Les bases de données graphiques stockent des données denses hautement connectées et traitent les requêtes de manière efficace. Mais savez-vous quand utiliser telle ou telle base de données graphique ? Lisez ce qui suit pour en savoir plus.
“Les données sont le nouveau pétrole” La croissance de toute organisation dépend de la manière dont elle stocke et utilise efficacement les données. 2.5 quintillions d’octets de données sont générés chaque jour. Nous avons donc besoin de systèmes et d’entrepôts tolérants aux pannes où les données peuvent être stockées et gérées efficacement. Au départ, les bases de données relationnelles étaient utilisées.
Mais au fil du temps, la quantité et le type de données ont évolué rapidement. C’est ainsi qu’est apparu le besoin de stocker des données vidéo, audio, des images, etc. C’est ce qui a déclenché le développement des bases de données SQL, NoSQL, Hadoop, des bases de données graphiques, etc. Chacune a ses propres cas d’utilisation et traite des formats de données différents. Les bases de données graphiques ont été développées pour simplifier les opérations sur les données et pour un stockage efficace.
Bases de données graphiques
Un graphe est une structure de données représentée sous la forme de nœuds et d’arêtes. Une base de données est un ensemble de tables qui stocke des données et les relations entre ces données. Une base de données graphique est une base de données qui stocke les données sous forme de nœuds et les relations qui existent entre les données sous forme d’arêtes. Les bases de données graphiques permettent de traiter des requêtes en temps réel et de gérer efficacement les relations nombreuses entre les entités.
Les modèles de données graphiques les plus répandus sont les graphes de propriété et les graphes RDF. Les analyses et les requêtes sont principalement effectuées à l’aide de graphes de propriété. L’intégration des données se fait à l’aide des graphes RDF. La différence entre les graphes de propriété et les graphes RDF est que les graphes RDF sont représentés sous forme de triples, c’est-à-dire de sujet, de prédicat et d’objet.
Les bases de données graphiques stockent les données dans des nœuds et la relation entre les données sous la forme d’arêtes entre les nœuds. Les arêtes du graphe peuvent être dirigées (unidirectionnelles) ou non dirigées (bidirectionnelles).
Le traitement des requêtes se fait en parcourant le graphe. Les algorithmes de parcours de graphe qui aident à trouver le chemin d’un nœud à l’autre, la distance entre les nœuds, à trouver des modèles, des boucles dans le graphe et la possibilité de formation de grappes, etc. sont utilisés pour répondre efficacement aux requêtes.

Applications des bases de données graphiques
Les bases de données graphiques sont utilisées pour la détection des fraudes. Les nœuds/entités peuvent être des noms de personnes, des adresses, des dates de naissance, etc., et certaines adresses IP frauduleuses, des numéros d’appareils, etc. Lorsqu’un nœud frauduleux interagit avec un nœud non frauduleux, des liens se forment entre eux et sont marqués comme suspects.
Les sites web de médias sociaux utilisent des bases de données de graphes pour recommander les personnes avec lesquelles nous aimerions nous connecter et le contenu que nous voulons voir. Pour ce faire, ils s’appuient sur des parcours de graphes dans la base de données.
La cartographie du réseau et la gestion de l’infrastructure, les éléments de configuration, etc. sont également stockés et gérés efficacement à l’aide de bases de données graphiques.
Base de données graphique et base de données relationnelle
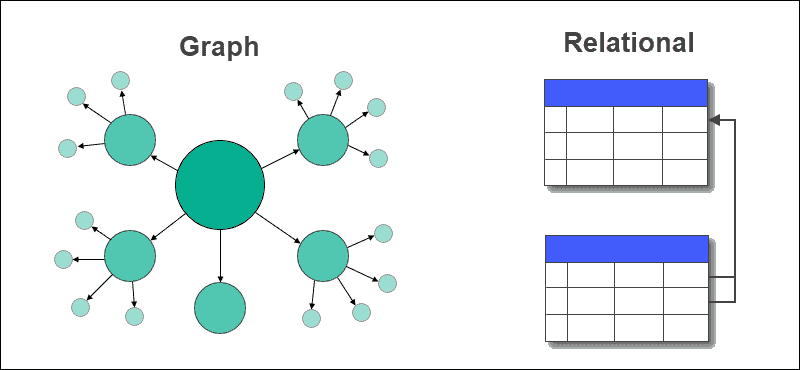
Dans une base de données graphique, les tableaux avec des lignes et des colonnes sont remplacés par des nœuds et des arêtes. Les relations entre les données sont stockées sur les arêtes dans une base de données graphique.
Une base de données relationnelle stocke les relations entre les tables à l’aide de clés étrangères et d’autres tables. L’extraction de données ou l’interrogation est facile et ne nécessite pas de jointures complexes dans une base de données graphique, ce qui n’est pas le cas des bases de données relationnelles.
Les bases de données relationnelles conviennent mieux aux cas d’utilisation qui impliquent des transactions, tandis que les bases de données graphiques conviennent aux applications à forte intensité de relations et de données.
Les bases de données graphiques prennent en charge les données structurées, semi-structurées et non structurées, alors que les bases de données relationnelles doivent avoir un schéma fixe.
Les bases de données graphiques répondent à des besoins dynamiques, tandis que les bases de données relationnelles sont généralement utilisées pour des problèmes connus et statiques.
Examinons maintenant les meilleures solutions de bases de données graphiques.
Cayley
Cayley est une base de données graphique open-source développée par Apache 2.0. Elle a été construite en utilisant Go et fonctionne avec des données liées. Cayley est la base de données utilisée pour construire la Freebase et le Knowledge Graph de Google. Elle prend en charge plusieurs langages d’interrogation comme MQL et Javascript avec un objet de graphe basé sur Gremlin.

Elle est facile à utiliser, rapide et modulaire. Il peut s’intégrer et interagir avec diverses bases de données telles que LevelDB, MongoDB et Bolt. Il prend en charge diverses API tierces écrites dans plusieurs langages comme Java, .NET, Rust, Haskell, Ruby, PHP, Javascript et Clojure. Il peut être déployé dans Docker et Kubernetes. Les principaux domaines dans lesquels Cayley est utilisé sont les technologies de l’information, les logiciels informatiques et les services financiers.
Amazon Neptune
Amazon Neptune est connu pour ses performances exceptionnelles sur des ensembles de données hautement connectés. Il est fiable, sécurisé, entièrement géré et prend en charge les API graphiques ouvertes. Il peut stocker des milliards de relations et interroger les données avec une latence extrêmement faible de quelques millisecondes.
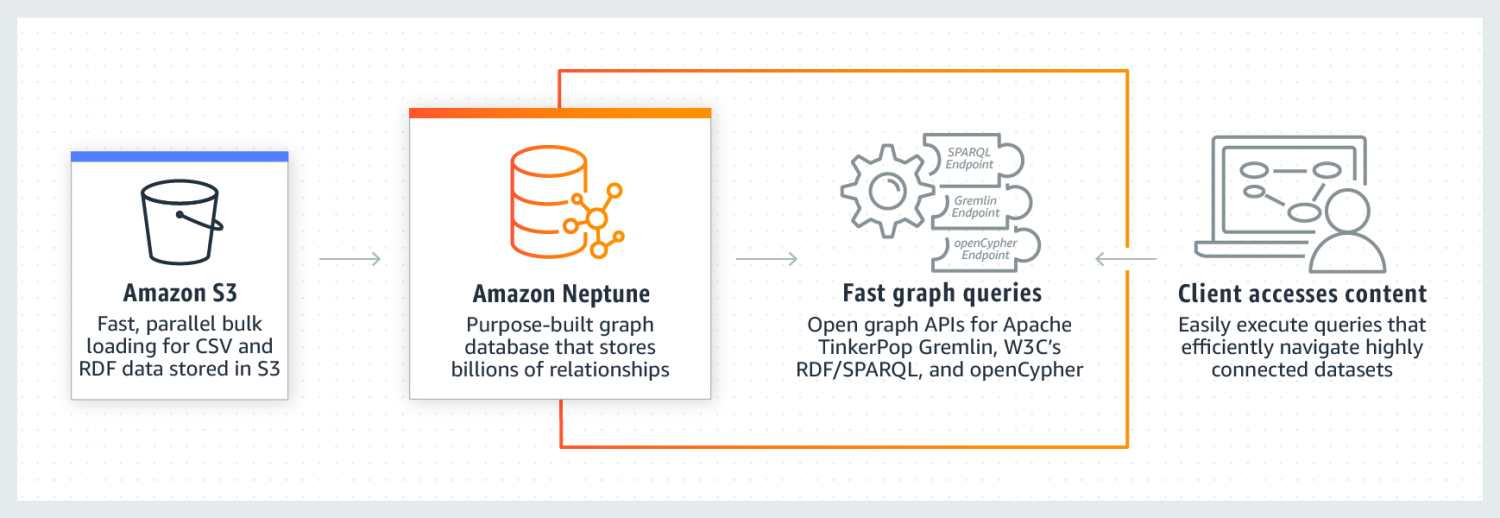
Le modèle de données graphiques de Neptune se compose de quatre positions, à savoir le sujet (S), le prédicat (P), l’objet (O) et le graphe (G). Chacune de ces positions est utilisée pour stocker la position du nœud source, du nœud cible, la relation entre eux et leurs propriétés.
Il utilise également un cache qui accélère l’exécution des requêtes de lecture. Les données sont stockées sous la forme de grappes de bases de données. Chaque grappe comprend une instance de base de données primaire et des répliques en lecture des instances de base de données. Neptune est hautement sécurisé car il utilise l’authentification IAM, la certification SSL et la surveillance des journaux. Il est également facile de migrer des données d’autres sources vers Amazon Neptune. Il garantit également la résilience en créant des répliques et des sauvegardes périodiques. Parmi les entreprises qui utilisent Neptune, citons Herren, Onedot, Juncture et Hi Platform.
Neo4j
Neo4j est une base de données graphique évolutive, sécurisée, à la demande et fiable. Neo4j a été conçu en Java, en utilisant Cypher comme langage d’interrogation. Elle utilise le protocole Bolt et toutes les transactions se font par l’intermédiaire d’un point de terminaison HTTP. Elle répond beaucoup plus rapidement aux requêtes que les autres bases de données relationnelles. Il n’y a pas de frais généraux liés à des jointures complexes et ses optimisations fonctionnent bien lorsque la taille de l’ensemble des données est importante et qu’elles sont fortement connectées. Elle offre l’avantage du stockage des graphes ainsi que les propriétés ACID d’une base de données relationnelle.

Neo4j prend en charge divers langages tels que Java, .NET, Node.js, Ruby, Python, etc. à l’aide de pilotes. Il est également utilisé dans la science des données graphiques, l’analyse et les flux de travail d’apprentissage automatique. Neo4j Aura DB est une base de données graphique en nuage tolérante aux pannes et entièrement gérée. Des entreprises comme Microsoft, Cisco, Adobe, eBay, IBM, Samsung, etc. utilisent Neo4j.
ArangoDB
ArangoDB est une base de données multi-modèle open-source. L’approche multi-modèle permet aux utilisateurs d’interroger les données dans le langage de leur choix. Les nœuds et les arêtes d’ArangoDB sont des documents JSON. Chaque document a un identifiant unique. Les relations entre deux nœuds sont indiquées sous forme d’arêtes, et leurs identifiants uniques sont stockés. Ses bonnes performances sont dues à la présence d’un index de hachage.

Les déplacements, les jointures et les recherches dans les bases de données sont améliorés. Il facilite la conception, la mise à l’échelle et l’adaptation à diverses architectures. Il joue un rôle important dans les tâches complexes de science des données telles que l’extraction de caractéristiques et la recherche avancée.
ArrangoDB peut fonctionner dans un environnement en nuage et est compatible avec Mac Os, Linux et Windows. L’authentification LDAP, le masquage des données et les algorithmes de cryptage garantissent la sécurité de la base de données. Elle est utilisée dans la gestion des risques, l’IAM, la détection des fraudes, l’infrastructure de réseau, les moteurs de recommandation, etc. Accenture, Cisco, Dish et VMware sont quelques-unes des organisations qui utilisent ArangoDB.
DataStax
DataStax est une base de données NoSQL en nuage (cloud database-as-a-service) construite sur Apache Cassandra. Elle est hautement évolutive et utilise une architecture cloud-native. Elle est fiable et sécurisée. Chaque document stocké dans une base de données DataStax possède un index qui facilite la recherche et la récupération rapide des données. Des ” shards ” sont créés sur les données indexées. Diverses sources de données peuvent être utilisées pour créer des applications avec les outils Datastax Enterprise, Kafka et Docker.
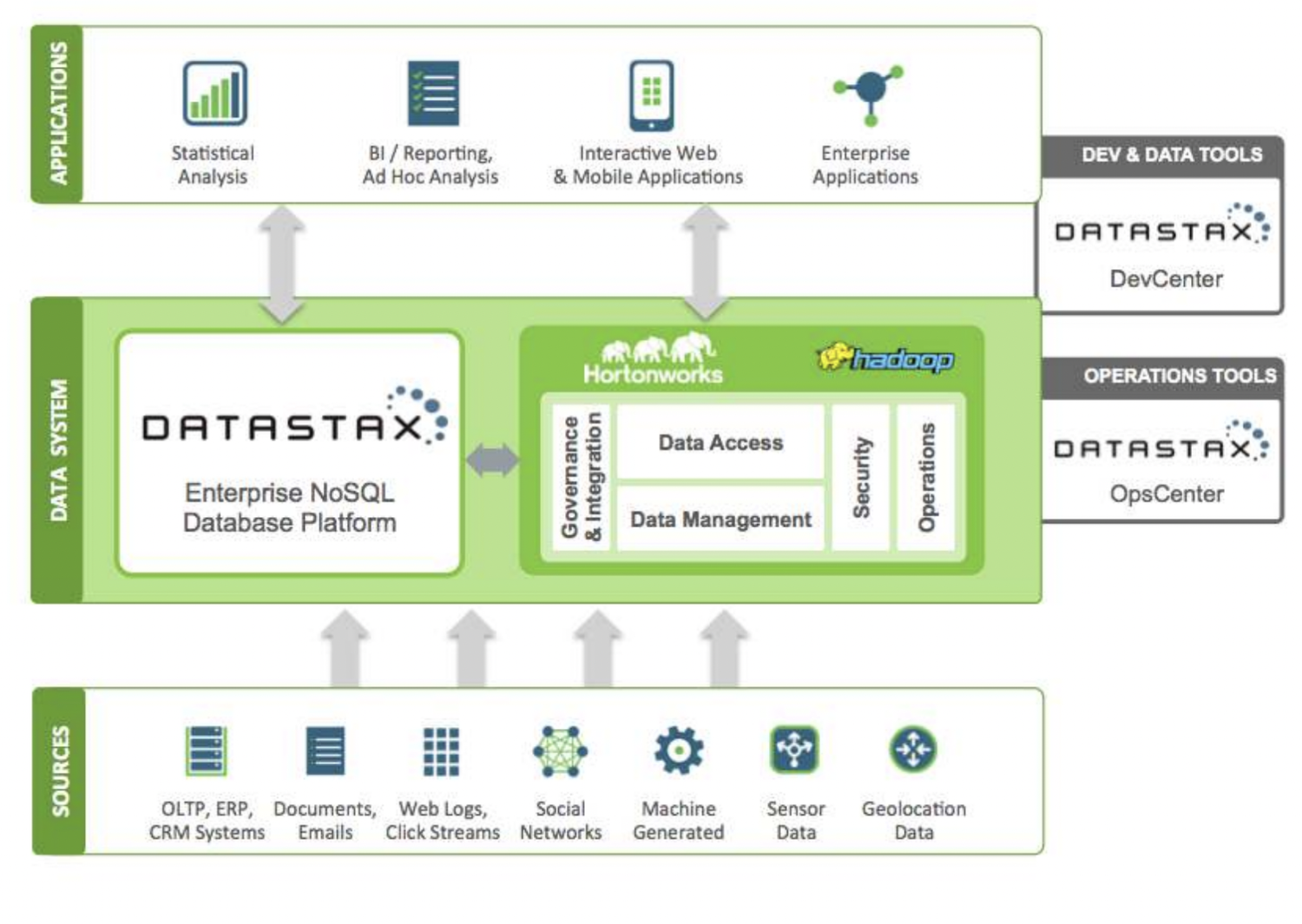
Les données collectées à partir des sources sont envoyées à un écosystème Hadoop et à DataStax. Hadoop gère la sécurité, les opérations, l’accès aux données et la gestion en interagissant avec DataStax. Les données sont affinées à l’aide des outils de développement et d’exploitation de Datastax.
Les informations analysées sont ensuite utilisées pour des analyses statistiques, des applications d’entreprise, des rapports, etc. Comme il s’agit d’une solution en nuage, les clients paient pour ce qu’ils utilisent, et les prix sont raisonnables. Verizon, CapitalOne, TMobile et Overstock sont quelques-unes des entreprises qui utilisent DataStax.
Orient DB
OrientDB est une base de données graphique qui gère efficacement les données et permet de créer des représentations visuelles pour les mettre en valeur. Il s’agit d’une base de données graphique multi-modèle construite en Java. Elle stocke les données sous forme de paires clé-valeur, de documents, de modèles d’objets, etc. Il se compose de trois éléments principaux : l’éditeur de graphes, le studio de requêtes et la console de ligne de commande.
L’éditeur de graphes permet de visualiser les données et d’interagir avec elles. L’interface de requête Studio est utilisée pour exécuter des requêtes et fournir immédiatement des résultats sous forme d’images et de tableaux. La console de ligne de commande est utilisée pour interroger les données d’OrientDB. OrientDB a une architecture distribuée avec plusieurs serveurs qui peuvent effectuer des opérations de lecture et d’écriture. Les serveurs répliques sont utilisés pour effectuer des opérations de lecture et d’interrogation. Il prend en charge l’indexation et est également conforme à la norme ACID. Parmi les entreprises qui utilisent OrientDB, citons Comcast Corporation et Blackfriars Group.
Dgraph
Dgraph est une base de données graphique en nuage qui prend en charge GraphQL. Elle a été conçue en utilisant Go. Elle minimise les appels réseau et réduit la latence en maximisant le traitement simultané des requêtes. L’intégration transparente de Dgraph avec GraphQL facilite le développement d’applications dorsales GraphQL.

Une mutation GraphQL passe par une fonction Lambda qui interagit avec la base de données et un pipeline de données. Cela simplifie le traitement des requêtes. Il est évolutif horizontalement, ce qui signifie que le nombre de ressources augmente avec l’accroissement des requêtes et des données. Il offre diverses fonctionnalités telles que l’autorisation basée sur JWT, le visualisateur de données, l’authentification en nuage, les sauvegardes de données, etc. Parmi les organisations qui utilisent Dgraph, citons Intuit, intel et Factset.
Tigergraph
Tigergraph est une base de données de graphes de propriétés développée en C . Elle est très évolutive et permet d’effectuer des analyses avancées sur des données hautement connectées. Elle utilise une structure graphique native pour le stockage des données et un moteur de traitement des graphes pour le traitement des données. La base de données est stockée sur disque et en mémoire et utilise également un cache CPU pour une récupération rapide. Il utilise la fonction Map Reduce pour le traitement parallèle des données.
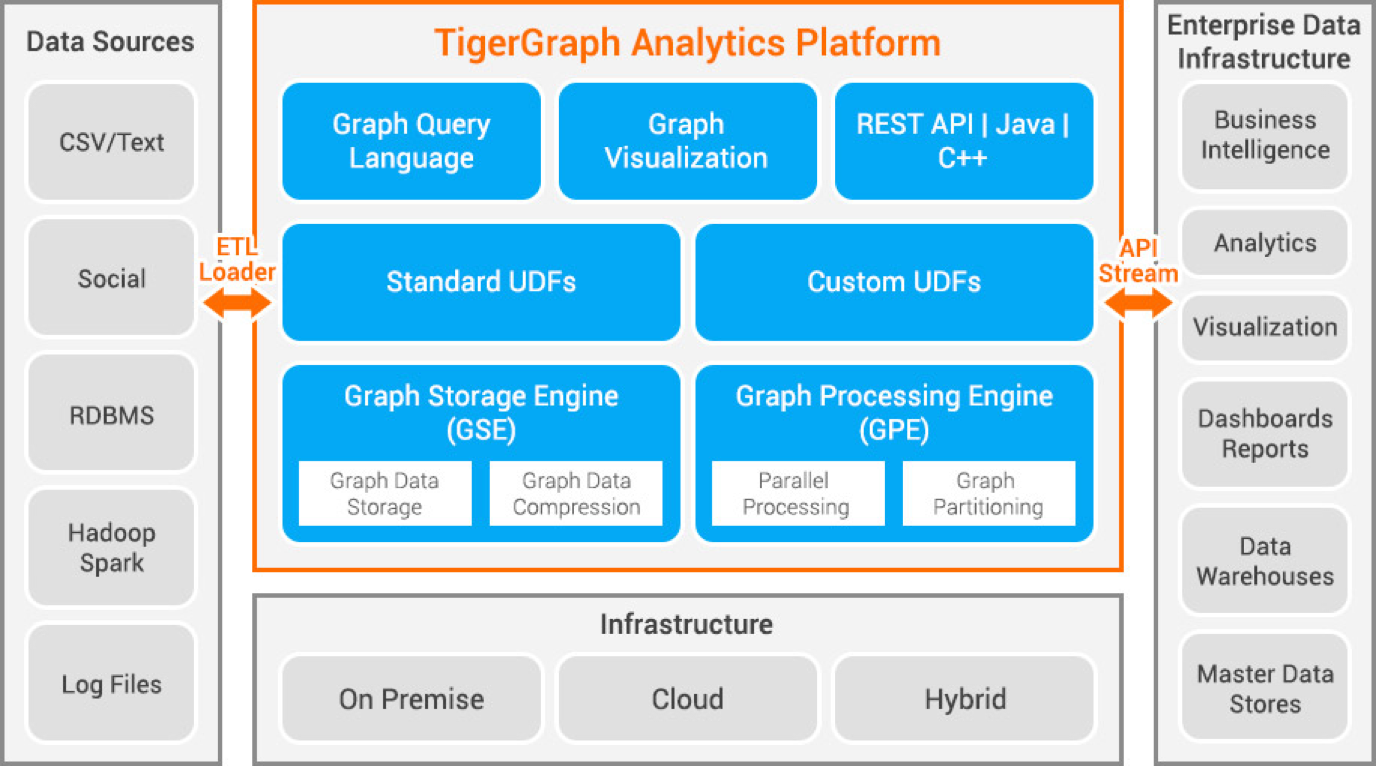
Il est extrêmement rapide et évolutif. Il effectue des calculs en parallèle et fournit des mises à jour en temps réel. Il utilise des techniques de compression des données et les multiplie par 10. Il partitionne automatiquement les données entre les serveurs, ce qui évite à l’utilisateur de perdre du temps et de l’énergie à diviser les données manuellement. Il est utilisé pour la détection des fraudes dans les ménages, la gestion de la chaîne d’approvisionnement et l’amélioration des soins de santé. JPMorgan Chase, Intuit et United Health Group sont quelques-unes des organisations qui utilisent Tigergraph.
AllegroGraph
AllegroGraph utilise la technologie des graphes de connaissances entité-événement pour effectuer des analyses et prendre des décisions sur des données hautement connectées, complexes et denses. Les données sont stockées au format JSON et JSON-LD dans les nœuds du graphe. Il utilise l’architecture du protocole REST. Il traite également des ensembles de données extrêmement volumineux en divisant les données sur la base de critères spécifiques et en les répartissant dans plusieurs référentiels de bases de connaissances.
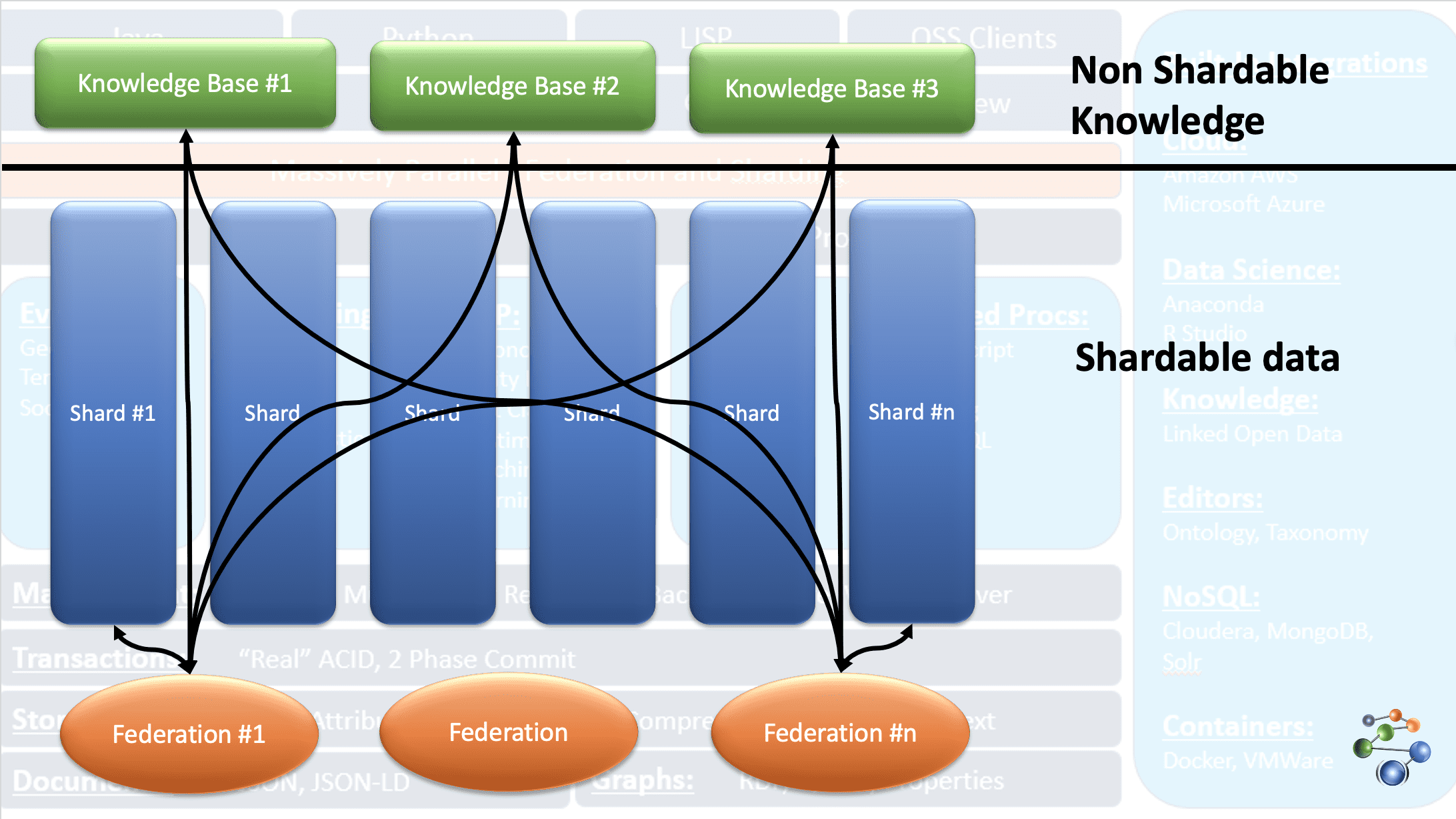
Cela est possible grâce à la fonctionnalité FedShard de la base de données AllegroGraph. L’exécution des requêtes se fait en combinant les fédérations avec les référentiels de bases de connaissances. Elle prend en charge les types de schémas XML et utilise des indices triples. Elle stocke des données géospatiales comme les latitudes et les longitudes et des données temporelles comme la date, l’horodatage, etc. Il est compatible avec Windows, Mac et Linux. Il est utilisé pour la détection des fraudes, les soins de santé, l’identification des entités, la prédiction des risques, etc.
Stardog
Stardog est une base de données graphique qui effectue la virtualisation des données graphiques et relie les données des entrepôts de données et des lacs de données sans copier physiquement les données dans un nouvel emplacement de stockage. Stardog s’appuie sur les normes ouvertes RDF. Il prend en charge les données structurées, semi-structurées et non structurées. Ce type de matérialisation effectué par Stardog offre une grande flexibilité. C’est la seule base de données de graphes qui combine les graphes de connaissances et la virtualisation.

Stardog utilise un moteur d’inférence basé sur l’intelligence artificielle pour traiter et fournir des résultats de requêtes de manière efficace. Il s’agit d’une base de données de graphes conforme à la norme ACID. Les lectures et écritures simultanées sont prises en charge. Elle traite les requêtes complexes avec facilité grâce à son architecture de pointe. Elle est utilisée pour la gestion des actifs informatiques, la gestion et l’analyse des données et offre une haute disponibilité. Parmi les entreprises qui utilisent Stardog, citons Cisco, eBay, la NASA et Finra.
Quelques mots pour conclure
Les bases de données graphiques permettent d’interroger facilement les relations de plusieurs à plusieurs et de stocker efficacement les données. Elles sont évolutives, sécurisées et peuvent être intégrées à de nombreux outils, API et langages tiers. Ces dernières années, elles ont été intégrées à l’informatique en nuage et offrent les meilleures performances.
Ils simplifient les jointures complexes en requêtes simples, ce qui facilite la tâche des développeurs. Les tâches à forte intensité de données telles que l’IdO et le Big Data sont également des bases de données graphiques. Celles-ci continueront d’évoluer et s’étendront certainement à d’autres cas d’utilisation à l’avenir.