Los datos son el alma de cualquier empresa. Es la clave del éxito y resulta esencial para recopilar información, tomar decisiones y mejorar las operaciones.
Una empresa depende de sus datos y aplicaciones para funcionar cada día. Pero, ¿qué ocurre cuando falla una de sus bases de datos o sistemas?
Toda la información y los datos críticos de la empresa podrían estar en peligro.
Afortunadamente, hay formas de evitar que esto ocurra. Uno de los métodos más eficaces para proteger los datos empresariales es la replicación de bases de datos. Es algo que toda pequeña, mediana y gran empresa debe adaptar para sobrevivir en la competencia.
En este artículo, hablaré de qué es la replicación de datos, cómo funciona y otros aspectos importantes.
Así que, ¡empecemos!
¿Qué es la replicación de bases de datos?
La transferencia de datos de una base de datos de origen a una o varias bases de datos de destino se conoce como replicación de bases de datos. A menudo implica copiar o transmitir datos de una base de datos a otra para que todos los usuarios puedan acceder a datos sincronizados, independientemente del sistema que utilicen para visualizarlos.

Si los datos cambian, una herramienta de replicación de datos se asegurará de que los cambios también se apliquen en la base de datos de destino. Como resultado, se crea una red distribuida de almacenamiento de datos con mayor disponibilidad en múltiples ubicaciones, lo que permite a todos acceder rápidamente a datos vitales y relevantes.
Utilizando una solución de replicación de datos, es probable que note una mejora en la coherencia de los datos en cada nodo, una reducción de la redundancia de datos, una mayor fiabilidad de los datos y, finalmente, un aumento del rendimiento.
La replicación de bases de datos puede producirse en tiempo real, a medida que los datos se crean, editan y destruyen en la base de datos de origen o como parte de una operación por lotes.
¿Cómo funciona la replicación de datos?
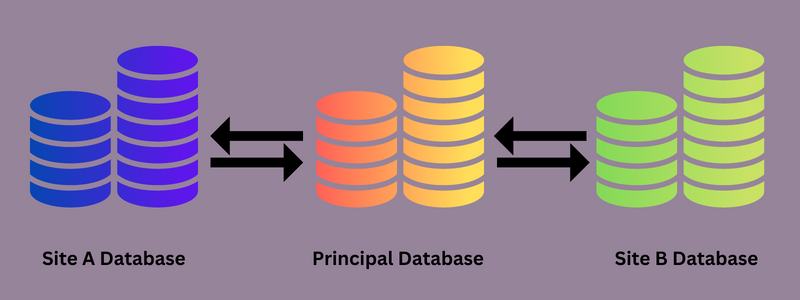
La replicación de bases de datos puede realizarse una sola vez o como un proceso continuo. Implica a todas las fuentes de datos de una organización, y se utiliza un sistema de gestión de bases de datos distribuidas (DDBMS) para transferir o distribuir los datos a todas las fuentes.
Todos los cambios, adiciones y supresiones realizados en la base de datos de origen se sincronizan automáticamente con las demás bases de datos de destino si dichos cambios son necesarios. Según el paradigma convencional de software Editor-Suscriptor, en el proceso de replicación de datos intervienen uno o varios «editores» y «suscriptores».
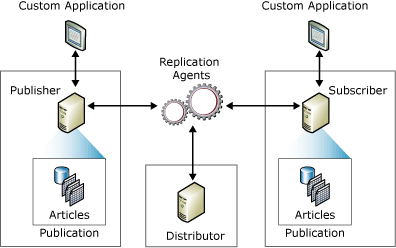
Un «publicador» es un sistema o la base de datos de origen en la que se realizan los cambios, y un «suscriptor» es un sistema en el que se replican los cambios.
Cualquier modificación realizada en un sistema «publicador» se replica después en las bases de datos «suscriptoras». Los usuarios también pueden realizar cambios en las bases de datos de los suscriptores, que luego se replican en la base de datos del editor. Esto distribuye los cambios a todos los demás abonados de la red si el sistema es bidireccional.
Además, la mayoría de los abonados tienen un enlace fijo con el editor, lo que permite que los cambios o actualizaciones se produzcan automáticamente sin intervención manual. Estas actualizaciones pueden producirse por lotes a intervalos regulares o pueden activarse y aplicarse en tiempo real.
Tipos de replicación de bases de datos
Algunos de los tipos de replicación de bases de datos son:
#1. Replicación de tabla completa
La replicación de tabla completa crea una copia de la base de datos de origen completa en el almacenamiento de destino. Traslada las filas del editor al suscriptor, incluidas las filas nuevas, modificadas y existentes.
Sin embargo, este enfoque de replicación va unido a un elevado coste de mantenimiento debido a los requisitos de potencia informática y ancho de banda de red necesarios para copiarlo todo. Sobrecarga la red y puede crear retrasos en la replicación, especialmente cuando el volumen de datos es mayor.
#2. Replicación de instantáneas
En esta replicación de bases de datos se utiliza una instantánea de la base de datos de origen para replicar los datos en la base de datos de destino. No tiene en cuenta los cambios de datos como nuevos, actualizados o eliminados; en su lugar, crea una copia de lo que recoge en ese momento.
Cuando los cambios de datos son muy pocos, esta técnica de replicación es preferible. Es significativamente más rápida que la replicación de tabla completa, pero no hace un seguimiento de los datos borrados con fuerza.

#3. Replicación por fusión
La replicación por fusión es un proceso que transfiere y distribuye objetos y datos de una base de datos a otra con sincronización de bases de datos. Es complejo, ya que este proceso permite a los suscriptores y editores modificar la base de datos, lo que provoca frecuentes conflictos de datos relacionados con las versiones.
Los agentes de fusión desplegados en los servidores sincronizan todos los cambios y siguen un proceso predefinido de resolución de conflictos para resolver cualquier conflicto de datos.
#4. Replicación incremental basada en claves
La replicación incremental basada en claves comprueba las claves o índices de una base de datos en busca de cambios como borrado, nuevo y actualizado. A continuación, el mecanismo de replicación copia en la base de datos réplica sólo las claves de replicación necesarias para reflejar los cambios desde la última actualización. Estas claves suelen ser una marca de tiempo, una fecha o un número entero.
Dado que sólo se replican en la base de datos de réplica los cambios indicados, el proceso es más rápido. Desgraciadamente, este método no permite los borrados duros porque el valor crítico se elimina borrando el registro de la base de datos primaria.
#5. Replicación incremental basada en registros
Este tipo de replicación de bases de datos duplica los datos según el archivo de registro binario de la base de datos. Al inspeccionar el archivo de registro binario, éste le proporcionará información sobre los cambios realizados en la base de datos primaria, por ejemplo, actualizaciones, inserciones o eliminaciones. A continuación, se realizan las mismas modificaciones o actualizaciones en su base de datos de destino.
Este es uno de los métodos de replicación de datos más utilizados, ya que es eficaz, especialmente para las bases de datos estáticas. Además, la mayoría de los proveedores de bases de datos lo soportan, incluidos Oracle, MongoDB, MySQL y PostgreSQL.
#6. Replicación transaccional
Cuando se produce una novedad en los datos de origen, la replicación transaccional mueve todos los datos existentes de la base de datos de origen a la de destino. A continuación, ejecuta la misma transacción en las réplicas.
Aunque es un método de replicación eficaz, los modelos se utilizan sobre todo en actividades de lectura y no permiten operaciones de creación, borrado o actualización.
¿Por qué es importante la replicación de bases de datos?

La replicación de bases de datos es importante por las siguientes razones:
Fiabilidad y disponibilidad de los datos
La replicación de datos favorece la disponibilidad de los datos. Desempeña un papel importante cuando un servidor falla en circunstancias inusuales al proporcionar copias de seguridad de la base de datos. De este modo, puede salvarle el día porque los datos están disponibles en otras ubicaciones. Además, mejora la fiabilidad de los datos al mantener los datos relevantes y más recientes guardados de forma segura en varios servidores.
Recuperación en caso de desastre
La replicación de bases de datos es útil durante un escenario de fallo del servidor. Es una maravillosa técnica de gestión y recuperación de desastres ya que replica y almacena los datos y los cambios recientes en otras ubicaciones del servidor en lugar de depender de un único servidor.
Rendimiento del servidor
El acceso a los datos es mucho más rápido cuando éstos se procesan y operan en varios servidores. Además, los administradores pueden liberar ciclos de procesamiento en el servidor original para operaciones de escritura que consumen más recursos dirigiendo todas las operaciones de lectura de datos a una réplica.
Mejor rendimiento de la red
Mantener varias copias de los mismos datos en diferentes ubicaciones puede reducir la latencia del acceso a los datos, ya que puede recuperar los datos relevantes desde la ubicación en la que se ejecuta la transacción.
Por ejemplo, los usuarios de los países europeos pueden tener problemas de latencia al acceder a los datos desde los centros de datos australianos. Por lo tanto, colocar una réplica de estos datos cerca del usuario puede mejorar los tiempos de acceso a la vez que equilibra la tensión de la red.
Mejora del rendimiento del sistema de pruebas

La replicación de bases de datos agiliza la distribución y sincronización de datos para los sistemas de prueba que requieren un acceso rápido para agilizar la toma de decisiones.
Copia de seguridad de bases de datos frente a replicación de bases de datos
Tanto la copia de seguridad de la base de datos como la replicación de la base de datos varían en varios aspectos. Algunas de ellas son las siguientes:
- Las copias de seguridad de las bases de datos deben reconstruirse y restaurarse antes de poder utilizarse. A diferencia de las copias de seguridad de bases de datos, la replicación de datos no requiere reconstrucción y puede utilizarse inmediatamente.
- Las copias de seguridad de bases de datos constan de archivos o carpetas, archivos de datos de bases de datos y archivos de aplicaciones, dependiendo de los protocolos organizativos de copia de seguridad-restauración. En cambio, la replicación de bases de datos suele utilizarse para duplicar volúmenes o sistemas de archivos completos, bases de datos y aplicaciones.
- Tanto la copia de seguridad como la replicación son medidas de protección de datos. La primera tiene por objeto reducir los Objetivos de Punto de Recuperación (OPR) y evitar la pérdida de datos. Mientras que la segunda está diseñada para reducir los Objetivos de Tiempo de Recuperación (RTO), asegurando la continuidad del negocio y minimizando el tiempo de inactividad.
- La copia de seguridad de las bases de datos es un método de bajo coste para evitar la pérdida total de datos. Es esencial para el cumplimiento de las normas y no garantiza la continuidad operativa. Por el contrario, la replicación garantiza que las aplicaciones y los procesos empresariales estén siempre disponibles, incluso después de un apagón.
- La copia de seguridad de bases de datos tiene que ver con el cumplimiento y la recuperación granular, como el almacenamiento a largo plazo de los registros de la empresa. Por otro lado, la replicación y la recuperación de bases de datos se centran en la recuperación en caso de desastre, la reanudación rápida y fácil de las operaciones tras un apagón o una corrupción.
- La copia de seguridadde bases de datos se utiliza habitualmente en el lugar de trabajo para todo, desde los servidores de producción hasta los ordenadores de sobremesa. Por el contrario, la replicación de bases de datos se utiliza con frecuencia para aplicaciones de misión crítica que deben estar siempre disponibles.
Técnicas de replicación de bases de datos

Las organizaciones pueden replicar los datos siguiendo una técnica precisa para trasladarlos. Estas estrategias difieren de los tipos de replicación descritos anteriormente.
#1. Réplica completa de bases de datos
La replicación completa de bases de datos replica una base de datos completa para su uso en distintos hosts. Esto garantiza la mayor redundancia y disponibilidad de datos. Para las empresas globales, esto permite a los usuarios de Asia acceder a los mismos datos que sus homólogos de Norteamérica a la misma velocidad. Si el servidor asiático falla, los usuarios pueden utilizar sus servidores europeos o norteamericanos como copia de seguridad.
Sin embargo, el inconveniente de esta técnica es la lentitud del procedimiento de actualización. También es difícil mantener la coherencia en la ubicación de cada archivo, lo que resulta significativo si los datos cambian continuamente.
#2. Replicación parcial de bases de datos
La replicación parcial de bases de datos es el proceso mediante el cual los datos de una base de datos se separan en trozos y se guardan en ubicaciones diferentes, en función de la relevancia de cada sitio.
Los peritos de seguros, los asesores financieros y los profesionales de ventas se benefician de la replicación parcial. Estos empleados pueden llevar las bases de datos parciales en otros dispositivos u ordenadores portátiles y sincronizarlas rutinariamente con un servidor central.
Para los analistas, puede resultar más económico mantener los datos europeos en Europa, los australianos en Australia, etc. Esto significa mantener los datos cerca de los consumidores al tiempo que se conserva un conjunto de datos completo en la sede central para los análisis de alto nivel.
Inconvenientes de la replicación de bases de datos

Aunque la replicación de datos puede aportar un valor significativo a su trabajo y a su empresa, también conlleva los siguientes inconvenientes:
Costes más elevados
Cuando los datos se replican y almacenan en varias ubicaciones, requieren más espacio de almacenamiento y recursos informáticos. Esta mayor demanda de hardware y recursos informáticos puede conllevar costes más elevados, como la compra y el mantenimiento de dispositivos de almacenamiento, servidores e infraestructura de red adicionales.
Limitaciones de tiempo
La replicación de datos es un proceso complejo que implica copiar datos de una ubicación a otras múltiples y mantener la coherencia en todas las copias. Este proceso puede llevar un tiempo considerable, especialmente para las organizaciones que deben replicar grandes cantidades de datos.
Ancho de banda
A medida que aumenta el volumen de datos que se replican, también aumentan los requisitos de ancho de banda, lo que puede sobrecargar los recursos de la red.
Datos incoherentes
Cuando se replican datos en un entorno distribuido, existe el riesgo de que los datos queden desincronizados si las actualizaciones no se realizan de forma coherente en todas las réplicas. Esto puede dar lugar a datos incoherentes y puede requerir un esfuerzo adicional para resolverlo.
Casos de uso de la replicación de bases de datos

Hay muchos casos en los que se puede utilizar la replicación de datos, como por ejemplo
Equilibrio de carga
Al replicar los datos en varios servidores, la carga se distribuye entre estos servidores para mejorar su rendimiento. De este modo, el equilibrio de la carga garantiza que un único servidor no se vea desbordado por demasiadas peticiones y que el sistema siga estando disponible y respondiendo incluso en periodos de mucho tráfico.
Almacén de datos
Un almacén de datos es un depósito centralizado para almacenar grandes cantidades de datos procedentes de múltiples fuentes. La replicación de los datos de estas fuentes en el almacén de datos permite a las organizaciones analizar e informar sobre sus datos de forma centralizada y organizada.
Despliegue interregional
La replicación de datos en varias regiones permite a las organizaciones mejorar la accesibilidad y la redundancia de los datos. Si una región experimenta una interrupción, se puede seguir accediendo a los datos desde otra región. Además, tener los datos en varias regiones puede ayudar a mejorar la velocidad de acceso para los usuarios de distintas partes del mundo.
Copia de seguridad y archivo
Replicar los datos en un almacenamiento secundario ayuda a las organizaciones a mantener una copia a largo plazo de sus datos. Esto les permite acceder a los datos con facilidad y garantiza que no se pierdan aunque falle el almacenamiento primario.
Sincronización de datos
La replicación de datos entre varios sistemas ayuda a garantizar que los datos permanezcan sincronizados, coherentes y actualizados en todas partes. Esto es importante para aplicaciones como el comercio electrónico, en las que los mismos datos deben ser accesibles desde múltiples sistemas.
Colaboración entre varios sitios
La replicación de datos entre varios sitios permite a las organizaciones compartir datos en tiempo real, lo que posibilita la colaboración y el aumento de la productividad. Esto resulta especialmente útil para organizaciones con equipos en múltiples ubicaciones o empresas que necesitan compartir datos con socios o clientes.
Recursos de aprendizaje
He aquí algunos recursos de aprendizaje que le ayudarán a comprender mejor el tema:
#1. Replicación de bases de datos por Bettina Kemme
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Database Replication (Synthesis Lectures on Data Management) | Buy on Amazon |
Este libro le ayudará a comprender los diferentes mecanismos de control de concurrencia y réplica, así como las cuestiones que le conciernen.
#2. Replicación de Bases de Datos: Una Guía Completa:
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Database Replication A Complete Guide – 2020 Edition | Buy on Amazon |
Este libro le preparará para afrontar los retos de la replicación de bases de datos explicando y respondiendo a sus preguntas.
Conclusión
La replicación de datos es una estrategia infravalorada en el mundo actual de rápido crecimiento e impulsado por los datos. Si es usted propietario de una empresa, se sorprenderá de sus ventajas.
Sin embargo, a medida que crece el número de fuentes y destinos, las empresas deben estar preparadas para afrontar los retos que ello conlleva. Por eso, una estrategia de replicación de datos fiable y escalable puede resultarle muy útil.
También puede explorar algún software útil de monitorización de bases de datos para analizar el rendimiento.