
MapReduce ofrece una forma eficaz, rápida y rentable de crear aplicaciones.
Este modelo utiliza conceptos avanzados como el procesamiento en paralelo, la localidad de los datos, etc., para proporcionar muchas ventajas a programadores y organizaciones.
Pero hay tantos modelos y marcos de programación disponibles en el mercado que resulta difícil elegir.
Y cuando se trata de Big Data, no se puede elegir cualquier cosa. Debe elegir aquellas tecnologías que puedan manejar grandes volúmenes de datos.
MapReduce es una gran solución para ello.
En este artículo, hablaré de lo que es realmente MapReduce y de cómo puede ser beneficioso.
Empecemos
¿Qué es MapReduce?
MapReduce es un modelo de programación o marco de software dentro del marco Apache Hadoop. Se utiliza para crear aplicaciones capaces de procesar datos masivos en paralelo en miles de nodos (llamados clusters o grids) con tolerancia a fallos y fiabilidad.
Este procesamiento de datos se realiza sobre una base de datos o un sistema de archivos donde se almacenan los datos. MapReduce puede trabajar con un sistema de archivos Hadoop (HDFS) para acceder y gestionar grandes volúmenes de datos.
Este marco fue introducido en 2004 por Google y popularizado por Apache Hadoop. Es una capa o motor de procesamiento en Hadoop que ejecuta programas MapReduce desarrollados en diferentes lenguajes, incluyendo Java, C , Python y Ruby.
Los programas MapReduce en la computación en nube se ejecutan en paralelo, por lo que son adecuados para realizar análisis de datos a gran escala.

MapReduce tiene como objetivo dividir una tarea en múltiples tareas más pequeñas utilizando las funciones «map» y «reduce». Mapeará cada tarea y luego la reducirá a varias tareas equivalentes, lo que se traduce en una menor potencia de procesamiento y sobrecarga en la red del clúster.
Ejemplo: Suponga que está preparando una comida para una casa llena de invitados. Si intenta preparar todos los platos y realizar todos los procesos usted mismo, se convertirá en una tarea ajetreada que le llevará mucho tiempo.
Pero suponga que implica a algunos de sus amigos o colegas (no invitados) para que le ayuden a preparar la comida distribuyendo los diferentes procesos a otra persona que pueda realizar las tareas simultáneamente. En ese caso, preparará la comida mucho más rápida y fácilmente mientras sus invitados siguen en casa.
MapReduce funciona de forma similar con tareas distribuidas y procesamiento paralelo para permitir una forma más rápida y sencilla de completar una tarea determinada.
Apache Hadoop permite a los programadores utilizar MapReduce para ejecutar modelos en grandes conjuntos de datos distribuidos y utilizar técnicas avanzadas de aprendizaje automático y estadísticas para encontrar patrones, hacer predicciones, detectar correlaciones y mucho más.
Características de MapReduce
Algunas de las principales características de MapReduce son:
- Interfaz de usuario: Dispondrá de una interfaz de usuario intuitiva que proporciona detalles razonables sobre cada aspecto del marco de trabajo. Le ayudará a configurar, aplicar y ajustar sus tareas sin problemas.

- Carga útil: Las aplicaciones utilizan las interfaces Mapper y Reducer para habilitar las funciones de mapeo y reducción. El Mapeador mapea pares clave-valor de entrada a pares clave-valor intermedios. Reducer se utiliza para reducir pares clave-valor intermedios que comparten una clave a otros valores más pequeños. Realiza tres funciones: ordenar, barajar y reducir.
- Particionador: Controla la división de las claves intermedias mapa-valor.
- Reportero: Es una función para informar del progreso, actualizar Contadores y establecer mensajes de estado.
- Contadores: Representa los contadores globales que define una aplicación MapReduce.
- OutputCollector: Esta función recoge los datos de salida del Mapeador o Reductor en lugar de las salidas intermedias.
- RecordWriter: Escribe los datos de salida o pares clave-valor en el archivo de salida.
- DistributedCache: Distribuye eficazmente los archivos de mayor tamaño y de sólo lectura que son específicos de la aplicación.
- Compresión de datos: El escritor de la aplicación puede comprimir tanto las salidas de los trabajos como las salidas intermedias de los mapas.
- Omisión de registros erróneos: Puede omitir varios registros erróneos mientras procesa las entradas del mapa. Esta característica puede controlarse a través de la clase – SkipBadRecords.
- Depuración: Tendrá la opción de ejecutar scripts definidos por el usuario y habilitar la depuración. Si una tarea en MapReduce falla, puede ejecutar su script de depuración y encontrar los problemas.
Arquitectura de MapReduce
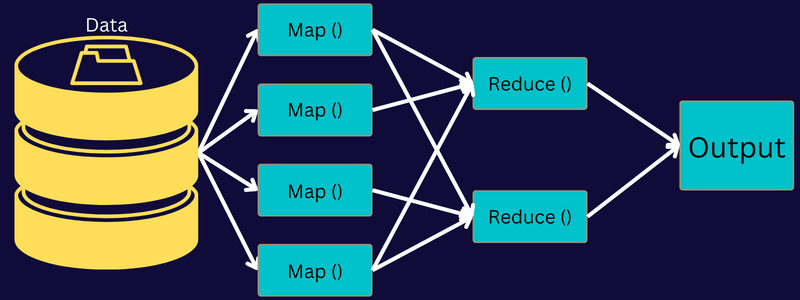
Comprendamos la arquitectura de MapReduce profundizando en sus componentes:
- Job: Un trabajo en MapReduce es la tarea real que el cliente MapReduce quiere realizar. Se compone de varias tareas más pequeñas que se combinan para formar la tarea final.
- Servidor de historial de trabajos: Es un proceso demonio para almacenar y guardar todos los datos históricos sobre una aplicación o tarea, como los registros generados después o antes de ejecutar un trabajo.
- Cliente: Un cliente (programa o API) lleva un trabajo a MapReduce para su ejecución o procesamiento. En MapReduce, uno o varios clientes pueden enviar continuamente trabajos al gestor de MapReduce para su procesamiento.
- Maestro MapReduce: Un MapReduce Master divide un trabajo en varias partes más pequeñas, asegurando que las tareas progresan simultáneamente.
- Partes de trabajo: Los subtrabajos o partes de trabajo se obtienen dividiendo el trabajo primario. Se trabaja sobre ellos y se combinan al final para crear la tarea final.
- Datos de entrada: Es el conjunto de datos alimentado a MapReduce para el procesamiento de la tarea.
- Datos de salida: Es el resultado final obtenido una vez procesada la tarea.
Así pues, lo que realmente ocurre en esta arquitectura es que el cliente envía un trabajo al maestro de MapReduce, que lo divide en partes más pequeñas e iguales. Esto permite que el trabajo se procese más rápidamente, ya que las tareas más pequeñas tardan menos tiempo en procesarse que las tareas más grandes.
Sin embargo, asegúrese de que las tareas no se dividen en partes demasiado pequeñas porque, si lo hace, puede tener que enfrentarse a una mayor sobrecarga de gestión de las divisiones y perder un tiempo considerable en ello.
A continuación, las partes del trabajo se ponen a disposición para proceder con las tareas Map y Reduce. Además, las tareas Map y Reduce tienen un programa adecuado basado en el caso de uso en el que está trabajando el equipo. El programador desarrolla el código basado en la lógica para cumplir los requisitos.
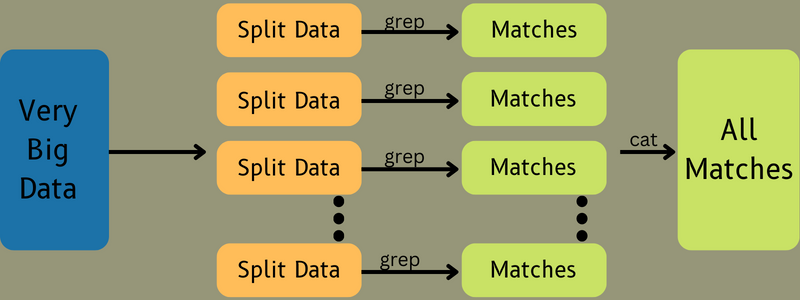
Después, los datos de entrada se introducen en la tarea Map para que ésta pueda generar rápidamente la salida como un par clave-valor. En lugar de almacenar estos datos en HDFS, se utiliza un disco local para almacenar los datos con el fin de eliminar la posibilidad de replicación.
Una vez completada la tarea, se puede desechar la salida. Por lo tanto, la replicación se convertirá en un exceso si almacena la salida en HDFS. La salida de cada tarea de mapa se alimentará a la tarea de reducción, y la salida del mapa se proporcionará a la máquina que ejecuta la tarea de reducción.
A continuación, la salida se fusionará y se pasará a la función de reducción definida por el usuario. Por último, la salida reducida se almacenará en un HDFS.
Además, el proceso puede tener varias tareas Map y Reduce para el procesamiento de datos en función del objetivo final. Los algoritmos Map y Reduce se optimizan para mantener al mínimo la complejidad temporal o espacial.
Dado que MapReduce implica principalmente tareas Map y Reduce, es pertinente entender más sobre ellas. Por lo tanto, vamos a discutir las fases de MapReduce para tener una idea clara de estos temas.
Fases de MapReduce
Mapear
Los datos de entrada se mapean en la salida o pares clave-valor en esta fase. Aquí, la clave puede referirse al id de una dirección mientras que el valor puede ser el valor real de esa dirección.
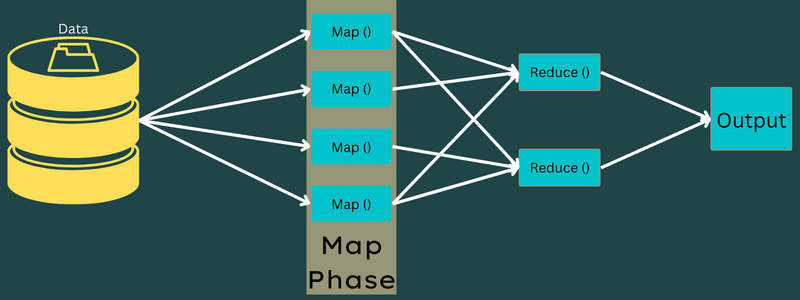
Sólo hay una pero dos tareas en esta fase – divisiones, y mapeo. Splits significa las subpartes o partes del trabajo divididas del trabajo principal. También se denominan divisiones de entrada. Así, una división de entrada puede denominarse un trozo de entrada consumido por un mapa.
A continuación, tiene lugar la tarea de mapeo. Se considera la primera fase mientras se ejecuta un programa map-reduce. Aquí, los datos contenidos en cada split se pasarán a una función map para que los procese y genere la salida.
La función – Map() se ejecuta en el repositorio de memoria sobre los pares clave-valor de entrada, generando un par clave-valor intermedio. Este nuevo par clave-valor funcionará como la entrada que se pasará a la función Reduce() o Reducer.
Reducir
Los pares clave-valor intermedios obtenidos en la fase de mapeo funcionan como entrada para la función Reduce o Reducer. Al igual que en la fase de mapeo, intervienen dos tareas: barajar y reducir.
Así, los pares clave-valor obtenidos se ordenan y barajan para pasar al Reductor. A continuación, el Reductor agrupa o agrega los datos según su par clave-valor basándose en el algoritmo reductor que haya escrito el desarrollador.
Aquí, los valores de la fase de barajado se combinan para devolver un valor de salida. Esta fase suma todo el conjunto de datos.
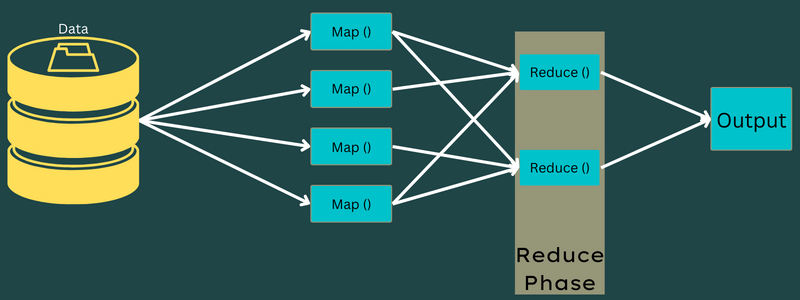
Ahora, el proceso completo de ejecución de las tareas Map y Reduce está controlado por algunas entidades. Éstas son
- Rastreador de trabajos: En palabras sencillas, un rastreador de trabajos actúa como un maestro que se encarga de ejecutar completamente un trabajo enviado. El rastreador de trabajos gestiona todos los trabajos y recursos de un cluster. Además, el rastreador de trabajos programa cada mapa añadido en el rastreador de tareas que se ejecuta en un nodo de datos específico.
- Rastreadores de tareas múltiples: En palabras sencillas, los rastreadores de tareas múltiples funcionan como esclavos que realizan la tarea siguiendo las instrucciones del rastreador de tareas. Un rastreador de tareas se despliega en cada nodo por separado en el cluster ejecutando las tareas Map y Reduce.
Funciona porque un trabajo se dividirá en varias tareas que se ejecutarán en diferentes nodos de datos de un cluster. El rastreador de tareas se encarga de coordinar la tarea programando las tareas y ejecutándolas en varios nodos de datos. A continuación, el Rastreador de Tareas situado en cada nodo de datos ejecuta partes del trabajo y se ocupa de cada tarea.
Además, los Rastreadores de Tareas envían informes de progreso al rastreador del trabajo. Asimismo, el Rastreador de Tareas envía periódicamente una señal de «latido» al Rastreador de Trabajos y le notifica el estado del sistema. En caso de fallo, un rastreador de tareas es capaz de reprogramar el trabajo en otro rastreador de tareas.
Fase de salida: Cuando llegue a esta fase, tendrá los pares clave-valor finales generados desde el Reductor. Puede utilizar un formateador de salida para traducir los pares clave-valor y escribirlos en un archivo con la ayuda de un escritor de registros.
¿Por qué utilizar MapReduce?
He aquí algunas de las ventajas de MapReduce, que explican las razones por las que debe utilizarlo en sus aplicaciones de big data:
Procesamiento paralelo
Puede dividir un trabajo en diferentes nodos en los que cada nodo gestiona simultáneamente una parte de este trabajo en MapReduce. Así, dividir tareas más grandes en otras más pequeñas disminuye la complejidad. Además, como las distintas tareas se ejecutan en paralelo en diferentes máquinas en lugar de en una sola, se tarda mucho menos tiempo en procesar los datos.
Localidad de los datos
En MapReduce, puede trasladar la unidad de procesamiento a los datos, y no al revés.
De forma tradicional, los datos se llevaban a la unidad de procesamiento para ser procesados. Sin embargo, con el rápido crecimiento de los datos, este proceso empezó a plantear muchos retos. Algunos de ellos eran el mayor coste, la mayor pérdida de tiempo, la sobrecarga del nodo maestro, los fallos frecuentes y el menor rendimiento de la red.
Pero MapReduce ayuda a superar estos problemas siguiendo un enfoque inverso: acercando una unidad de procesamiento a los datos. De este modo, los datos se distribuyen entre diferentes nodos en los que cada nodo puede procesar una parte de los datos almacenados.
Como resultado, ofrece rentabilidad y reduce el tiempo de procesamiento, ya que cada nodo trabaja en paralelo con su parte de datos correspondiente. Además, como cada nodo procesa una parte de estos datos, ningún nodo estará sobrecargado.
Seguridad

El modelo MapReduce ofrece una mayor seguridad. Ayuda a proteger su aplicación de datos no autorizados al tiempo que mejora la seguridad del clúster.
Escalabilidad y flexibilidad
MapReduce es un marco altamente escalable. Permite ejecutar aplicaciones desde varias máquinas, utilizando datos con miles de terabytes. También ofrece la flexibilidad de procesar datos que pueden ser estructurados, semiestructurados o no estructurados y de cualquier formato o tamaño.
Simplicidad
Puede escribir programas MapReduce en cualquier lenguaje de programación como Java, R, Perl, Python, etc. Por lo tanto, es fácil para cualquiera aprender y escribir programas a la vez que se asegura de que se cumplen sus requisitos de procesamiento de datos.
Casos de uso de MapReduce
- Indexación de texto completo: MapReduce se utiliza para realizar la indexación de texto completo. Su Mapeador puede mapear cada palabra o frase de un documento. Y el Reductor se utiliza para escribir todos los elementos mapeados en un índice.
- Cálculo del Pagerank: Google utiliza MapReduce para calcular el Pagerank.
- Análisis de registros: MapReduce puede analizar archivos de registro. Puede dividir un archivo de registro grande en varias partes o splits mientras el mapeador busca las páginas web a las que se ha accedido.
Se enviará un par clave-valor al reductor si se detecta una página web en el registro. Aquí, la página web será la clave, y el índice «1» es el valor. Tras dar un par clave-valor al reductor, se agregarán varias páginas web. El resultado final es el número total de visitas de cada página web.

- Gráfico de enlaces web inversos: El marco también encuentra uso en Reverse Web-Link Graph. Aquí, Map() obtiene la URL objetivo y la fuente y toma la entrada de la fuente o página web.
A continuación, Reduce() agrega la lista de cada URL fuente asociada a la URL objetivo. Por último, da salida a las fuentes y al objetivo.
- Recuento de palabras: MapReduce se utiliza para contar cuántas veces aparece una palabra en un documento determinado.
- Calentamiento global: Organizaciones, gobiernos y empresas pueden utilizar MapReduce para resolver problemas de calentamiento global.
Por ejemplo, usted puede querer conocer el aumento del nivel de temperatura del océano debido al calentamiento global. Para ello, puede reunir miles de datos en todo el planeta. Los datos pueden ser la temperatura alta, la temperatura baja, la latitud, la longitud, la fecha, la hora, etc. Esto requerirá varios mapas y tareas de reducción para calcular la salida utilizando MapReduce.
- Ensayos de fármacos: Tradicionalmente, los científicos de datos y los matemáticos trabajaban juntos para formular un nuevo fármaco que pueda combatir una enfermedad. Con la difusión de los algoritmos y MapReduce, los departamentos informáticos de las organizaciones pueden abordar fácilmente cuestiones que sólo estaban en manos de superordenadores, científicos con doctorado, etc. Ahora, se puede inspeccionar la eficacia de un fármaco para un grupo de pacientes.
- Otras aplicaciones: MapReduce puede procesar incluso datos a gran escala que de otro modo no cabrían en una base de datos relacional. También utiliza herramientas de ciencia de datos y permite ejecutarlas sobre conjuntos de datos diferentes y distribuidos, lo que antes sólo era posible en un único ordenador.
Gracias a la robustez y sencillez de MapReduce, encuentra aplicaciones en el ámbito militar, empresarial, científico, etc.
Conclusión
MapReduce puede resultar un gran avance tecnológico. No sólo es un proceso más rápido y sencillo, sino también rentable y requiere menos tiempo. Dadas sus ventajas y su creciente uso, es probable que sea testigo de una mayor adopción en todas las industrias y organizaciones.