Apache Parquet offre plusieurs avantages pour le stockage et la récupération des données par rapport aux méthodes traditionnelles comme CSV.
Le format Parquet est conçu pour un traitement plus rapide des données de types complexes. Dans cet article, nous expliquons comment le format Parquet est adapté aux besoins actuels en matière de données, qui ne cessent de croître.
Avant d’entrer dans les détails du format Parquet, essayons de comprendre ce que sont les données CSV et les défis qu’elles posent en matière de stockage de données.
Qu’est-ce que le stockage CSV ?
Nous avons tous beaucoup entendu parler des CSV(Comma Separated Values), l’un des moyens les plus courants d’organiser et de formater les données. Le stockage de données CSV est basé sur des lignes. Les fichiers CSV sont stockés avec l’extension .csv. Les données CSV peuvent être stockées et ouvertes à l’aide d’Excel, de Google Sheets ou de n’importe quel éditeur de texte. Les données sont facilement visualisables une fois le fichier ouvert.
Ce n’est pas une bonne chose, et certainement pas pour un format de base de données.
De plus, à mesure que le volume de données augmente, il devient difficile de les interroger, de les gérer et de les récupérer.
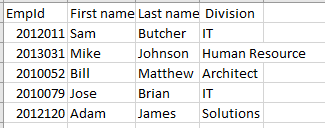
Voici un exemple de données stockées dans un fichier CSV :
Numéro d'employé, Prénom, Nom de famille, Secteur d'activité
2012011,Sam,Butcher,IT
2013031,Mike,Johnson,Ressources humaines
2010052,Bill,Matthew,Architecte
2010079,Jose,Brian,IT
2012120,Adam,James,Solutions
Si nous le visualisons dans Excel, nous pouvons voir une structure ligne-colonne comme ci-dessous :
Les défis du stockage CSV
Les stockages basés sur des lignes comme le CSV conviennent aux opérations de création, de mise à jouret de suppression.
Qu’en est-il alors de la lecturedans CRUD ?
Imaginez un million de lignes dans le fichier .csv ci-dessus. L’ouverture du fichier et la recherche des données souhaitées prendraient un temps raisonnable. Ce n’est pas si simple. La plupart des fournisseurs de services en nuage, comme AWS, facturent les entreprises en fonction de la quantité de données numérisées ou stockées – là encore, les fichiers CSV consomment beaucoup d’espace.
Le stockage des fichiers CSV n’offre pas d’option exclusive pour le stockage des métadonnées, ce qui rend la numérisation des données une tâche fastidieuse.
Quelle est donc la solution rentable et optimale pour effectuer toutes les opérations CRUD ? Explorons la question.
Qu’est-ce que le stockage de données Parquet ?
Parquet est un format de stockage open-source pour stocker les données. Il est largement utilisé dans les écosystèmes Hadoop et Spark. Les fichiers Parquet sont stockés sous l’extension .parquet.
Parquet est un format très structuré. Il peut également être utilisé pour optimiser des données brutes complexes présentes en masse dans les lacs de données. Cela permet de réduire considérablement le temps d’interrogation.
Parquet rend le stockage des données efficace et la récupération plus rapide grâce à un mélange de formats de stockage basés sur les lignes et les colonnes (hybride). Dans ce format, les données sont partitionnées horizontalement et verticalement. Le format Parquet élimine également dans une large mesure la surcharge d’analyse.
Le format limite le nombre total d’opérations d’E/S et, en fin de compte, le coût.
Parquet stocke également les métadonnées, qui contiennent des informations sur les données telles que le schéma de données, le nombre de valeurs, l’emplacement des colonnes, la valeur minimale, la valeur maximale, le nombre de groupes de lignes, le type d’encodage, etc. Les métadonnées sont stockées à différents niveaux du fichier, ce qui accélère l’accès aux données.
Dans le cas d’un accès basé sur les lignes, comme le format CSV, l’extraction des données prend du temps, car la requête doit parcourir chaque ligne pour obtenir les valeurs de colonnes particulières. Avec le stockage Parquet, il est possible d’accéder à toutes les colonnes requises en une seule fois.
En résumé,
- Parquet est basé sur la structure en colonnes pour le stockage des données
- Il s’agit d’un format de données optimisé pour stocker des données complexes en masse dans des systèmes de stockage
- Le format Parquet comprend diverses méthodes de compression et d’encodage des données
- Il réduit considérablement le temps de balayage des données et le temps d’interrogation, et occupe moins d’espace disque que d’autres formats de stockage tels que CSV
- Il minimise le nombre d’opérations d’entrée-sortie, réduisant ainsi le coût du stockage et de l’exécution des requêtes
- Inclut des métadonnées qui facilitent la recherche des données
- Fournit un support open-source
Format de données Parquet
Avant de passer à un exemple, nous allons comprendre plus en détail comment les données sont stockées dans le format Parquet :
Un fichier peut comporter plusieurs partitions horizontales, appelées groupes de lignes. Au sein de chaque groupe de lignes, un partitionnement vertical est appliqué. Les colonnes sont divisées en plusieurs morceaux de colonnes. Les données sont stockées sous forme de pages à l’intérieur des blocs de colonnes. Chaque page contient les valeurs de données encodées et les métadonnées. Comme nous l’avons mentionné précédemment, les métadonnées de l’ensemble du fichier sont également stockées dans le pied de page du fichier au niveau du groupe de lignes.
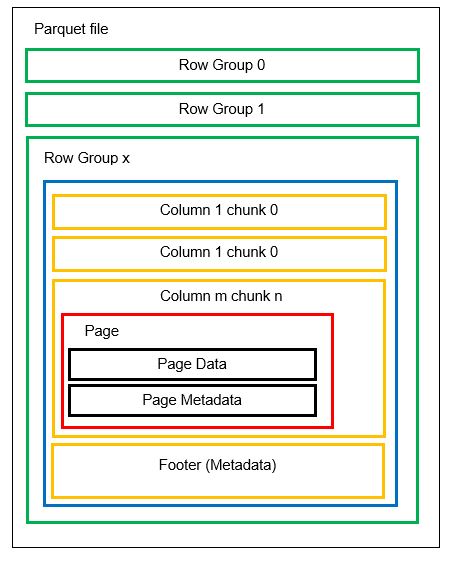
Comme les données sont divisées en morceaux de colonnes, il est également facile d’ajouter de nouvelles données en encodant les nouvelles valeurs dans un nouveau morceau et dans un nouveau fichier. Les métadonnées sont alors mises à jour pour les fichiers et les groupes de lignes concernés. On peut donc dire que Parquet est un format flexible.
Parquet supporte nativement la compression des données en utilisant des techniques de compression de page et d’encodage de dictionnaire. Voyons un exemple simple de compression de dictionnaire :
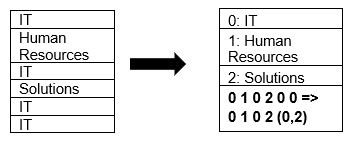
Notez que dans l’exemple ci-dessus, nous voyons la division informatique 4 fois. Ainsi, lors du stockage dans le dictionnaire, le format encode les données avec une autre valeur facile à stocker (0,1,2…) ainsi que le nombre de fois où elle est répétée en continu – IT, IT est remplacé par 0,2 pour économiser de l’espace. L’interrogation des données compressées prend moins de temps.
Comparaison directe
Maintenant que nous avons une bonne idée de l’aspect des formats CSV et Parquet, il est temps de comparer les deux formats à l’aide de statistiques :
| CSV | Parquet |
| Format de stockage basé sur les lignes. | Il s’agit d’un hybride des formats de stockage basés sur les lignes et sur les colonnes. |
| Il consomme beaucoup d’espace car aucune option de compression par défaut n’est disponible. Par exemple, un fichier de 1 To occupera le même espace s’il est stocké sur Amazon S3 ou tout autre nuage. | Le format Parquet compresse les données lors de leur stockage, ce qui permet de réduire la consommation d’espace. Un fichier de 1 To stocké au format Parquet n’occupera que 130 Go d’espace. |
| Le temps d’exécution des requêtes est lent en raison de la recherche basée sur les lignes. Pour chaque colonne, chaque ligne de données doit être récupérée. | Le temps d’exécution des requêtes est environ 34 fois plus rapide en raison du stockage par colonne et de la présence de métadonnées. |
| Davantage de données doivent être analysées par requête. | Environ 99 % de données en moins sont analysées pour l’exécution de la requête, ce qui optimise les performances. |
| La plupart des dispositifs de stockage facturent en fonction de l’espace de stockage, de sorte que le format CSV implique un coût de stockage élevé. | Les coûts de stockage sont moindres car les données sont stockées dans un format compressé et encodé. |
| Le schéma de fichier doit être soit déduit (ce qui entraîne des erreurs), soit fourni (ce qui est fastidieux). | Le schéma de fichier est stocké dans les métadonnées. |
| Le format convient aux types de données simples. | Parquet convient même aux types complexes tels que les schémas imbriqués, les tableaux et les dictionnaires. |
Conclusion 👩💻
Nous avons vu à travers des exemples que Parquet est plus efficace que CSV en termes de coût, de flexibilité et de performance. Il s’agit d’un mécanisme efficace pour stocker et récupérer des données, en particulier lorsque le monde entier s’oriente vers le stockage en nuage et l’optimisation de l’espace. Toutes les grandes plateformes comme Azure, AWS et BigQuery prennent en charge le format Parquet.