La différence entre les produits médiocres et les produits excellents réside dans l’exploitation forestière. Découvrez pourquoi il en est ainsi et comment lier le tout.
Tout comme la sécurité, la journalisation est un autre composant clé des applications web (ou des applications en général) qui est mis de côté à cause de vieilles habitudes et de l’incapacité à voir plus loin. Ce que beaucoup considèrent comme des rames de bandes numériques inutiles sont des outils puissants pour regarder à l’intérieur de vos applications, corriger les erreurs, améliorer les points faibles et ravir les clients.
Avant d’aborder la question de la journalisation centralisée, examinons d’abord pourquoi la journalisation est si importante.
Deux types (niveaux) de journalisation
Les ordinateurs sont des systèmes déterministes, sauf quand ils ne le sont pas.
En tant que développeur professionnel, j’ai rencontré de nombreux cas où le comportement observé de l’application a déconcerté tout le monde pendant des jours, mais la clé se trouvait toujours dans les journaux. Chaque logiciel que nous utilisons produit (ou du moins devrait produire) des journaux, qui nous indiquent ce qu’il faisait lorsque la situation problématique s’est produite.
Selon moi, il existe deux types de journaux : les journaux générés automatiquement et les journaux générés par le programmeur. Veuillez noter qu’il ne s’agit pas d’une différenciation de manuel, et que me citer sur cette terminologie vous causera des ennuis. 😉
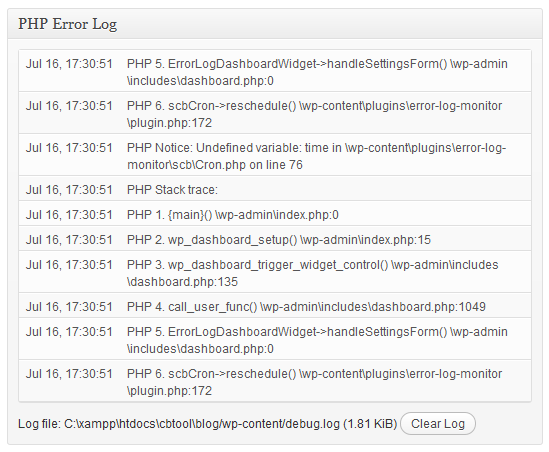
L’image ci-dessus montre ce que l’on peut appeler un journal auto-généré.
Dans ce cas précis, il s’agit d’un système WordPress qui enregistre une condition inattendue (un avis) lors de l’exécution d’un code PHP. Des journaux de ce type sont générés en permanence et sans relâche – par des outils de base de données comme MySQL, des serveurs web comme Apache, des langages et des environnements de programmation, des appareils mobiles et même des systèmes d’exploitation.
Ils contiennent rarement beaucoup de valeur, et les programmeurs ne prennent même pas la peine de les consulter, sauf en cas de problème. À ce moment-là, ils se plongent dans les journaux pour essayer de comprendre ce qui n’a pas fonctionné.
Mais les journaux générés automatiquement n’ont qu’une utilité limitée. Si plusieurs personnes ont un accès administrateur à un site, par exemple, et que l’une d’entre elles supprime une information essentielle, il est impossible de détecter le coupable à l’aide des journaux générés automatiquement. Du point de vue des systèmes reliés entre eux par l’application, il s’agit d’une journée de travail comme une autre : quelqu’un avait l’autorité nécessaire pour exécuter une tâche, et le système l’a exécutée.
Ce qu’il faut ici, c’est une couche supplémentaire de journalisation explicite et étendue qui crée des pistes pour l’aspect humain des choses. C’est ce que j’appelle les journaux générés par les programmeurs, et ils constituent l’épine dorsale d’industries sensibles comme la banque. Voici un exemple de ce à quoi pourrait ressembler un tel système de journalisation :
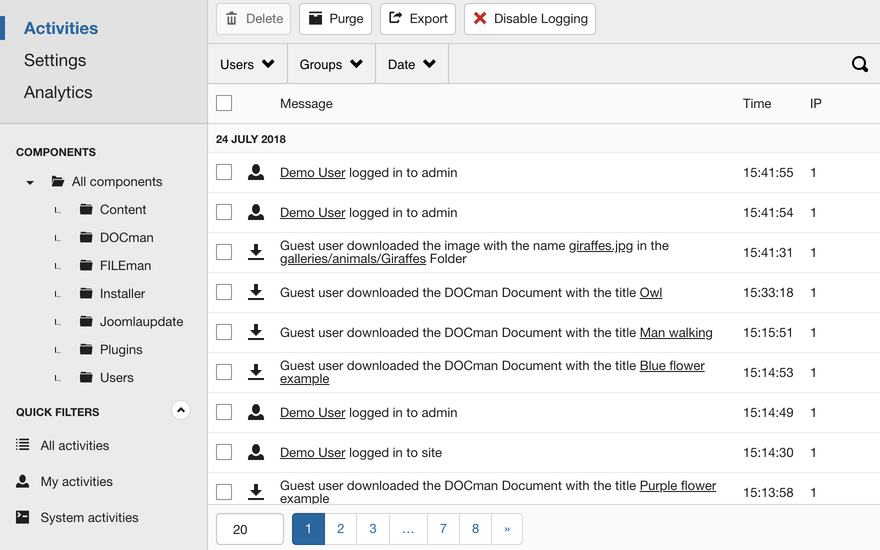
La journalisation, c’est le pouvoir
Si vous disposez de ces deux types de journaux dans un système, voici comment vous pouvez les exploiter et en augmenter l’impact.
Garder une longueur d’avance sur le client
l’”enchantement du client” est désormais considéré comme un gadget marketing inutile, mais grâce à la journalisation, il peut être rendu très concret. Je connais des produits numériques qui surveillent leurs journaux comme un faucon, et dès qu’un client casse quelque chose sur la page, ils peuvent l’appeler et lui proposer de l’aide.

Pensez-y : dans les secondes qui suivent l’apparition d’une vilaine erreur, vous recevez un appel de l’entreprise qui vous dit : “J’ai cru comprendre que vous essayiez d’ajouter cet article au panier, mais qu’il n’arrivait pas à s’écouler. Est-ce que je peux ajouter cet article et terminer la commande pour vous ?”
Un client ravi ? Et comment !
Moral et productivité de l’équipe
Comme je l’ai dit plus haut, lorsque des bogues ne sont pas détectés pendant une longue période, les développeurs de votre équipe sont frustrés et perdent de plus en plus de temps à courir après les bogues. Et c’est justement le problème avec le débogage: il nécessite un esprit frais et curieux dès le départ. Si une pensée WTF s’immisce dans votre cerveau, l’ensemble du processus tombe à l’eau.

Et qu’est-ce qui rend le débogage difficile ? D’après mon expérience, le manque de journalisation, ou le manque de connaissance de la journalisation. Pour commencer, il se peut que vous ne réalisiez pas que votre base de données préférée n’est qu’un autre logiciel qui génère des logs, ou que vous ne fassiez pas beaucoup de logs dans votre application (voir les logs générés par le programmeur ci-dessus).
Je me souviens particulièrement d’un cas où l’application ne répondait plus, sans que personne ne sache pourquoi. Quelques jours plus tard, le coupable était la limite d’entrées/sorties du disque atteinte en raison d’un trafic excessif. Comme personne ne s’est donné la peine de chercher, personne n’a pu comprendre pourquoi.
Pistes d’audit
Que se passe-t-il si, deux ans plus tard, votre client affirme que toutes ces commandes n’ont pas été passées par lui, mais par un pirate informatique?
Quel argument vous permettrait d’accéder à sa demande ou de la rejeter ? Si vous disposez d’un enregistrement complet (adresse IP, date et heure, carte de crédit, etc.), vous serez en mesure d’analyser tout cela et de prendre une décision. Qu’elle soit bonne ou mauvaise, elle aura au moins une base objective, plutôt que de ressembler à un coup d’essai.

Il en va de même si vous êtes soumis à une réglementation ou à un audit par un tiers dans le cadre d’un nouveau projet important. L’absence d’un système de journalisation robuste vous fera mal voir.
Améliorer les systèmes existants
Comment améliorer le système actuel ?
Faut-il se contenter d’augmenter la mémoire vive et le nombre de threads de l’unité centrale ? Que faire si votre application est lente malgré des ressources suffisantes ? Où se trouve le goulot d’étranglement ? Le plus souvent, la journalisation est la réponse.
Par exemple, tous les principaux systèmes de base de données disposent d’une fonction permettant d’enregistrer les requêtes lentes.
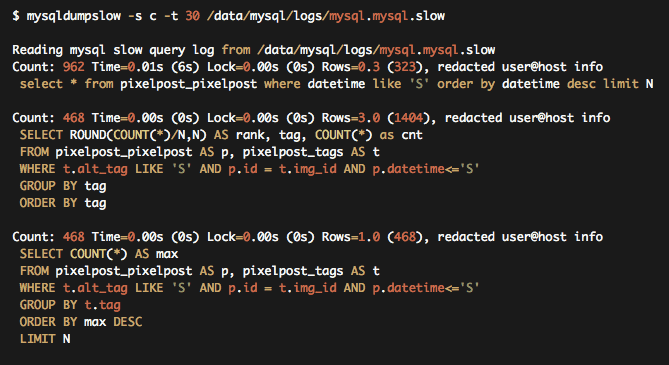
Si vous consultez régulièrement le journal des requêtes lentes, vous saurez quelles sont les opérations qui prennent le plus de temps et vous découvrirez ainsi de petites zones importantes sur lesquelles il faut travailler. Souvent, un petit changement de ce type est plus efficace que le doublement de la capacité matérielle.
On ne compte plus les façons dont un bon système de journalisation peut vous aider. Le meilleur argument est peut-être qu’il s’agit d’une activité automatisée qui, une fois mise en place, ne nécessite aucune surveillance et qui vous sauvera un jour de la ruine.
Ceci étant dit, examinons quelques-uns des étonnants collecteurs de logs (outils de journalisation unifiés) Open Source qui existent. Au cas où vous vous poseriez la question, nous avons abordé les outils de journalisation commerciaux basés sur le cloud dans un article précédent.
Graylog
Graylog est l’un des principaux noms de l’industrie en ce qui concerne les capacités de journalisation et de visualisation de niveau industriel. Il est également unique en ce sens qu’il analyse vos journaux collectés à la recherche de signes de vulnérabilité en matière de sécurité et vous en informe instantanément.
Graylog est un système de journalisation centralisé, mais il offre la souplesse dont vous avez besoin, en vous permettant de personnaliser les alertes, les tableaux de bord, etc.
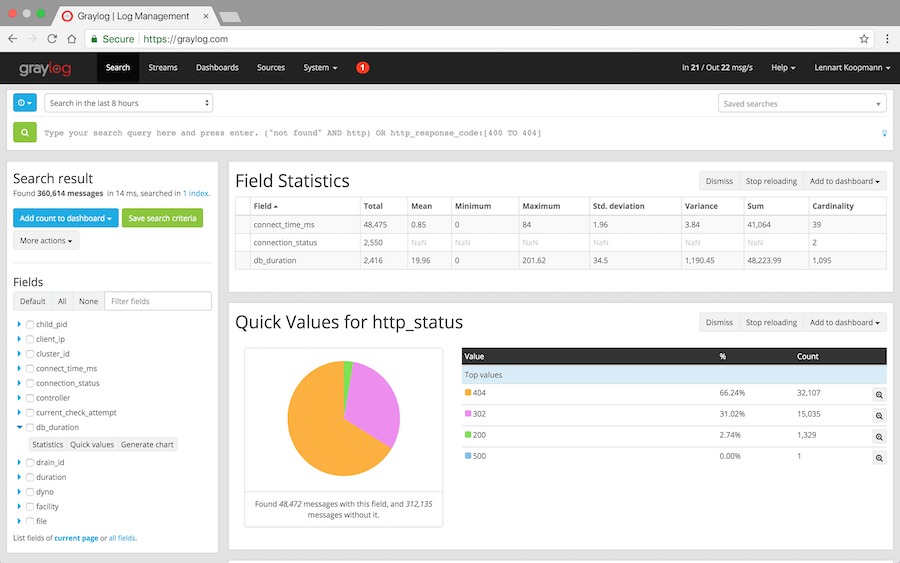
Graylog est un logiciel libre, mais il existe un plan d’entreprise si vos besoins sont complexes.
Avec des clients tels que SAP, Cisco et LinkedIn, Graylog est un outil auquel vous pouvez faire confiance les yeux fermés.
Logstash
Si vous êtes un fan ou un utilisateur de la pile Elastic, Logstash vaut la peine d’être vérifié (la pile ELK est déjà une chose, au cas où vous ne le sauriez pas). Comme les autres outils de journalisation de cette liste, Logstash est entièrement open-source, ce qui vous donne la liberté de le déployer et de l’utiliser comme vous le souhaitez.
Mais ne vous y trompez pas : Logstash est un vaisseau-mère dont les capacités dépassent de loin celles de n’importe quel outil de journalisation. Il est capable de collecter de grandes quantités de données à partir de plusieurs plateformes, vous permet de définir et d’exécuter vos propres pipelines de données, de donner un sens aux vidages de journaux non structurés, et bien plus encore.
Bien sûr, la seule limitation est qu’il ne fonctionne qu’avec la suite de produits Elastic, mais si vous commencez et que vous cherchez à évoluer rapidement, Logstash est la voie à suivre !
Fluentd
Parmi les outils de journalisation centralisés qui fonctionnent comme une couche intermédiaire pour l’ingestion de données, Flutend est un premier parmi les égaux. Avec une excellente bibliothèque de plugins, Fluentd est capable de capturer des données à partir de pratiquement n’importe quel système de production, de les pétrir dans la structure désirée, de construire un pipeline personnalisé et de les envoyer à votre plateforme analytique préférée, que ce soit MongoDB ou Elasticsearch.
Fluentd est construit sur Ruby, est entièrement open source, et est très populaire en raison de sa flexibilité et de sa modularité.
Avec des entreprises majeures comme Microsoft, Atlassian, et Twilio qui utilisent la plateforme, Fluentd n’a rien à prouver 🙂
Flume
Si les très, très grands ensembles de données sont votre défi, et que vous voulez éventuellement alimenter quelque chose comme Hadoop, Flume est l’un des meilleurs choix qui soient. Il s’agit d’un projet open source “pur”, dans le sens où il est maintenu par notre chère Fondation Apache, ce qui signifie qu’il n’y a pas de plan d’entreprise.
Ce n’est pas forcément ce que vous recherchez 🙂
Écrit en Java (qui continue de m’étonner lorsqu’il s’agit de technologies révolutionnaires), le code source de Flume est entièrement ouvert. Flume est fait pour vous si vous recherchez une plateforme d’ingestion de données distribuée et tolérante aux pannes pour des tâches lourdes.
Octopussy
Je lui donne zéro sur dix pour la dénomination du produit, mais Octopussy peut être un bon choix si vos besoins sont simples et que vous vous demandez ce que signifie toute cette agitation liée aux pipelines, à l’ingestion, à l’agrégation, etc.
À mon avis, Octopussy couvre les besoins de la plupart des produits existants (les statistiques estimées sont inutiles, mais si je devais deviner, je dirais qu’il prend en charge 80% des cas d’utilisation dans le monde réel).

Octopussy n’a pas du tout une grande interface utilisateur, mais il se rattrape en termes de vitesse et d’absence de gonflement. Les sources sont disponibles sur GitHub, comme prévu, et je pense qu’il vaut la peine d’y jeter un coup d’œil.
Rsyslog
Rsyslog est un système de traitement des logs rapide comme une fusée.
Il s’agit d’un utilitaire pour les systèmes d’exploitation de type Unix. En termes techniques, il s’agit d’un routeur de messages dont les entrées et les sorties peuvent être chargées dynamiquement et qui est hautement configurable.
Il peut recevoir des données de plusieurs sources, les transformer et envoyer les résultats vers plusieurs destinations. Avec Rsyslog, vous pouvez envoyer 1 million de messages par seconde vers des destinations locales.
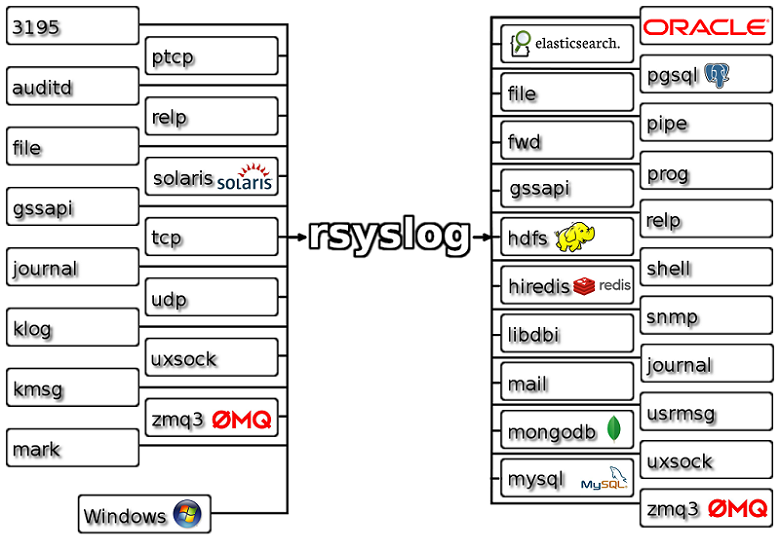
Rsyslog fournit également un agent Windows qui travaille en étroite collaboration avec l’agent Linux Rsyslog. Il est utilisé pour l’intégration entre les deux environnements. Cet agent Windows est utilisé pour transmettre les journaux d’événements de Windows et pour configurer le service de surveillance des fichiers.
Vous trouverez ci-dessous d’autres fonctionnalités offertes par Rsyslog :
- Configurations flexibles
- Capacités multithreading
- Protection contre la manipulation des fichiers journaux à l’aide de signatures de journaux et de cryptage.
- Prise en charge des plateformes Big Data
- Fournit des capacités de filtrage basées sur le contenu
Grafana Loki
Inspiré par Prometheus, Grafana Loki est une solution d’agrégation de logs multi-tenant.
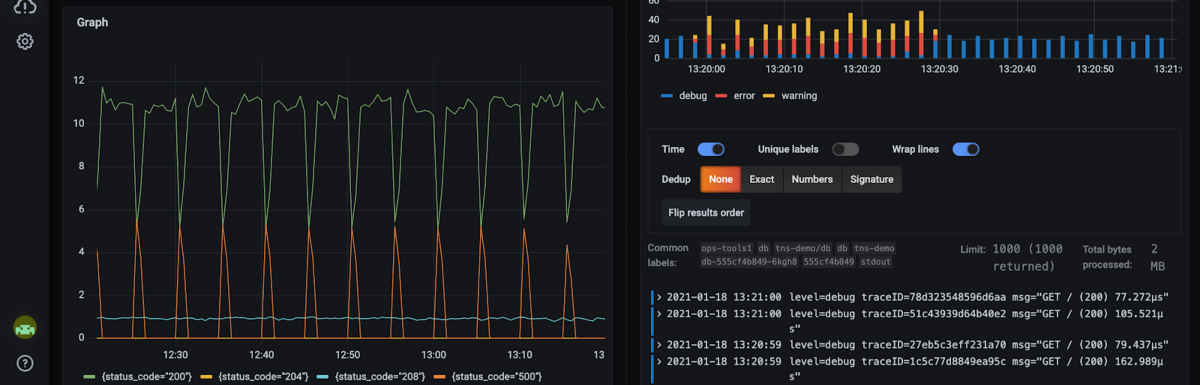
La solution Loki est rentable, elle indexe uniquement les métadonnées et peut être branchée sur un système populaire comme Kubernetes, Prometheus, Linux, SQL, etc. Vous pouvez consulter ce guide de démarrage pour l’installer et voir par vous-même comment elle fonctionne.
Logwatch
Je suis sûr qu’il y a ceux parmi nous qui ne veulent pas de toute la cérémonie associée à un système de journalisation “unifié”, “centralisé”. Leur activité est basée sur des serveurs uniques et ils recherchent quelque chose de rapide et d’efficace pour surveiller leurs fichiers journaux. Eh bien, dites bonjour à Logwatch.
Une fois installé, LogWatch peut analyser les journaux de votre système et créer un rapport du type que vous souhaitez. Il s’agit d’un logiciel quelque peu désuet (lisez “fiable”), cependant, et il a été écrit en Perl. Vous aurez donc besoin de Perl 5.6 sur votre serveur pour le faire fonctionner. Je n’ai pas de captures d’écran à partager car il s’agit d’un processus purement en ligne de commande, démonisé.
Si vous êtes un accro de la ligne de commande et que vous aimez la vieille école, vous allez adorer Logwatch !
Syslog-ng
L’outil Syslog-ng a été développé pour traiter les fichiers de données Syslog (un protocole client-serveur établi pour l’enregistrement des systèmes) en temps réel. Au fil du temps, il en est venu à prendre en charge d’autres formats de données : non structurées, SQL et NoSQL. Le fonctionnement du protocole Syslog est assez bien résumé dans l’illustration suivante.

syslog-ng est un outil de collecte et de classification de logs fiable et de qualité production, écrit en C et reconnu depuis longtemps dans l’industrie. Le plus intéressant est son extensibilité, qui vous permet d’écrire des plugins en C, Python, Java, Lua ou Perl.
Abréviation de (Log Navigator), lnav est un outil purement terminal qui fonctionne sur une seule machine, dans un seul répertoire. Il est destiné à ceux qui ont unifié leurs logs dans un seul répertoire ou qui veulent filtrer et afficher des logs en temps réel à partir d’une seule source.
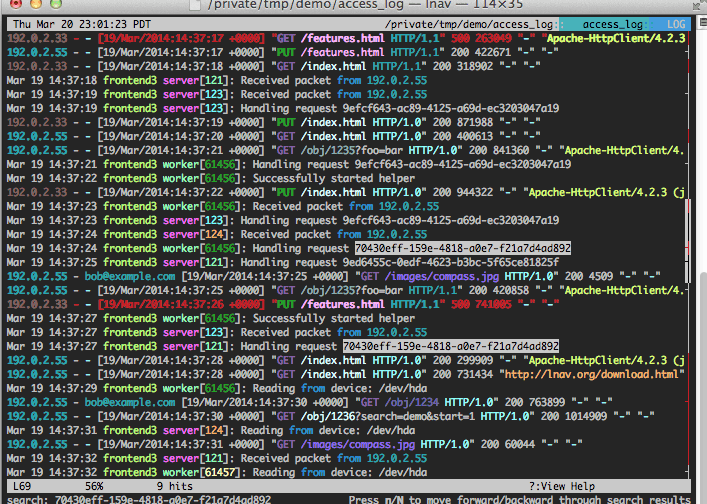
Si vous pensiez que lnav n’était rien de plus qu’un tailf|grep glorifié, vous vous trompiez. Il y a plusieurs fonctionnalités qui vous feront tomber amoureux de lui : l’affichage des séries temporelles, l’impression jolie (pour JSON et d’autres formats), les sources de logs codées en couleur, les filtres puissants, la capacité de comprendre plusieurs protocoles de logs, et plus encore.
C’est juste que parfois vous avez besoin d’une couche de journalisation sans tracas, sans installation, peut-être temporaire, et lnav répond parfaitement à ce besoin !
Conclusion
Et voilà, vous l’avez !
Cette liste a été difficile à compiler, pour être franc, car la journalisation n’est pas aussi populaire que, disons, la gestion de contenu, et tous les esprits semblent avoir été accaparés par trois ou quatre outils. Néanmoins, les besoins de chacun sont différents, et j’ai essayé de les couvrir largement.
Des simples outils en ligne de commande, sans installation, aux véritables mastodontes de la gestion des données, tout est là !
Ensuite, découvrez quelques-uns des meilleurs logiciels de profilage pour optimiser l’application.