El aprendizaje automático (Machine Learning, ML) es una innovación tecnológica que sigue demostrando su valía en muchos sectores.
El aprendizaje automático está relacionado con la inteligencia artificial y el aprendizaje profundo. Dado que vivimos en una era tecnológica en constante progreso, ahora es posible predecir lo que vendrá y saber cómo cambiar nuestro enfoque utilizando el ML.
Por lo tanto, no está limitado a formas manuales; casi todas las tareas hoy en día están automatizadas. Existen diferentes algoritmos de aprendizaje automático diseñados para diferentes trabajos. Estos algoritmos pueden resolver problemas complejos y ahorrar horas de tiempo empresarial.
Algunos ejemplos podrían ser jugar al ajedrez, rellenar datos, realizar operaciones quirúrgicas, elegir la mejor opción de la lista de la compra y muchos más.
En este artículo le explicaré en detalle los algoritmos y modelos de aprendizaje automático.
Allá vamos
¿Qué es el aprendizaje automático?

El aprendizaje automático es una habilidad o tecnología en la que una máquina (como un ordenador) necesita desarrollar la capacidad de aprender y adaptarse utilizando modelos estadísticos y algoritmos sin estar muy programada.
Como resultado, las máquinas se comportan de forma similar a los humanos. Es un tipo de Inteligencia Artificial que permite a las aplicaciones informáticas ser más precisas en las predicciones y en la realización de diferentes tareas aprovechando los datos y mejorándose a sí mismas.
Dado que las tecnologías informáticas crecen rápidamente, el aprendizaje automático actual no es el mismo que el del pasado. El aprendizaje automático demuestra su existencia desde el reconocimiento de patrones hasta la teoría del aprendizaje para realizar determinadas tareas.
Con el aprendizaje automático, los ordenadores aprenden de cálculos anteriores para producir decisiones y resultados repetibles y fiables. En otras palabras, el aprendizaje automático es una ciencia que ha cobrado un nuevo impulso.
Aunque muchos algoritmos se utilizan desde hace mucho tiempo, la capacidad de aplicar cálculos complejos de forma automática a grandes datos, cada vez más rápido, una y otra vez, es un desarrollo reciente.
Algunos ejemplos publicitados son los siguientes:
- Descuentos y ofertas de recomendación en línea, como los de Netflix y Amazon
- Conducción autónoma y el tan publicitado coche de Google
- Detección de fraudes y sugerencia de algunas formas de saltarse esos problemas
Y muchos más.
¿Por qué necesita el aprendizaje automático?

El aprendizaje automático es un concepto importante que todo empresario implementa en sus aplicaciones de software para conocer el comportamiento de sus clientes, los patrones operativos del negocio y mucho más. Apoya el desarrollo de productos de última generación.
Muchas empresas líderes, como Google, Uber, Instagram, Amazon, etc., hacen del aprendizaje automático la parte central de sus operaciones. Sin embargo, las industrias que trabajan con una gran cantidad de datos conocen la importancia de los modelos de aprendizaje automático.
Las organizaciones son capaces de trabajar eficazmente con esta tecnología. Industrias como los servicios financieros, la administración pública, la sanidad, el comercio minorista, el transporte y el petróleo-gas utilizan modelos de aprendizaje automático para ofrecer resultados más valiosos a sus clientes.
¿Quién utiliza el aprendizaje automático?

El aprendizaje automático se utiliza hoy en día en numerosas aplicaciones. El ejemplo más conocido es el motor de recomendación de Instagram, Facebook, Twitter, etc.
Facebook está utilizando el aprendizaje automático para personalizar las experiencias de los usuarios en sus noticias. Si un usuario se detiene con frecuencia a consultar la misma categoría de publicaciones, el motor de recomendación empieza a mostrar más publicaciones de la misma categoría.
Detrás de la pantalla, el motor de recomendación intenta estudiar el comportamiento en línea de los miembros a través de sus patrones. El feed de noticias se ajusta automáticamente cuando el usuario cambia su acción.
En relación con los motores de recomendación, muchas empresas utilizan el mismo concepto para ejecutar sus procedimientos empresariales críticos. Éstos son:
- Software de gestión de las relaciones con los clientes (CRM): Utiliza modelos de aprendizaje automático para analizar los correos electrónicos de los visitantes e indicar al equipo de ventas que responda primero a los mensajes más importantes.
- Inteligencia empresarial (BI): Los proveedores de análisis y BI utilizan la tecnología para identificar puntos de datos esenciales, patrones y anomalías.
- Sistemas de información de recursos humanos (SIRH): Utiliza modelos de aprendizaje automático en su software para filtrar sus solicitudes y reconocer a los mejores candidatos para el puesto requerido.
- Coches autoconducidos: Los algoritmos de aprendizaje automático hacen posible que las empresas fabricantes de automóviles identifiquen el objeto o perciban el comportamiento del conductor para alertar inmediatamente y evitar accidentes.
- Asistentes virtuales: Los asistentes virtuales son asistentes inteligentes que combinan modelos supervisados y no supervisados para interpretar el habla y proporcionar contexto.
¿Qué son los modelos de aprendizaje automático?

Un modelo de aprendizaje automático es un programa informático o una aplicación entrenada para juzgar y reconocer algunos patrones. Puede entrenar el modelo con la ayuda de datos y suministrarle el algoritmo para que aprenda de esos datos.
Por ejemplo, quiere hacer una aplicación que reconozca las emociones basándose en las expresiones faciales del usuario. En este caso, necesita alimentar el modelo con diferentes imágenes de caras etiquetadas con diferentes emociones y entrenar bien su modelo. Ahora, puede utilizar el mismo modelo en su aplicación para determinar fácilmente el estado de ánimo del usuario.
En términos sencillos, un modelo de aprendizaje automático es una representación simplificada de procesos. Es la forma más sencilla de determinar algo o recomendar algo a un consumidor. Todo en el modelo funciona como una aproximación.
Por ejemplo, cuando dibujamos un globo terráqueo o lo fabricamos, le damos la forma de una esfera. Pero el globo terráqueo real no es esférico como sabemos. En este caso, asumimos la forma para construir algo. Los modelos ML funcionan de forma similar.
Sigamos adelante con los diferentes modelos y algoritmos de aprendizaje automático.
Tipos de modelos de aprendizaje automático

Todos los modelos de aprendizaje automático se clasifican en supervisados, no supervisados y de aprendizaje por refuerzo. El aprendizaje supervisado y el no supervisado se clasifican a su vez en diferentes términos. Analicemos cada uno de ellos en detalle.
Aprendizaje supervisado
El aprendizaje supervisado es un modelo de aprendizaje automático directo que implica el aprendizaje de una función básica. Esta función asigna una entrada a la salida. Por ejemplo, si tiene un conjunto de datos formado por dos variables, la edad como entrada y la altura como salida.
Con un modelo de aprendizaje supervisado, puede predecir fácilmente la altura de una persona basándose en la edad de esa persona. Para entender este modelo de aprendizaje, debe pasar por las subcategorías.
#1. Clasificación
La clasificación es una tarea de modelado predictivo muy utilizada en el campo del aprendizaje automático en la que se predice una etiqueta para unos datos de entrada dados. Requiere el conjunto de datos de entrenamiento con una amplia gama de instancias de entradas y salidas a partir de las cuales aprende el modelo.
El conjunto de datos de entrenamiento se utiliza para encontrar la forma mínima de asignar muestras de datos de entrada a las etiquetas de clase especificadas. Por último, el conjunto de datos de entrenamiento representa la cuestión que contiene un gran número de muestras de salida.

Se utiliza para el filtrado de spam, la búsqueda de documentos, el reconocimiento de caracteres manuscritos, la detección de fraudes, la identificación de idiomas y el análisis de sentimientos. En este caso, la salida es discreta.
#2. Regresión
En este modelo, la salida es siempre continua. El análisis de regresión es esencialmente un enfoque estadístico que modela una conexión entre una o más variables que son independientes y un objetivo o variable dependiente.
La regresión permite ver cómo cambia el número de la variable dependiente en relación con la variable independiente mientras las demás variables independientes son constantes. Se utiliza para predecir el salario, la edad, la temperatura, el precio y otros datos reales.
El análisis de regresión es un método de «mejor estimación» que genera una previsión a partir del conjunto de datos. En palabras sencillas, ajusta varios puntos de datos en un gráfico para obtener el valor más preciso.
Ejemplo: Predecir el precio de un billete de avión es un trabajo de regresión habitual.
Aprendizaje no supervisado
El aprendizaje no supervisado se utiliza esencialmente para hacer inferencias así como para encontrar patrones a partir de los datos de entrada sin ninguna referencia a los resultados etiquetados. Esta técnica se utiliza para descubrir agrupaciones y patrones de datos ocultos sin necesidad de intervención humana.
Puede descubrir diferencias y similitudes en la información, lo que hace que esta técnica sea ideal para la segmentación de clientes, el análisis exploratorio de datos, el reconocimiento de patrones e imágenes y las estrategias de venta cruzada.
El aprendizaje no supervisado también se utiliza para reducir el número finito de características de un modelo mediante el proceso de reducción de la dimensionalidad que incluye dos enfoques: la descomposición del valor singular y el análisis de componentes principales.
#1. Agrupación
La agrupación es un modelo de aprendizaje no supervisado que incluye la agrupación de los puntos de datos. Se utiliza con frecuencia para la detección de fraudes, la clasificación de documentos y la segmentación de clientes.

Los algoritmos de agrupación o clustering más comunes incluyen el clustering jerárquico, el clustering basado en la densidad, el clustering por desplazamiento de medias y el clustering k-means. Cada algoritmo se utiliza de forma diferente para encontrar agrupaciones, pero el objetivo es el mismo en todos los casos.
#2. Reducción de la dimensionalidad
Se trata de un método de reducción de diversas variables aleatorias consideradas para obtener un conjunto de variables principales. En otras palabras, el proceso de disminuir la dimensión del conjunto de características se denomina reducción de la dimensionalidad. El algoritmo popular de este modelo se denomina Análisis de Componentes Principales.
Su maldición se refiere al hecho de añadir más entradas a las actividades de modelado predictivo, lo que dificulta aún más el modelado. Generalmente se utiliza para la visualización de datos.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es un paradigma de aprendizaje en el que un agente aprende a interactuar con el entorno y, por el conjunto correcto de acciones, obtiene ocasionalmente una recompensa.
El modelo de aprendizaje por refuerzo aprende a medida que avanza con el método de ensayo y error. La secuencia de resultados satisfactorios obliga al modelo a desarrollar la mejor recomendación para un problema determinado. Esto se utiliza a menudo en juegos, navegación, robótica, etc.
Tipos de algoritmos de aprendizaje automático

#1. Regresión lineal
Aquí, la idea es encontrar una línea que se ajuste lo mejor posible a los datos que se necesitan. Existen extensiones en el modelo de regresión lineal que incluyen la regresión lineal múltiple y la regresión polinómica. Se trata de encontrar el mejor plano que se ajuste a los datos y la mejor curva que se ajuste a los datos, respectivamente.
#2. Regresión logística
La regresión logística es muy similar al algoritmo de regresión lineal pero se utiliza esencialmente para obtener un número finito de resultados, digamos dos. La regresión logística se utiliza sobre la regresión lineal al modelizar la probabilidad de los resultados.
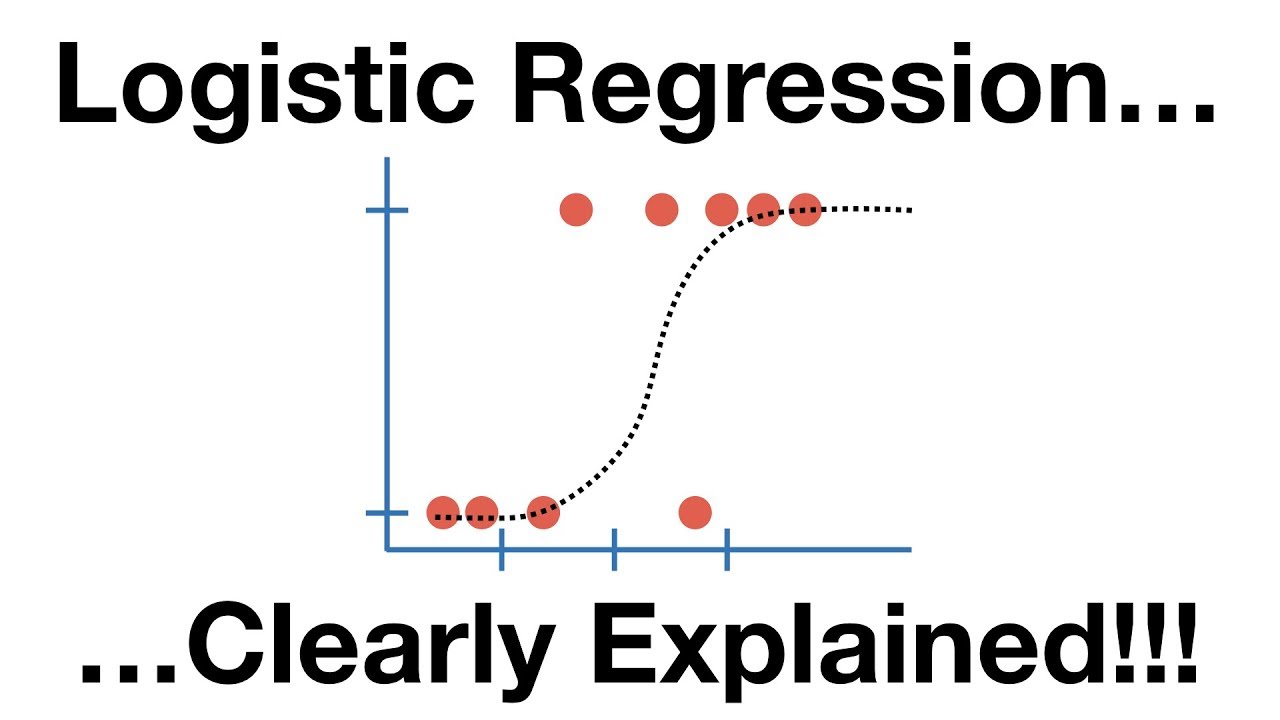
Aquí, una ecuación logística se construye de forma brillante para que la variable de salida esté entre 0 y 1.
#3. Árbol de decisión
El modelo de árbol de decisión se utiliza ampliamente en la planificación estratégica, el aprendizaje automático y la investigación de operaciones. Consta de nodos. Si tiene más nodos, obtendrá resultados más precisos. El último nodo del árbol de decisión consta de datos que ayudan a tomar decisiones más rápidamente.
Por ello, los últimos nodos también se denominan las hojas de los árboles. Los árboles de decisión son fáciles e intuitivos de construir, pero se quedan cortos en cuanto a precisión.
#4. Bosque aleatorio
Es una técnica de aprendizaje por conjuntos. En términos sencillos, se construye a partir de árboles de decisión. El modelo de bosques aleatorios implica múltiples árboles de decisión mediante el uso de conjuntos de datos bootstrapped de los datos verdaderos. Selecciona aleatoriamente el subconjunto de las variables en cada paso del árbol.
El modelo de bosque aleatorio selecciona el modo de predicción de cada árbol de decisión. Por lo tanto, confiar en el modelo «la mayoría gana» reduce el riesgo de error.
Por ejemplo, si crea un árbol de decisión individual y el modelo predice 0 al final, no tendrá nada. Pero si crea 4 árboles de decisión a la vez, podría obtener el valor 1. Este es el poder del modelo de aprendizaje de bosque aleatorio.
#5. Máquina de vectores de apoyo
Una máquina de vectores de apoyo (SVM) es un algoritmo de aprendizaje automático supervisado que es complicado pero intuitivo cuando hablamos del nivel más fundamental.
Por ejemplo, si hay dos tipos de datos o clases, el algoritmo SVM encontrará una frontera o un hiperplano entre esas clases de datos y maximizará el margen entre las dos. Hay muchos planos o límites que separan dos clases, pero un plano puede maximizar la distancia o el margen entre las clases.
#6. Análisis de componentes principales (ACP)
El análisis de componentes principales consiste en proyectar información de mayor dimensión, como 3 dimensiones, a un espacio más pequeño, como 2 dimensiones. El resultado es una dimensión mínima de los datos. De este modo, se pueden mantener los valores originales en el modelo sin obstaculizar la posición, pero reduciendo las dimensiones.
En palabras sencillas, se trata de un modelo de reducción de dimensiones que se utiliza especialmente para reducir al mínimo las múltiples variables presentes en el conjunto de datos. Se puede hacer juntando aquellas variables cuya escala de medida es la misma y tiene correlaciones más altas que otras.
El objetivo principal de este algoritmo es mostrarle los nuevos grupos de variables y darle acceso suficiente para realizar su trabajo.
Por ejemplo, el ACP ayuda a interpretar encuestas que incluyen muchas preguntas o variables, como las encuestas sobre bienestar, cultura de estudio o comportamiento. Puede ver variables mínimas de esto con el modelo PCA.
#7. Bayes ingenuo
El algoritmo Naive Bayes se utiliza en la ciencia de datos y es un modelo popular utilizado en muchas industrias. La idea está tomada del Teorema de Bayes que explica la ecuación de probabilidad como «cuál es la probabilidad de Q (variable de salida) dada P».
Se trata de una explicación matemática que se utiliza en la era tecnológica actual.
Aparte de éstos, algunos modelos mencionados en la parte de regresión, incluidos el árbol de decisión, la red neuronal y el bosque aleatorio, también entran dentro del modelo de clasificación. La única diferencia entre los términos es que la salida es discreta en lugar de continua.
#8. Red neuronal
Una red neuronal es de nuevo el modelo más utilizado en las industrias. Es esencialmente una red de varias ecuaciones matemáticas. Primero, toma una o más variables como entrada y recorre la red de ecuaciones. Al final, le da resultados en una o más variables de salida.

En otras palabras, una red neuronal toma un vector de entradas y devuelve el vector de salidas. Es similar a las matrices en matemáticas. Tiene capas ocultas en medio de las capas de entrada y salida que representan funciones lineales y de activación.
#9. Algoritmo K-Nearest Neighbours (KNN)
El algoritmo KNN se utiliza tanto para problemas de clasificación como de regresión. Se utiliza ampliamente en la industria de la ciencia de datos para resolver problemas de clasificación. Además, almacena todos los casos disponibles y clasifica los casos venideros tomando los votos de sus k vecinos.
La función de distancia realiza la medición. Por ejemplo, si desea datos sobre una persona, necesita hablar con las personas más cercanas a esa persona, como amigos, colegas, etc. De forma similar funciona el algoritmo KNN.
Debe tener en cuenta tres cosas antes de seleccionar el algoritmo KNN.
- Es necesario preprocesar los datos.
- Es necesario normalizar las variables, o las variables más altas pueden sesgar el modelo.
- El KNN es caro computacionalmente.
#10. Agrupación de K-Means
Se trata de un modelo de aprendizaje automático no supervisado que resuelve las tareas de agrupación. Aquí los conjuntos de datos se clasifican y categorizan en varios conglomerados (digamos K) de forma que todos los puntos dentro de un conglomerado sean heterogéneos y homogéneos respecto a los datos.
K-Means forma clústeres de este modo:
- El K-Means elige el número K de puntos de datos, llamados centroides, para cada conglomerado.
- Cada punto de datos forma un conglomerado con el conglomerado más cercano (centroides), es decir, K conglomerados.
- Esto crea nuevos centroides.
- A continuación, se determina la distancia más cercana para cada punto. Este proceso se repite hasta que los centroides no cambian.
Conclusión
Los modelos y algoritmos deaprendizaje automático son muy decisivos para los procesos críticos. Estos algoritmos facilitan y simplifican nuestro día a día. De este modo, resulta más fácil llevar a cabo los procesos más gigantescos en cuestión de segundos.
Así pues, el ML es una poderosa herramienta que muchas industrias utilizan hoy en día, y su demanda crece continuamente. Y no está lejos el día en que podamos obtener respuestas aún más precisas a nuestros complejos problemas.