
El aprendizaje conjunto puede ayudarle a tomar mejores decisiones y a resolver muchos retos de la vida real combinando las decisiones de varios modelos.
El aprendizaje automático (ML) sigue expandiendo sus alas en múltiples sectores e industrias, ya sean las finanzas, la medicina, el desarrollo de aplicaciones o la seguridad.
Entrenar adecuadamente los modelos de ML le ayudará a lograr un mayor éxito en su negocio o puesto de trabajo, y existen varios métodos para conseguirlo.
En este artículo, hablaré sobre el aprendizaje conjunto, su importancia, casos de uso y técnicas.
¡Permanezca atento!
¿Qué es el aprendizaje por conjuntos?
En el aprendizaje automático y la estadística, «conjunto» se refiere a los métodos que generan varias hipótesis utilizando un aprendiz base común.

Y el aprendizaje por conjuntos es un enfoque de aprendizaje automático en el que se crean y combinan estratégicamente varios modelos (como expertos o clasificadores) con el objetivo de resolver un problema computacional o hacer mejores predicciones.
Este enfoque busca mejorar el rendimiento de predicción, aproximación de funciones, clasificación, etc., de un modelo dado. También se utiliza para eliminar la posibilidad de que elija un modelo pobre o menos valioso entre muchos. Para lograr un mejor rendimiento predictivo, se utilizan varios algoritmos de aprendizaje.
Aprendizaje por conjuntos en ML
En los modelos de aprendizaje automático, hay algunas fuentes como el sesgo, la varianza y el ruido que pueden causar errores. El aprendizaje por conjuntos puede ayudar a reducir estas fuentes causantes de errores y garantizar la estabilidad y precisión de sus algoritmos de ML.
A continuación le explicamos por qué se utiliza el aprendizaje por conjuntos en diversos escenarios:
Elección del clasificador adecuado
El aprendizaje por conjuntos le ayuda a elegir un modelo o clasificador mejor al tiempo que reduce el riesgo que puede derivarse de una mala selección del modelo.

Existen diferentes tipos de clasificadores utilizados para distintos problemas, como las máquinas de vectores soporte (SVM), los perceptrones multicapa (MLP), los clasificadores Bayes ingenuos, los árboles de decisión, etc. Además, hay diferentes realizaciones de algoritmos de clasificación que debe elegir. El rendimiento de los distintos datos de entrenamiento también puede ser diferente.
Pero en lugar de seleccionar un solo modelo, si utiliza un conjunto de todos estos modelos y combina sus resultados individuales, puede evitar seleccionar modelos más pobres.
Volumen de datos
Muchos métodos y modelos de ML no son tan eficaces en sus resultados si los alimenta con datos inadecuados o con un gran volumen de datos.
En cambio, el aprendizaje por conjuntos puede funcionar en ambos escenarios, incluso si el volumen de datos es escaso o excesivo.
- Si hay datos inadecuados, puede utilizar el bootstrap para entrenar varios clasificadores con la ayuda de diferentes muestras de datos bootstrap.
- Si hay un gran volumen de datos que puede hacer que el entrenamiento de un único clasificador sea un reto, entonces puede dividir estratégicamente los datos en subconjuntos más pequeños.
Complejidad

Un único clasificador puede no ser capaz de resolver algunos problemas de gran complejidad. Sus límites de decisión separando datos de varias clases podrían ser altamente complejos. Así, si se aplica un clasificador lineal a una frontera no lineal y compleja, no será capaz de aprenderla.
Sin embargo, al combinar adecuadamente un conjunto de clasificadores lineales adecuados, puede hacer que aprenda un límite no lineal dado. El clasificador dividirá los datos en muchas particiones más pequeñas y fáciles de aprender, y cada clasificador aprenderá sólo una partición más sencilla. A continuación, se combinarán los distintos clasificadores para producir un límite de decisión aproximado.
Estimación de la confianza
En el aprendizaje por conjuntos, se asigna un voto de confianza a una decisión que ha tomado un sistema. Supongamos que tiene un conjunto de varios clasificadores entrenados en un problema determinado. Si la mayoría de los clasificadores están de acuerdo con la decisión tomada, su resultado puede considerarse como un conjunto con una decisión de alta confianza.
Por otro lado, si la mitad de los clasificadores no están de acuerdo con la decisión tomada, se dice que es un conjunto con una decisión de baja confianza.
Sin embargo, una confianza baja o alta no siempre es la decisión correcta. Pero existe una alta probabilidad de que una decisión con alta confianza sea correcta si el conjunto está correctamente entrenado.
Precisión con la fusión de datos
Los datos recogidos de múltiples fuentes, cuando se combinan estratégicamente, pueden mejorar la precisión de las decisiones de clasificación. Esta precisión es superior a la que se obtiene con la ayuda de una sola fuente de datos.
¿Cómo funciona el aprendizaje por conjuntos?
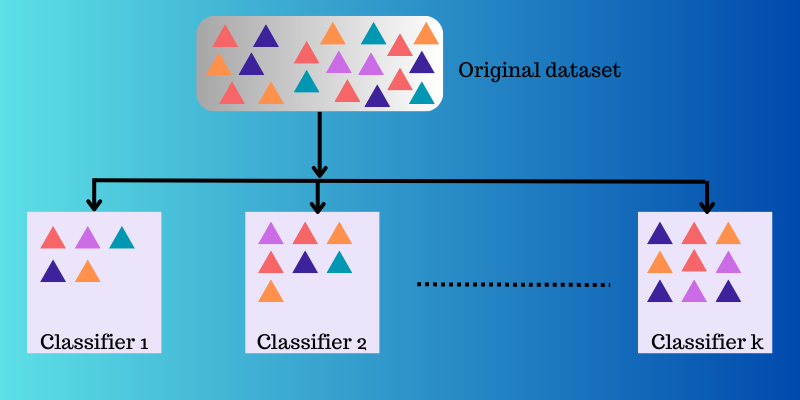
El aprendizaje ensemble toma múltiples funciones de mapeo que diferentes clasificadores han aprendido y luego las combina para crear una única función de mapeo.
He aquí un ejemplo de cómo funciona el aprendizaje por conjuntos.
Ejemplo: Está creando una aplicación basada en alimentos para los usuarios finales. Para ofrecer una experiencia de usuario de alta calidad, quiere recoger sus opiniones sobre los problemas a los que se enfrentan, las lagunas destacadas, los errores, los fallos, etc.
Para ello, puede pedir la opinión de su familia, amigos, compañeros de trabajo y otras personas con las que se comunique frecuentemente sobre sus elecciones alimentarias y su experiencia al pedir comida en línea. También puede lanzar su aplicación en versión beta para recabar opiniones en tiempo real sin sesgos ni ruido.
Por lo tanto, lo que en realidad está haciendo aquí es considerar múltiples ideas y opiniones de diferentes personas para ayudar a mejorar la experiencia del usuario.
El aprendizaje conjunto y sus modelos funcionan de forma similar. Utiliza un conjunto de modelos y los combina para producir un resultado final que mejore la precisión y el rendimiento de la predicción.
Técnicas básicas de aprendizaje ensemble
#1. Modo
Un «modo» es un valor que aparece en un conjunto de datos. En el aprendizaje por conjuntos, los profesionales del ML utilizan varios modelos para crear predicciones sobre cada punto de datos. Estas predicciones se consideran votos individuales y la predicción que han hecho la mayoría de los modelos se considera la predicción final. Se utiliza sobre todo en problemas de clasificación.
Ejemplo: Cuatro personas calificaron su aplicación con 4 mientras que una de ellas la calificó con 3, entonces el modo sería 4 ya que la mayoría votó 4.
#2. Promedio/Media
Mediante esta técnica, los profesionales tienen en cuenta todas las predicciones del modelo y calculan su media para llegar a la predicción final. Se utiliza sobre todo para hacer predicciones en problemas de regresión, calcular probabilidades en problemas de clasificación, etc.
Ejemplo: En el ejemplo anterior, en el que cuatro personas calificaron su aplicación con 4 mientras que una persona la calificó con 3, la media sería (4 4 4 4 3)/5=3,8
#3. Media ponderada
En este método de aprendizaje por conjuntos, los profesionales asignan diferentes pesos a los distintos modelos para realizar una predicción. Aquí, el peso asignado describe la relevancia de cada modelo.
Ejemplo: Supongamos que 5 personas proporcionan comentarios sobre su aplicación. De ellos, 3 son desarrolladores de aplicaciones, mientras que 2 no tienen ninguna experiencia en el desarrollo de aplicaciones. Por lo tanto, la opinión de esas 3 personas tendrá más peso que la de las 2 restantes.
Técnicas avanzadas de aprendizaje por conjuntos
#1. Bagging
Bagging (Bootstrap AGGregatING) es una técnica de aprendizaje de conjuntos muy intuitiva y sencilla, con un buen rendimiento. Como su nombre indica, se elabora combinando dos términos «Bootstrap» y «agregación».
El bootstrap es otro método de muestreo en el que tendrá que crear subconjuntos de varias observaciones tomadas de un conjunto de datos original con reemplazo. Aquí, el tamaño del subconjunto será el mismo que el del conjunto de datos original.
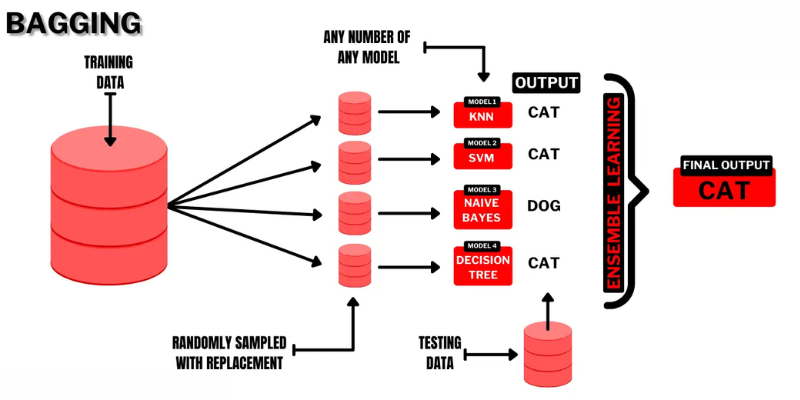
Así pues, en el bagging, se utilizan subconjuntos o bolsas para comprender la distribución del conjunto completo. Sin embargo, en el bagging los subconjuntos pueden ser más pequeños que el conjunto de datos original. Este método implica un único algoritmo ML. El objetivo de combinar los resultados de diferentes modelos es obtener un resultado generalizado.
Así funciona el bagging
- Se generan varios subconjuntos a partir del conjunto original y se seleccionan observaciones con reemplazos. Los subconjuntos se utilizan en el entrenamiento de modelos o árboles de decisión.
- Se crea un modelo débil o base para cada subconjunto. Los modelos serán independientes entre sí y se ejecutarán en paralelo.
- La predicción final se hará combinando cada predicción de cada modelo utilizando estadísticas como el promedio, la votación, etc.
Los algoritmos más utilizados en esta técnica de ensemble son:
- Bosque aleatorio
- Árboles de decisión en bolsa
La ventaja de este método es que ayuda a mantener al mínimo los errores de varianza en los árboles de decisión.
#2. Apilamiento
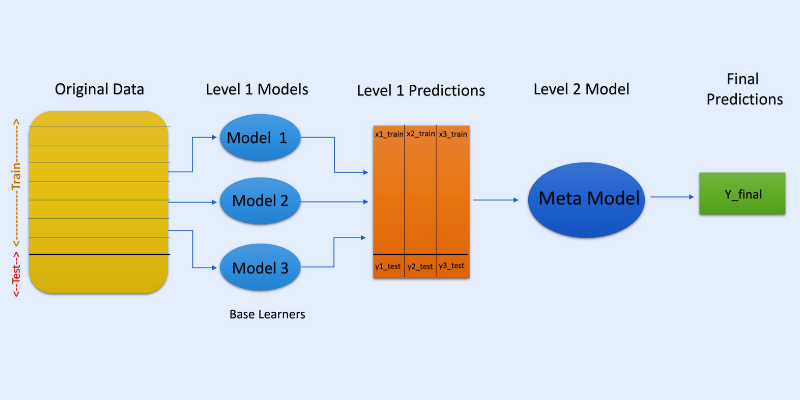
En el apilamiento o generalización apilada, las predicciones de diferentes modelos, como un árbol de decisión, se utilizan para crear un nuevo modelo que realice predicciones sobre este conjunto de prueba.
El apilamiento implica la creación de subconjuntos de datos bootstrapped para el entrenamiento de los modelos, de forma similar al bagging. Pero aquí, la salida de los modelos se toma como entrada para alimentar a otro clasificador, conocido como metaclasificador para la predicción final de las muestras.
La razón por la que se utilizan dos capas de clasificadores es determinar si los conjuntos de datos de entrenamiento se aprenden adecuadamente. Aunque el enfoque de dos capas es habitual, también se pueden utilizar más capas.
Por ejemplo, puede utilizar de 3 a 5 modelos en la primera capa o nivel 1 y un único modelo en la capa 2 o nivel 2. Este último combinará las predicciones obtenidas en el nivel 1 para realizar la predicción final.
Además, puede utilizar cualquier modelo de aprendizaje ML para agregar predicciones; un modelo lineal como la regresión lineal, la regresión logística, etc., es habitual.
Los algoritmos de ML más utilizados en el apilamiento son:
- Mezcla
- Superconjunto
- Modelos apilados
Nota: La mezcla utiliza un conjunto de validación o retención del conjunto de datos de entrenamiento para hacer predicciones. A diferencia del apilamiento, el blending implica que las predicciones se realicen sólo a partir del holdout.
#3. Refuerzo
El boosting es un método iterativo de aprendizaje por conjuntos que ajusta la ponderación de una observación específica en función de su última o anterior clasificación. Esto significa que cada modelo posterior tiene como objetivo corregir los errores encontrados en el modelo anterior.
Si la observación no se clasifica correctamente, entonces el boosting aumenta el peso de la observación.
En el boosting, los profesionales entrenan el primer algoritmo de boosting en un conjunto de datos completo. A continuación, construyen los algoritmos de ML posteriores utilizando los residuos extraídos del algoritmo de boosting anterior. Así, se da más peso a las observaciones incorrectas predichas por el modelo anterior.
Así es como funciona paso a paso:
- Se generará un subconjunto a partir del conjunto de datos original. Cada punto de datos tendrá inicialmente las mismas ponderaciones.
- La creación de un modelo base se realiza sobre el subconjunto.
- La predicción se realizará sobre el conjunto de datos completo.
- Utilizando los valores reales y los predichos, se calcularán los errores.
- Las observaciones predichas incorrectamente recibirán más ponderaciones
- Se creará un nuevo modelo y la predicción final se realizará sobre este conjunto de datos, mientras el modelo intenta corregir los errores cometidos anteriormente. Se crearán múltiples modelos de forma similar, cada uno corrigiendo los errores anteriores
- La predicción final se realizará a partir del modelo final, que es la media ponderada de todos los modelos.
Los algoritmos de boosting más populares son:
- CatBoost
- GBM ligero
- AdaBoost
La ventaja del boosting es que genera predicciones superiores y reduce los errores debidos al sesgo.
Otras técnicas de ensamblaje

Mezclade expertos: se utiliza para entrenar múltiples clasificadores, y sus salidas se ensamblan con una regla lineal general. Aquí, las ponderaciones dadas a las combinaciones se determinan mediante un modelo entrenable.
Votación por mayoría: consiste en elegir un clasificador impar, y las predicciones se calculan para cada muestra. La clase que reciba el máximo de un conjunto de clasificadores será la clase predicha del conjunto. Se utiliza para resolver problemas como la clasificación binaria.
Regla Max: utiliza las distribuciones de probabilidad de cada clasificador y emplea la confianza para hacer predicciones. Se utiliza para problemas de clasificación multiclase.
Casos de uso del aprendizaje por conjuntos
#1. Detección de rostros y emociones

El aprendizaje por conjuntos utiliza técnicas como el análisis de componentes independientes (ICA) para realizar la detección de rostros.
Además, el aprendizaje por conjuntos se utiliza en la detección de la emoción de una persona mediante la detección del habla. Además, sus capacidades ayudan a los usuarios a realizar la detección de emociones faciales.
#2. Seguridad
Detección de fraudes: El aprendizaje por conjuntos ayuda a mejorar la potencia del modelado del comportamiento normal. Por eso se considera eficaz para detectar actividades fraudulentas, por ejemplo, en sistemas bancarios y de tarjetas de crédito, fraudes en las telecomunicaciones, blanqueo de dinero, etc.

DDoS: La denegación de servicio distribuida (DDoS) es un ataque mortal contra un ISP. Los clasificadores conjuntos pueden reducir la detección de errores y también discriminar los ataques del tráfico auténtico.
Detección de intrusiones: El aprendizaje por conjuntos puede utilizarse en sistemas de supervisión como las herramientas de detección de intrusiones para detectar códigos de intrusos mediante la supervisión de redes o sistemas, la búsqueda de anomalías, etc.
Detección de malware: El aprendizaje conjunto es bastante eficaz para detectar y clasificar códigos de malware como virus y gusanos informáticos, ransomware, troyanos, spyware, etc. utilizando técnicas de aprendizaje automático.
#3. Aprendizaje incremental
En el aprendizaje incremental, un algoritmo de ML aprende de un nuevo conjunto de datos conservando los aprendizajes anteriores pero sin acceder a los datos previos que ha visto. Los sistemas ensemble se utilizan en el aprendizaje incremental haciendo que aprenda un clasificador añadido en cada conjunto de datos a medida que está disponible.
#4. Medicina
Los clasificadores ensemble son útiles en el campo del diagnóstico médico, como la detección de trastornos neurocognitivos (como el Alzheimer). Realiza la detección tomando como entrada conjuntos de datos de IRM y clasificando la citología cervical. Aparte de eso, se aplica en proteómica (estudio de las proteínas), neurociencia y otras áreas.
#5. Teledetección
Detección de cambios: Los clasificadores ensemble se utilizan para realizar la detección de cambios mediante métodos como la media bayesiana y la votación por mayoría.
Cartografía de la cubierta terrestre: Se utilizan métodos de aprendizaje conjunto como el boosting, los árboles de decisión, el análisis de componentes principales del núcleo (KPCA), etc. para detectar y cartografiar la cubierta terrestre de forma eficaz.
#6. Finanzas
La precisión es un aspecto crítico de las finanzas, ya se trate de cálculos o de predicciones. Influye enormemente en el resultado de las decisiones que se toman. También se pueden analizar los cambios en los datos bursátiles, detectar manipulaciones en los precios de las acciones, etc.
Recursos de aprendizaje adicionales
#1. Métodos de ensamblaje para el aprendizaje automático
Este libro le ayudará a aprender e implementar importantes métodos de aprendizaje por conjuntos desde cero.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Ensemble Methods for Machine Learning | Buy on Amazon |
#2. Métodos Ensemble: Fundamentos y algoritmos
Este libro presenta los fundamentos del aprendizaje por conjuntos y sus algoritmos. También esboza cómo se utiliza en el mundo real.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Ensemble Methods: Foundations and Algorithms (Chapman & Hall/CRC Machine Learning & Pattern… | Buy on Amazon |
#3. Aprendizaje por conjuntos
Ofrece una introducción al método ensemble unificado, retos, aplicaciones, etc.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Ensemble Learning: Pattern Classification Using Ensemble Methods (Second Edition) (Machine… | Buy on Amazon |
#4. Aprendizaje automático por conjuntos: Métodos y aplicaciones:
Proporciona una amplia cobertura de las técnicas avanzadas de aprendizaje por conjuntos.
| Vista previa | Producto | Valoración | |
|---|---|---|---|

|
Ensemble Machine Learning: Methods and Applications | Buy on Amazon |
Conclusión
Espero que ahora tenga alguna idea sobre el aprendizaje por conjuntos, sus métodos, casos de uso y por qué utilizarlo puede ser beneficioso para su caso de uso. Tiene potencial para resolver muchos retos de la vida real, desde el ámbito de la seguridad y el desarrollo de aplicaciones hasta las finanzas, la medicina y otros. Sus usos se están ampliando, por lo que es probable que se produzcan más mejoras en este concepto en un futuro próximo.
También puede explorar algunas herramientas de generación de datos sintéticos para entrenar modelos de aprendizaje automático