Google JAX ou Just AfterExecutionest un cadre développé par Google pour accélérer les tâches d’apprentissage automatique.
Vous pouvez le considérer comme une bibliothèque pour Python, qui aide à accélérer l’exécution des tâches, le calcul scientifique, les transformations de fonctions, l’apprentissage profond, les réseaux neuronaux, et bien plus encore.
À propos de Google JAX
Le package de calcul le plus fondamental en Python est le package NumPy qui contient toutes les fonctions telles que les agrégations, les opérations vectorielles, l’algèbre linéaire, les manipulations de tableaux et de matrices à n dimensions, et bien d’autres fonctions avancées.
Et si nous pouvions accélérer davantage les calculs effectués à l’aide de NumPy, en particulier pour les ensembles de données volumineux ?
Avons-nous quelque chose qui pourrait fonctionner aussi bien sur différents types de processeurs, comme un GPU ou un TPU, sans aucune modification du code ?
Et si le système pouvait effectuer des transformations de fonctions composables automatiquement et plus efficacement ?
Google JAX est une bibliothèque (ou un cadre, comme le dit Wikipédia) qui fait exactement cela et peut-être bien plus encore. Elle a été conçue pour optimiser les performances et exécuter efficacement des tâches d’apprentissage automatique (ML) et d’apprentissage profond. Google JAX offre les fonctionnalités de transformation suivantes qui la rendent unique par rapport aux autres bibliothèques de ML et qui aident au calcul scientifique avancé pour l’apprentissage profond et les réseaux neuronaux :
- Auto-différenciation
- Vectorisation automatique
- Parallélisation automatique
- Compilation juste à temps (JIT)
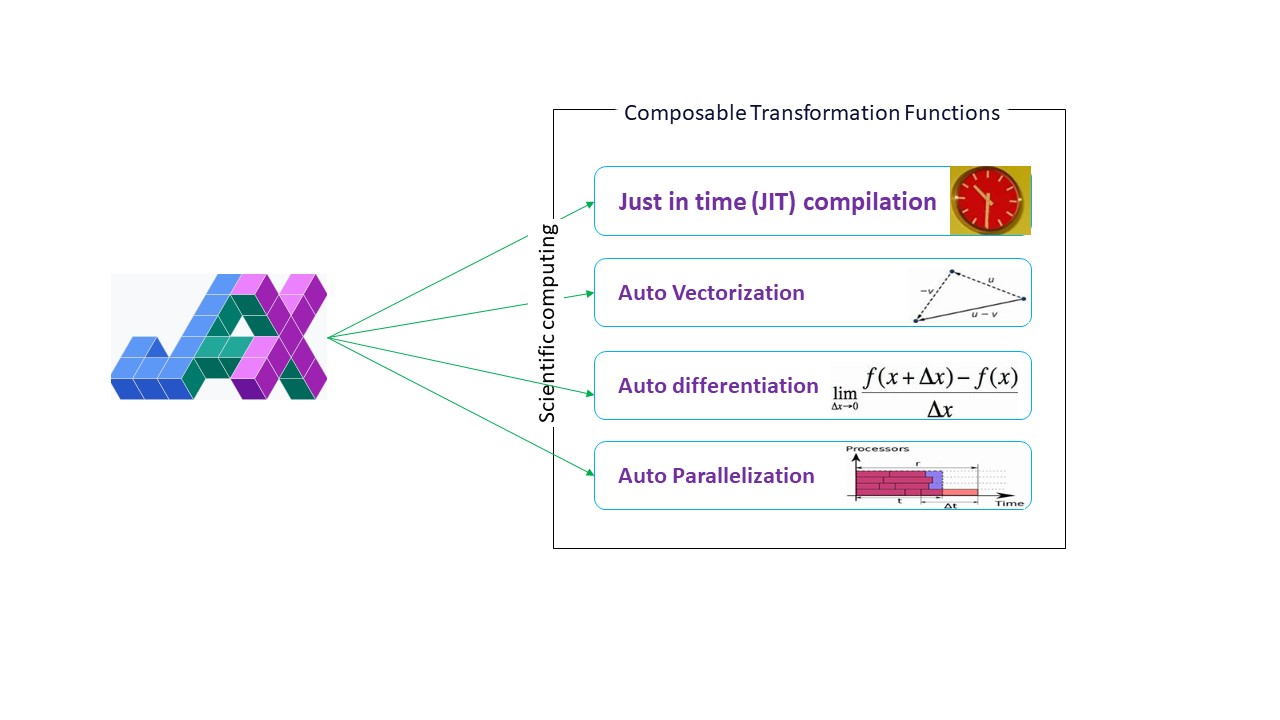
Toutes les transformations utilisent XLA (Accelerated Linear Algebra) pour de meilleures performances et une optimisation de la mémoire. XLA est un moteur de compilation optimisé spécifique à un domaine qui effectue de l’algèbre linéaire et accélère les modèles TensorFlow. L’utilisation de XLA en plus de votre code Python ne nécessite aucune modification significative du code !
Examinons en détail chacune de ces fonctionnalités.
Fonctionnalités de Google JAX
Google JAX est livré avec d’importantes fonctions de transformation composables pour améliorer les performances et effectuer des tâches d’apprentissage profond plus efficacement. Par exemple, la différenciation automatique permet d’obtenir le gradient d’une fonction et de trouver des dérivées de n’importe quel ordre. De même, la parallélisation automatique et le JIT permettent d’exécuter plusieurs tâches en parallèle. Ces transformations sont essentielles pour des applications telles que la robotique, les jeux et même la recherche.
Une fonction de transformation composable est une fonction pure qui transforme un ensemble de données en une autre forme. Elles sont appelées composables car elles sont autonomes (c’est-à-dire que ces fonctions ne dépendent pas du reste du programme) et sans état (c’est-à-dire que la même entrée produira toujours la même sortie).
Y(x) = T : (f(x))
Dans l’équation ci-dessus, f(x) est la fonction originale sur laquelle une transformation est appliquée. Y(x) est la fonction résultante après l’application de la transformation.
Par exemple, si vous avez une fonction nommée “total_facture_amt” et que vous souhaitez obtenir le résultat sous la forme d’une transformation de fonction, il vous suffit d’utiliser la transformation de votre choix, disons le gradient (grad) :
grad_total_bill = grad(total_bill_amt)
En transformant des fonctions numériques à l’aide de fonctions telles que grad(), nous pouvons facilement obtenir leurs dérivés d’ordre supérieur, que nous pouvons utiliser largement dans les algorithmes d’optimisation d’apprentissage profond tels que la descente de gradient, rendant ainsi les algorithmes plus rapides et plus efficaces. De même, en utilisant jit(), nous pouvons compiler les programmes Python juste à temps (lazily).
#1. Différenciation automatique
Python utilise la fonction autograd pour différencier automatiquement le code NumPy et le code Python natif. JAX utilise une version modifiée d’autograd (c’est-à-dire grad) et combine XLA (Accelerated Linear Algebra) pour effectuer une différenciation automatique et trouver des dérivées de n’importe quel ordre pour les GPU (Graphic Processing Units) et les TPU (Tensor Processing Units)]
Quelques mots sur les TPU, les GPU et les CPU : Le CPU ou Central Processing Unit (unité centrale de traitement) gère toutes les opérations de l’ordinateur. Le GPU est un processeur supplémentaire qui augmente la puissance de calcul et exécute des opérations haut de gamme. La TPU est une unité puissante spécifiquement développée pour les charges de travail complexes et lourdes telles que l’IA et les algorithmes d’apprentissage en profondeur.
À l’instar de la fonction autograd, qui permet de différencier les boucles, les récursions, les branches, etc., JAX utilise la fonction grad() pour les gradients en mode inverse (rétropropagation). Nous pouvons également différencier une fonction dans n’importe quel ordre à l’aide de grad :
grad(grad(grad(sin θ))) (1.0)
Autodifférenciation d’ordre supérieur
Comme nous l’avons mentionné précédemment, grad est très utile pour trouver les dérivées partielles d’une fonction. Nous pouvons utiliser une dérivée partielle pour calculer la descente de gradient d’une fonction de coût par rapport aux paramètres du réseau neuronal dans l’apprentissage profond afin de minimiser les pertes.
Calcul de la dérivée partielle
Supposons qu’une fonction comporte plusieurs variables, x, y et z. La dérivée d’une variable en maintenant les autres variables constantes est appelée dérivée partielle. Supposons que nous ayons une fonction,
f(x,y,z) = x 2y z2
Exemple de dérivée partielle
La dérivée partielle de x sera ∂f/∂x, ce qui nous indique comment une fonction change pour une variable lorsque les autres sont constantes. Si nous effectuons cette opération manuellement, nous devons écrire un programme pour différencier, l’appliquer pour chaque variable, puis calculer la descente du gradient. Pour plusieurs variables, cette opération devient complexe et prend beaucoup de temps.
La différenciation automatique décompose la fonction en un ensemble d’opérations élémentaires, telles que , -, *, / ou sin, cos, tan, exp, etc. et applique ensuite la règle de la chaîne pour calculer la dérivée. Nous pouvons effectuer cette opération en mode avant et en mode arrière.
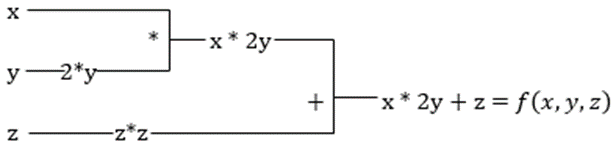
Il ne s’agit pas ce n’est pas ça ! Tous ces calculs se font très rapidement (pensez à un million de calculs similaires à ceux décrits ci-dessus et au temps que cela peut prendre !) XLA s’occupe de la vitesse et de la performance.
#2. Algèbre linéaire accélérée
Reprenons l’équation précédente. Sans XLA, le calcul nécessitera trois noyaux (ou plus), chaque noyau effectuant une tâche plus petite. Par exemple,
Noyau k1 –> x * 2y (multiplication)
k2 –> x * 2y z (addition)
k3 –> Réduction
Si la même tâche est exécutée par le XLA, un seul noyau se charge de toutes les opérations intermédiaires en les fusionnant. Les résultats intermédiaires des opérations élémentaires sont transmis en continu au lieu d’être stockés en mémoire, ce qui permet d’économiser de la mémoire et d’améliorer la vitesse.
#3. Compilation juste à temps
JAX utilise en interne le compilateur XLA pour accélérer la vitesse d’exécution. XLA peut augmenter la vitesse du CPU, du GPU et du TPU. Tout cela est possible grâce à l’exécution du code JIT. Pour ce faire, nous pouvons utiliser jit via l’importation :
from jax import jit
def ma_fonction(x) :
............quelques lignes de code
ma_fonction_jit = jit(ma_fonction)Une autre façon est de décorer jit sur la définition de la fonction :
@jit
def ma_fonction(x) :
............quelques lignes de codeCe code est beaucoup plus rapide car la transformation renvoie la version compilée du code à l’appelant au lieu d’utiliser l’interpréteur Python. Ceci est particulièrement utile pour les entrées vectorielles, comme les tableaux et les matrices.
Il en va de même pour toutes les fonctions Python existantes. Par exemple, les fonctions du paquet NumPy. Dans ce cas, nous devons importer jax.numpy en tant que jnp plutôt que NumPy :
import jax
import jax.numpy as jnp
x = jnp.array([[1,2,3,4], [5,6,7,8]])Une fois que vous avez fait cela, l’objet de base JAX appelé DeviceArray remplace le tableau NumPy standard. DeviceArray est paresseux – les valeurs sont conservées dans l’accélérateur jusqu’à ce qu’on en ait besoin. Cela signifie également que le programme JAX n’attend pas que les résultats reviennent au programme appelant (Python), suivant ainsi une distribution asynchrone.
#4. Vectorisation automatique (vmap)
Dans un monde typique d’apprentissage automatique, nous avons des ensembles de données avec un million ou plus de points de données. Il est très probable que nous effectuions des calculs ou des manipulations sur chacun ou sur la plupart de ces points de données – ce qui est une tâche qui prend beaucoup de temps et de mémoire ! Par exemple, si vous souhaitez trouver le carré de chacun des points de données de l’ensemble, la première chose qui vous vient à l’esprit est de créer une boucle et de prendre le carré un par un – argh !
Si nous créons ces points sous forme de vecteurs, nous pourrions faire tous les carrés en une seule fois en effectuant des manipulations vectorielles ou matricielles sur les points de données avec notre NumPy favori. Et si votre programme pouvait faire cela automatiquement, pourriez-vous demander quelque chose de plus ? C’est exactement ce que fait JAX ! Il peut vectoriser automatiquement tous vos points de données afin que vous puissiez facilement effectuer des opérations sur eux – ce qui rend vos algorithmes beaucoup plus rapides et efficaces.
JAX utilise la fonction vmap pour la vectorisation automatique. Considérez le tableau suivant :
x = jnp.array([1,2,3,4,5,6,7,8,9,10])
y = jnp.square(x)En faisant simplement ce qui précède, la méthode square s’exécutera pour chaque point du tableau. Mais si vous faites ce qui suit :
vmap(jnp.square(x))La méthode square ne s’exécutera qu’une seule fois parce que les points de données sont maintenant vectorisés automatiquement à l’aide de la méthode vmap avant d’exécuter la fonction, et le bouclage est repoussé au niveau élémentaire de l’opération – ce qui donne une multiplication matricielle plutôt qu’une multiplication scalaire, et donc de meilleures performances.
#5. Programmation SPMD (pmap)
La programmation SPMD ( Single Program Multiple Data) est essentielle dans les contextes d’apprentissage profond – vous appliquez souvent les mêmes fonctions sur différents ensembles de données résidant sur plusieurs GPU ou TPU. JAX dispose d’une fonction appelée pump, qui permet la programmation parallèle sur plusieurs GPU ou tout autre accélérateur. Comme JIT, les programmes utilisant pmap seront compilés par XLA et exécutés simultanément sur les systèmes. Cette parallélisation automatique fonctionne à la fois pour les calculs en avant et en arrière.
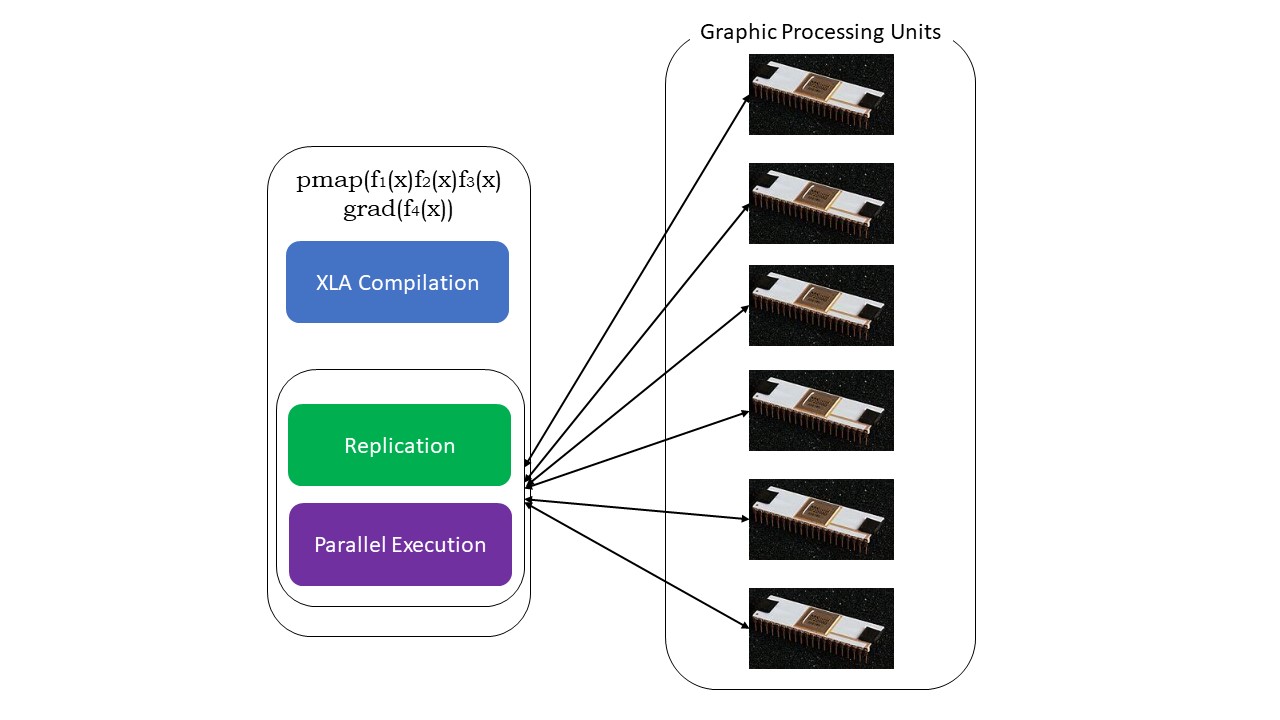
Nous pouvons également appliquer plusieurs transformations en une seule fois, dans n’importe quel ordre, à n’importe quelle fonction :
pmap(vmap(jit(grad (f(x)))))
Transformations multiples composables
Limites de Google JAX
Les développeurs de Google JAX ont bien pensé à accélérer les algorithmes d’apprentissage profond en introduisant toutes ces transformations géniales. Les fonctions et les paquets de calcul scientifique s’apparentent à NumPy, ce qui vous évite de vous soucier de la courbe d’apprentissage. Cependant, JAX présente les limitations suivantes :
- Google JAX en est encore aux premiers stades de développement et, bien que son objectif principal soit l’optimisation des performances, il n’offre pas beaucoup d’avantages pour le calcul sur l’unité centrale. NumPy semble plus performant, et l’utilisation de JAX ne ferait qu’ajouter à la charge de travail.
- JAX en est encore au stade de la recherche ou aux premiers stades de son développement et a besoin d’être peaufiné pour atteindre les normes d’infrastructure de frameworks tels que TensorFlow, qui sont mieux établis et disposent de plus de modèles prédéfinis, de projets open-source et de matériel d’apprentissage.
- Pour l’instant, JAX ne prend pas en charge le système d’exploitation Windows – vous aurez besoin d’une machine virtuelle pour le faire fonctionner.
- JAX ne fonctionne que pour les fonctions pures, c’est-à-dire celles qui n’ont pas d’effets secondaires. Pour les fonctions ayant des effets de bord, JAX peut ne pas être une bonne option.
Comment installer JAX dans votre environnement Python ?
Si vous avez installé Python sur votre système et que vous souhaitez exécuter JAX sur votre machine locale (CPU), utilisez les commandes suivantes :
pip install --upgrade pip
pip install --upgrade "jax[cpu]"Si vous souhaitez exécuter Google JAX sur un GPU ou un TPU, suivez les instructions données sur la page JAX de GitHub. Pour configurer Python, visitez la page de téléchargement officiel de python.
Conclusion
Google JAX est idéal pour l’écriture d’algorithmes d’apprentissage profond efficaces, la robotique et la recherche. Malgré ses limites, il est largement utilisé avec d’autres frameworks comme Haiku, Flax, et bien d’autres. Vous serez en mesure d’apprécier ce que JAX fait lorsque vous exécuterez des programmes et verrez les différences de temps d’exécution du code avec et sans JAX. Vous pouvez commencer par lire la documentation officielle de Google JAX, qui est très complète.