
L’apprentissage d’ensemble peut vous aider à prendre de meilleures décisions et à résoudre de nombreux problèmes concrets en combinant les décisions de plusieurs modèles.
L’apprentissage machine (ML) continue d’étendre ses ailes dans de nombreux secteurs et industries, qu’il s’agisse de la finance, de la médecine, du développement d’applications ou de la sécurité.
Entraîner correctement les modèles d’apprentissage automatique vous aidera à mieux réussir dans votre entreprise ou votre travail, et il existe plusieurs méthodes pour y parvenir.
Dans cet article, je parlerai de l’apprentissage global, de son importance, de ses cas d’utilisation et de ses techniques.
Restez à l’écoute !
Qu’est-ce que l’apprentissage d’ensemble ?
Dans le domaine de l’apprentissage automatique et des statistiques, le terme “ensemble” fait référence à des méthodes générant diverses hypothèses tout en utilisant un apprenant de base commun.

L’apprentissage d’ensemble est une approche de l’apprentissage automatique dans laquelle plusieurs modèles (comme des experts ou des classificateurs) sont stratégiquement créés et combinés dans le but de résoudre un problème informatique ou de faire de meilleures prédictions.
Cette approche vise à améliorer les performances d’un modèle donné en matière de prédiction, d’approximation de fonction, de classification, etc. Elle est également utilisée pour éliminer la possibilité que vous choisissiez un modèle médiocre ou de moindre valeur parmi de nombreux autres. Pour améliorer les performances prédictives, plusieurs algorithmes d’apprentissage sont utilisés.
Apprentissage d’ensemble en ML
Dans les modèles d’apprentissage automatique, certaines sources telles que le biais, la variance et le bruit peuvent entraîner des erreurs. L’apprentissage d’ensemble peut contribuer à réduire ces sources d’erreur et à garantir la stabilité et la précision de vos algorithmes d’apprentissage automatique.
Voici pourquoi l’apprentissage d’ensemble est utilisé dans différents scénarios :
Choix du bon classificateur
L’apprentissage d’ensemble vous aide à choisir un meilleur modèle ou classificateur tout en réduisant le risque qui peut résulter d’une mauvaise sélection de modèle.

Il existe différents types de classificateurs utilisés pour différents problèmes, tels que les machines à vecteurs de support (SVM), les perceptrons multicouches (MLP), les classificateurs de Bayes naïfs, les arbres de décision, etc. En outre, il existe différentes réalisations d’algorithmes de classification que vous devez choisir. Les performances des différentes données d’apprentissage peuvent également être différentes.
Mais au lieu de sélectionner un seul modèle, si vous utilisez un ensemble de tous ces modèles et que vous combinez leurs résultats individuels, vous pouvez éviter de sélectionner des modèles moins performants.
Volume de données
De nombreux modèles et méthodes de ML ne sont pas très efficaces si vous leur fournissez des données inadéquates ou un grand volume de données.
En revanche, l’apprentissage d’ensemble peut fonctionner dans les deux cas, même si le volume de données est trop faible ou trop important.
- Si les données sont inadéquates, vous pouvez utiliser le bootstrap pour former divers classificateurs à l’aide de différents échantillons de données bootstrap.
- Si le volume de données est important et que la formation d’un seul classificateur peut s’avérer difficile, vous pouvez alors partitionner stratégiquement les données en sous-ensembles plus petits.
Complexité

Un classificateur unique peut ne pas être en mesure de résoudre certains problèmes très complexes. Les limites décisionnelles séparant les données de différentes classes peuvent être très complexes. Ainsi, si vous appliquez un classificateur linéaire à une frontière complexe non linéaire, il ne sera pas en mesure de l’apprendre.
Toutefois, en combinant correctement un ensemble de classificateurs linéaires appropriés, vous pouvez faire en sorte qu’il apprenne une frontière non linéaire donnée. Le classificateur divisera les données en plusieurs partitions plus petites et plus faciles à apprendre, et chaque classificateur n’apprendra qu’une seule partition plus simple. Ensuite, les différents classificateurs seront combinés pour produire une limite de décision approximative.
Estimation de la confiance
Dans l’apprentissage d’ensemble, un vote de confiance est attribué à une décision prise par un système. Supposons que vous disposiez d’un ensemble de divers classificateurs formés à un problème donné. Si la majorité des classificateurs sont d’accord avec la décision prise, le résultat peut être considéré comme un ensemble avec une décision à haut niveau de confiance.
En revanche, si la moitié des classificateurs ne sont pas d’accord avec la décision prise, on dit qu’il s’agit d’un ensemble avec une décision à faible confiance.
Cependant, un niveau de confiance faible ou élevé n’est pas toujours la bonne décision. Mais il y a de fortes chances qu’une décision avec un niveau de confiance élevé soit correcte si l’ensemble est correctement entraîné.
Précision grâce à la fusion de données
Les données collectées à partir de sources multiples, lorsqu’elles sont combinées de manière stratégique, peuvent améliorer la précision des décisions de classification. Cette précision est supérieure à celle obtenue avec l’aide d’une seule source de données.
Comment fonctionne l’apprentissage d’ensemble ?
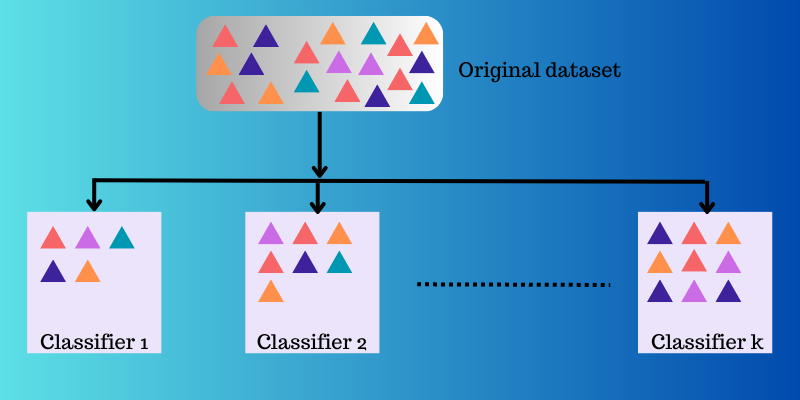
L’apprentissage d’ensemble utilise plusieurs fonctions de mise en correspondance que différents classificateurs ont apprises, puis les combine pour créer une fonction de mise en correspondance unique.
Voici un exemple du fonctionnement de l’apprentissage d’ensemble.
Exemple : Vous créez une application basée sur l’alimentation pour les utilisateurs finaux. Afin d’offrir une expérience utilisateur de haute qualité, vous souhaitez recueillir leurs commentaires sur les problèmes qu’ils rencontrent, les lacunes importantes, les erreurs, les bogues, etc.
Pour ce faire, vous pouvez demander l’avis de votre famille, de vos amis, de vos collègues et d’autres personnes avec lesquelles vous communiquez fréquemment sur leurs choix alimentaires et leur expérience de la commande de nourriture en ligne. Vous pouvez également lancer votre application en version bêta afin de recueillir un retour d’information en temps réel, sans parti pris ni bruit.
Ce que vous faites ici, c’est prendre en compte plusieurs idées et opinions de différentes personnes pour améliorer l’expérience de l’utilisateur.
L’apprentissage d’ensemble et ses modèles fonctionnent de la même manière. Il utilise un ensemble de modèles et les combine pour produire un résultat final afin d’améliorer la précision et la performance des prédictions.
Techniques de base de l’apprentissage d’ensemble
#1. Mode
Un “mode” est une valeur apparaissant dans un ensemble de données. Dans l’apprentissage d’ensemble, les professionnels de la ML utilisent plusieurs modèles pour créer des prédictions sur chaque point de données. Ces prédictions sont considérées comme des votes individuels et la prédiction faite par la plupart des modèles est considérée comme la prédiction finale. Ce type d’apprentissage est principalement utilisé dans les problèmes de classification.
Exemple : Quatre personnes ont attribué une note de 4 à votre application, tandis que l’une d’entre elles lui a attribué une note de 3. Le mode serait donc 4 puisque la majorité a voté 4.
#2. Moyenne
Avec cette technique, les professionnels prennent en compte toutes les prédictions du modèle et calculent leur moyenne pour obtenir la prédiction finale. Cette technique est principalement utilisée pour faire des prédictions dans les problèmes de régression, pour calculer les probabilités dans les problèmes de classification, etc.
Exemple : Dans l’exemple ci-dessus, où quatre personnes ont attribué une note de 4 à votre application et une personne une note de 3, la moyenne serait de (4 4 4 4 3)/5=3,8
#3. Moyenne pondérée
Dans cette méthode d’apprentissage d’ensemble, les professionnels attribuent des poids différents aux différents modèles pour faire une prédiction. Ici, le poids attribué décrit la pertinence de chaque modèle.
Exemple : Supposons que 5 personnes aient donné leur avis sur votre application. Trois d’entre elles sont des développeurs d’applications, tandis que deux n’ont aucune expérience dans ce domaine. Les commentaires de ces 3 personnes auront donc plus de poids que ceux des 2 autres.
Techniques avancées d’apprentissage d’ensemble
#1. L’ensachage
Bagging (Bootstrap AGGregatING) est une technique d’apprentissage d’ensemble simple et très intuitive qui offre de bonnes performances. Comme son nom l’indique, elle résulte de la combinaison de deux termes : “Bootstrap” et “agrégation”.
Le bootstrap est une autre méthode d’échantillonnage dans laquelle vous devez créer des sous-ensembles de plusieurs observations tirées d’un ensemble de données original avec remplacement. Ici, la taille du sous-ensemble sera la même que celle de l’ensemble de données original.
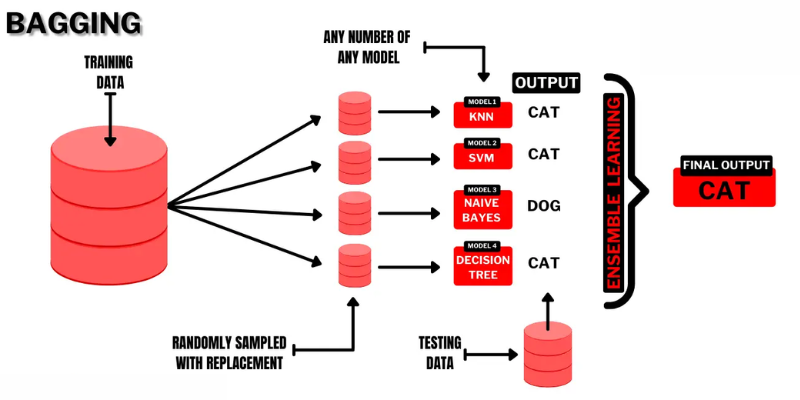
Ainsi, dans le bagging, les sous-ensembles ou les sacs sont utilisés pour comprendre la distribution de l’ensemble complet. Toutefois, les sous-ensembles peuvent être plus petits que l’ensemble de données original. Cette méthode fait appel à un seul algorithme ML. L’objectif de la combinaison des résultats de différents modèles est d’obtenir un résultat généralisé.
Voici comment fonctionne le bagging :
- Plusieurs sous-ensembles sont générés à partir de l’ensemble original et les observations sont sélectionnées avec des remplacements. Les sous-ensembles sont utilisés pour la formation de modèles ou d’arbres de décision.
- Un modèle faible ou de base est créé pour chaque sous-ensemble. Les modèles sont indépendants les uns des autres et fonctionnent en parallèle.
- La prédiction finale est réalisée en combinant chaque prédiction de chaque modèle à l’aide de statistiques telles que la moyenne, le vote, etc.
Les algorithmes populaires utilisés dans cette technique d’ensemble sont les suivants :
- Forêt aléatoire
- Arbres de décision en sac
L’avantage de cette méthode est qu’elle permet de réduire au minimum les erreurs de variance dans les arbres de décision.
#2. Empilement
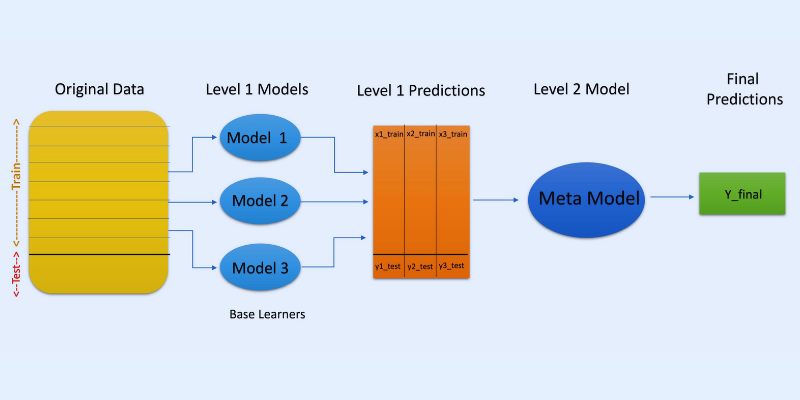
Dans l’empilage ou la généralisation par empilage, les prédictions de différents modèles, comme un arbre de décision, sont utilisées pour créer un nouveau modèle qui fera des prédictions sur cet ensemble de test.
L’empilage implique la création de sous-ensembles de données bootstrapés pour la formation des modèles, comme pour le bagging. Mais ici, la sortie des modèles est utilisée comme entrée pour alimenter un autre classificateur, connu sous le nom de méta-classificateur, pour la prédiction finale des échantillons.
La raison pour laquelle deux couches de classification sont utilisées est de déterminer si les ensembles de données d’apprentissage sont appris de manière appropriée. Bien que l’approche à deux couches soit courante, il est également possible d’utiliser davantage de couches.
Par exemple, vous pouvez utiliser 3 à 5 modèles dans la première couche ou niveau 1 et un seul modèle dans la couche 2 ou niveau 2. Ce dernier combinera les prédictions obtenues au niveau 1 pour établir la prédiction finale.
En outre, vous pouvez utiliser n’importe quel modèle d’apprentissage ML pour agréger les prédictions ; un modèle linéaire comme la régression linéaire, la régression logistique, etc. est courant.
Les algorithmes de ML les plus couramment utilisés dans l’empilage sont les suivants :
- Mélange
- Super ensemble
- Modèles empilés
Remarque : le mélange utilise un ensemble de validation ou d’attente de l’ensemble de données d’apprentissage pour faire des prédictions. Contrairement à l’empilage, le mélange implique que les prédictions ne soient faites qu’à partir de l’ensemble d’attente.
#3. Boosting
Le boosting est une méthode itérative d’apprentissage d’ensemble qui ajuste le poids d’une observation spécifique en fonction de sa dernière ou précédente classification. Cela signifie que chaque modèle ultérieur vise à corriger les erreurs trouvées dans le modèle précédent.
Si l’observation n’est pas classée correctement, le boosting augmente le poids de l’observation.
Dans le cadre du boosting, les professionnels forment le premier algorithme de boosting sur un ensemble de données complet. Ensuite, ils construisent les algorithmes ML suivants en utilisant les résidus extraits de l’algorithme de boosting précédent. Ainsi, un poids plus important est accordé aux observations incorrectes prédites par le modèle précédent.
Voici comment cela fonctionne, étape par étape :
- Un sous-ensemble est généré à partir de l’ensemble de données original. Chaque point de données aura initialement les mêmes poids.
- La création d’un modèle de base s’effectue sur le sous-ensemble.
- La prédiction sera effectuée sur l’ensemble des données.
- Les erreurs sont calculées à partir des valeurs réelles et prédites.
- Les observations prédites de manière incorrecte se verront attribuer plus de poids
- Un nouveau modèle sera créé et la prédiction finale sera effectuée sur cet ensemble de données, tandis que le modèle tentera de corriger les erreurs commises précédemment. Plusieurs modèles seront créés de la même manière, chacun corrigeant les erreurs précédentes
- La prédiction finale sera faite à partir du modèle final, qui est la moyenne pondérée de tous les modèles.
Les algorithmes de boosting les plus répandus sont les suivants
- CatBoost
- GBM léger
- AdaBoost
L’avantage du boosting est qu’il génère des prédictions supérieures et réduit les erreurs dues aux biais.
Autres techniques d’ensemble

Un mélange d’experts : il est utilisé pour entraîner plusieurs classificateurs, et leurs résultats sont regroupés à l’aide d’une règle linéaire générale. Ici, les poids attribués aux combinaisons sont déterminés par un modèle entraînable.
Vote majoritaire : il s’agit de choisir un classificateur impair, et les prédictions sont calculées pour chaque échantillon. La classe qui reçoit le maximum de classe d’un ensemble de classificateurs sera la classe prédite de l’ensemble. Cette méthode est utilisée pour résoudre des problèmes tels que la classification binaire.
Règle du maximum : elle utilise les distributions de probabilité de chaque classificateur et utilise la confiance pour faire des prédictions. Elle est utilisée pour les problèmes de classification multi-classes.
Cas d’utilisation de l’apprentissage d’ensemble
#1. Détection des visages et des émotions

L’apprentissage d’ensemble utilise des techniques telles que l’analyse en composantes indépendantes (ICA) pour effectuer la détection des visages.
En outre, l’apprentissage d’ensemble est utilisé pour détecter l’émotion d’une personne par le biais de la détection de la parole. En outre, ses capacités aident les utilisateurs à effectuer la détection des émotions faciales.
#2. Sécurité
Détection des fraudes : L’apprentissage ensembliste permet d’améliorer la puissance de la modélisation du comportement normal. C’est pourquoi il est jugé efficace pour détecter les activités frauduleuses, par exemple dans les systèmes de cartes de crédit et les systèmes bancaires, les fraudes en matière de télécommunications, le blanchiment d’argent, etc.

DDoS : Le déni de service distribué (DDoS) est une attaque mortelle contre un fournisseur d’accès à Internet. Les classificateurs d’ensemble peuvent réduire le nombre d’erreurs de détection et distinguer les attaques du trafic authentique.
Détection d’intrusion : L’apprentissage ensembliste peut être utilisé dans les systèmes de surveillance tels que les outils de détection d’intrusion pour détecter les codes d’intrusion en surveillant les réseaux ou les systèmes, en trouvant des anomalies, etc.
Détection des logiciels malveillants : L’apprentissage d’ensemble est très efficace pour détecter et classer les codes de logiciels malveillants tels que les virus et les vers informatiques, les ransomwares, les chevaux de Troie, les logiciels espions, etc. à l’aide de techniques d’apprentissage automatique.
#3. Apprentissage incrémental
Dans l’apprentissage incrémental, un algorithme de ML apprend à partir d’un nouvel ensemble de données tout en conservant les apprentissages précédents, mais sans accéder aux données antérieures qu’il a vues. Les systèmes d’ensemble sont utilisés dans l’apprentissage incrémental en lui faisant apprendre un classificateur supplémentaire sur chaque ensemble de données au fur et à mesure qu’il devient disponible.
#4. Médecine
Les classificateurs d’ensemble sont utiles dans le domaine du diagnostic médical, notamment pour la détection des troubles neurocognitifs (comme la maladie d’Alzheimer). Il effectue la détection en prenant des ensembles de données d’IRM comme entrées et en classifiant la cytologie cervicale. En outre, il est appliqué à la protéomique (étude des protéines), aux neurosciences et à d’autres domaines.
#5. Télédétection
Détection des changements : Les classificateurs d’ensemble sont utilisés pour détecter les changements par des méthodes telles que la moyenne bayésienne et le vote majoritaire.
Cartographie de l’occupation du sol : Des méthodes d’apprentissage d’ensemble telles que le boosting, les arbres de décision, l’analyse en composantes principales du noyau (KPCA), etc. sont utilisées pour détecter et cartographier efficacement l’occupation du sol.
#6. La finance
La précision est un aspect essentiel de la finance, qu’il s’agisse de calcul ou de prédiction. Elle influence fortement le résultat des décisions que vous prenez. Ces outils peuvent également analyser les changements dans les données du marché boursier, détecter les manipulations des prix des actions, et plus encore.
Ressources pédagogiques supplémentaires
#1. Ensemble Methods for Machine Learning (Méthodes d’ensemble pour l’apprentissage automatique)
Ce livre vous aidera à apprendre et à mettre en œuvre d’importantes méthodes d’apprentissage ensembliste à partir de zéro.
| Preview | Product | Rating | |
|---|---|---|---|

|
Ensemble Methods for Machine Learning | Buy on Amazon |
#2. Ensemble Methods : Fondations et algorithmes
Ce livre présente les bases de l’apprentissage par ensembles et ses algorithmes. Il explique également comment il est utilisé dans le monde réel.
| Preview | Product | Rating | |
|---|---|---|---|

|
Ensemble Methods: Foundations and Algorithms (Chapman & Hall/CRC Machine Learning & Pattern… | Buy on Amazon |
#3. Apprentissage d’ensemble
Ce site propose une introduction à une méthode d’ensemble unifiée, aux défis, aux applications, etc.
| Preview | Product | Rating | |
|---|---|---|---|

|
Ensemble Learning: Pattern Classification Using Ensemble Methods (Second Edition) (Machine… | Buy on Amazon |
#4. Ensemble Machine Learning : Methods and Applications :
Il couvre largement les techniques avancées d’apprentissage ensembliste.
| Preview | Product | Rating | |
|---|---|---|---|

|
Ensemble Machine Learning: Methods and Applications | Buy on Amazon |
Conclusion
J’espère que vous avez maintenant une idée de l’apprentissage d’ensemble, de ses méthodes, de ses cas d’utilisation et des raisons pour lesquelles son utilisation peut être bénéfique pour votre cas d’utilisation. Il a le potentiel de résoudre de nombreux défis de la vie réelle, depuis le domaine de la sécurité et du développement d’applications jusqu’à la finance, la médecine, et plus encore. Ses utilisations se multiplient, et il est donc probable que ce concept connaisse de nouvelles améliorations dans un avenir proche.
Vous pouvez également explorer certains outils de génération de données synthétiques pour former des modèles d’apprentissage automatique