
La creación de un sistema de software automatizado supuso la instalación de varios servidores con una configuración dedicada de CPU, memoria, almacenamiento y otros recursos durante muchos años. A continuación, se formó un equipo de administradores para gestionar estos sistemas. A continuación, el equipo de desarrollo se hizo cargo de la infraestructura y comenzó a crear procesos que conectaran los servidores.
Este proceso puede ser complicado porque implica a muchos grupos diferentes que trabajan juntos por un objetivo común. Estos conflictos de intereses pueden ser entonces un problema.
También puede resultar bastante costoso. Requiere tener administradores en nómina. Los servidores, que funcionan continuamente, consumen recursos aunque no se utilicen.
Para mantener el mejor rendimiento a lo largo del tiempo, necesita una solución de autoescalado que escale automáticamente los recursos del servidor.

La plataforma en nube tiene una ventaja: le permite crear una arquitectura integral sin necesidad de configurar clústeres de servidores. Desde el punto de vista de la administración, no hay nada que mantener.
Se trata de una opción rentable para las startups y las fases de producto mínimo viable (MVP) de los proyectos. Es un buen punto de partida si resulta difícil predecir las futuras cargas de producción y la actividad de los usuarios. Aquí es donde puede resultar complicado determinar la configuración de los servidores en clúster.
La automatización de procesos a través de servicios en la nube sin servidor es lo que hace destacar a la arquitectura sin servidor. Conecta servicios y produce resultados similares a los de los servidores de clúster tradicionales.
Este es un ejemplo de construcción de una arquitectura de este tipo utilizando únicamente servicios nativos de AWS.
Recogiendo el flujo de servicios sin servidor
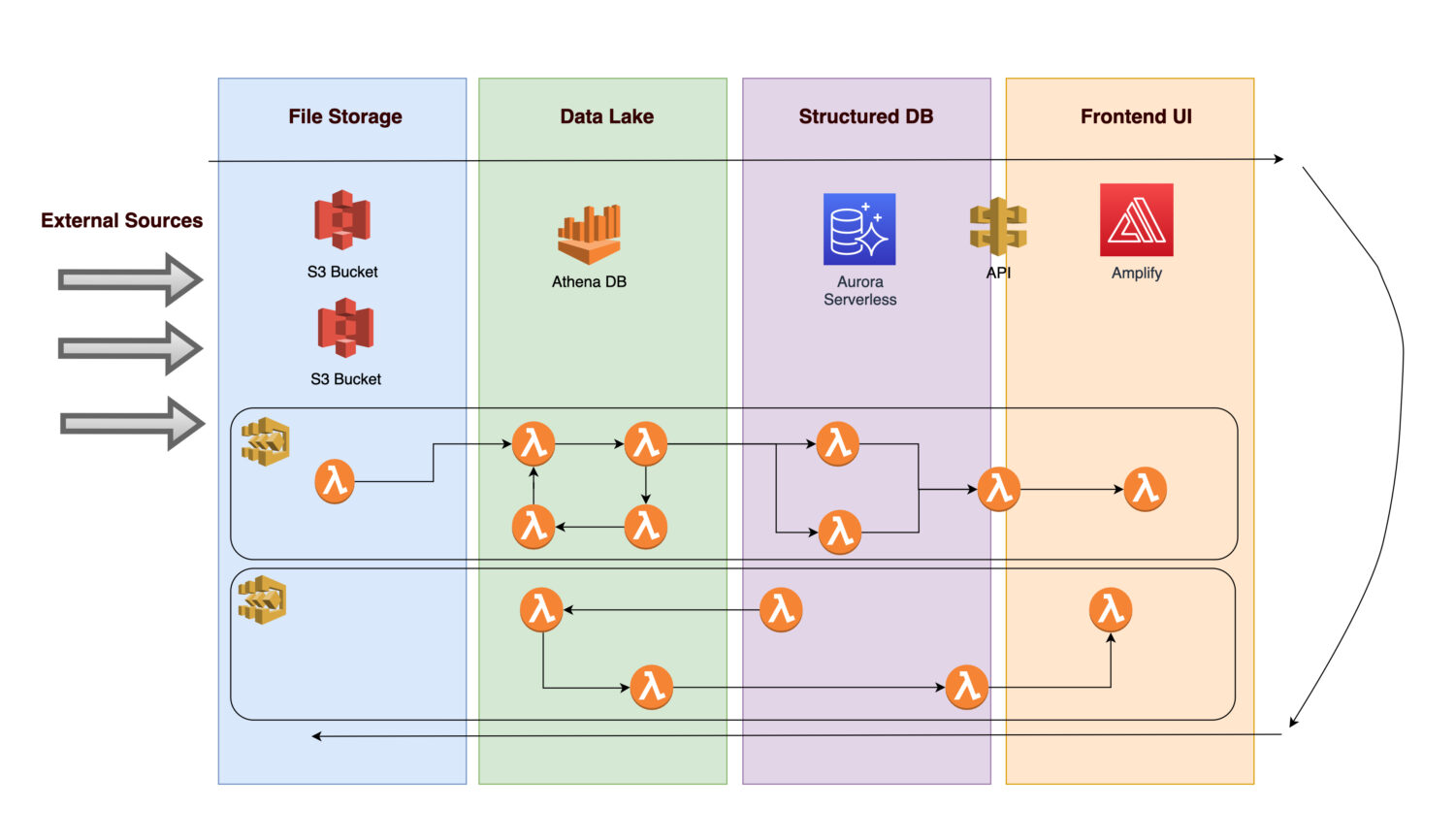
Imagine que desea crear una plataforma para recopilar diversos datos e imágenes (o fotos) de la infraestructura de algunos activos concretos (puede tratarse de cualquier activo de fabricación o de servicios públicos).
- Para posibilitar futuros análisis, es necesario que primero se ingieran los datos entrantes.
- Tras aplicar las reglas de negocio, un procedimiento back-end guarda los resultados calculados como información normalizada en una base de datos relacional.
- Un front-end de la aplicación que muestre los datos limpios normalizados permite a los usuarios ver los resultados.
Examinemos qué componentes podría incluir la arquitectura.
Cubos AWS S3
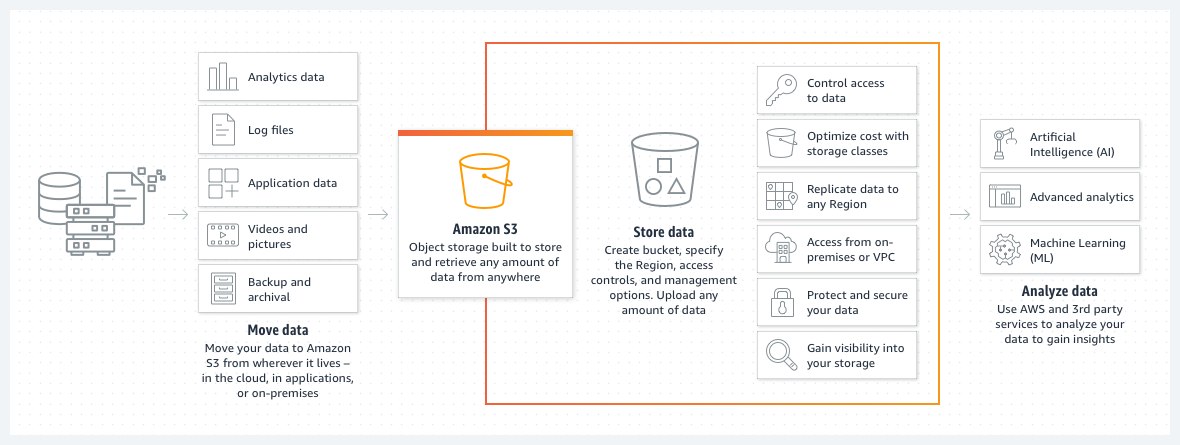
Los buckets de Amazon S3 son una excelente forma de almacenar archivos o imágenes en la nube de AWS. El precio del almacenamiento en el cubo S3 es notablemente bajo. Es más, la introducción de una política de ciclo de vida del cubo S3 reduce aún más este precio.
Una política de este tipo moverá automáticamente los archivos más antiguos a diferentes clases de cubos S3, como un archivo o un acceso profundo al archivo. Las clases se diferencian entonces también por la velocidad del tiempo de acceso, pero para los datos antiguos, esto será un problema menor. Sirve principalmente para acceder a los datos archivados en caso de urgencia más que para las necesidades de las operaciones estándar.
- Puede organizar sus datos en subcarpetas.
- Deberá establecer las restricciones de permisos adecuadas.
- Añada etiquetas a los buckets para facilitar su identificación y para su posible uso dentro de las políticas dinámicas de los buckets de S3.
- El cubo no tiene servidor por diseño. Es simplemente un espacio de almacenamiento para sus datos.
Un cubo S3 es serverless por diseño. Es simplemente un espacio de almacenamiento para sus datos.
Base de datos AWS Athena
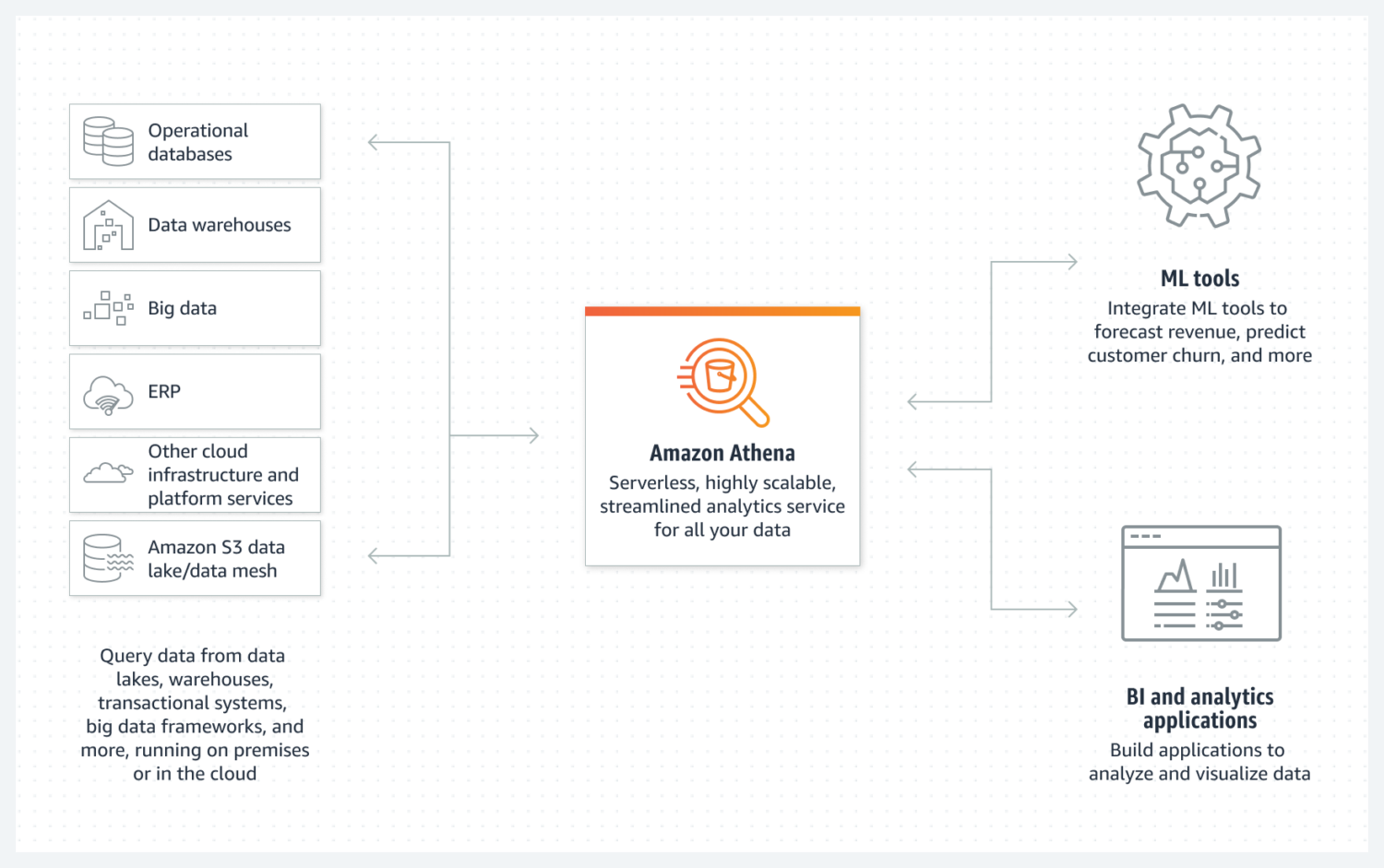
Athena facilita la creación de un lago de datos básico de AWS. Se trata de una base de datos sin servidores que utiliza un bucket de S3 para almacenar sus datos. La organización de los datos se mantiene mediante formatos de archivo estructurados como parquet o archivos de valores separados por comas(CSV). El bucket de S3 guarda los archivos, y Athena hace referencia a ellos cada vez que los procesos seleccionan los datos de la base de datos.
Sólo tenga en cuenta que Athena no admite varias funcionalidades consideradas estándar, por ejemplo, las sentencias de actualización. Por ello, debe considerar Athena como una opción muy sencilla.
Sin embargo, soporta la indexación y la partición. También puede escalarse horizontalmente con mucha facilidad, ya que esto es tan complejo como añadir nuevos buckets a la infraestructura. Para la creación de un lago de datos sencillo pero funcional, esto puede ser suficiente en la mayoría de los casos.
Para obtener un buen rendimiento, es esencial seleccionar el mejor diseño de datos centrándose en su uso futuro. Es esencial tener muy clara la forma en que desea seleccionar los datos. Volver a crear tablas más tarde, cuando ya existen y están llenas de muchos datos, es difícil.
Athena DB es una gran elección y una buena opción para su objetivo si busca crear un conjunto de datos sencillo e inmutable que sea fácil de escalar horizontalmente con el tiempo.
Base de datos Aurora de AWS
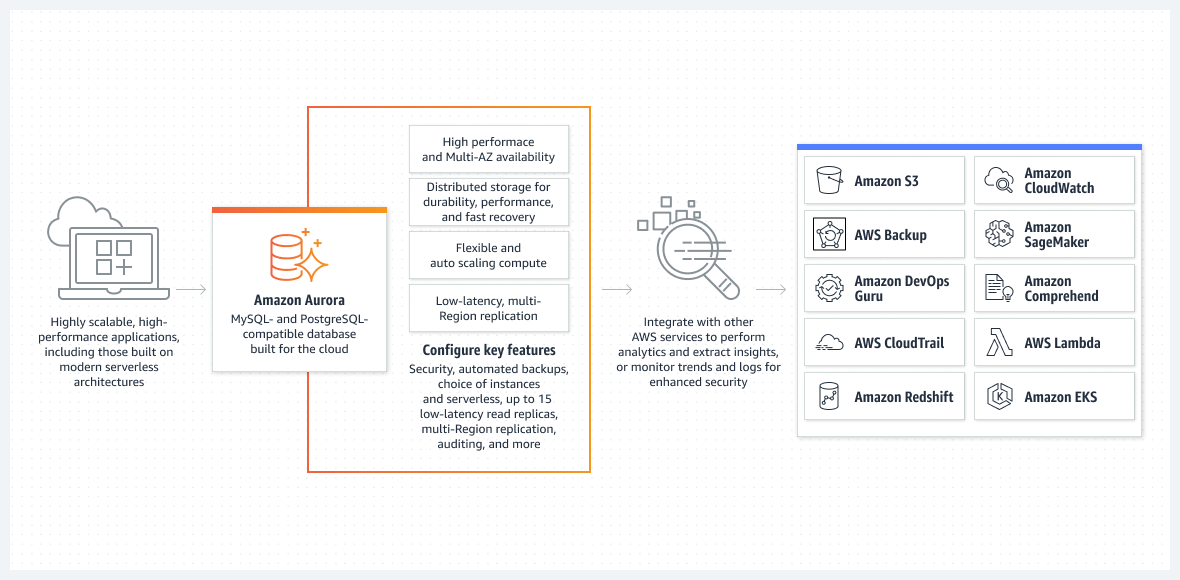
Athena DB destaca en el almacenamiento de datos sin curar. Al fin y al cabo, así es como quiere almacenar su contenido original para maximizar su reutilización futura. Sin embargo, es lenta a la hora de proporcionar resultados selectos a una aplicación front-end.
Una de las mejores opciones, principalmente desde la perspectiva de una configuración fácil de ejecutar, es la base de datos Aurora que funciona en modo sin servidor.
Aurora está lejos de ser una base de datos básica. Es una de las soluciones de bases de datos relacionales nativas más avanzadas de AWS. También es una solución de base de datos relacional nativa muy compleja que mejora con cada versión.
Aurora es única porque puede ejecutarse en modo sin servidor, lo que la diferencia de otros servicios relacionales. Así es como funciona el modo
- Para configurar el clúster de Aurora, utilice la consola de AWS. Deberá especificar los niveles estándar de CPU y RAM, así como el intervalo máximo de la funcionalidad de autoescala. Esto afectará al rendimiento que el clúster de Aurora puede añadir o eliminar dinámicamente. En función de la utilización actual de la base de datos, AWS decide aumentar o reducir la escala.
- El clúster de Aurora no se pondrá en marcha a menos que el usuario o el proceso inicie una solicitud real. Por ejemplo, cuando se inicia el procesamiento por lotes programado. O si la aplicación realiza una llamada a la API back-end para recuperar datos de una base de datos. La base de datos se abrirá automáticamente y permanecerá activa durante un tiempo predeterminado una vez finalizados los procesos de solicitud.
- El cluster Aurora se apagará automáticamente si no hay más trabajo en la base de datos.
Para enfatizarlo una vez más, Aurora DB sin servidor sólo se ejecuta cuando tiene que realizar trabajo real. El clúster puesto en marcha automáticamente volverá a apagarse si no está procesando ningún trabajo. El trabajo real es lo que usted paga y no su tiempo de inactividad.
Aurora sin servidor está totalmente gestionada por AWS y no requiere un administrador.
AWS Amplify
Amplify ofrece una plataforma sin servidor para el despliegue rápido de aplicaciones front-end realizadas con bibliotecas JavaScript y React. No es necesario configurar servidores en clúster. Utilice la consola de AWS para desplegar el código directamente o utilice una canalización de DevOps automatizada.
Puede llamar a API de back-end para acceder a datos almacenados en bases de datos. Estas llamadas le permiten acceder a los datos reales en la aplicación front-end. La optimización principal del rendimiento en el back-end debe realizarla el equipo. Puede reducir aún más la posibilidad de una respuesta lenta en la interfaz de usuario si diseña declaraciones select eficaces dentro de las llamadas a la API directamente.
Funciones escalonadas de AWS
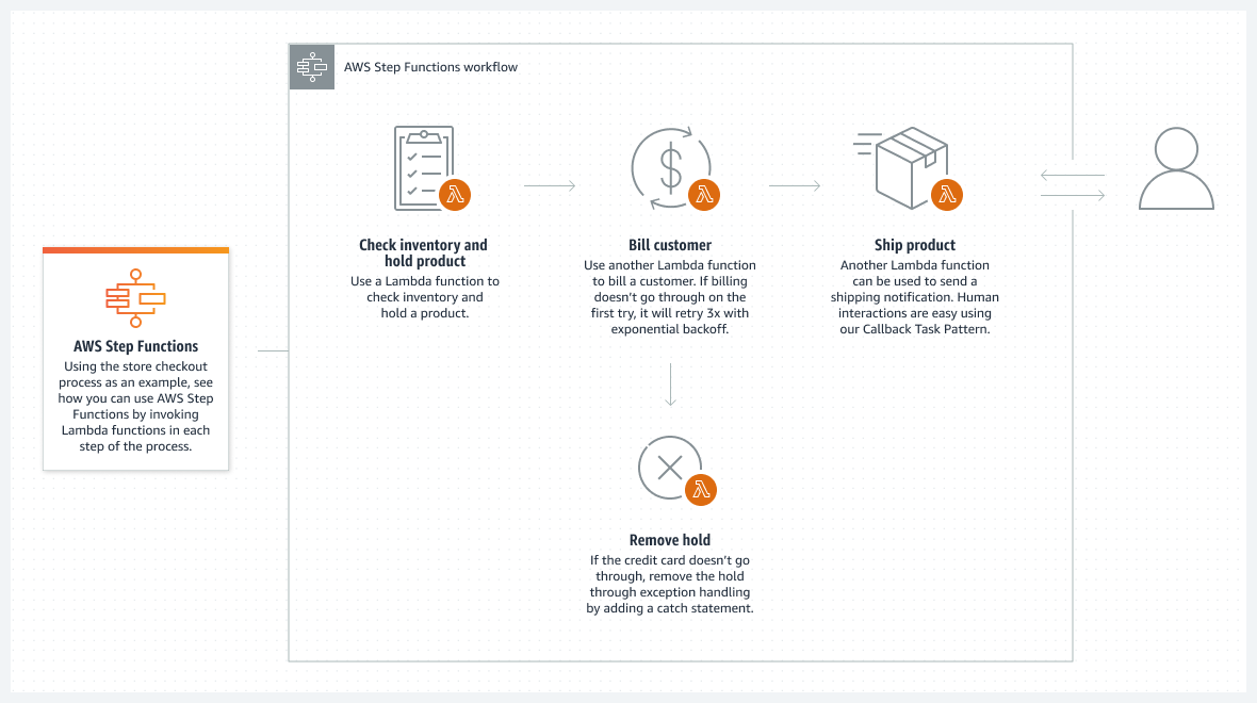
Aunque todos los componentes principales de un sistema sean sin servidor, esto no garantiza una arquitectura completamente sin servidor. Esto sólo es posible si todos los procesos por lotes entre los componentes son sin servidor.
Las funciones escalonadas de AWS proporcionan la mejor solución en la nube de AWS. Una lista conectada de funciones de AWS Lambda conforma la función escalonada. Estas funciones crean un diagrama de flujo que tiene estados iniciales y finales claros. Una función lambda, normalmente escrita en lenguajes Python o Node JS, es un trozo de código ejecutable que procesa lo que sea necesario.
A continuación se muestra un ejemplo de cómo podría ejecutar una función lambda:
- AWS activa una función lambda automática cada vez que un nuevo archivo entra en la carpeta S3. Tras analizar el archivo, la lambda lo carga en Athena. La lambda almacena sus resultados en formato CSV en un bucket de S3 (o en una tabla de seguimiento de una base de datos) antes de cerrarse.
- Este resultado es entonces utilizado por la siguiente lambda para realizar los siguientes pasos. Esto podría incluir llamar a un modelo de aprendizaje automático y transformar un subconjunto de los nuevos datos en tablas normalizadas. El último paso puede ser cargar los datos en la base de datos Aurora.
- Una función paso enlaza estas lambdas para formar un flujo por lotes. Incluso es posible hacer que otra función de paso se ejecute en lugar de un paso de otra función de paso raíz. De esta forma, es posible cubrir muchos escenarios.
Este flujo sin servidor tiene un gran inconveniente: cada función lambda sólo puede ejecutarse durante 15 minutos como máximo. Por lo tanto, dividir el flujo en funciones lambda más pequeñas puede hacer que esto sea menos problemático.
Es posible llamar a varias funciones lambda simultáneamente en un paso, lo que básicamente significa paralelizar un paso con varias lambdas ejecutadas simultáneamente. Simplemente espere a que termine todo el procesamiento paralelo de lambdas antes de continuar. A continuación, continúe con el siguiente procesamiento lambda.
Palabras finales
La arquitectura sin servidor ofrece una oportunidad única para crear una plataforma en la nube que cubra todo el panorama del sistema. Esta plataforma es escalable horizontalmente y tiene bajos costes operativos mientras lo hace.
Es la solución perfecta para proyectos de presupuesto limitado. Es una excelente opción de exploración, normalmente cuando nadie conoce la realidad de la carga de producción. Esto es especialmente importante después de haber incorporado con éxito a todos los usuarios. Es posible que los equipos de proyecto sigan teniendo una visión general del funcionamiento del sistema. Puede tener todas estas ventajas y seguir sin tener que aceptar compromisos.
Esta cobertura no será adecuada para todos los casos, en particular para aquellos que impliquen un uso elevado de la CPU. Sin embargo, la nube de AWS evoluciona constantemente en lo que respecta a los casos de uso sin servidor. Suele ser una buena idea realizar una investigación exhaustiva antes de decidirse por la opción sin servidor para su próximo proyecto en la nube de AWS.
A continuación, consulte las mejores bases de datos sin servidor para aplicaciones modernas.