Les langues humaines sont difficiles à comprendre pour les machines, car elles comportent beaucoup d’acronymes, de significations différentes, de sous-sens, de règles grammaticales, de contexte, d’argot et bien d’autres aspects.
Or, de nombreux processus et opérations commerciales font appel à des machines et nécessitent une interaction entre les machines et les humains.
Les scientifiques avaient donc besoin d’une technologie qui aiderait les machines à décoder les langues humaines et simplifierait leur apprentissage.
C’est ainsi que les algorithmes de traitement du langage naturel (NLP) ont vu le jour. Ils ont rendu les programmes informatiques capables de comprendre les différentes langues humaines, qu’elles soient écrites ou parlées.
Le TAL utilise différents algorithmes pour traiter les langues. Avec l’introduction des algorithmes de TAL, la technologie est devenue un élément essentiel de l’intelligence artificielle (IA) pour aider à rationaliser les données non structurées.
Dans cet article, je vais vous parler du NLP et de certains des algorithmes NLP les plus utilisés.
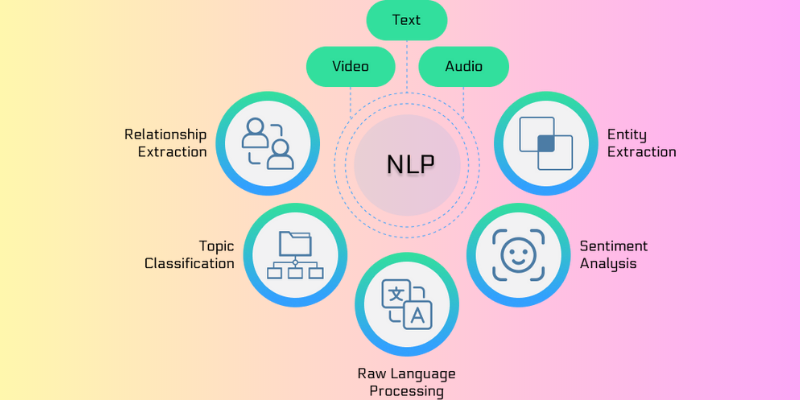
Qu’est-ce que le NLP ?
Le traitement du langage naturel (TLN) est un domaine de l’informatique, de la linguistique et de l’intelligence artificielle qui traite de l’interaction entre le langage humain et les ordinateurs. Il aide à programmer les machines de manière à ce qu’elles puissent analyser et traiter de grands volumes de données associées aux langues naturelles.

En d’autres termes, le NLP est une technologie ou un mécanisme moderne utilisé par les machines pour comprendre, analyser et interpréter le langage humain. Il donne aux machines la capacité de comprendre les textes et le langage parlé des humains. Grâce au NLP, les machines peuvent effectuer des traductions, des reconnaissances vocales, des résumés, des segmentations thématiques et bien d’autres tâches pour le compte des développeurs.
Le plus intéressant, c’est que le NLP effectue tout le travail et toutes les tâches en temps réel à l’aide de plusieurs algorithmes, ce qui le rend beaucoup plus efficace. C’est l’une des technologies qui mélange l’apprentissage automatique, l’apprentissage profond et les modèles statistiques avec une modélisation informatique basée sur des règles linguistiques.
Les algorithmes de NLP permettent aux ordinateurs de traiter le langage humain à travers des textes ou des données vocales et d’en décoder le sens à des fins diverses. La capacité d’interprétation des ordinateurs a tellement évolué que les machines peuvent même comprendre les sentiments humains et l’intention qui se cache derrière un texte. La PNL peut également prédire les mots ou les phrases qui viendront à l’esprit d’un utilisateur lorsqu’il écrit ou parle.
Cette technologie existe depuis des décennies et, avec le temps, elle a été évaluée et a permis d’améliorer la précision des processus. La PNL a ses racines dans le domaine de la linguistique et a même aidé les développeurs à créer des moteurs de recherche pour l’internet. La technologie ayant évolué avec le temps, l’utilisation de la PNL s’est élargie.
Aujourd’hui, la PNL trouve des applications dans un large éventail de domaines, allant de la finance, des moteurs de recherche et de l’intelligence économique aux soins de santé et à la robotique. En outre, la PNL est entrée en profondeur dans les systèmes modernes ; elle est utilisée pour de nombreuses applications populaires telles que les GPS à commande vocale, les chatbots de service à la clientèle, l’assistance numérique, les opérations de conversion de la parole en texte, et bien d’autres encore.
Comment fonctionne la PNL ?
La PNL est une technologie dynamique qui utilise différentes méthodologies pour traduire le langage humain complexe pour les machines. Elle fait principalement appel à l’intelligence artificielle pour traiter et traduire les mots écrits ou parlés afin qu’ils puissent être compris par les ordinateurs.
Tout comme les humains disposent d’un cerveau pour traiter toutes les données, les ordinateurs utilisent un programme spécialisé qui les aide à traiter les données et à les rendre compréhensibles. La PNL fonctionne en deux phases au cours de la conversion, l’une étant le traitement des données et l’autre le développement d’algorithmes.
Le traitement des données constitue la première phase, au cours de laquelle les données textuelles d’entrée sont préparées et nettoyées afin que la machine puisse les analyser. Les données sont traitées de manière à faire ressortir toutes les caractéristiques du texte d’entrée et à le rendre compatible avec les algorithmes informatiques. Fondamentalement, l’étape du traitement des données prépare les données sous une forme que la machine peut comprendre.
Les techniques impliquées dans cette phase sont les suivantes :
- Latokenisation: Le texte d’entrée est divisé en petites formes de manière à ce que le NLP puisse travailler dessus.
- Suppression des mots vides: La technique de suppression des mots vides supprime tous les mots familiers du texte et les transforme en une forme qui conserve toutes les informations dans un état minimal.
- Lemmatisationet troncature: La lemmatisation et le stemming permettent de réduire les mots à leur structure racine afin que les machines puissent les traiter facilement.
- Étiquetage des parties du discours: De cette manière, les mots d’entrée sont marqués en fonction de leur nom, de leurs adjectifs et de leurs verbes, puis ils sont traités.
Une fois que les données d’entrée sont passées par la première phase, la machine développe un algorithme qui lui permet de les traiter. Parmi tous les algorithmes de TAL utilisés pour traiter les mots prétraités, les systèmes basés sur des règles et ceux basés sur l’apprentissage automatique sont largement utilisés :
- Systèmes basés sur des règles : Dans ce cas, le système utilise des règles linguistiques pour le traitement final des mots. Il s’agit d’un algorithme ancien qui est encore utilisé à grande échelle.
- Systèmes basés sur l’apprentissage automatique : Il s’agit d’un algorithme avancé qui combine les réseaux neuronaux, l’apprentissage profond et l’apprentissage automatique pour décider de sa propre règle de traitement des mots. Comme il utilise des méthodes statistiques, l’algorithme décide du traitement des mots en fonction des données d’apprentissage, et il apporte des modifications au fur et à mesure.
Catégories d’algorithmes de TAL
Les algorithmes de TAL sont des algorithmes ou des instructions basés sur le ML qui sont utilisés lors du traitement des langues naturelles. Ils s’intéressent au développement de protocoles et de modèles qui permettent à une machine d’interpréter les langues humaines.

Les algorithmes de TAL peuvent modifier leur forme en fonction de l’approche de l’IA et des données d’entraînement qui leur ont été fournies. La tâche principale de ces algorithmes consiste à utiliser différentes techniques pour transformer efficacement des données confuses ou non structurées en informations pertinentes dont la machine peut tirer des enseignements.
En plus de toutes les techniques, les algorithmes NLP utilisent les principes du langage naturel pour rendre les données d’entrée plus compréhensibles pour la machine. Ils sont chargés d’aider la machine à comprendre la valeur contextuelle d’une entrée donnée, faute de quoi la machine ne sera pas en mesure d’exécuter la requête.
Les algorithmes de NLP sont répartis en trois catégories principales, et les modèles d’IA choisissent l’une ou l’autre de ces catégories en fonction de l’approche du data scientist. Ces catégories sont les suivantes
#1. Algorithmes symboliques
Les algorithmes symboliques constituent l’un des piliers des algorithmes de NLP. Ils sont chargés d’analyser le sens de chaque texte d’entrée et de l’utiliser pour établir une relation entre différents concepts.
Les algorithmes symboliques s’appuient sur des symboles pour représenter la connaissance et la relation entre les concepts. Comme ces algorithmes utilisent la logique et attribuent des significations aux mots en fonction du contexte, vous pouvez obtenir une grande précision.
Les graphes de connaissances jouent également un rôle crucial dans la définition des concepts d’un langage d’entrée et des relations entre ces concepts. Grâce à sa capacité à définir correctement les concepts et à comprendre facilement le contexte des mots, cet algorithme contribue à la construction de l’XAI.
Cependant, les algorithmes symboliques sont difficiles à étendre un ensemble de règles en raison de diverses limitations.
#2. Algorithmes statistiques
Les algorithmes statistiques peuvent faciliter le travail des machines en parcourant les textes, en comprenant chacun d’entre eux et en en extrayant le sens. Il s’agit d’un algorithme NLP très efficace car il aide les machines à apprendre le langage humain en reconnaissant des modèles et des tendances dans l’ensemble des textes d’entrée. Cette analyse permet aux machines de prédire en temps réel quel mot est susceptible d’être écrit après le mot actuel.
De la reconnaissance vocale à la suggestion de texte, en passant par l’analyse des sentiments et la traduction automatique, les algorithmes statistiques sont utilisés dans de nombreuses applications. La principale raison de leur utilisation généralisée est qu’ils peuvent fonctionner sur de grands ensembles de données.
En outre, les algorithmes statistiques peuvent détecter si deux phrases d’un paragraphe ont un sens similaire et déterminer celle qu’il convient d’utiliser. Cependant, le principal inconvénient de cet algorithme est qu’il dépend en partie d’une ingénierie complexe des caractéristiques.
#3. Algorithmes hybrides
Ce type d’algorithme de TAL combine la puissance des algorithmes symboliques et statistiques pour produire un résultat efficace. En se concentrant sur les principaux avantages et caractéristiques, il peut facilement annuler les faiblesses maximales de l’une ou l’autre approche, ce qui est essentiel pour une grande précision.

Les deux approches peuvent être exploitées de nombreuses façons :
- Apprentissage symbolique à l’appui de l’apprentissage automatique
- L’apprentissage automatique au service de l’approche symbolique
- Travail en parallèle de l’apprentissage symbolique et de l’apprentissage automatique
Les algorithmes symboliques peuvent soutenir l’apprentissage automatique en l’aidant à former le modèle de manière à ce qu’il ait moins d’efforts à faire pour apprendre le langage par lui-même. Bien que l’apprentissage automatique prenne en charge les méthodes symboliques, le modèle d’apprentissage automatique peut créer un ensemble de règles initial pour la symbolique et éviter à l’expert en données de le construire manuellement.
Cependant, lorsque l’apprentissage symbolique et l’apprentissage automatique fonctionnent ensemble, ils donnent de meilleurs résultats car ils peuvent garantir que les modèles comprennent correctement un passage spécifique.
Les meilleurs algorithmes de NLP
Il existe de nombreux algorithmes de NLP qui aident un ordinateur à émuler le langage humain pour le comprendre. Voici les meilleurs algorithmes de PNL que vous pouvez utiliser :
#1. Modélisation des sujets
Topic modeling is one of the algorithms that use statistical NLP techniques to find main themes or topics from a large number of text documents.
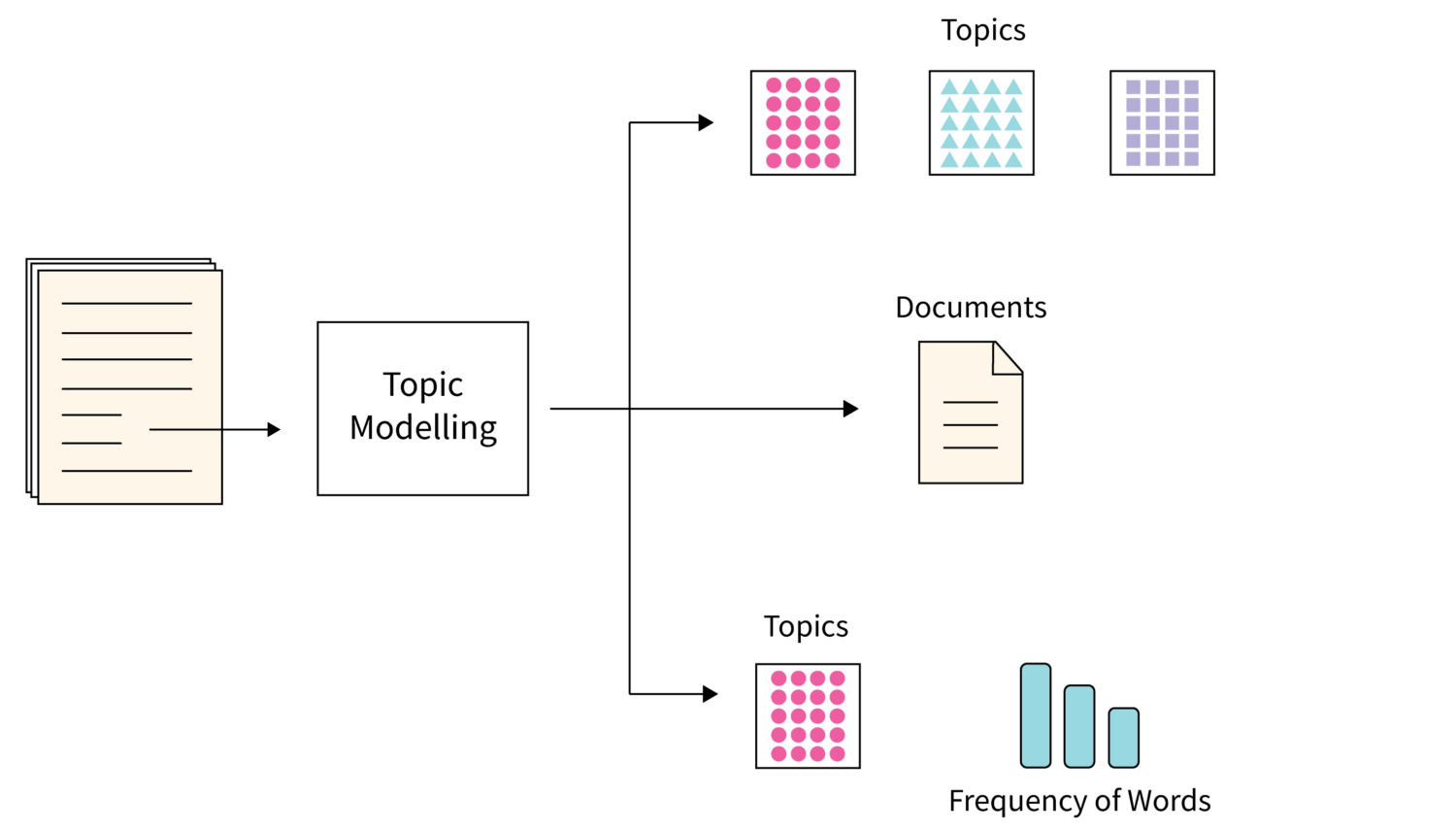
Basically, it helps machines to find the topic that can be used to define a particular set of texts. Since each corpus of text documents contains many topics, this algorithm uses any suitable technique to find each topic by evaluating particular sets of word vocabulary.
L’allocation de Dirichlet latent est un choix populaire lorsqu’il s’agit d’utiliser la meilleure technique pour la modélisation des sujets. Il s’agit d’un algorithme de ML non supervisé qui permet d’accumuler et d’organiser les archives d’une grande quantité de données, ce qui n’est pas possible par l’annotation humaine.
#2. Résumés de texte
Il s’agit d’une technique NLP très exigeante dans laquelle l’algorithme résume un texte brièvement et de manière fluide. Il s’agit d’un processus rapide, car le résumé permet d’extraire toutes les informations utiles sans avoir à parcourir chaque mot.
Le résumé peut être effectué de deux manières :
- Le résumé basé sur l’extraction : La machine n’extrait que les mots et phrases principaux du document sans modifier l’original.
- Le résumé par abstraction : Dans ce processus, de nouveaux mots et phrases sont créés à partir du document texte, qui décrit toutes les informations et l’intention.
#3. Analyse sentimentale
Il s’agit d’un algorithme NLP qui aide une machine à comprendre le sens ou l’intention d’un texte de l’utilisateur. Il est très populaire et utilisé dans différents modèles d’IA d’entreprises parce qu’il aide les entreprises à comprendre ce que les clients pensent de leurs produits ou services.
En comprenant l’intention du texte ou des données vocales d’un client sur différentes plateformes, les modèles d’IA peuvent vous renseigner sur les sentiments d’un client et vous aider à l’approcher en conséquence.
#4. Extraction de mots-clés
L’extraction de mots-clés est un autre algorithme NLP populaire qui permet d’extraire un grand nombre de mots et de phrases ciblés à partir d’un vaste ensemble de données textuelles.
Il existe différents algorithmes d’extraction de mots-clés, dont les noms les plus connus sont TextRank, Term Frequency et RAKE. Certains de ces algorithmes peuvent utiliser des mots supplémentaires, tandis que d’autres peuvent aider à extraire des mots-clés sur la base du contenu d’un texte donné.
Chacun des algorithmes d’extraction de mots-clés utilise ses propres méthodes théoriques et fondamentales. L’extraction de mots-clés est utile à de nombreuses organisations car elle permet de stocker, de rechercher et d’extraire du contenu à partir d’un ensemble substantiel de données non structurées.
#5. Graphes de connaissances
Lorsqu’il s’agit de choisir le meilleur algorithme de NLP, beaucoup considèrent les algorithmes de graphes de connaissances. Il s’agit d’une excellente technique qui utilise des triples pour stocker des informations.
Cet algorithme est essentiellement un mélange de trois éléments – sujet, prédicat et entité. Cependant, la création d’un graphe de connaissances n’est pas limitée à une seule technique ; au contraire, elle nécessite plusieurs techniques de NLP pour être plus efficace et plus détaillée. L’approche par sujet est utilisée pour extraire des informations ordonnées à partir d’un amas de textes non structurés.
#6. TF-IDF
TF-IDF est un algorithme statistique de NLP qui permet d’évaluer l’importance d’un mot dans un document particulier appartenant à une collection massive. Cette technique implique la multiplication de valeurs distinctes, qui sont :
- La fréquence des termes : La valeur de la fréquence des termes vous donne le nombre total de fois qu’un mot apparaît dans un document particulier. Les mots vides ont généralement une fréquence élevée dans un document.
- Fréquence inverse du document : La fréquence inverse des documents, quant à elle, met en évidence les termes qui sont très spécifiques à un document ou les mots qui apparaissent moins souvent dans un corpus entier de documents.
#7. Words Cloud
Words Cloud est un algorithme NLP unique qui fait appel à des techniques de visualisation des données. Dans cet algorithme, les mots importants sont mis en évidence, puis affichés dans un tableau.
Les mots essentiels du document sont imprimés en gros caractères, tandis que les mots les moins importants sont affichés en petits caractères. Parfois, les éléments les moins importants ne sont même pas visibles dans le tableau.
Ressources pédagogiques
Outre les informations ci-dessus, si vous souhaitez en savoir plus sur le traitement du langage naturel (NLP), vous pouvez envisager les cours et les livres suivants.
#1. Science des données : Traitement du langage naturel en Python (Traitement du langage naturel en Python)
This Udemy course is highly rated by learners and meticulously created by Lazy Programmer Inc. It teaches everything about NLP and NLP algorithms and teaches you how to write sentiment analysis.
With a total duration of 11 hours and 52 minutes, this course gives you access to 88 lectures.
#2. Traitement du langage naturel : NLP avec des transformateurs en Python (Traitement du langage naturel avec des transformateurs en Python)
With this popular Udemy course, you will not only learn Natural Language Processing with Transformer models, but you will also have the ability to create fine-tuned Transformer models.
This course gives you comprehensive coverage of NLP with its 11.5 hours of on-demand video and 5 articles. Additionally, you will learn vector construction techniques and text data preprocessing for NLP.
#3. Traitement du langage naturel avec les transformateurs
Ce livre a été publié pour la première fois en 2017 et visait à aider les scientifiques des données et les codeurs à se familiariser avec le NLP.
| Preview | Product | Rating | |
|---|---|---|---|

|
Natural Language Processing with Transformers, Revised Edition | Buy on Amazon |
Une fois que vous commencez à lire le livre, vous obtiendrez de construire et d’optimiser les modèles de transformateurs pour de nombreuses tâches NLP. Vous saurez également comment utiliser les transformateurs pour l’apprentissage par transfert interlinguistique.
#4. Traitement pratique du langage naturel
Dans ce livre, les auteurs expliquent les tâches, les problèmes et les approches de solution pour le traitement du langage naturel.
| Preview | Product | Rating | |
|---|---|---|---|

|
Practical Natural Language Processing: A Comprehensive Guide to Building Real-World Nlp Systems | Buy on Amazon |
Ce livre enseigne également la mise en œuvre et l’évaluation de différentes applications du TAL.
Conclusion
Le NLP fait partie intégrante du monde moderne de l’IA qui aide les machines à comprendre les langues humaines et à les interpréter.
Les algorithmes de PNL sont utiles pour diverses applications, des moteurs de recherche aux technologies de l’information, en passant par la finance et le marketing.