Apache Kafka es un servicio de transmisión de mensajes que permite a diferentes aplicaciones de un sistema distribuido comunicarse y compartir datos a través de mensajes.
Funciona como un sistema pub/sub en el que las aplicaciones productoras publican mensajes y los sistemas consumidores se suscriben a ellos.
Apache Kafka le permite adoptar una arquitectura poco acoplada entre las partes de su sistema que producen y consumen datos. Esto simplifica el diseño y la gestión del sistema. Kafka se apoya en Zookeeper para la gestión de metadatos y la sincronización de los distintos elementos del cluster.

Características de Apache Kafka
ApacheKafka se ha hecho popular, entre otras razones, por ser
- Escalable a través de clusters y particiones
- Rápido capaz de realizar 2 millones de escrituras por segundo
- Mantiene el orden de envío de los mensajes
- Fiable gracias a su sistema de réplicas
- Puede actualizarse sin tiempo de inactividad
Ahora, exploremos algunos de los casos de uso comunes de Kafka.
Casos de uso comunes de Apache Kafka
Kafka se utiliza a menudo en el procesamiento de big data, el registro y la agregación de eventos como clics de botones para análisis, y la combinación de registros de diferentes partes de un sistema en una ubicación central.
Ayuda a posibilitar la comunicación entre diferentes aplicaciones de un sistema y el procesamiento en tiempo real de datos procedentes de dispositivos IoT.
Ahora, veamos los pasos detallados para instalar Kafka en Windows y Linux.
Instalación de Kafka en Windows
En primer lugar, compruebe si Java está instalado en su máquina para instalar Apache Kafka en Windows. Abra el símbolo del sistema en modo Administrador e introduzca el comando
java --versionSi Java está instalado, debería obtener el número de versión del JDK actualmente instalado.
Si obtiene un mensaje de error diciendo que el comando no fue reconocido, Java no fue instalado, y necesita instalar Java. Para instalar Java, diríjase a Adoptium.net y haga clic en el botón de descarga.
Esto debería descargar el archivo instalador de Java. Cuando finalice la descarga, ejecute el instalador. Esto debería abrir el prompt de instalación.
Pulse, Siguiente repetidamente para elegir las opciones por defecto. La instalación debería entonces comenzar. Verifique la instalación cerrando el símbolo del sistema, volviendo a abrir otro símbolo del sistema en modo Administrador e introduciendo el comando
java --versionEsta vez, debería obtener la versión del JDK que acaba de instalar. Una vez completada la instalación, podemos empezar a instalar Kafka.
Para instalar Kafka, vaya primero al sitio web de Kafka.

Haga clic en el enlace, y debería llevarle a la página de descargas. Descargue los últimos binarios disponibles.
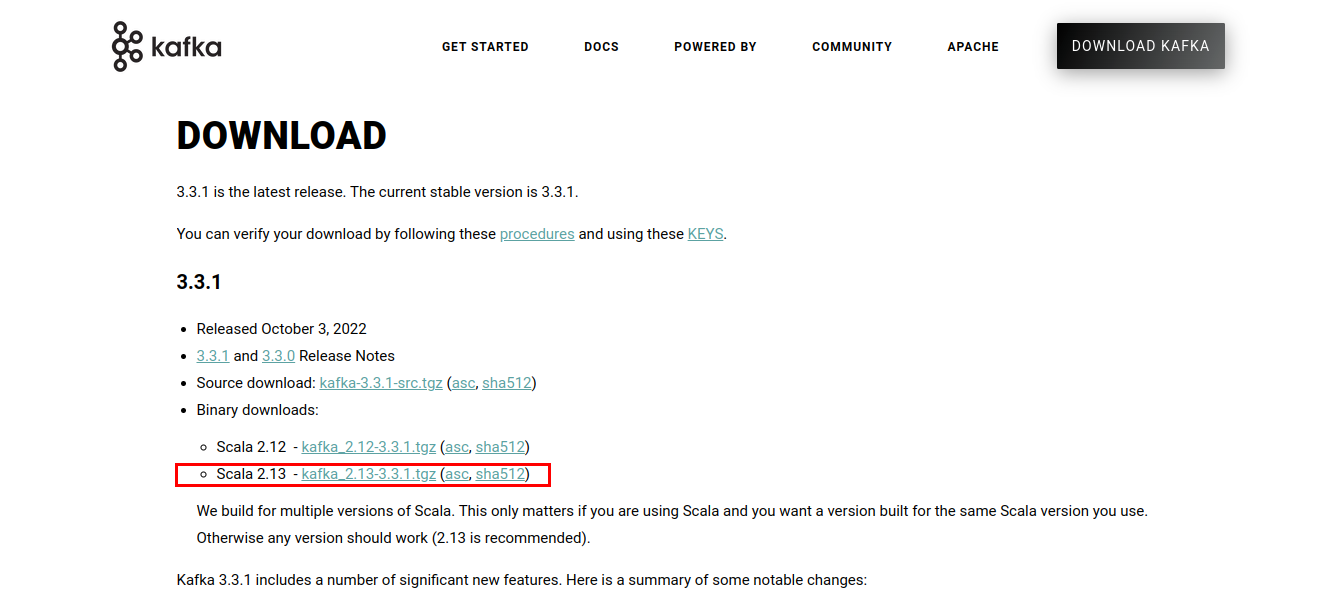
Esto descargará los scripts y binarios de Kafka empaquetados en un archivo .tgz. Tras la descarga, deberá extraer los archivos del archivo .tgz. Para extraerlos, utilizaré WinZip, que puede descargarse del sitio web de WinZip.
Una vez extraído el archivo, muévalo a la carpeta C:\ de forma que la ruta del archivo pase a ser C:\kafka
A continuación, abra el símbolo del sistema en modo Administrador e inicie Zookeeper navegando primero hasta el directorio Kafka. Y ejecutando el archivo zookeeper-server-start.bat con zookeeper.properties como archivo de configuración
cd C:\kafka
bin\windows\zookeeper-server-start.bat config\zookeeper.propertiesCon Zookeeper en ejecución, necesitamos añadir el archivo ejecutable wmic que utiliza Kafka en el PATH de nuestro sistema,
set PATH=C:\Windows\System32\wbem\;%PATH%;Después de esto, inicie el servidor Apache Kafka abriendo otra sesión de símbolo del sistema en modo Administrador y navegando hasta la carpeta C :\kafka
cd C:\kafkaA continuación, inicie Kafka ejecutando
bin\windows\kafka-server-start.bat config\server.propertiesCon esto, Kafka debería estar ejecutándose. Puede personalizar las propiedades del servidor, como dónde se escriben los registros en el archivo server . properties.
Instalación de Kafka en Linux
En primer lugar, asegúrese de que su sistema está al día actualizando todos los paquetes
sudo apt update && sudo apt upgradeA continuación, compruebe si Java está instalado en su máquina ejecutando
java --versionSi java está instalado, verá el número de versión. Sin embargo, si no lo está, puede instalarlo utilizando apt.
sudo apt install default-jdkDespués de esto, podemos instalar Apache Kafka descargando los binarios del sitio web.
Abra su terminal y navegue hasta la carpeta donde se guardó la descarga. En mi caso, tengo que navegar a la carpeta Descargas.
cd DescargasUna vez en la carpeta de descargas, extraiga los archivos descargados utilizando tar:
tar -xvzf kafka_2.13-3.3.1.tgzNavegue hasta la carpeta extraída
cd kafka_2.13-3.3.1.tgzEnumere los directorios y archivos.
Una vez en la carpeta, inicie un servidor Zookeeper ejecutando el script zookeeper-server-start.sh situado en el directorio bin de la carpeta extraída.
El script requerirá un archivo de configuración de Zookeeper. El archivo por defecto se llama zookeeper. properties y se encuentra en el subdirectorio config.
Así que para iniciar el servidor, utilice el comando
bin/zookeeper-server-start.sh config/zookeeper.propertiesCon Zookeeper en marcha, podemos iniciar el servidor Apache Kafka. El script kafka-server-start.sh también se encuentra en el directorio bin. El comando también espera un archivo de configuración. El predeterminado es server.properties almacenado en el archivo config.
bin/kafka-server-start.sh config/server.propertiesEsto debería poner en marcha Apache Kafka. Dentro del directorio bin, encontrará muchos scripts para hacer cosas como crear temas, gestionar productores y gestionar consumidores. También puede personalizar las propiedades del servidor en el archivo server.properties.
Palabras finales
En esta guía hemos repasado cómo instalar Java y Apache Kafka. Aunque puede instalar y gestionar clústeres de Kafka manualmente, también puede utilizar opciones gestionadas como Amazon Web Services y Confluent.
A continuación, puede aprender el procesamiento de datos con Kafka y Spark.