Daten werden immer wichtiger für die Erstellung von Modellen für maschinelles Lernen, das Testen von Anwendungen und die Gewinnung von Geschäftserkenntnissen.
Aus Gründen der Einhaltung der zahlreichen Datenvorschriften werden sie jedoch oft unter Verschluss gehalten und streng geschützt. Der Zugriff auf solche Daten kann Monate dauern, bis die notwendigen Genehmigungen erteilt werden. Als Alternative können Unternehmen synthetische Daten verwenden.
Was sind synthetische Daten?
Synthetische Daten sind künstlich erzeugte Daten, die statistisch gesehen dem alten Datensatz ähneln. Sie können zusammen mit realen Daten verwendet werden, um KI-Modelle zu unterstützen und zu verbessern, oder sie können ganz als Ersatz verwendet werden.
Da sie keinem Datensubjekt gehören und keine persönlich identifizierenden Informationen oder sensible Daten wie Sozialversicherungsnummern enthalten, können sie als datenschutzfreundliche Alternative zu echten Produktionsdaten verwendet werden.
Unterschiede zwischen realen und synthetischen Daten
- Der wichtigste Unterschied liegt in der Art und Weise, wie die beiden Arten von Daten erzeugt werden. Echte Daten stammen von echten Personen, deren Daten bei Umfragen oder bei der Nutzung Ihrer Anwendung erfasst wurden. Synthetische Daten hingegen werden künstlich erzeugt, ähneln aber dennoch dem Originaldatensatz.
- Der zweite Unterschied liegt in den Datenschutzbestimmungen, die für echte und synthetische Daten gelten. Bei realen Daten sollten die Betroffenen wissen, welche Daten über sie gesammelt werden und warum sie gesammelt werden, und es gibt Grenzen für die Verwendung der Daten. Diese Vorschriften gelten jedoch nicht mehr für synthetische Daten, da die Daten nicht einer Person zugeordnet werden können und keine persönlichen Informationen enthalten.
- Der dritte Unterschied liegt in der Menge der verfügbaren Daten. Bei echten Daten können Sie nur so viel haben, wie Ihnen die Benutzer zur Verfügung stellen. Andererseits können Sie so viele synthetische Daten generieren, wie Sie wollen.
Warum Sie die Verwendung synthetischer Daten in Betracht ziehen sollten
- Synthetische Daten sind relativ kostengünstig, da Sie viel größere Datensätze erzeugen können, die dem kleineren Datensatz, den Sie bereits haben, ähneln. Das bedeutet, dass Ihre Modelle für maschinelles Lernen mit mehr Daten trainiert werden können.
- Die generierten Daten werden automatisch für Sie beschriftet und bereinigt. Das bedeutet, dass Sie keine Zeit für die zeitaufwändige Vorbereitung der Daten für maschinelles Lernen oder Analysen aufwenden müssen.
- Es gibt keine Probleme mit dem Datenschutz, da die Daten nicht persönlich identifizierbar sind und nicht zu einer betroffenen Person gehören. Das heißt, Sie können sie frei verwenden und weitergeben.
- Sie können KI-Voreingenommenheit überwinden, indem Sie sicherstellen, dass Minderheiten gut vertreten sind. Dies hilft Ihnen, eine faire und verantwortungsvolle KI zu entwickeln.
Wie man synthetische Daten generiert
Der Generierungsprozess variiert zwar je nachdem, welches Tool Sie verwenden, aber im Allgemeinen beginnt der Prozess mit der Verbindung eines Generators mit einem bestehenden Datensatz. Danach identifizieren Sie die personenbezogenen Felder in Ihrem Datensatz und kennzeichnen sie, um sie auszuschließen oder zu verschleiern.
Der Generator beginnt dann mit der Identifizierung der Datentypen der verbleibenden Spalten und der statistischen Muster in diesen Spalten. Von da an können Sie so viele synthetische Daten erzeugen, wie Sie benötigen.
Normalerweise können Sie die generierten Daten mit dem Originaldatensatz vergleichen, um zu sehen, wie gut die synthetischen Daten den echten Daten ähneln.
Jetzt werden wir die Tools für die Generierung synthetischer Daten zum Trainieren von Machine Learning-Modellen untersuchen.
Meistens KI

Mostly AI verfügt über einen KI-gesteuerten Generator für synthetische Daten, der aus den statistischen Mustern des Originaldatensatzes lernt. Die KI generiert dann fiktive Charaktere, die den gelernten Mustern entsprechen.
Mit Mostly AI können Sie ganze Datenbanken mit referenzieller Integrität erzeugen. Sie können alle Arten von Daten synthetisieren, um bessere KI-Modelle zu erstellen.
Synthesized.io
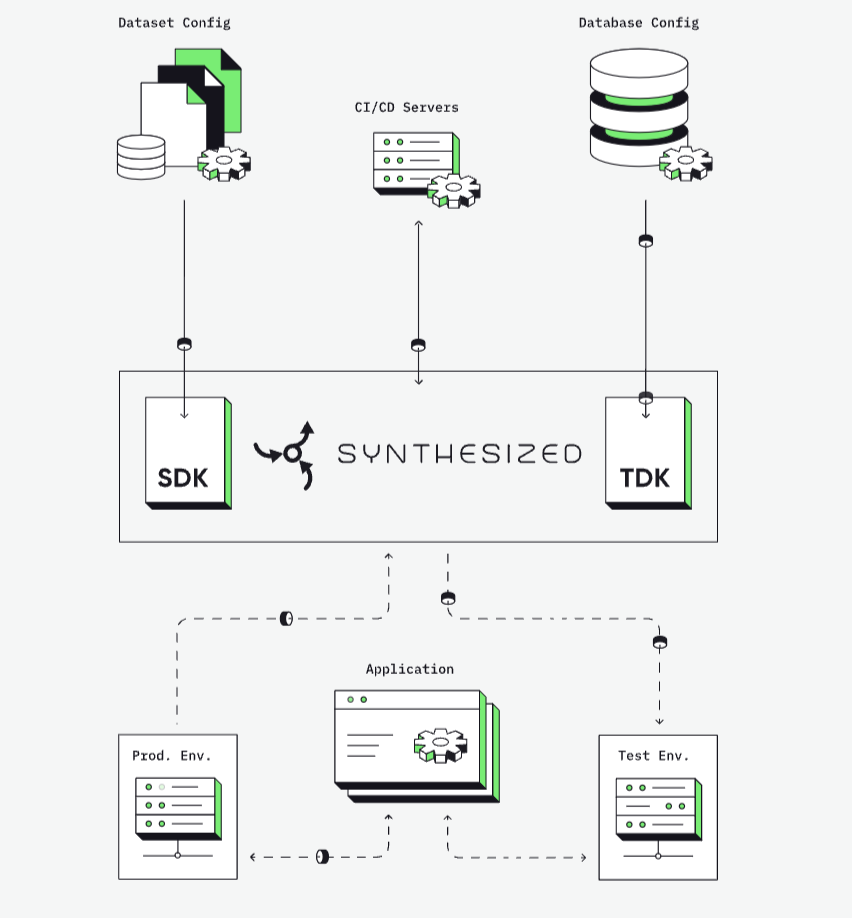
Synthesized.io wird von führenden Unternehmen für ihre KI-Initiativen verwendet. Um synthesize.io zu verwenden, legen Sie die Datenanforderungen in einer YAML-Konfigurationsdatei fest.
Anschließend erstellen Sie einen Job und führen ihn als Teil einer Datenpipeline aus. Es gibt auch ein sehr großzügiges kostenloses Angebot, mit dem Sie experimentieren können, um zu sehen, ob es Ihren Datenanforderungen entspricht.
YData

Mit YData können Sie tabellarische, Zeitreihen-, Transaktions-, Multitabellen- und relationale Daten erzeugen. Damit umgehen Sie die Probleme, die mit der Datenerfassung, -weitergabe und -qualität verbunden sind.
Es wird mit einer KI und einem SDK geliefert, die Sie für die Interaktion mit der Plattform nutzen können. Außerdem gibt es eine großzügige kostenlose Stufe, mit der Sie das Produkt testen können.
Gretel KI

Gretel AI bietet APIs zur Erzeugung unbegrenzter Mengen synthetischer Daten. Gretel hat einen Open-Source-Datengenerator, den Sie installieren und verwenden können.
Alternativ können Sie auch die kostenpflichtige REST-API oder CLI verwenden. Die Preise sind jedoch angemessen und skalieren mit der Größe des Unternehmens.
Copulas
Copulas ist eine Open-Source-Python-Bibliothek zur Modellierung multivariater Verteilungen mit Copula-Funktionen und zur Erzeugung synthetischer Daten, die denselben statistischen Eigenschaften folgen.
Das Projekt wurde 2018 am MIT als Teil des Synthetic Data Vault Project gestartet.
CTGAN
CTGAN besteht aus Generatoren, die aus realen Einzeltabellendaten lernen und aus den identifizierten Mustern synthetische Daten erzeugen können.
Es ist als Open-Source-Python-Bibliothek implementiert. CTGAN ist zusammen mit Copulas Teil des Synthetic Data Vault Project.
DoppelGANger
DoppelGANger ist eine Open-Source-Implementierung von Generative Adversarial Networks zur Erzeugung synthetischer Daten.
DoppelGANger ist nützlich für die Erzeugung von Zeitreihendaten und wird von Unternehmen wie Gretel AI verwendet. Die Python-Bibliothek ist kostenlos und quelloffen erhältlich.
Synth
Synth ist ein Open-Source-Datengenerator, mit dem Sie realistische Daten nach Ihren Vorgaben erstellen, persönlich identifizierbare Informationen verbergen und Testdaten für Ihre Anwendungen entwickeln können.
Mit Synth können Sie Echtzeit-Serien und relationale Daten für Ihre Bedürfnisse im Bereich des maschinellen Lernens erzeugen. Synth ist außerdem datenbankunabhängig, so dass Sie es mit Ihren SQL- und NoSQL-Datenbanken verwenden können.
SDV.dev

SDV steht für Synthetic Data Vault. SDV.dev ist ein Softwareprojekt, das 2016 am MIT begann und verschiedene Tools zur Erzeugung synthetischer Daten entwickelt hat.
Zu diesen Tools gehören Copulas, CTGAN, DeepEcho und RDT. Diese Tools sind als Open-Source-Python-Bibliotheken implementiert, die Sie einfach verwenden können.
Tofu
Tofu ist eine Open-Source-Python-Bibliothek zur Erzeugung synthetischer Daten auf der Grundlage von britischen Biobankdaten. Im Gegensatz zu den zuvor genannten Tools, mit denen Sie jede Art von Daten auf der Grundlage Ihres vorhandenen Datensatzes erzeugen können, erzeugt Tofu ausschließlich Daten, die denen der Biobank ähneln.
Die UK Biobank ist eine Studie über die phänotypischen und genotypischen Merkmale von 500 000 Erwachsenen mittleren Alters aus Großbritannien.
Twinify
Twinify ist ein Softwarepaket, das als Bibliothek oder Befehlszeilentool verwendet wird, um sensible Daten zu zwillingsbilden, indem synthetische Daten mit identischen statistischen Verteilungen erzeugt werden.

Um Twinify zu verwenden, stellen Sie die realen Daten als CSV-Datei zur Verfügung. Twinify lernt aus den Daten, um ein Modell zu erstellen, das zur Erzeugung synthetischer Daten verwendet werden kann. Die Nutzung ist völlig kostenlos.
Datanamic
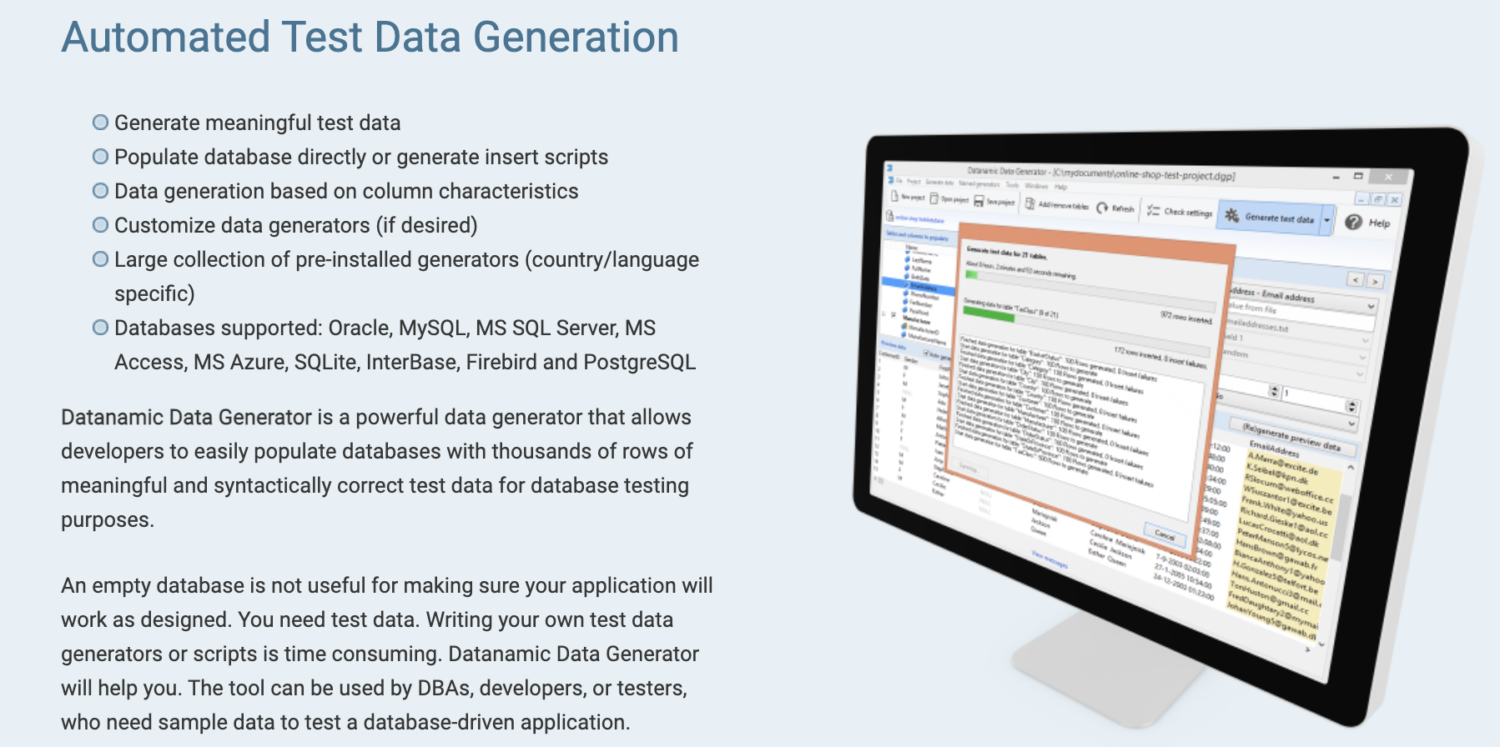
Datanamic hilft Ihnen bei der Erstellung von Testdaten für datengesteuerte und Machine-Learning-Anwendungen. Es generiert Daten auf der Grundlage von Spaltenmerkmalen wie E-Mail, Name und Telefonnummer.
Die Datengeneratoren von Datanamic sind anpassbar und unterstützen die meisten Datenbanken wie Oracle, MySQL, MySQL Server, MS Access und Postgres. Es unterstützt und gewährleistet die referenzielle Integrität der generierten Daten.
Benerator
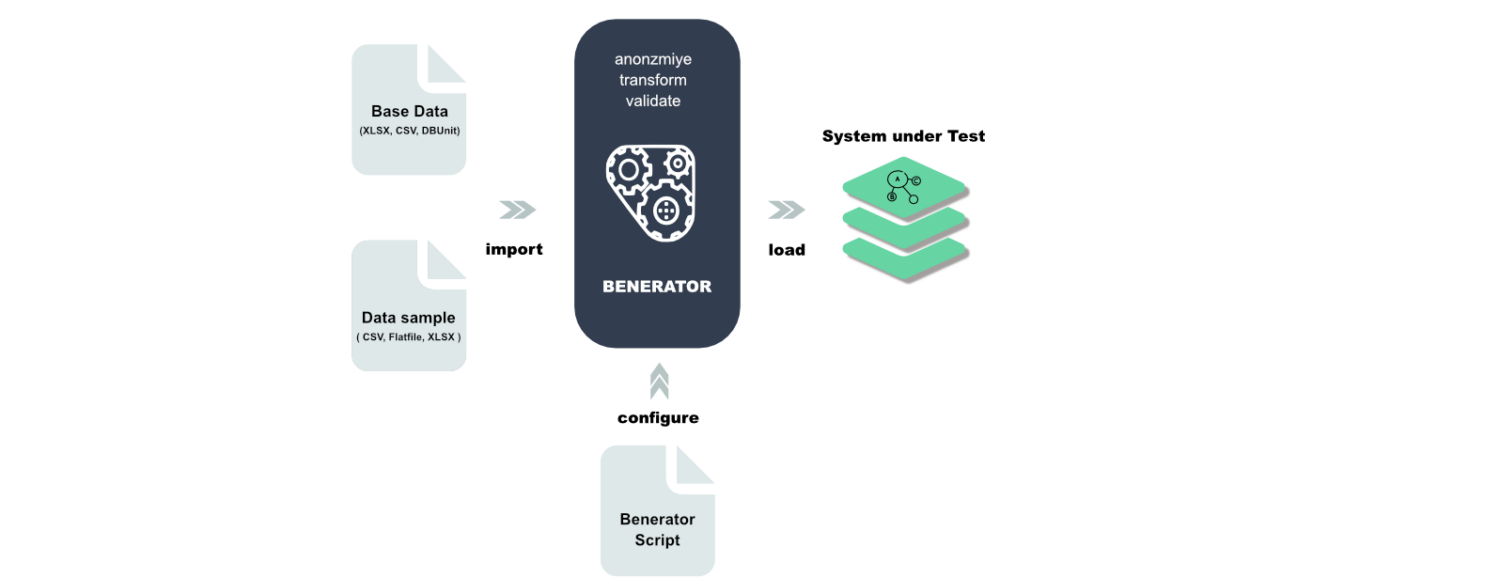
Benerator ist eine Software zur Datenverschleierung, -generierung und -migration für Test- und Schulungszwecke. Mit Benerator beschreiben Sie Daten mit XML (Extensible Markup Language) und generieren sie mit dem Befehlszeilen-Tool.
Benerator ist so konzipiert, dass es auch von Nicht-Entwicklern genutzt werden kann, und Sie können damit Milliarden von Datenzeilen generieren. Benerator ist kostenlos und Open-Source.
Letzte Worte
Nach Schätzungen von Gartner werden bis 2030 mehr synthetische Daten für das maschinelle Lernen verwendet werden als reale Daten.
Angesichts der Kosten und der Bedenken hinsichtlich des Datenschutzes bei der Verwendung echter Daten ist es nicht schwer zu verstehen, warum. Es ist daher notwendig, dass Unternehmen mehr über synthetische Daten und die verschiedenen Tools erfahren, die ihnen bei der Generierung dieser Daten helfen.
Als nächstes sollten Sie sich über synthetische Überwachungs-Tools für Ihr Online-Geschäft informieren.