Les données sont devenues de plus en plus importantes pour construire des modèles d’apprentissage automatique, tester des applications et obtenir des informations commerciales.
Cependant, pour se conformer aux nombreuses réglementations en matière de données, elles sont souvent placées dans des coffres-forts et strictement protégées. L’accès à ces données peut prendre des mois pour obtenir les autorisations nécessaires. Les entreprises peuvent également utiliser des données synthétiques.
Qu’est-ce qu’une donnée synthétique ?
Les données synthétiques sont des données générées artificiellement qui ressemblent statistiquement à l’ancien ensemble de données. Elles peuvent être utilisées avec des données réelles pour soutenir et améliorer les modèles d’IA ou peuvent être utilisées comme substitut.
Comme elles n’appartiennent à aucune personne concernée et ne contiennent pas d’informations d’identification personnelle ou de données sensibles telles que les numéros de sécurité sociale, elles peuvent être utilisées comme alternative aux données de production réelles pour protéger la vie privée.
Différences entre les données réelles et synthétiques
- La différence la plus importante réside dans la manière dont les deux types de données sont générés. Les données réelles proviennent de sujets réels dont les données ont été collectées lors d’enquêtes ou de l’utilisation de votre application. En revanche, les données synthétiques sont générées artificiellement mais ressemblent toujours à l’ensemble de données d’origine.
- La deuxième différence concerne les règles de protection des données qui s’appliquent aux données réelles et synthétiques. Dans le cas des données réelles, les personnes concernées doivent être en mesure de savoir quelles données les concernant sont collectées et pourquoi elles le sont, et il existe des limites à l’utilisation qui peut en être faite. En revanche, ces règles ne s’appliquent plus aux données synthétiques, car elles ne peuvent être attribuées à un sujet et ne contiennent pas d’informations personnelles.
- La troisième différence réside dans les quantités de données disponibles. Avec les données réelles, vous ne pouvez disposer que de la quantité que les utilisateurs vous donnent. En revanche, vous pouvez générer autant de données synthétiques que vous le souhaitez.
Pourquoi devriez-vous envisager d’utiliser des données synthétiques ?
- Les données synthétiques sont relativement moins chères à produire, car elles permettent de générer des ensembles de données beaucoup plus importants qui ressemblent à l’ensemble de données plus petit dont vous disposez déjà. Cela signifie que vos modèles d’apprentissage automatique disposeront de plus de données pour s’entraîner.
- Les données générées sont automatiquement étiquetées et nettoyées pour vous. Vous n’avez donc pas besoin de passer du temps à préparer les données pour l’apprentissage automatique ou l’analyse.
- Il n’y a pas de problème de confidentialité car les données ne sont pas personnellement identifiables et n’appartiennent pas à une personne concernée. Vous pouvez donc les utiliser et les partager librement.
- Vous pouvez surmonter les préjugés de l’IA en veillant à ce que les classes minoritaires soient bien représentées. Cela vous aidera à construire une IA juste et responsable.
Comment générer des données synthétiques ?
Bien que le processus de génération varie en fonction de l’outil que vous utilisez, il commence généralement par la connexion d’un générateur à un ensemble de données existant. Ensuite, vous identifiez les champs d’identification personnelle dans votre ensemble de données et les étiquetez pour les exclure ou les obscurcir.
Le générateur commence alors à identifier les types de données des colonnes restantes et les modèles statistiques de ces colonnes. À partir de là, vous pouvez générer autant de données synthétiques que vous le souhaitez.
En général, vous pouvez comparer les données générées avec l’ensemble de données original pour voir dans quelle mesure les données synthétiques ressemblent aux données réelles.
Nous allons maintenant explorer les outils de génération de données synthétiques pour entraîner les modèles d’apprentissage automatique.
Mostly AI

Mostly AI dispose d’un générateur de données synthétiques alimenté par l’IA qui apprend à partir des modèles statistiques de l’ensemble de données original. L’IA génère ensuite des personnages fictifs qui se conforment aux modèles appris.
Avec Mostly AI, vous pouvez générer des bases de données entières avec intégrité référentielle. Vous pouvez synthétiser toutes sortes de données pour vous aider à construire de meilleurs modèles d’IA.
Synthesized.io
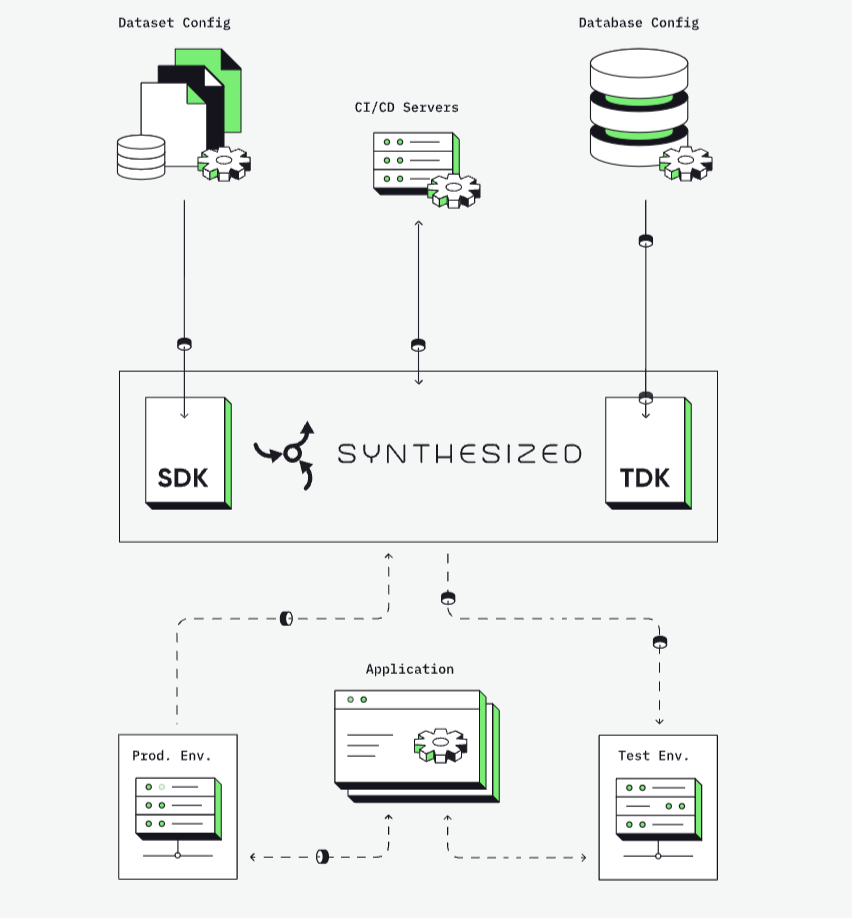
Synthesized.i o est utilisé par des entreprises de premier plan pour leurs initiatives en matière d’IA. Pour utiliser synthesize.io, vous spécifiez les exigences en matière de données dans un fichier de configuration YAML.
Vous créez ensuite une tâche et l’exécutez dans le cadre d’un pipeline de données. Il dispose également d’un niveau gratuit très généreux qui vous permet d’expérimenter et de voir s’il répond à vos besoins en matière de données.
YData

Avec YData, vous pouvez générer des données tabulaires, temporelles, transactionnelles, multi-tables et relationnelles. Cela vous permet d’éviter les problèmes liés à la collecte, au partage et à la qualité des données.
Il est livré avec une IA et un SDK à utiliser pour interagir avec sa plateforme. En outre, ils ont un niveau gratuit généreux que vous pouvez utiliser pour faire une démonstration du produit.
Gretel AI

GretelAI propose des API pour générer des quantités illimitées de données synthétiques. Gretel dispose d’un générateur de données open-source que vous pouvez installer et utiliser.
Vous pouvez également utiliser son API REST ou son CLI, ce qui a un coût. Les prix sont toutefois raisonnables et s’adaptent à la taille de l’entreprise.
Copulas
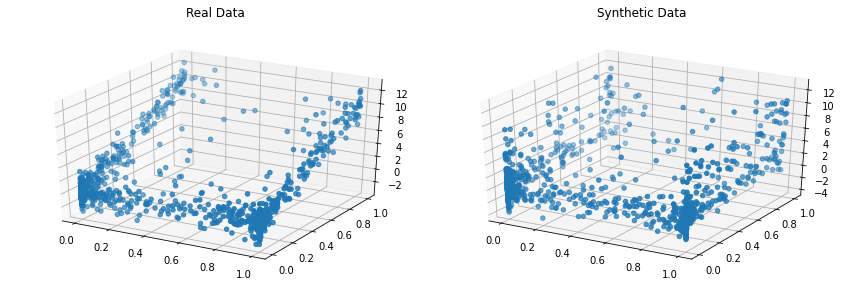
Copulas est une bibliothèque Python open-source pour modéliser des distributions multivariées à l’aide de fonctions copule et générer des données synthétiques qui suivent les mêmes propriétés statistiques.
Le projet a démarré en 2018 au MIT dans le cadre du projet Synthetic Data Vault.
CTGAN
CTGAN se compose de générateurs capables d’apprendre à partir de données réelles à tableau unique et de générer des données synthétiques à partir des modèles identifiés.
Il est implémenté sous la forme d’une bibliothèque Python open-source. CTGAN, ainsi que Copulas, font partie du projet Synthetic Data Vault.
DoppelGANger
DoppelGANger est une implémentation open-source de Generative Adversarial Networks pour générer des données synthétiques.
DoppelGANger est utile pour générer des données de séries temporelles et est utilisé par des entreprises telles que Gretel AI. La bibliothèque Python est disponible gratuitement et est open-source.
Synth
Synth est un générateur de données open-source qui vous aide à créer des données réalistes selon vos spécifications, à masquer des informations personnelles identifiables et à développer des données de test pour vos applications.
Vous pouvez utiliser Synth pour générer des séries en temps réel et des données relationnelles pour vos besoins d’apprentissage automatique. Synth est également agnostique en matière de bases de données, de sorte que vous pouvez l’utiliser avec vos bases de données SQL et NoSQL.
SDV.dev

SDV signifie Synthetic Data Vault (coffre-fort de données synthétiques). SDV.dev est un projet logiciel qui a débuté au MIT en 2016 et qui a créé différents outils pour générer des données synthétiques.
Ces outils comprennent Copulas, CTGAN, DeepEcho et RDT. Ces outils sont implémentés sous forme de bibliothèques Python open-source que vous pouvez facilement utiliser.
Tofu
Tofu est une bibliothèque Python open-source qui permet de générer des données synthétiques à partir des données de la biobanque britannique. Contrairement aux outils mentionnés précédemment qui vous aideront à générer n’importe quel type de données à partir de votre ensemble de données existant, Tofu génère des données qui ressemblent uniquement à celles de la biobanque.
La biobanque britannique est une étude sur les caractéristiques phénotypiques et génotypiques de 500 000 adultes d’âge moyen au Royaume-Uni.
Twinify
Twinify est un logiciel utilisé comme bibliothèque ou outil de ligne de commande pour jumeler des données sensibles en produisant des données synthétiques avec des distributions statistiques identiques.

Pour utiliser Twinify, vous fournissez les données réelles sous la forme d’un fichier CSV, et le logiciel apprend à partir des données pour produire un modèle qui peut être utilisé pour générer des données synthétiques. Son utilisation est entièrement gratuite.
Datanamic
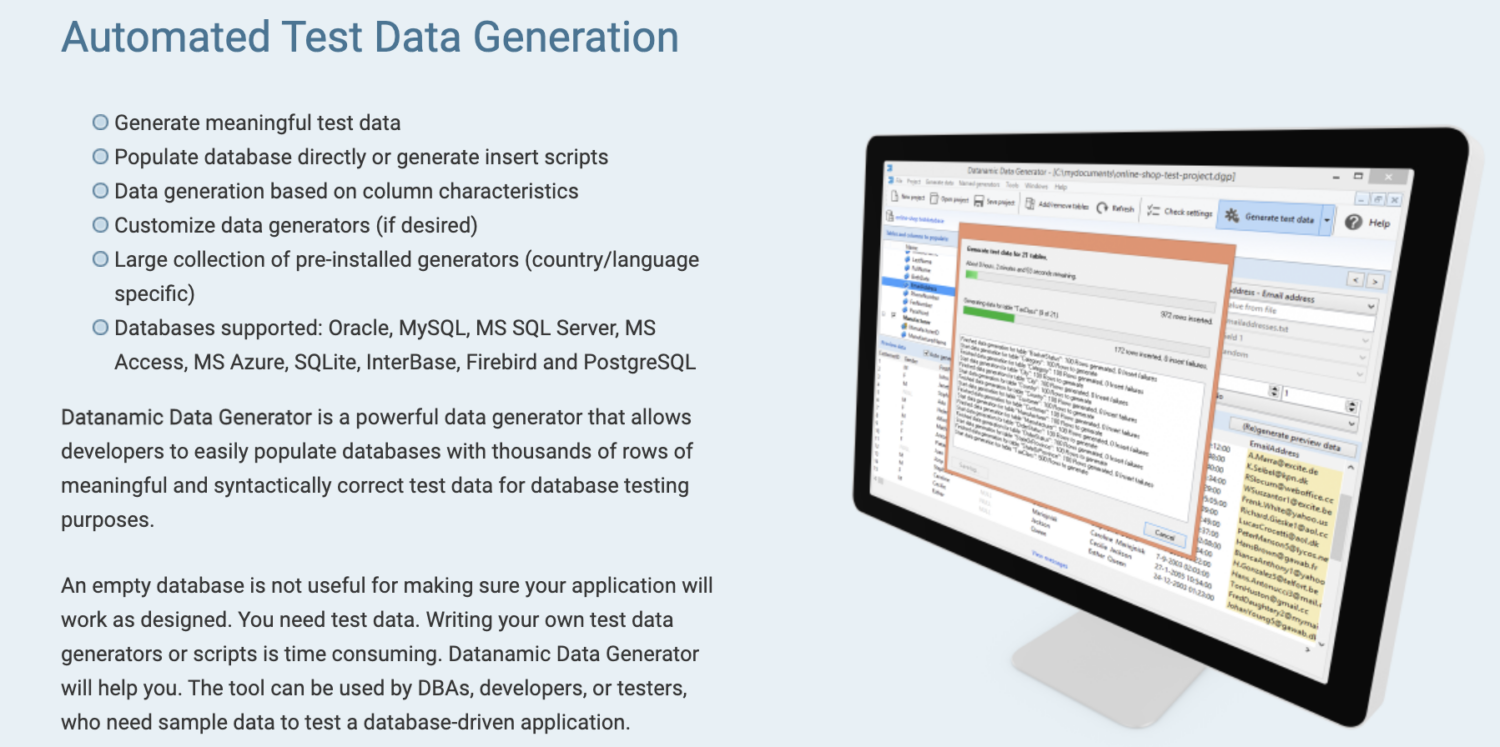
Datanamic vous aide à créer des données de test pour les applications fondées sur les données et l’apprentissage automatique. Il génère des données basées sur les caractéristiques des colonnes telles que l’email, le nom et le numéro de téléphone.
Les générateurs de données de Datanamic sont personnalisables et prennent en charge la plupart des bases de données telles qu’Oracle, MySQL, MySQL Server, MS Access et Postgres. Ils prennent en charge et garantissent l’intégrité référentielle des données générées.
Benerator
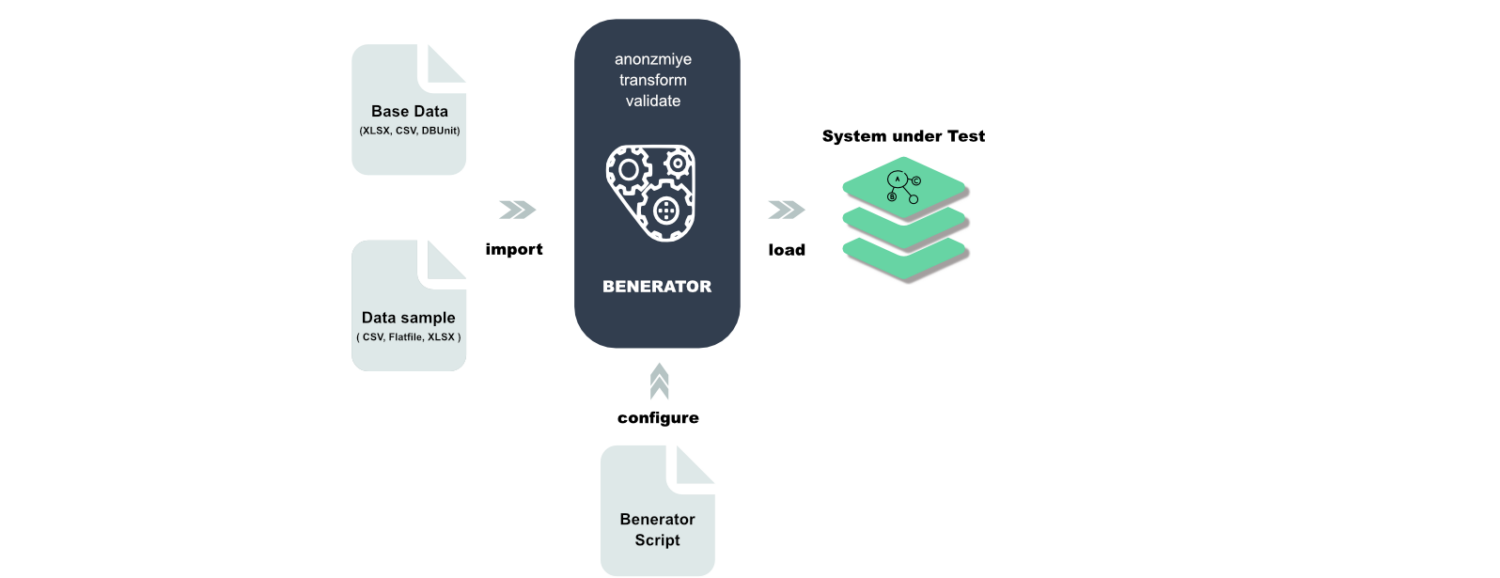
Benerator est un logiciel qui permet d’obscurcir, de générer et de migrer des données à des fins de test et de formation. Avec Benerator, vous décrivez les données à l’aide de XML (Extensible Markup Language) et les générez à l’aide de l’outil de ligne de commande.
Il est conçu pour être utilisé par des non-développeurs et vous permet de générer des milliards de lignes de données. Benerator est gratuit et open-source.
Le mot de la fin
Gartner estime que d’ici 2030, il y aura plus de données synthétiques utilisées pour l’apprentissage automatique que de données réelles.
Il n’est pas difficile de comprendre pourquoi, étant donné le coût et les problèmes de confidentialité liés à l’utilisation de données réelles. Il est donc nécessaire que les entreprises se familiarisent avec les données synthétiques et les différents outils qui les aident à les générer.
Ensuite, consultez les outils de surveillance synthétique pour votre entreprise en ligne.