldPing-Modul, mit dem Sie Website- und DNS-Leistungsmetriken weltweit überwachen können.
Zusammenfassung
Prometheus hat sehr wenige Anforderungen. Es kann recht einfach ausgeführt werden, da es sich um eine einzelne Binärdatei mit einer Konfigurationsdatei handelt. Es kann Tausende von Zielen verarbeiten und Millionen von Proben pro Sekunde aufnehmen. Prometheus wurde entwickelt, um das gesamte System, den Zustand und das Verhalten des Systems zu überwachen.
Grafana ist das beste verfügbare Tool für die Visualisierung von Metriken und lässt sich nahtlos in Prometheus integrieren.