
Construire un modèle d’apprentissage automatique est relativement facile. Créer des centaines ou des milliers de modèles et itérer sur les modèles existants est difficile.
Il est facile de se perdre dans le chaos. Ce chaos s’aggrave lorsque vous travaillez en équipe, car vous devez alors suivre ce que chacun fait. Pour mettre de l’ordre dans le chaos, il faut que toute l’équipe suive un processus et documente ses activités. C’est l’essence même de MLOps.
Qu’est-ce que le MLOps ?
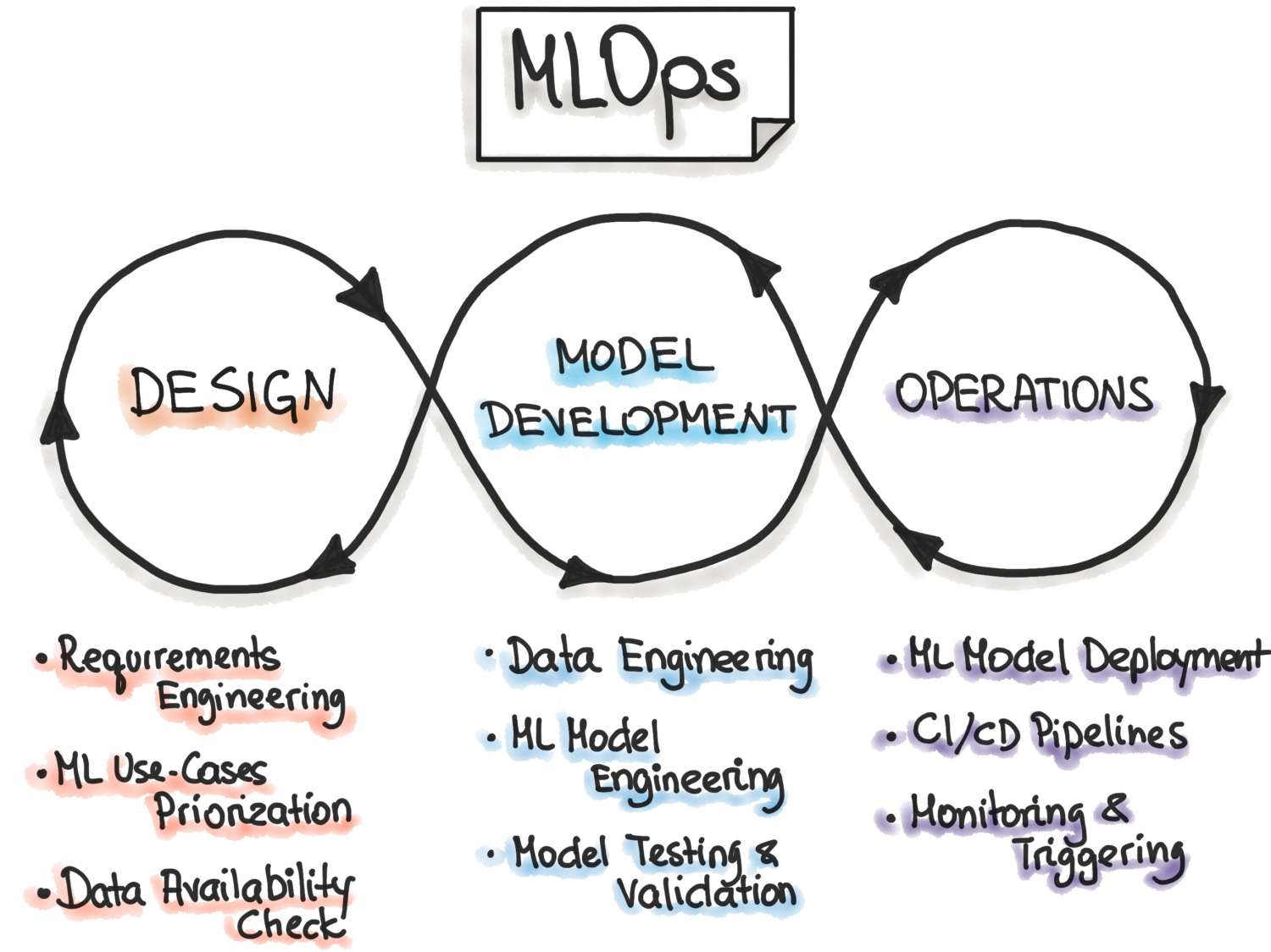
Selon MLOps.org, l’opérationnalisation de l’apprentissage automatique (Machine Learning Operationalisation) vise à mettre en place un processus de développement de l’apprentissage automatique de bout en bout afin de concevoir, construire et gérer des logiciels reproductibles, testables et évolutifs alimentés par l’apprentissage automatique. Essentiellement, MLOps est l’application des principes DevOps au Machine Learning.
Comme DevOps, l’idée clé de MLOps est l’automatisation afin de réduire les étapes manuelles et d’augmenter l’efficacité. De même, comme DevOps, MLOps comprend à la fois l’intégration continue (CI) et la livraison continue (CD). En plus de ces deux éléments, il comprend également la formation continue (CT). L’aspect supplémentaire de l’entraînement continu consiste à reformer les modèles avec de nouvelles données et à les redéployer.
MLOps est donc une culture d’ingénierie qui promeut une approche méthodique du développement de modèles d’apprentissage automatique et l’automatisation des différentes étapes de la méthode. Le processus comprend principalement l’extraction, l’analyse et la préparation des données, l’entraînement des modèles, l’évaluation, la mise à disposition des modèles et le suivi.
Avantages des MLOps
En général, les avantages de l’application des principes MLOps sont les mêmes que ceux des procédures opérationnelles standard. Ces avantages sont les suivants :
- Un processus bien défini fournit une feuille de route de toutes les étapes cruciales du développement d’un modèle. Cela permet de s’assurer qu’aucune étape critique n’est oubliée.
- Les étapes du processus qui peuvent être automatisées peuvent être identifiées et automatisées. Cela réduit la quantité de travail répétitif et augmente la vitesse de développement. Cela permet également d’éliminer les erreurs humaines tout en réduisant la quantité de travail à effectuer.
- Il devient plus facile d’évaluer l’avancement du développement d’un modèle en sachant à quelle étape du pipeline le modèle se trouve.
- La communication entre les équipes est facilitée par l’utilisation d’un vocabulaire commun pour les étapes à suivre pendant le développement.
- Le processus peut être appliqué de manière répétée au développement de nombreux modèles, ce qui permet de gérer le chaos.
En fin de compte, le rôle des MLOps dans l’apprentissage automatique est de fournir une approche méthodique du développement de modèles qui peut être automatisée autant que possible.
Plateformes pour la création de pipelines
Pour vous aider à mettre en œuvre les MLOps dans vos pipelines, vous pouvez utiliser l’une des nombreuses plateformes dont nous allons parler ici. Bien que les caractéristiques individuelles de ces plateformes puissent être différentes, elles vous aident essentiellement à accomplir les tâches suivantes :
- Stocker tous vos modèles avec leurs métadonnées associées – telles que les configurations, le code, la précision et les expériences. Elles incluent également les différentes versions de vos modèles pour le contrôle des versions.
- Stocker les métadonnées des ensembles de données, telles que les données utilisées pour former les modèles.
- Surveillez les modèles en production pour détecter les problèmes tels que la dérive des modèles.
- Déployez les modèles en production.
- Construire des modèles dans des environnements à faible code ou sans code.
Examinons les meilleures plateformes MLOps.
MLFlow

MLFlow est peut-être la plateforme de gestion du cycle de vie de l’apprentissage automatique la plus populaire. Elle est gratuite et open source. Elle offre les fonctionnalités suivantes
- un suivi pour enregistrer vos expériences d’apprentissage automatique, votre code, vos données, vos configurations et vos résultats finaux ;
- les projets pour conditionner votre code dans un format facile à reproduire ;
- déploiement pour déployer votre apprentissage automatique ;
- un registre pour stocker tous vos modèles dans un référentiel central
MLFlow s’intègre aux bibliothèques d’apprentissage automatique les plus répandues, telles que TensorFlow et PyTorch. Il s’intègre également à des plateformes telles que Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning et Databricks. Il fonctionne également avec différents fournisseurs de cloud comme AWS, Google Cloud et Microsoft Azure.
Azure Machine Learning
AzureMachine Learning est une plateforme d’apprentissage automatique de bout en bout. Elle gère les différentes activités du cycle de vie des machines dans votre pipeline MLOPs. Ces activités comprennent la préparation des données, la construction et l’entraînement des modèles, la validation et le déploiement des modèles, ainsi que la gestion et la surveillance des déploiements.
Azure Machine Learning vous permet de construire des modèles en utilisant l’IDE et le framework de votre choix, PyTorch ou TensorFlow.
Il s’intègre également avec ONNX Runtime et Deepspeed pour optimiser votre formation et votre inférence. Les performances s’en trouvent améliorées. Elle exploite l’infrastructure d’IA sur Microsoft Azure qui associe les GPU NVIDIA et le réseau Mellanox pour vous aider à créer des clusters d’apprentissage automatique. Avec AML, vous pouvez créer un registre central pour stocker et partager des modèles et des ensembles de données.
Azure Machine Learning s’intègre avec Git et GitHub Actions pour créer des flux de travail. Il prend également en charge une configuration hybride ou multicloud. Vous pouvez également l’intégrer à d’autres services Azure tels que Synapse Analytics, Data Lake, Databricks et Security Center.
Google Vertex AI

Google Vertex AI est une plateforme unifiée de données et d’IA. Elle vous fournit les outils dont vous avez besoin pour créer des modèles personnalisés et pré-entraînés. Elle sert également de solution de bout en bout pour la mise en œuvre de MLOps. Pour faciliter son utilisation, elle s’intègre à BigQuery, Dataproc et Spark pour un accès transparent aux données pendant la formation.
En plus de l’API, Google Vertex AI fournit un environnement d’outils à code bas et sans code afin qu’il puisse être utilisé par des non-développeurs tels que les analystes commerciaux et de données et les ingénieurs. L’API permet aux développeurs de l’intégrer aux systèmes existants.
Google Vertex AI vous permet également de créer des applications d’IA générative à l’aide de Generative AI Studio. Il facilite et accélère le déploiement et la gestion de l’infrastructure. Les cas d’utilisation idéaux de Google Vertex AI comprennent la préparation des données, l’ingénierie des fonctionnalités, la formation et le réglage des hyperparamètres, la fourniture de modèles, le réglage et la compréhension des modèles, la surveillance des modèles et la gestion des modèles.
Lisez aussi : Apprenez l’ingénierie des fonctionnalités pour la science des données et la ML.
Databricks

Databricks est un lac de données qui vous permet de préparer et de traiter les données. Avec Databricks, vous pouvez gérer l’ensemble du cycle de vie de l’apprentissage automatique, de l’expérimentation à la production.
Databricks fournit essentiellement un MLFlow géré offrant des fonctionnalités telles que l’enregistrement des données et la version des modèles ML, le suivi des expériences, le service de modèles, un registre de modèles et le suivi des métriques publicitaires. Le registre de modèles vous permet de stocker des modèles à des fins de reproductibilité et vous aide à suivre les versions et l’étape du cycle de vie dans laquelle elles se trouvent.
Le déploiement de modèles à l’aide de Dataricks peut se faire en un seul clic, et vous disposerez de points d’extrémité d’API REST à utiliser pour faire des prédictions. Entre autres modèles, Dataricks s’intègre bien aux modèles génératifs et aux modèles de grand langage pré-entraînés existants, tels que ceux de la bibliothèque de transformateurs de visages en étreinte.
Dataricks fournit des blocs-notes Databricks collaboratifs qui prennent en charge Python, R, SQL et Scala. En outre, il simplifie la gestion de l’infrastructure en fournissant des clusters préconfigurés qui sont optimisés pour les tâches d’apprentissage automatique.
AWS SageMaker

AWSSageMaker est un service cloud AWS qui vous fournit les outils dont vous avez besoin pour développer, former et déployer vos modèles d’apprentissage automatique. L’objectif principal de SageMaker est d’automatiser le travail manuel fastidieux et répétitif qu’implique la construction d’un modèle d’apprentissage automatique.
En conséquence, il vous fournit des outils pour construire un pipeline de production pour vos modèles d’apprentissage automatique en utilisant différents services AWS, tels que les instances Amazon EC2 et le stockage Amazon S3.
SageMaker fonctionne avec les Notebooks Jupyter installés sur une instance EC2, ainsi que tous les packages et bibliothèques communs nécessaires au codage d’un modèle de Machine Learning. Pour les données, SageMaker est capable d’extraire des données d’Amazon Simple Storage Service.
Par défaut, vous obtenez des implémentations d’algorithmes de machine learning communs tels que la régression linéaire et la classification d’images. SageMaker est également livré avec un moniteur de modèle qui permet un réglage continu et automatique pour trouver l’ensemble des paramètres qui fournissent la meilleure performance pour vos modèles. Le déploiement est également simplifié, car vous pouvez facilement déployer votre modèle sur AWS en tant que point de terminaison HTTP sécurisé que vous pouvez surveiller avec CloudWatch.
DataRobot
DataRobot est une plateforme MLOps populaire qui permet de gérer les différentes étapes du cycle de vie de l’apprentissage automatique, telles que la préparation des données, l’expérimentation ML, la validation et la gestion des modèles.
Elle dispose d’outils permettant d’automatiser l’exécution d’expériences avec différentes sources de données, de tester des milliers de modèles et d’évaluer les meilleurs pour les déployer en production. Il prend en charge la construction de modèles pour différents types de modèles d’intelligence artificielle afin de résoudre des problèmes de séries temporelles, de traitement du langage naturel et de vision par ordinateur.
Avec DataRobot, vous pouvez construire en utilisant des modèles prêts à l’emploi, vous n’avez donc pas besoin d’écrire du code. Vous pouvez également opter pour une approche “code-first” et mettre en œuvre des modèles à l’aide d’un code personnalisé.
DataRobot est livré avec des carnets de notes pour écrire et modifier le code. Vous pouvez également utiliser l’API pour développer des modèles dans l’IDE de votre choix. En utilisant l’interface graphique, vous pouvez suivre les expériences de vos modèles.
Exécuter l’IA

Run AI tente de résoudre le problème de la sous-utilisation de l’infrastructure d’IA, en particulier des GPU. Il résout ce problème en favorisant la visibilité de toute l’infrastructure et en s’assurant qu’elle est utilisée pendant la formation.
Pour ce faire, Run AI se place entre votre logiciel MLOps et le matériel de l’entreprise. Tout en occupant cette couche, toutes les tâches de formation sont exécutées à l’aide de Run AI. La plateforme, à son tour, planifie l’exécution de chacun de ces travaux.
Il n’y a pas de restriction quant au choix du matériel, qu’il soit basé sur le cloud, comme AWS et Google Cloud, sur site ou une solution hybride. Il fournit une couche d’abstraction aux équipes d’apprentissage automatique en fonctionnant comme une plateforme de virtualisation du GPU. Vous pouvez exécuter des tâches à partir de Jupyter Notebook, d’un terminal bash ou de PyCharm à distance.
H2O.ai
H2O est une plateforme d’apprentissage automatique distribuée et open-source. Elle permet aux équipes de collaborer et de créer un référentiel central pour les modèles où les scientifiques des données peuvent expérimenter et comparer différents modèles.
En tant que plateforme MLOps, H2O offre un certain nombre de fonctionnalités clés. Tout d’abord, H2O simplifie également le déploiement de modèles sur un serveur en tant que point d’extrémité REST. Il propose différents thèmes de déploiement tels que les tests A/B, les modèles Champoion-Challenger et le déploiement simple d’un seul modèle.
Pendant la formation, il stocke et gère les données, les artefacts, les expériences, les modèles et les déploiements. Les modèles peuvent ainsi être reproduits. Il permet également de gérer les autorisations au niveau du groupe et de l’utilisateur afin de régir les modèles et les données. Pendant l’exécution du modèle, H2O assure également un suivi en temps réel de la dérive du modèle et d’autres mesures opérationnelles.
Paperspace Gradient
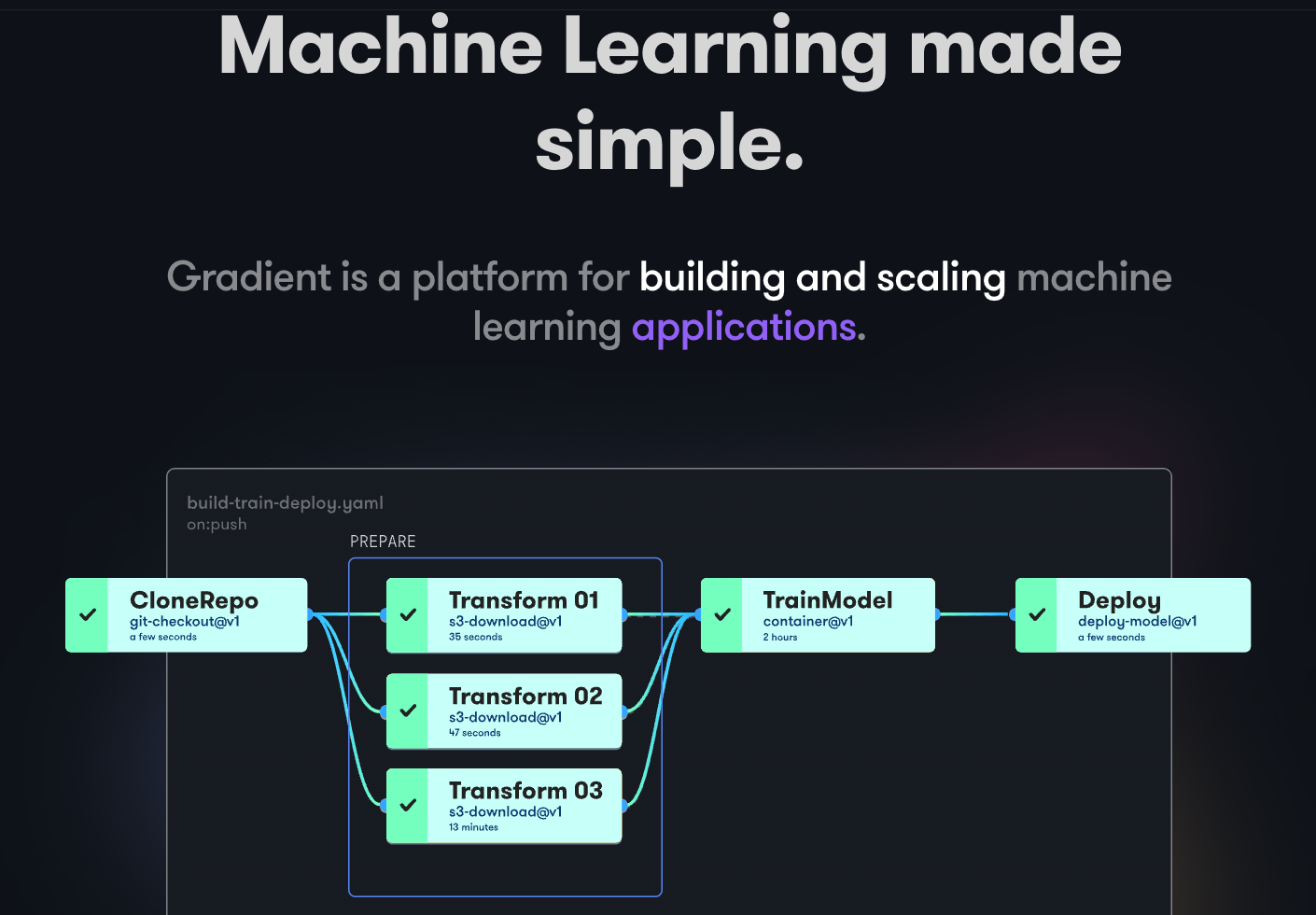
Gradient aide les développeurs à toutes les étapes du cycle de développement de l’apprentissage automatique. Il fournit des blocs-notes alimentés par le logiciel libre Jupyter pour le développement de modèles et l’entraînement sur le cloud à l’aide de puissants GPU. Cela vous permet d’explorer et de prototyper rapidement des modèles.
Les pipelines de déploiement peuvent être automatisés en créant des flux de travail. Ces flux sont définis en décrivant des tâches dans YAML. L’utilisation de flux de travail permet de créer des déploiements et de servir des modèles facilement réplicables et, par conséquent, évolutifs.
Dans son ensemble, Gradient fournit des conteneurs, des machines, des données, des modèles, des mesures, des journaux et des secrets pour vous aider à gérer les différentes étapes du pipeline de développement de modèles d’apprentissage automatique. Vos pipelines s’exécutent sur des clusters Gradiet. Ces clusters se trouvent sur Paperspace Cloud, AWS, GCP, Azure ou tout autre serveur. Vous pouvez interagir avec Gradient en utilisant le CLI ou le SDK de manière programmatique.
Le mot de la fin
MLOps est une approche puissante et polyvalente pour construire, déployer et gérer des modèles d’apprentissage automatique à grande échelle. MLOps est facile à utiliser, évolutif et sécurisé, ce qui en fait un bon choix pour les organisations de toutes tailles.
Dans cet article, nous avons abordé les MLOP, les raisons pour lesquelles il est important de les mettre en œuvre, ce qu’elles impliquent et les différentes plateformes MLOps populaires.
Ensuite, vous pouvez lire notre comparaison entre Dataricks et Snowflake.