Pour qu’une application soit performante, vous avez besoin d’un serveur d’application puissant, d’une bande passante garantie et suffisante, et d’un travail de programmation bien fait. Mais il y a un aspect qui n’est pas toujours pris en compte et qui a généralement un impact important sur les performances d’une application : la conception de la base de données.
Nous allons maintenant examiner les meilleures pratiques en matière de conception de base de données afin de nous assurer que l’accès aux données n’est pas un goulot d’étranglement qui affecte négativement les performances de l’application.
Quel est l’objectif d’une bonne conception de base de données ?
Outre l’amélioration des performances d’accès aux données, une bonne conception présente d’autres avantages, tels que le maintien de la cohérence, de la précision et de la fiabilité des données et la réduction de l’espace de stockage grâce à l’élimination des redondances. Un autre avantage d’une bonne conception est que la base de données est plus facile à utiliser et à maintenir. Toute personne chargée de la gérer n’aura qu’à regarder le diagramme entité-relation (ERD) pour comprendre sa structure.
Les ERD sont l’outil fondamental de la conception d’une base de données. Ils peuvent être créés et visualisés à trois niveaux de conception : conceptuel, logique et physique.
Le schéma conceptuel est un diagramme très résumé, qui ne contient que les éléments nécessaires pour convenir des critères avec les parties prenantes du projet, qui n’ont pas besoin de comprendre les détails techniques de la base de données. La conception logique montre les entités et leurs relations en détail, mais d’une manière indépendante de la base de données.
Il existe de nombreux outils qui facilitent la conception de bases de données à partir des ERD. Parmi les meilleurs, citons DbSchema, SqlDBM et Vertabelo.
DbSchema
DbSchema vous permet de concevoir et de gérer visuellement des bases de données SQL, NoSQL ou Cloud. L’outil vous permet de concevoir le schéma sur un ordinateur et de le déployer sur plusieurs bases de données et de générer de la documentation sous forme de diagrammes HTML5, d’écrire des requêtes et d’explorer visuellement les données, entre autres. Il offre également la synchronisation des schémas, la génération de données aléatoires et l’édition de code SQL avec auto-complétion.

SqlDBM
SqlDBM est l’un des meilleurs outils de conception de diagrammes de base de données, car il permet de concevoir facilement votre base de données dans n’importe quel navigateur. Aucun autre moteur de base de données ou outil de modélisation n’est nécessaire pour l’utiliser, bien que SqlDBM vous permette d’importer un schéma à partir d’une base de données existante. Il est idéal pour le travail en équipe, car il vous permet de partager des projets de conception avec des collègues.
Vertabelo
Vertabelo est un outil de conception visuelle de base de données en ligne qui vous permet de concevoir une base de données de manière logique et d’en déduire automatiquement le schéma physique. Il peut faire de l’ingénierie inverse, générer des diagrammes à partir de bases de données existantes et contrôler l’accès aux diagrammes en différenciant les privilèges d’accès pour les propriétaires, les éditeurs et les spectateurs.

Enfin, la conception physique est celle qui ajoute à l’ERD tous les détails nécessaires pour en faire une base de données utilisable dans un SGBD particulier, tel que MySQL, MariaDB, MS SQL Server ou tout autre. Examinons les meilleures pratiques à garder à l’esprit lors de la conception d’un ERD afin que la base de données résultante fonctionne au mieux.
Définissez le type de base de données à concevoir
On distingue généralement deux types fondamentaux de bases de données : les bases de données relationnelles et les bases de données dimensionnelles.
Les bases de données relationnelles sont utilisées pour les applications traditionnelles qui exécutent des transactions sur les données, c’est-à-dire qu’elles obtiennent des informations de la base de données, les traitent et stockent les résultats.
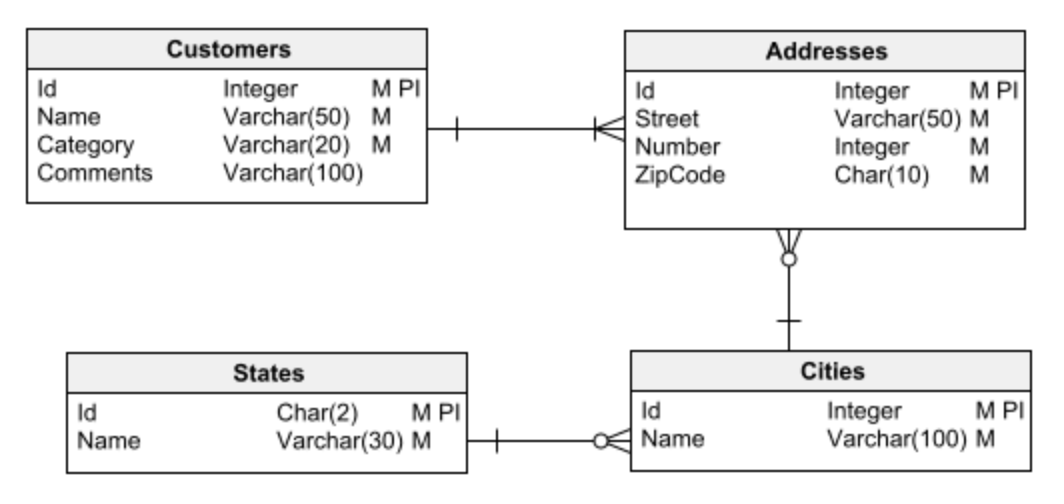
D’autre part, les bases de données dimensionnelles sont utilisées pour la création d’entrepôts de données : de grands dépôts d’informations pour l’analyse des données et l’exploration des données afin d’obtenir des informations.
La première étape de la conception d’une base de données consiste à choisir l’un des deux principaux types de base de données : relationnelle ou dimensionnelle. Il est essentiel que ce choix soit clair avant de commencer la conception. Dans le cas contraire, vous risquez de commettre des erreurs de conception qui entraîneront de nombreux problèmes et seront difficiles (voire impossibles) à corriger.
Adopter une convention d’appellation
Les noms utilisés dans la conception de la base de données sont essentiels car, une fois qu’un objet est créé dans une base de données, changer son nom peut être fatal. Le changement d’une seule lettre du nom peut briser des dépendances, des relations, voire des systèmes entiers.
C’est pourquoi il est essentiel de travailler avec une convention de dénomination saine : un ensemble de règles qui vous évite d’essayer 50 possibilités différentes pour trouver le nom d’un objet dont vous ne vous souvenez plus.
Il n’existe pas de guide universel sur ce que doit être une convention de nommage pour remplir sa mission. Mais l’important est d’établir une convention de dénomination avant de nommer les objets d’une base de données et de maintenir cette convention pour toujours. Une convention de nommage établit des lignes directrices telles que l’utilisation d’un trait de soulignement pour séparer les mots ou pour les joindre directement, l’utilisation de lettres majuscules ou de mots en majuscules (style Camel Case), l’utilisation de mots au pluriel ou au singulier pour nommer les objets, etc.
Commencez par la conception, puis la conception logique et enfin la conception physique.
C’est l’ordre naturel des choses. En tant que concepteur, vous pouvez être tenté de commencer par créer des objets directement dans le SGBD pour sauter des étapes. Mais cela vous empêchera de disposer d’un outil pour discuter avec les parties prenantes afin de vous assurer que la conception répond aux exigences de l’entreprise.
Après la conception, vous devez passer à la conception logique afin de disposer d’une documentation adéquate pour aider les programmeurs à comprendre la structure de la base de données. Il est essentiel de maintenir la conception logique à jour pour qu’elle soit indépendante du moteur de base de données utilisé. Ainsi, si vous migrez la base de données vers un autre moteur, la conception logique sera toujours utile.
Enfin, la conception physique peut être créée par les programmeurs eux-mêmes ou par un administrateur de bases de données, en reprenant la conception logique et en y ajoutant tous les détails d’implémentation nécessaires pour la mettre en œuvre sur un SGBD particulier.
Créez et maintenez un dictionnaire de données
Même si un ERD est clair et descriptif, vous devez ajouter un dictionnaire de données pour le rendre encore plus clair. Le dictionnaire de données maintient la cohérence et l’homogénéité de la conception de la base de données, en particulier lorsque le nombre d’objets qu’elle contient augmente de manière significative.
L’objectif principal du dictionnaire de données est de maintenir un référentiel unique d’informations de référence sur les entités d’un modèle de données et ses attributs. Le dictionnaire de données doit contenir les noms de toutes les entités, les noms de tous les attributs, leurs formats et types de données, ainsi qu’une brève description de chacun d’entre eux.
Le dictionnaire de données fournit un guide clair et concis de tous les éléments qui composent la base de données. Il permet d’éviter la création de plusieurs objets représentant la même chose, ce qui rend difficile de savoir à quel objet recourir lorsque vous avez besoin d’interroger ou de mettre à jour des informations.
Maintenir des critères cohérents pour les clés primaires
La décision d’utiliser des clés naturelles ou des clés de substitution doit être cohérente au sein d’un modèle de données. Si les entités d’un modèle de données ont des identifiants uniques qui peuvent être gérés efficacement en tant que clés primaires de leurs tables respectives, il n’est pas nécessaire de créer des clés de substitution.
Cependant, il est fréquent que les entités soient identifiées par plusieurs attributs de types différents – dates, nombres et/ou longues chaînes de caractères – qui peuvent s’avérer inefficaces pour former des clés primaires. Dans ce cas, il est préférable de créer des clés de substitution de type numérique entier, qui offrent une efficacité maximale dans la gestion de l’index. La clé de substitution est la seule option possible si une entité n’a pas d’attributs permettant de l’identifier de manière unique.
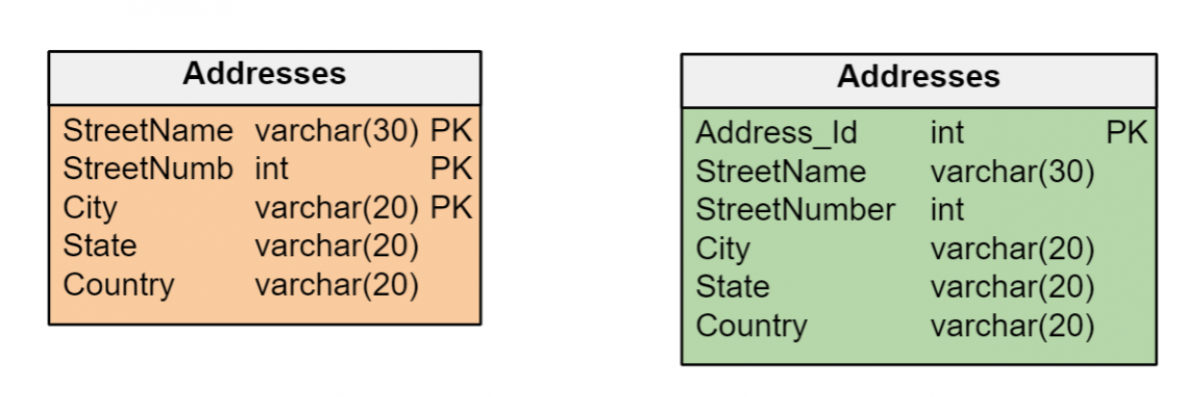
Utilisez les bons types de données pour chaque attribut.
Certaines données nous permettent de choisir le type de données à utiliser pour les représenter. Les dates, par exemple. Nous pouvons choisir de les stocker dans des champs de type date, de type date/heure, de type varchar ou même de type numérique. Un autre cas est celui des données numériques qui ne sont pas utilisées pour des opérations mathématiques mais pour identifier une entité, comme un numéro de permis de conduire ou un code postal.
Dans le cas des dates, il est pratique d’utiliser le type de données du moteur, ce qui facilite la manipulation des données. Si vous devez stocker uniquement la date d’un événement sans préciser l’heure, le type de données à choisir sera simplement Date ; si vous devez stocker la date et l’heure auxquelles un certain événement s’est produit, le type de données sera DateTime.
L’utilisation d’autres types, tels que varchar ou numeric, pour stocker des dates peut être pratique, mais uniquement dans des cas très particuliers. Par exemple, si l’on ne sait pas à l’avance dans quel format une date sera exprimée, il est pratique de la stocker en tant que varchar. Si les performances de recherche, de tri ou d’indexation sont critiques dans le traitement des champs de type date, une conversion préalable en float peut faire la différence.
Les données numériques qui ne sont pas impliquées dans des opérations mathématiques doivent être représentées sous forme de varchar, en appliquant des validations de format dans l’enregistrement afin d’éviter les incohérences ou les répétitions. Sinon, vous vous exposez au risque que certaines données dépassent les limites des champs numériques et vous obligent à remanier une conception alors qu’elle est déjà en production.
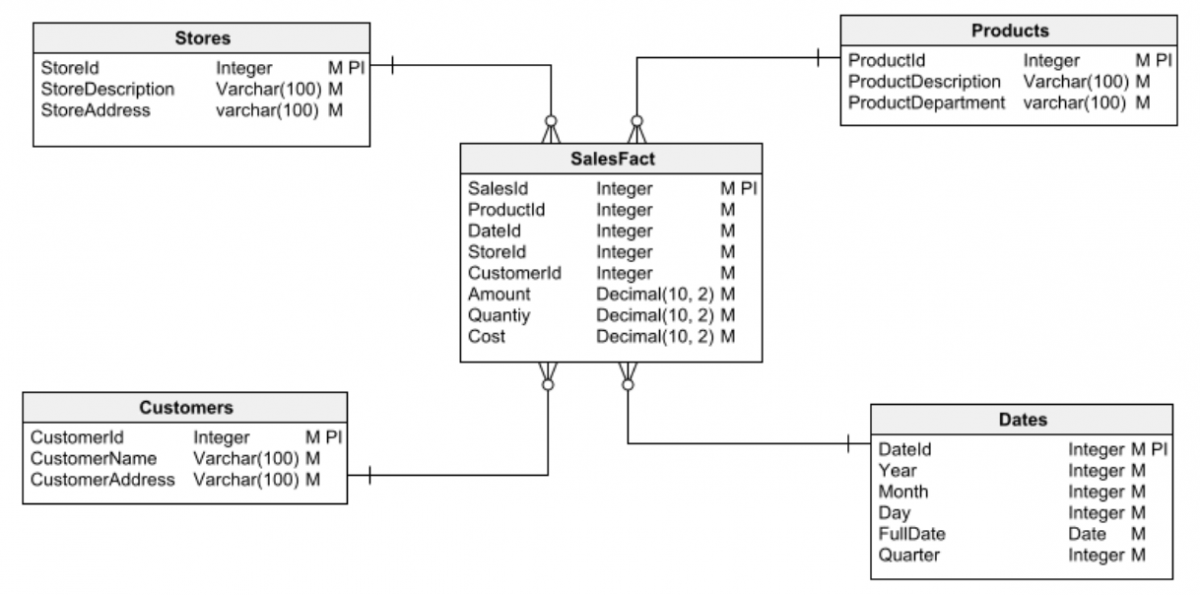
Utilisation de tables de consultation
Certains concepteurs inexpérimentés peuvent penser que l’utilisation excessive de tables de consultation pour normaliser une conception peut compliquer inutilement l’ERD d’une base de données parce qu’elle ajoute un grand nombre de tables “satellites” qui, parfois, n’ont pas plus d’une poignée d’éléments. Ceux qui pensent cela devraient comprendre que l’utilisation de tables de recherche présente beaucoup plus d’avantages que d’inconvénients. Si la complexité ou la taille d’un ERD pose problème, il existe des outils de conception d’ERD qui vous permettent de visualiser les diagrammes de différentes manières afin qu’ils soient compris malgré leur complexité.
Cet exemple de requête illustre l’utilisation correcte des tables de consultation dans une base de données bien conçue :
SELECT
Nom de la rue,
Numéro de rue,
Ville.Nom AS Ville,
States.Name AS State
FROM
Adresses
INNER JOIN Cities ON
Cities.CityId = Addresses.CityId
INNER JOIN States ON
States.StateId = Addresses.StateIdDans ce cas, nous utilisons des tables de consultation pour les villes et les États.
Les tables de recherche permettent notamment de réduire la taille de la base de données, d’améliorer les performances de recherche et d’imposer des restrictions sur l’ensemble des données valides qu’un champ peut contenir. Une bonne pratique consiste également à inclure dans toutes les tables de recherche un champ Bit ou un champ booléen qui indique si un enregistrement de la table est en cours d’utilisation ou obsolète. Ce champ peut être utilisé comme filtre pour éviter les éléments obsolètes en tant qu’options dans l’interface utilisateur de l’application.
Normaliser ou dénormaliser en fonction du type de base de données
Dans les bases de données relationnelles utilisées pour des applications traditionnelles, la normalisation est indispensable. Il est bien connu que la normalisation réduit l’espace de stockage nécessaire en évitant les redondances. Elle améliore la qualité de l’information et fournit de nombreux outils pour optimiser les performances des requêtes complexes.
Cependant, dans d’autres types de bases de données, une technique connue sous le nom de dénormalisation est appliquée. Dans les bases de données dimensionnelles, utilisées comme entrepôts de données, la dénormalisation ajoute certaines informations redondantes utiles dans les tables de schéma.
Bien qu’il s’agisse de concepts apparemment opposés, la dénormalisation ne consiste pas à annuler la normalisation. Il s’agit en fait d’une technique d’optimisation appliquée à un modèle de données après l’avoir normalisé afin de simplifier l’écriture des requêtes et l’établissement des rapports.
Conception de modèles physiques en plusieurs parties
Dans un projet de développement de logiciel, le concepteur de la base de données présente aux parties prenantes un modèle conceptuel à grande échelle, dans lequel aucun détail de mise en œuvre n’est indiqué. De son côté, pour travailler avec les développeurs, le concepteur doit fournir un modèle physique avec tous les détails de chaque entité et attribut. Toutefois, il n’est pas nécessaire que les deux modèles soient entièrement créés au début du projet.
Dans le cadre de l’application des méthodologies agiles, chaque développeur, au début de chaque cycle de développement, prend une ou plusieurs histoires d’utilisateur avec lesquelles il travaillera pendant ce cycle. Le travail du concepteur de la base de données consiste à fournir à chaque développeur un sous-modèle physique qui comprend uniquement les objets dont il a besoin pour une unité de travail.
À la fin de chaque cycle de développement, les sous-modèles créés au cours de ce cycle sont fusionnés afin que le modèle physique complet prenne forme parallèlement au développement de l’application.
Bien utiliser les vues et les index
Les vues et les index sont deux outils fondamentaux dans la conception des bases de données pour améliorer les performances des applications. L’utilisation de vues permet de manipuler des abstractions qui simplifient les requêtes, en masquant les détails inutiles des tables. À leur tour, les vues facilitent les tâches d’optimisation des requêtes pour les moteurs de base de données, car elles leur permettent d’anticiper la manière dont les données seront obtenues et de choisir les meilleures stratégies pour fournir les résultats des requêtes plus rapidement.
Les index peuvent améliorer les performances d’une requête lente en fonction de l’expérience de l’utilisateur une fois que la base de données est en production. Toutefois, la création d’index peut être effectuée dans le cadre des tâches de conception de la base de données, en anticipant les besoins de l’application.
Pour créer des index, vous devez avoir une idée approximative de l’ampleur de chaque table – en termes de nombre d’enregistrements – et créer ensuite des index pour les tables les plus importantes. Pour choisir les champs à inclure dans un index, vous devez considérer principalement ceux qui représentent des clés étrangères et ceux qui seront utilisés comme filtres dans les recherches.
Lorsque vous pensez que le travail est terminé, il est temps de procéder à un remaniement.
La conception d’une base de données peut toujours être améliorée. Lorsqu’aucune modification n’est apportée à la base de données en raison de nouvelles exigences ou de nouveaux besoins commerciaux, il s’agit d’une bonne occasion d’exécuter des procédures de remaniement qui améliorent la conception. Le remaniement consiste simplement à introduire des modifications qui améliorent la conception sans affecter la sémantique de la base de données.
Il existe de nombreuses techniques de remaniement permettant d’améliorer la conception d’une base de données qui sortent du cadre de cet article, mais il est bon d’en connaître l’existence pour les utiliser en cas de besoin.
Le fait de disposer de cette liste de bonnes pratiques chaque fois que vous devez concevoir une base de données vous permettra d’obtenir les meilleurs résultats, de sorte que les applications conservent toujours des performances optimales en matière d’accès aux données.