
Sowohl Container als auch serverlose Bereitstellungs- und Entwicklungsmodelle sind Teil der Kultur einer skalierbaren Architektur, die je nach Nutzung der Anwendung verfügbar ist. Das macht es schwer, sich zwischen beiden zu entscheiden, und genau das werden wir in diesem Beitrag besprechen.
Was sind Container?

Container bieten nicht nur die Möglichkeit, einige Einschränkungen der traditionellen Virtualisierung zu überwinden, sondern legen auch den Grundstein für einen radikalen Wandel in der Art und Weise, wie die Entwicklung und der Lebenszyklus von Diensten verstanden werden.
Die Idee hinter Containern stammt nicht aus der Linux-Welt, sondern hat ihre Wurzeln in einer Technologie, die als FreeBSD jail bekannt ist und im Jahr 2000 erschien. Sie ermöglicht die Partitionierung eines FreeBSD-Systems in Subsysteme (jail), die sowohl voneinander als auch vom zugrunde liegenden System isoliert sind, indem sie das Konzept von chroot erweitern.
Dies wurde mit dem Linux Vserver-Projekt in die Linux-Welt gebracht und in den folgenden Jahren mit neuen Technologien wie cgroup, systemd und Linux Kernel Namespace integriert, wodurch das Linux Container (LXC) Projekt entstand.
Im Jahr 2008 kamen mit Docker neue Tools und neue Ideen hinzu, wie z.B. die Möglichkeit, geschichtete Images zu erstellen (d.h. aus der Zusammenführung mehrerer Images) und die Einführung der Image-Registry. Container-Projekte in der Linux-Welt haben daher einen neuen Schub erhalten, der zur Geburt der Open Container Initiative führte, deren Mitglieder, darunter Docker und Red Hat, gemeinsam offene und gemeinsame Standards für Container-Technologien definieren.
Unter diesen Voraussetzungen und mit diesen Tools ist es nur natürlich, dass wir uns fragen, ob es Alternativen zur traditionellen Virtualisierung gibt.
Abgesehen von den rein technischen Aspekten ist ein Linux-Container ein Satz von einem oder mehreren Prozessen, die vom Rest des Systems isoliert sind:
- Über eine Standardverwaltungsschnittstelle verfügen (zum Starten, Stoppen, für Umgebungsvariablen)
- Die Nutzung von Ressourcen in Bezug auf virtuelle Maschinen optimieren
- Die Verwaltung größerer Anwendungen (verteilt auf mehrere Container) vereinfachen
Das Vorhandensein von Standards, die von Standardisierungsgremien vorgeschlagen wurden, garantiert außerdem Interoperabilität und die Möglichkeit, Container auch zwischen verschiedenen Clouds zu orchestrieren.
Das Konzept der Images und die Art und Weise, wie sie konstruiert und aggregiert werden, stellt den wichtigsten und innovativsten Aspekt dar, nicht so sehr aus technologischer Sicht, sondern wegen der Auswirkungen auf die Entwicklung und das Betriebsmanagement, mit Konsequenzen, die auch die Art und Weise, wie Unternehmen verstanden werden, betreffen.
Die Images sind unveränderlich, d.h. jeder Container, der von demselben Image ausgeführt wird, ist identisch mit den anderen, er enthält keine Statusinformationen oder persistente Daten. Die Persistenz wird anderen Tools wie externen Datenbanken und Dateisystemen anvertraut. Damit wird vor allem eine klare Trennung zwischen der Laufzeitumgebung der Anwendung und den Daten, auf denen sie arbeitet, festgelegt und eine funktionale Trennungslogik eingeführt, die Vorteile bei der Bereinigung, der Prozessverwaltung und der Sicherheit bringt.
Die wirkliche Innovation im Entwicklungsprozess und im Lebenszyklus der Anwendung liegt darin, dass sie, sobald eine vollständige und konsistente Betriebsumgebung auf einem oder mehreren Images erstellt wurde, die von den Daten, auf denen sie arbeitet, getrennt ist, alle Phasen von der Entwicklung bis zur Produktion ohne Änderungen durchlaufen kann.
Was ist Serverless?
Container ermöglichen zwar eine bessere Ressourcenzuweisung als virtuelle Maschinen, aber sie erlauben es nicht wirklich, auf Null zu skalieren und linear zu wachsen: Wenn ein Container keine Dienste liefert, bleibt er dennoch als Prozess aktiv. Eine Antwort auf diesen Bedarf können serverlose Ansätze sein.
Eine wirklich effiziente Ressourcenzuweisung setzt voraus, dass die gesamte Rechenleistung tatsächlich nur bei Bedarf instanziiert und unmittelbar nach der Nutzung wieder freigegeben wird.
Die ersten Schritte in diese Richtung wurden von Google mit der Einführung der Google App Engine im Jahr 2008 unternommen, aber der wirkliche Anstoß kam mit der Einführung von AWS Lambda durch Amazon im Jahr 2014, dem ersten echten FaaS-Modell. In der Folge kamen alternative Lösungen anderer Anbieter hinzu: Microsoft mit Azure Functions, IBM und Google mit ihren eigenen Cloud Functions. Auch die Open-Source-Welt hat sich mit der Veröffentlichung von Produkten wie Apache OpenWhisk, OpenLambda und IronFunctions in diese Richtung bewegt.

- Quelle: epsagon.com
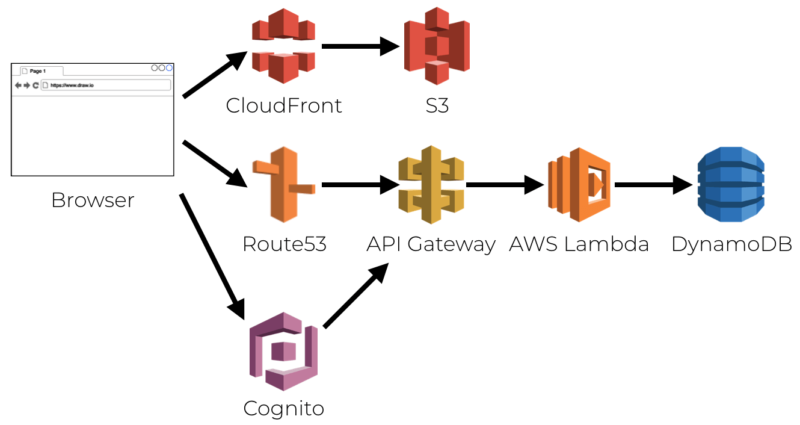
Serverless Computing ist eine der Möglichkeiten zur Verteilung von Diensten in einem Cloud-Kontext, bei der Anwendungen oder besser gesagt Funktionen ausgeführt werden, ohne dass die zugrunde liegende Infrastruktur sichtbar sein muss: Bereitstellung, Skalierung und Verwaltung erfolgen automatisch und linear nur angesichts der tatsächlichen Anfragen und Bedürfnisse. Der Begriff serverlos ist also nicht als “Abwesenheit” von Servern zu verstehen, sondern als Transparenz der beteiligten Systeme aus der Sicht der Entwickler und Benutzer.
Diese Eigenschaft bedeutet, dass das DevOps-Paradigma, das für den Einsatz von containerisierten Technologien typisch ist, aufgegeben wird, um zu einer neuen, klareren Unterscheidung zwischen der Infrastruktur- und der Anwendungskomponente zurückzukehren, wodurch zwei neue Konzepte in der Cloud-Welt eingeführt werden:
- FaaS (Function as a Service) ermöglicht es Entwicklern, eine Ausführungsumgebung für ihre Anwendungen (sei es C #, Java, Node.js, Python usw.) zu haben, die nur als Reaktion auf bestimmte Ereignisse instanziiert wird.
- BaaS (Backend as a Service) ermöglicht es, die typischen Funktionen der Anwendungen an Dritte zu delegieren, ohne sie selbst implementieren zu müssen (z.B. im Fall von Diensten wie Auth0, der Identitätsmanagement- und Authentifizierungsfunktionen bietet).
Es gibt viele Serverless-Frameworks auf dem Markt.
Der Hauptunterschied zwischen Serverless und Containern

Container sind sehr wichtig für den Aufschwung, den die Serverless-Architektur im Laufe der Zeit genommen hat, vor allem für die Einbeziehung von Konzepten und der Kultur, nicht mehr die alten virtuellen Maschinen und klassischen Server zu verwenden. Alles kann lokal oder in der Cloud gehostet werden, ohne Komplikationen oder Komplexität.
Der große Unterschied zwischen einer Serverless-Architektur mit FaaS und Containern besteht darin, dass man sich nicht um die Prozesse kümmert, die auf der Ebene des Betriebssystems ablaufen. Auch wenn Dienste wie Docker ähnliche Abstraktionsmöglichkeiten wie die Container-Technologie bieten, insbesondere wenn sie in Verbindung mit Kubernetes verwendet werden, ermöglichen die Serverless-Architektur und FaaS ein noch größeres Maß an Abstraktion bei der Anwendungsentwicklung.
In einer Serverless-Architektur, die FaaS verwendet, wird die Skalierbarkeit der Anwendung automatisch und transparent verwaltet und sie verfügt außerdem über die Fähigkeit einer hohen Granularität des Dienstes für seine beste Leistung. Bei Plattformen, die Container verwenden, muss diese Bereitstellung manuell verwaltet werden, selbst mit automatisierten Tools.
Letztendlich bestimmen der Stil der Anwendung und die verfügbare Infrastruktur, welche der beiden Bereitstellungsformen am besten geeignet ist. Die Serverless-Architektur verfügt über ein hohes Maß an Abstraktion bei der Verarbeitung durch das Betriebssystem, während sich Container weiterentwickeln und Möglichkeiten zur Automatisierung von Skalierbarkeit und Verfügbarkeit entwickeln.
Wie wählt man zwischen Serverless und Containern?
In diesem Überblick haben wir versucht zu verdeutlichen, wie radikal der Wandel ist, der die Welt der IT-Dienste in den letzten Jahren erschüttert und Infrastrukturen, Entwicklungsmodelle und sogar Geschäftsmodelle neu definiert hat.
Was jedoch wie ein evolutionärer Prozess aussieht, bei dem neue Technologien die bisherigen ersetzen, ist in Wirklichkeit ein viel weniger linearer Weg: Es gibt Szenarien, in denen jede der drei Technologien als einzige anwendbar ist, andere, in denen sie integriert werden müssen, und jede wird ihren eigenen Platz finden.
Nicht alle Workloads sind in Containern portabel: In einigen Fällen wäre es notwendig, die Anwendung neu zu entwerfen und zu schreiben. Es ist nicht sicher, dass dies immer möglich ist. Es gibt also immer noch Situationen, in denen virtuelle Maschinen eine Systemkontrolle oder Flexibilität ermöglichen, die sie unverzichtbar machen.
Container und serverlose Anwendungsfälle
Container finden ihren idealen Einsatz in komplexen Anwendungen, die ein hohes Maß an Kontrolle über die Betriebsumgebung erfordern, möglicherweise mit langen Verarbeitungszeiten und die sich gleichzeitig für die Implementierung in einer containerisierten Umgebung eignen.
Auch wenn die Ressourcennutzung weniger effizient ist als bei einem serverlosen Ansatz, ist die Leistung im Durchschnitt besser, da zumindest der erste Container immer aktiv ist und nicht von Grund auf neu instanziert werden muss.
Design, Entwicklung und Verwaltung können einfacher sein, da das Vorhandensein gemeinsamer Frameworks und Standards die Orchestrierung zwischen Clouds verschiedener Anbieter ermöglicht und die Skalierung viel einfacher ist als bei virtuellen Servern.
Umgekehrt erfordern Änderungen an einzelnen Funktionen in Containern die Erstellung und Bereitstellung eines neuen Images, wodurch sich die Freigabezeiten verlängern und die Möglichkeit von Fehlern besteht. Das Wachstum der Anzahl der Instanzen als Reaktion auf die steigende Last führt zu Schwierigkeiten bei der Überwachung und möglichen Leistungsproblemen, da die Wachstumskapazität immer durch die Geschwindigkeit der Komponenten begrenzt ist, die die Datenpersistenz gewährleisten.
Ein typisches Anwendungsbeispiel kann eine große E-Commerce-Website sein, die aus zahlreichen Teilen wie der Preisliste, der Lagerverwaltung und den Zahlungen besteht, die jeweils in einen Container verpackt werden können, für den Ausführungszeiten und Speichergrenzen kein Problem darstellen.
Der serverlose Ansatz ist ideal im Kontext von Microservices und in Szenarien wie dem IoT, in denen bestimmte Funktionen nur bei bestimmten Ereignissen aufgerufen werden müssen und nicht Teil eines ständig aktiven Dienstes sein dürfen.
Da es sich um ein reines Pay-per-Use-Modell handelt, ermöglicht es eine Kostenoptimierung, vor allem in Fällen, in denen es schwierig ist, die Dimensionierung a priori vorzunehmen oder die zu bewältigende Last vorherzusagen.
Die Schwierigkeit bei der Entwicklung und das Fehlen von Standards, die in vielen Fällen das Problem der Herstellerabhängigkeit verursachen, stellen nach wie vor eine starke Einschränkung des Einsatzbereichs dar.
Letzte Worte
Zusammenfassend lässt sich sagen, dass keine Technologie in einem absoluten Sinne besser ist als die andere: jede erfüllt spezifische Bedürfnisse. Sie können nebeneinander bestehen und je nach Bedarf in ein einziges Projekt integriert werden. Der beste Ansatz ist daher, sich nicht von vornherein auf einen bestimmten Weg für die Entwicklung Ihrer Anwendungen festzulegen, sondern mit einer sorgfältigen Analyse der Merkmale und Anforderungen zu beginnen, um die am besten geeignete Architektur zu wählen.