La ciencia de datos es para cualquiera a quien le guste desenredar cosas enmarañadas y descubrir maravillas ocultas en un aparente desorden.
Es como buscar agujas en pajares; sólo que los científicos de datos no necesitan ensuciarse las manos en absoluto. Utilizando herramientas extravagantes con gráficos de colores y mirando montones de números, se limitan a bucear en los pajares de datos y encontrar agujas valiosas en forma de percepciones de gran valor empresarial.
Una caja de herramientas típica de un científico de datos debería incluir al menos un elemento de cada una de estas categorías: bases de datos relacionales, bases de datos NoSQL, marcos de big data, herramientas de visualización, herramientas de scraping, lenguajes de programación, IDEs y herramientas de aprendizaje profundo.
Bases de datos relacionales
Una base de datos relacional es una colección de datos estructurada en tablas con atributos. Las tablas pueden vincularse entre sí, definiendo relaciones y restricciones, y creando lo que se denomina un modelo de datos. Para trabajar con bases de datos relacionales, se suele utilizar un lenguaje llamado SQL (Lenguaje de consulta estructurado).
Las aplicaciones que gestionan la estructura y los datos de las bases de datos relacionales se denominan RDBMS (Relational DataBase Management Systems). Existen muchas aplicaciones de este tipo, y las más relevantes han empezado a centrarse recientemente en el campo de la ciencia de datos, añadiendo funcionalidades para trabajar con repositorios de big data y aplicar técnicas como la analítica de datos y el aprendizaje automático.
Servidor SQL
El RDBMS de Microsoft, lleva más de 20 años evolucionando ampliando constantemente su funcionalidad empresarial. Desde su versión 2016, SQL Server ofrece una cartera de servicios que incluye soporte para código R incrustado. SQL Server 2017 sube la apuesta cambiando el nombre de sus servicios R a servicios de lenguaje de máquina y añadiendo compatibilidad con el lenguaje Python (más información sobre estos dos lenguajes más adelante).
Con estas importantes incorporaciones, SQL Server se dirige a los científicos de datos que quizá no tengan experiencia con Transact SQL, el lenguaje de consulta nativo de Microsoft SQL Server.

SQL Server dista mucho de ser un producto gratuito. Puede comprar licencias para instalarlo en un servidor Windows (el precio variará en función del número de usuarios simultáneos) o utilizarlo como un servicio de pago, a través de la nube Microsoft Azure. Aprender a utilizar Microsoft SQL Server es fácil.
MySQL
En el lado del software de código abierto, MySQL tiene la corona de popularidad de los RDBMS. Aunque Oracle es actualmente su propietario, sigue siendo libre y de código abierto bajo los términos de una Licencia Pública General GNU. La mayoría de las aplicaciones basadas en web utilizan MySQL como repositorio de datos subyacente, gracias a su conformidad con el estándar SQL.
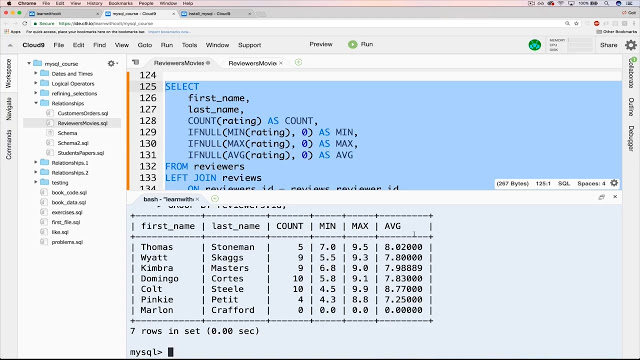
También contribuyen a su popularidad sus sencillos procedimientos de instalación, su gran comunidad de desarrolladores, toneladas de documentación exhaustiva y herramientas de terceros, como phpMyAdmin, que simplifican las actividades cotidianas de gestión. Aunque MySQL no dispone de funciones nativas para realizar análisis de datos, su carácter abierto permite su integración con casi cualquier herramienta de visualización, elaboración de informes e inteligencia empresarial que pueda elegir.
PostgreSQL
Otra opción de RDBMS de código abierto es PostgreSQL. Aunque no es tan popular como MySQL, PostgreSQL destaca por su flexibilidad y extensibilidad, y su soporte para consultas complejas, las que van más allá de las sentencias básicas como SELECT, WHERE y GROUP BY.
Estas características le están permitiendo ganar popularidad entre los científicos de datos. Otra característica interesante es el soporte para entornos múltiples, que permite utilizarlo en entornos en la nube y locales, o en una mezcla de ambos, lo que se conoce comúnmente como entornos en la nube híbridos.
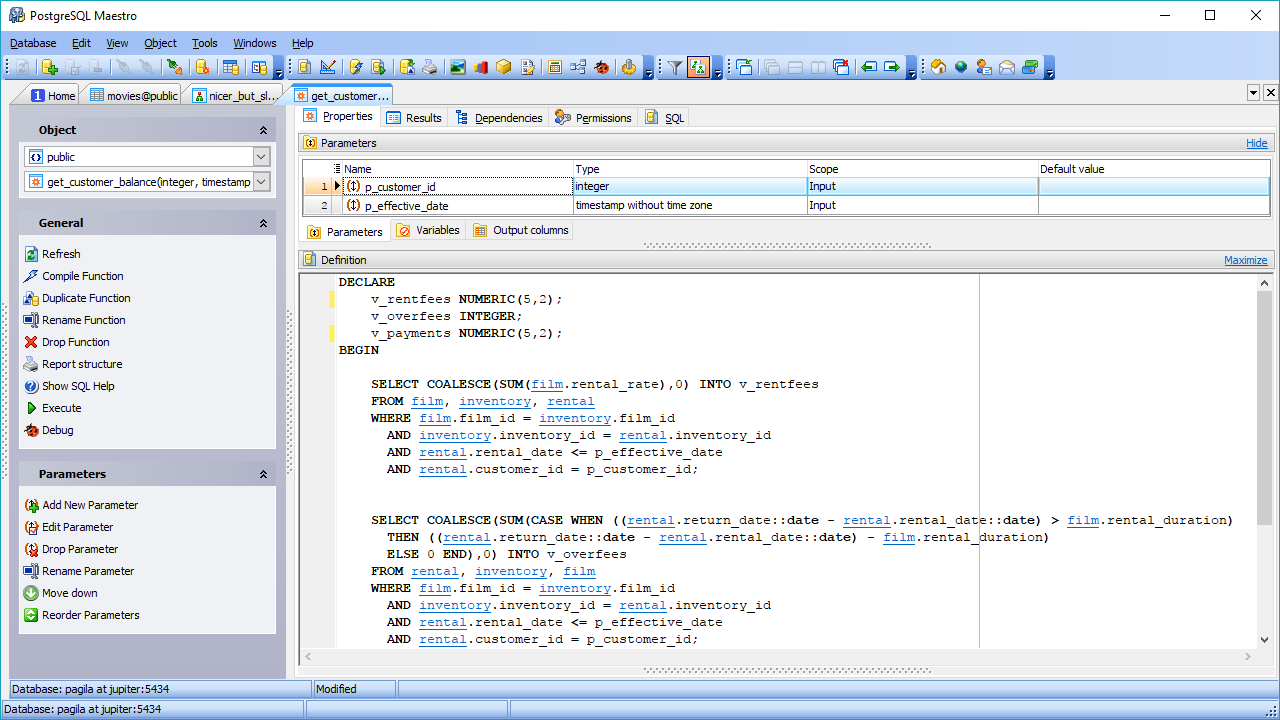
PostgreSQL es capaz de combinar el procesamiento analítico en línea (OLAP) con el procesamiento transaccional en línea (OLTP), trabajando en un modo denominado procesamiento transaccional/analítico híbrido (HTAP). También es muy adecuado para trabajar con big data, gracias a la incorporación de PostGIS para datos geográficos y JSON-B para documentos. PostgreSQL también admite datos no estructurados, lo que le permite estar en ambas categorías: Bases de datos SQL y NoSQL.
Bases de datos NoSQL
También conocidas como bases de datos no relacionales, este tipo de repositorio de datos proporciona un acceso más rápido a estructuras de datos no tabulares. Algunos ejemplos de estas estructuras son los gráficos, los documentos, las columnas anchas, los valores clave, entre muchos otros. Los almacenes de datos NoSQL pueden dejar de lado la coherencia de los datos en favor de otras ventajas, como la disponibilidad, la partición y la velocidad de acceso.
Dado que no existe SQL en los almacenes de datos NoSQL, la única forma de consultar este tipo de bases de datos es utilizando lenguajes de bajo nivel, y no existe ninguno tan ampliamente aceptado como el SQL. Además, no existen especificaciones estándar para NoSQL. Por eso, irónicamente, algunas bases de datos NoSQL están empezando a añadir soporte para scripts SQL.
MongoDB
MongoDB es un popular sistema de bases de datos NoSQL que almacena datos en forma de documentos JSON. Se centra en la escalabilidad y la flexibilidad para almacenar datos de forma no estructurada. Esto significa que no existe una lista fija de campos que deba respetarse en todos los elementos almacenados. Además, la estructura de los datos puede modificarse con el tiempo, algo que en una base de datos relacional implica un alto riesgo de afectar a las aplicaciones en ejecución.

La tecnología de MongoDB permite la indexación, las consultas ad hoc y la agregación, que proporcionan una base sólida para el análisis de datos. La naturaleza distribuida de la base de datos proporciona alta disponibilidad, escalado y distribución geográfica sin necesidad de herramientas sofisticadas.
Redis
Esta es otra opción en el frente de las NoSQL de código abierto. Es básicamente un almacén de estructuras de datos que opera en memoria y, además de proporcionar servicios de base de datos, también funciona como memoria caché y corredor de mensajes.

Admite un sinfín de estructuras de datos poco convencionales, como hashes, índices geoespaciales, listas y conjuntos ordenados. Es muy adecuado para la ciencia de datos gracias a su alto rendimiento en tareas intensivas en datos, como el cálculo de intersecciones de conjuntos, la ordenación de listas largas o la generación de clasificaciones complejas. La razón del extraordinario rendimiento de Redis es su funcionamiento en memoria. Puede configurarse para que persista los datos de forma selectiva.
Marcos de Big Data
Supongamos que tiene que analizar los datos que los usuarios de Facebook generan durante un mes. Hablamos de fotos, vídeos, mensajes, de todo. Teniendo en cuenta que cada día se añaden más de 500 terabytes de datos a la red social por parte de sus usuarios, es difícil medir el volumen que representa un mes entero de sus datos.
Para manipular esa enorme cantidad de datos de forma eficaz, se necesita un marco adecuado capaz de calcular estadísticas sobre una arquitectura distribuida. Dos son los marcos que lideran el mercado: Hadoop y Spark.
Hadoop
Como marco de macrodatos, Hadoop se ocupa de las complejidades asociadas a la recuperación, el procesamiento y el almacenamiento de enormes pilas de datos. Hadoop opera en un entorno distribuido, compuesto por clusters de ordenadores que procesan algoritmos sencillos. Existe un algoritmo orquestador, denominado MapReduce, que divide las tareas grandes en partes pequeñas y, a continuación, distribuye esas tareas pequeñas entre los clústeres disponibles.

Hadoop se recomienda para depósitos de datos de tipo empresarial que requieren un acceso rápido y una alta disponibilidad, todo ello en un esquema de bajo coste. Pero se necesita un administrador de Linux con profundos conocimientos de H adoop para mantener el esquema en funcionamiento.
Spark
Hadoop no es el único marco disponible para la manipulación de big data. Otro gran nombre en este ámbito es Spark. El motor Spark fue diseñado para superar a Hadoop en términos de velocidad de análisis y facilidad de uso. Aparentemente, logró este objetivo: algunas comparaciones dicen que Spark funciona hasta 10 veces más rápido que Hadoop cuando trabaja en disco, y 100 veces más rápido operando en memoria. También requiere un menor número de máquinas para procesar la misma cantidad de datos.

Además de la velocidad, otra ventaja de Spark es su compatibilidad con el procesamiento de flujos. Este tipo de procesamiento de datos, también llamado procesamiento en tiempo real, implica la entrada y salida continua de datos.
Herramientas de visualización
Un chiste común entre los científicos de datos dice que, si tortura los datos el tiempo suficiente, le confesarán lo que necesita saber. En este caso, «torturar» significa manipular los datos transformándolos y filtrándolos para visualizarlos mejor. Y ahí es donde entran en escena las herramientas de visualización de datos. Estas herramientas toman datos preprocesados de múltiples fuentes y muestran sus verdades reveladas en formas gráficas y comprensibles.
Hay cientos de herramientas que entran en esta categoría. Nos guste o no, la más utilizada es Microsoft Excel y sus herramientas de gráficos. Los gráficos de Excel están al alcance de cualquiera que utilice Excel, pero su funcionalidad es limitada. Lo mismo ocurre con otras aplicaciones de hojas de cálculo, como Google Sheets y Libre Office. Pero aquí estamos hablando de herramientas más específicas, especialmente diseñadas para la inteligencia empresarial (BI) y el análisis de datos.
Power BI
No hace mucho, Microsoft lanzó su aplicación de visualización Power BI. Puede tomar datos de diversas fuentes, como archivos de texto, bases de datos, hojas de cálculo y muchos servicios de datos en línea, incluidos Facebook y Twitter, y utilizarlos para generar cuadros de mando repletos de gráficos, tablas, mapas y muchos otros objetos de visualización. Los objetos del tablero son interactivos, lo que significa que puede hacer clic en una serie de datos de un gráfico para seleccionarla y utilizarla como filtro para los demás objetos del tablero.
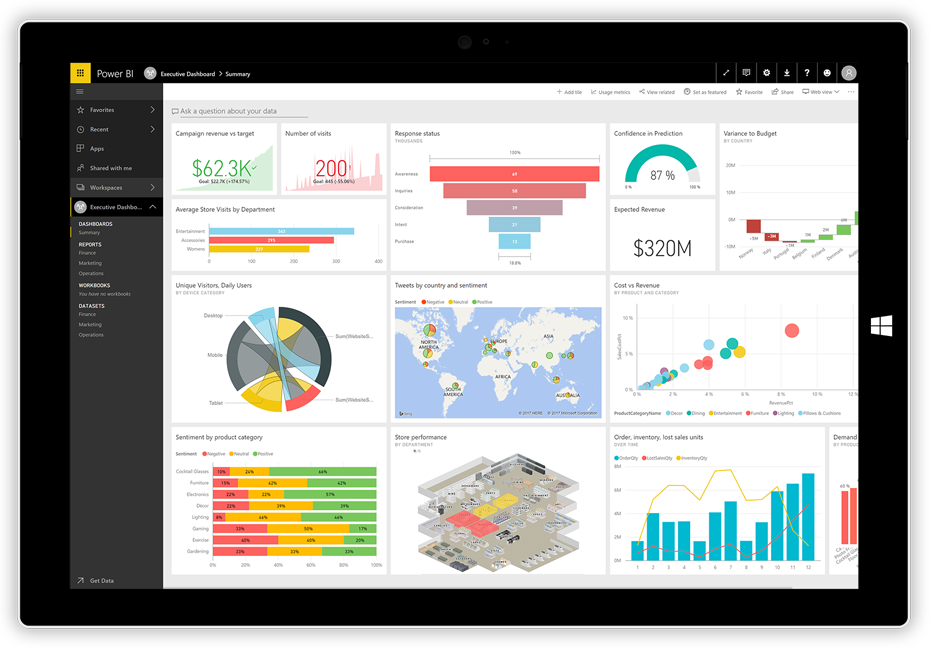
Power BI es una combinación de una aplicación de escritorio de Windows (parte del paquete Office 365), una aplicación web y un servicio en línea para publicar los cuadros de mando en la web y compartirlos con sus usuarios. El servicio le permite crear y gestionar permisos para conceder acceso a los tableros sólo a determinadas personas.
Tableau
Tableau es otra opción para crear cuadros de mando interactivos a partir de una combinación de múltiples fuentes de datos. También ofrece una versión de escritorio, una versión web y un servicio en línea para compartir los cuadros de mando que cree. Funciona de forma natural «con su forma de pensar» (como afirma), y es fácil de usar para personas sin conocimientos técnicos, lo que se ve reforzado por la gran cantidad de tutoriales y vídeos en línea.
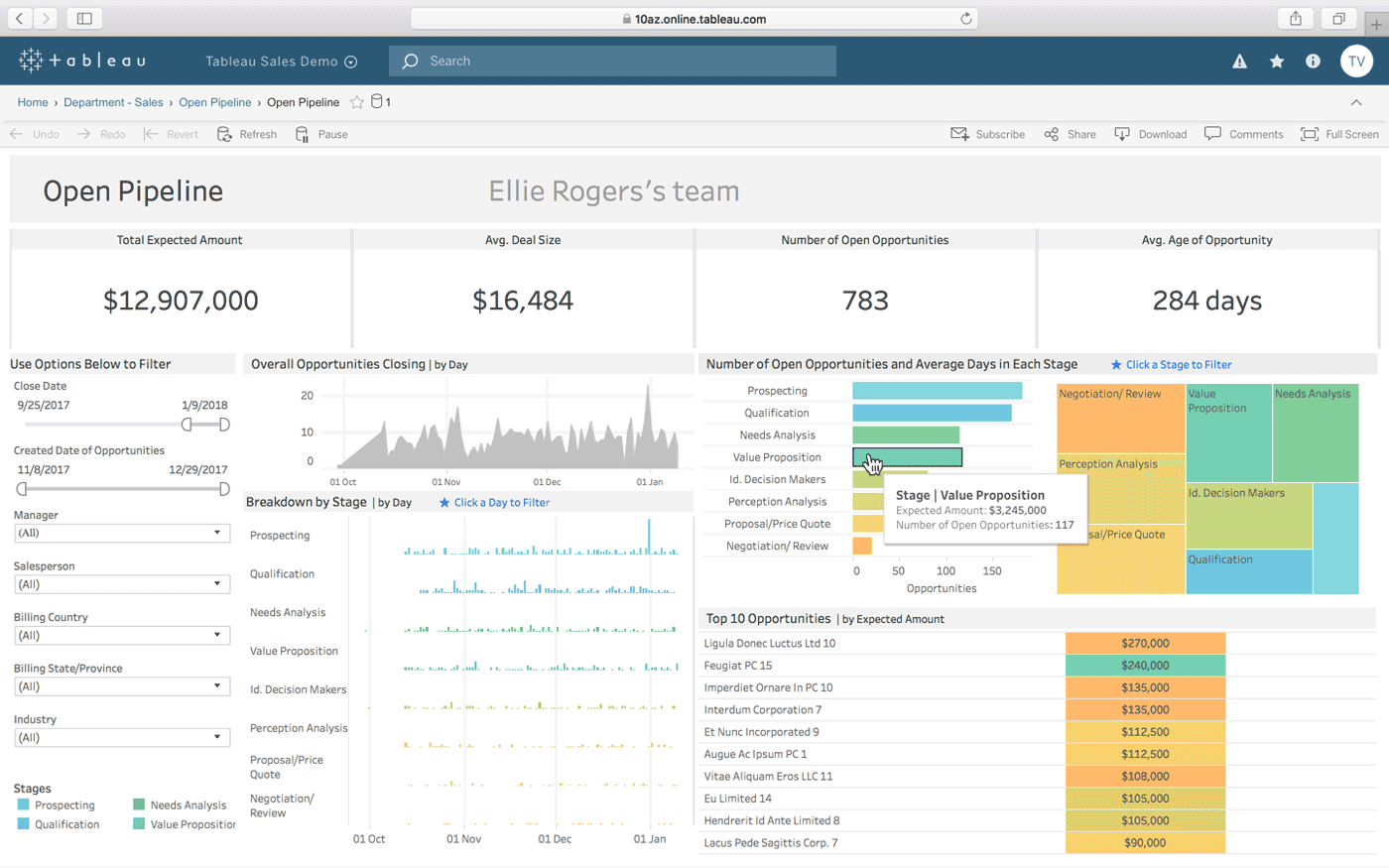
Algunas de las características más destacadas de Tableau son sus conectores de datos ilimitados, sus datos en vivo y en memoria, y sus diseños optimizados para móviles.
QlikView
QlikView ofrece una interfaz de usuario limpia y sencilla para ayudar a los analistas a descubrir nuevas perspectivas a partir de los datos existentes mediante elementos visuales fácilmente comprensibles para todos.
Esta herramienta es conocida por ser una de las plataformas de inteligencia empresarial más flexibles. Ofrece una función llamada Búsqueda Asociativa, que le ayuda a centrarse en los datos más importantes, ahorrándole el tiempo que le llevaría encontrarlos por su cuenta.
Con QlikView, puede colaborar con sus socios en tiempo real, realizando análisis comparativos. Todos los datos pertinentes pueden combinarse en una app, con funciones de seguridad que restringen el acceso a los datos.
Herramientas de scraping
En los tiempos en los que Internet acababa de surgir, los rastreadores web empezaron a viajar por las redes recopilando información a su paso. A medida que la tecnología evolucionó, el término web crawling cambió por web scraping, pero seguía significando lo mismo: extraer automáticamente información de sitios web. Para hacer web scraping, se utilizan procesos automatizados, o bots, que saltan de una página web a otra, extrayendo datos de ellas y exportándolos a diferentes formatos o insertándolos en bases de datos para su posterior análisis.
A continuación resumimos las características de tres de los raspadores web más populares disponibles en la actualidad.
Octoparse
El raspador webOctoparse ofrece algunas características interesantes, como herramientas integradas para obtener información de sitios web que no facilitan el trabajo a los robots de raspado. Es una aplicación de escritorio que no requiere codificación, con una interfaz de usuario fácil de usar que permite visualizar el proceso de extracción a través de un diseñador gráfico de flujos de trabajo.
Junto con la aplicación independiente, Octoparse ofrece un servicio basado en la nube para acelerar el proceso de extracción de datos. Los usuarios pueden experimentar una ganancia de velocidad de 4x a 10x cuando utilizan el servicio en la nube en lugar de la aplicación de escritorio. Si se queda con la versión de escritorio, puede utilizar Octoparse de forma gratuita. Pero si prefiere utilizar el servicio en la nube, tendrá que elegir uno de sus planes de pago.
Capturador de contenidos
Si busca una herramienta de raspado con muchas funciones, debería echarle un ojo a Content Grabber. A diferencia de Octoparse, para utilizar Content Grabber es necesario tener conocimientos avanzados de programación. A cambio, obtendrá edición de scripts, interfaces de depuración y otras funcionalidades avanzadas. Con Content Grabber, puede utilizar lenguajes .Net para escribir expresiones regulares. De este modo, no tendrá que generar las expresiones utilizando una herramienta incorporada.
La herramienta ofrece una API (interfaz de programación de aplicaciones) que puede utilizar para añadir funciones de raspado a sus aplicaciones web y de escritorio. Para utilizar esta API, los desarrolladores necesitan obtener acceso al servicio Content Grabber Windows.
ParseHub
Este raspador puede manejar una extensa lista de diferentes tipos de contenido, incluidos foros, comentarios anidados, calendarios y mapas. También puede tratar con páginas que contengan autenticación, Javascript, Ajax, etc. ParseHub puede utilizarse como aplicación web o como aplicación de escritorio capaz de ejecutarse en Windows, macOS X y Linux.
Al igual que Content Grabber, se recomienda tener ciertos conocimientos de programación para sacar el máximo partido a ParseHub. Dispone de una versión gratuita, limitada a 5 proyectos y 200 páginas por ejecución.
Lenguajes de programación
Al igual que el lenguaje SQL mencionado anteriormente está diseñado específicamente para trabajar con bases de datos relacionales, existen otros lenguajes creados con un claro enfoque hacia la ciencia de datos. Estos lenguajes permiten a los desarrolladores escribir programas que se ocupan del análisis masivo de datos, como la estadística y el aprendizaje automático.
SQL también se considera una habilidad importante que los desarrolladores deben tener para hacer ciencia de datos, pero eso se debe a que la mayoría de las organizaciones todavía tienen muchos datos en bases de datos relacionales. los «verdaderos» lenguajes de la ciencia de datos son R y Python.
Python

Python es un lenguaje de programación de alto nivel, interpretado y de propósito general, muy adecuado para el desarrollo rápido de aplicaciones. Tiene una sintaxis sencilla y fácil de aprender que permite reducir la curva de aprendizaje y los costes de mantenimiento de los programas. Hay muchas razones por las que es el lenguaje preferido para la ciencia de datos. Por mencionar algunas: potencial de scripting, verbosidad, portabilidad y rendimiento.
Este lenguaje es un buen punto de partida para los científicos de datos que planean experimentar mucho antes de lanzarse al trabajo real y duro de crujir datos, y que quieren desarrollar aplicaciones completas.
R
El lenguaje R se utiliza principalmente para el procesamiento estadístico de datos y la creación de gráficos. Aunque no está pensado para desarrollar aplicaciones completas, como sería el caso de Python, R se ha hecho muy popular en los últimos años debido a su potencial para la minería y el análisis de datos.

Gracias a una biblioteca cada vez mayor de paquetes disponibles gratuitamente que amplían su funcionalidad, R es capaz de realizar todo tipo de trabajos de machacamiento de datos, incluidos el modelado lineal/no lineal, la clasificación, las pruebas estadísticas, etc.
No es un lenguaje fácil de aprender, pero una vez que se familiarice con su filosofía, estará haciendo computación estadística como un profesional.
IDEs
Si está considerando seriamente dedicarse a la ciencia de datos, tendrá que elegir cuidadosamente un entorno de desarrollo integrado (IDE) que se adapte a sus necesidades, porque usted y su IDE pasarán mucho tiempo trabajando juntos.
Un IDE ideal debe reunir todas las herramientas que necesita en su trabajo diario como programador: un editor de texto con resaltado de sintaxis y autocompletado, un potente depurador, un explorador de objetos y un fácil acceso a herramientas externas. Además, debe ser compatible con el lenguaje de su preferencia, por lo que es una buena idea elegir su IDE después de saber qué lenguaje va a utilizar.
Spyder
Este IDE genérico está pensado sobre todo para científicos y analistas que también necesitan codificar. Para que se sientan cómodos, no se limita a la funcionalidad del IDE, sino que también proporciona herramientas para la exploración/visualización de datos y la ejecución interactiva, como podría encontrarse en un paquete científico. El editor de Spyder admite varios idiomas y añade un explorador de clases, división de ventanas, salto a la definición, autocompletado de código e incluso una herramienta de análisis de código.
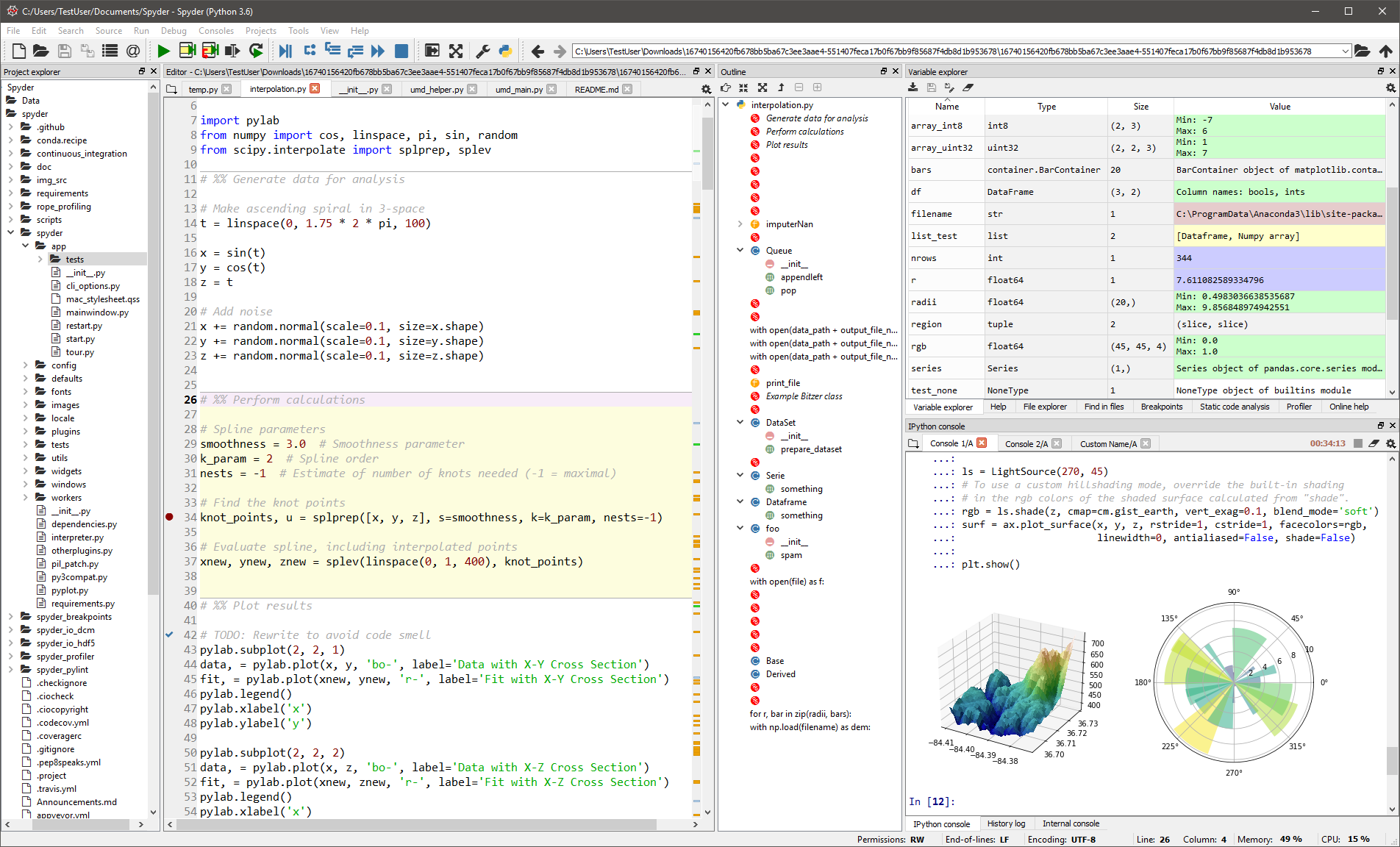
El depurador le ayuda a rastrear cada línea de código de forma interactiva, y un perfilador le ayuda a encontrar y eliminar ineficiencias.
PyCharm
Si programa en Python, lo más probable es que su IDE preferido sea PyCharm. Dispone de un editor de código inteligente con búsqueda inteligente, completado de código y detección y corrección de errores. Con un solo clic, puede saltar del editor de código a cualquier ventana relacionada con el contexto, incluyendo prueba, supermétodo, implementación, declaración y más. PyCharm es compatible con Anaconda y muchos paquetes científicos, como NumPy y Matplotlib, por citar sólo dos de ellos.
Ofrece integración con los sistemas de control de versiones más importantes, y también con un ejecutor de pruebas, un perfilador y un depurador. Para cerrar con broche de oro, también se integra con Docker y Vagrant para facilitar el desarrollo multiplataforma y la contenerización.
RStudio
Para aquellos científicos de datos que prefieren el equipo R, el IDE de elección debe ser RStudio, debido a su gran cantidad de características. Puede instalarlo en un escritorio con Windows, macOS o Linux, o podría ejecutarlo desde un navegador web si no desea instalarlo localmente. Ambas versiones ofrecen ventajas como el resaltado de sintaxis, la sangría inteligente y la finalización de código. Hay un visor de datos integrado que resulta muy útil cuando necesita examinar datos tabulares.
El modo de depuración permite ver cómo se actualizan los datos dinámicamente al ejecutar un programa o script paso a paso. Para el control de versiones, RStudio integra soporte para SVN y Git. Un buen plus es la posibilidad de crear gráficos interactivos, con las bibliotecas Shiny y gives.
Su caja de herramientas personal
Llegados a este punto, debería tener una visión completa de las herramientas que debería conocer para destacar en la ciencia de datos. Además, esperamos haberle dado suficiente información para decidir cuál es la opción más conveniente dentro de cada categoría de herramientas. Ahora depende de usted. La ciencia de datos es un campo floreciente donde desarrollar una carrera profesional. Pero si quiere hacerlo, debe mantenerse al día de los cambios en las tendencias y las tecnologías, ya que se producen casi a diario.