ChatGPT-4 vs. ChatGPT-4o vs. ChatGPT-4o mini vs. o1-preview vs. o1-mini: Differences Tested
OpenAI has launched its 4o series of GenAI models, including 4o, 4o mini, o1-preview, and o1-mini. The sheer presence of all these ChatGPT versions has added a significant cognitive overhead for the average user.
For instance, OpenAI recommends GPT-4o as “great for most tasks”, whereas GPT-4o mini is “faster for everyday tasks.” Likewise, o1-preview is branded for using advanced reasoning compared to o1-mini, which is “faster at reasoning.”
This guide will test the prompts and explore the difference between ChatGPT-4, ChatGPT-4o, ChatGPT-4o mini, o1-preview, and o1-mini.
Which ChatGPT Version to Choose?
In my trials, advanced OpenAI models (o1-mini & o1-preview) weren’t significantly better than GPT-4o and GPT-4o mini. Even the GPT-4 Legacy did fairly well for day-to-day tasks. Additionally, the o1-mini and o1-preview are notably more expensive than the 4o and 4o mini. Finally, I would advise using the latest GPT models only when absolutely needed.
The following sections have these models pitched against each other for seven prompts to judge their creativity, reasoning, and everyday usability.
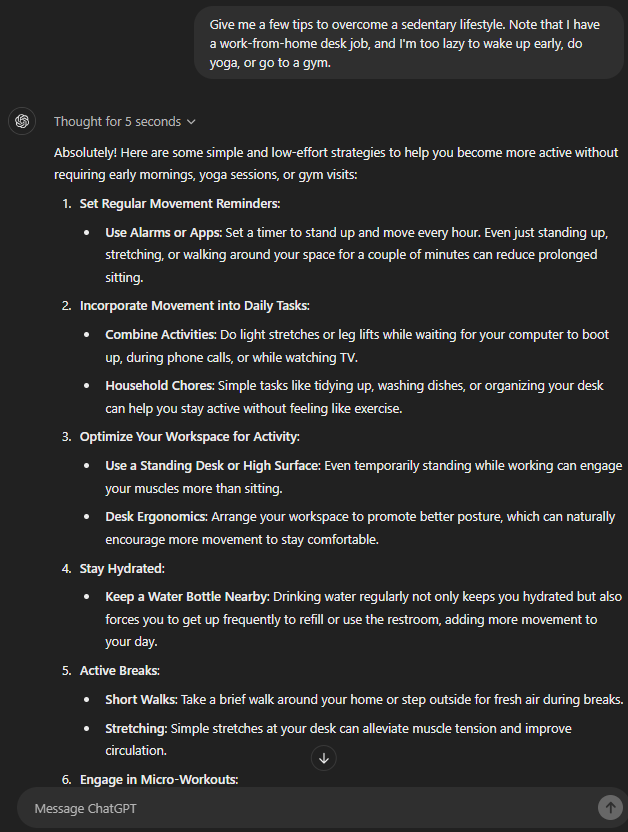
Give me a few tips to overcome a sedentary lifestyle. Note that I have a work-from-home desk job, and I’m too lazy to wake up early, do yoga, or go to a gym.
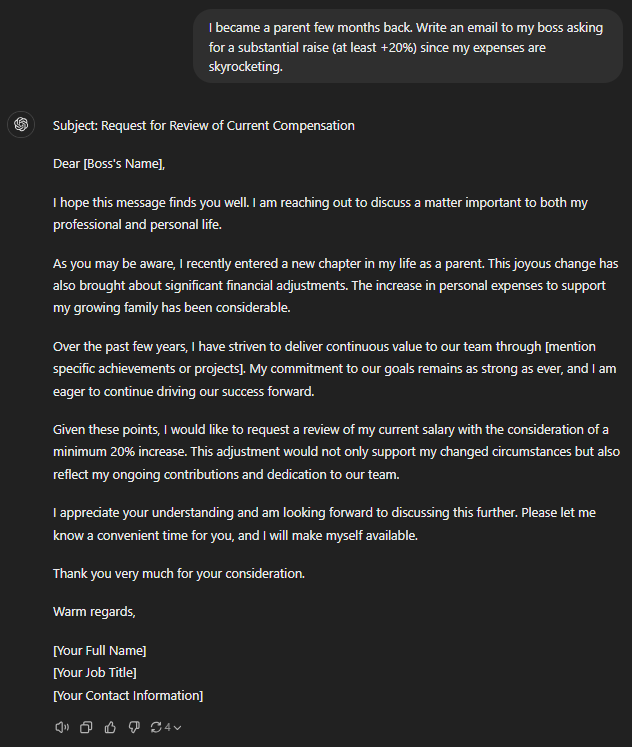
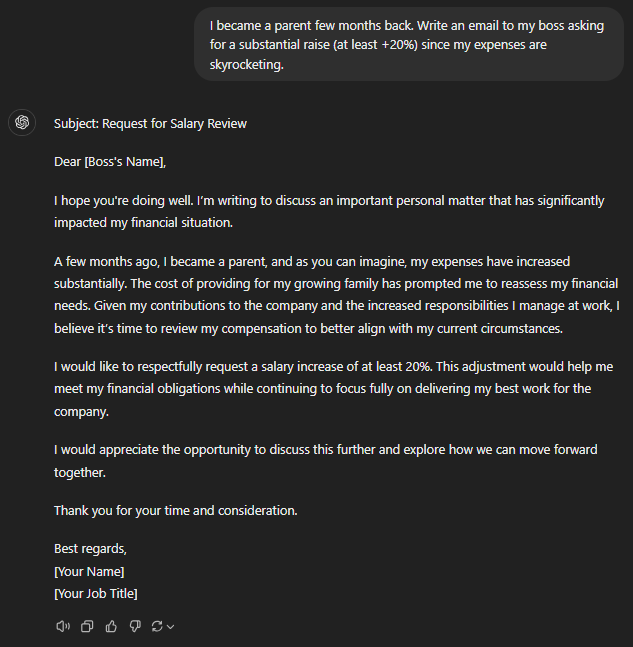
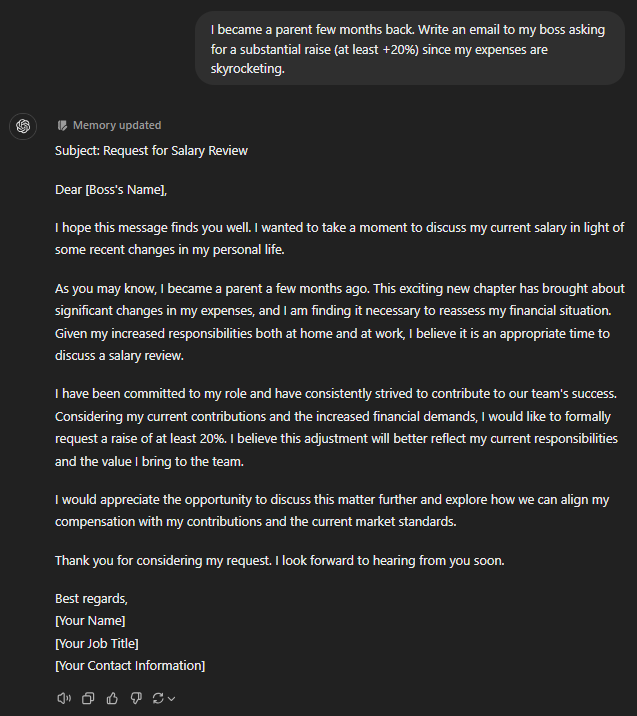
I became a parent a few months back. Write an email to my boss asking for a substantial raise (at least +20%) since my expenses are skyrocketing.
Give me a 10-point summary of the first installment of the Harry Potter book series, The Philosopher’s Stone.
Write a poem describing nuclear winter, its horrors, and the fact that no nation should press the red button. Use 10 lines or less.
A ship anchored in a port has a ladder that hangs over its side. The ladder is 300cm long, and the distance between each rung is 30cm. The bottom rung touches the water. The tide rises at a rate of 15cm an hour. When will the water reach the fourth rung?
Jesica has three brothers and four sisters. How many sisters do Jesica’s brothers have?
A male and a female are sitting on a bench. ‘I’m a male,’ says the person with brown hair. ‘I’m a female,’ says the person with black hair. If at least one of them is lying, who is the male, and who is the female?
Prompt 1: Suggest a Solution
Give me a few tips to overcome a sedentary lifestyle. Note that I have a work-from-home desk job, and I'm too lazy to wake up early, do yoga, or go to a gym.
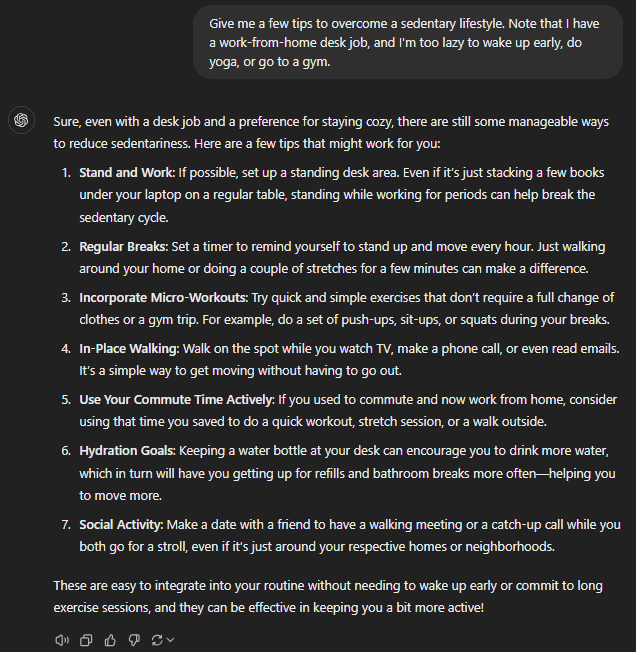
GPT-4
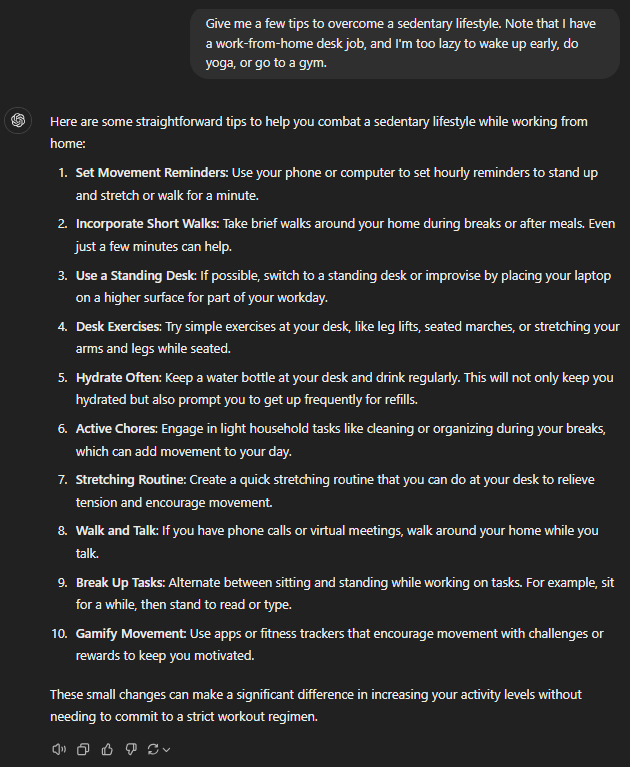
GPT-4o
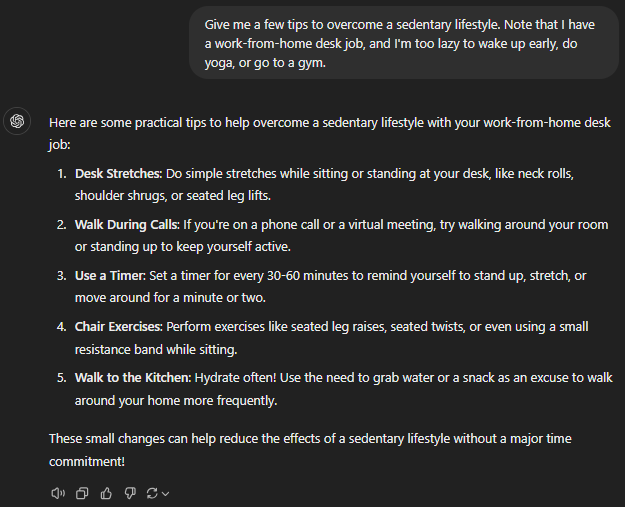
GPT-4o mini
GPT o1-preview
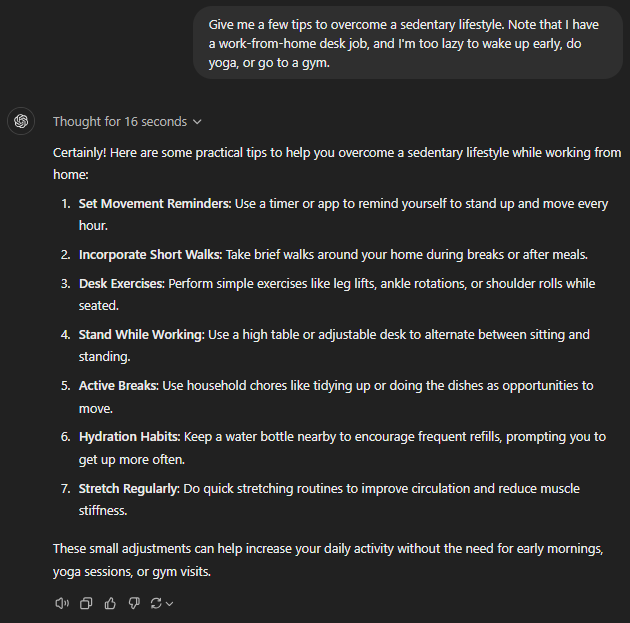
GPT o1-mini
Prompt 1 Assessment
All of the models checked out the basics, such as frequent breaks, periodic hydration, standing desks, etc.
GPT-4, despite being the legacy model, produced a pretty detailed output. It also assumed many of us had to commute pre-COVID and suggested using that time to work out. This is very practical and humanesque thinking, indeed.
4o turned out to be the shortest of them all, yet included almost everything without getting repetitive like 4o-mini. For instance, using a standing desk and alternating between sitting and standing is the same. Likewise, desk exercises and “stretching routine at your desk” are similar.
o1-preview resulted in the most concise answer. However, the o1-mini went in-depth, covering multiple tips to avoid a sedentary lifestyle, including micro workouts, using technology, socializing, and the ever-important posture awareness while working.
Prompt 2: Write an Email
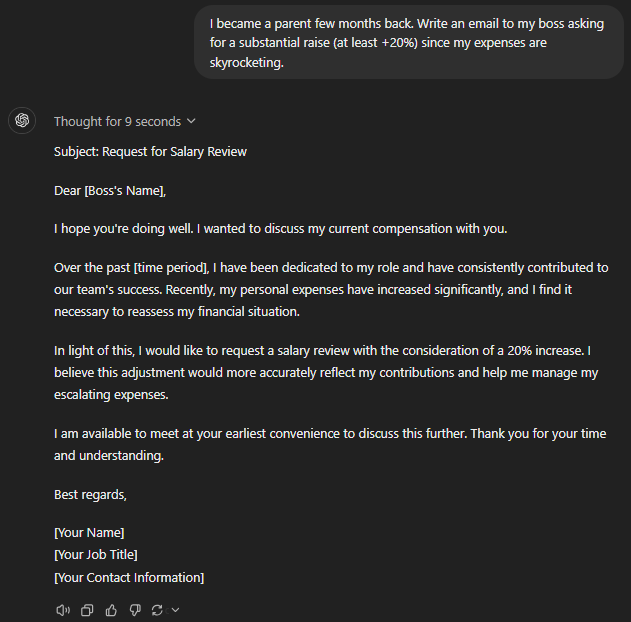
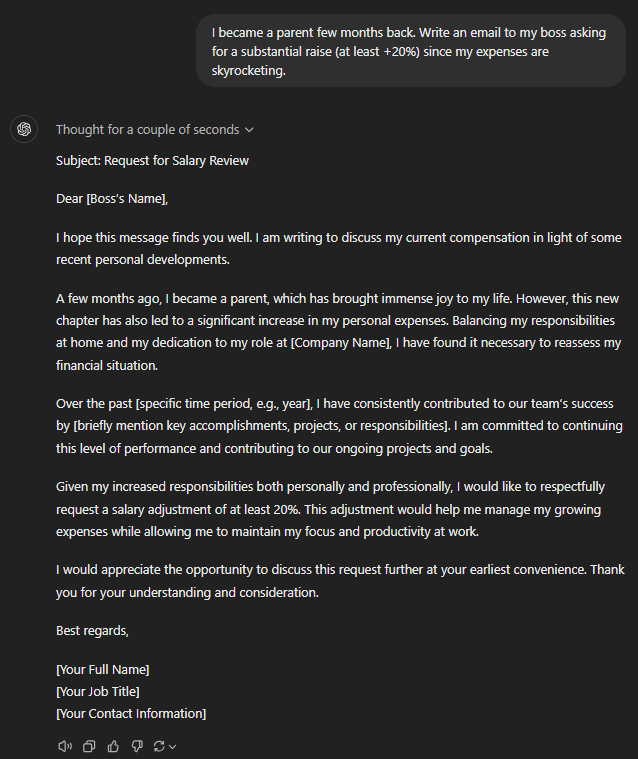
I became a parent few months back. Write an email to my boss asking for a substantial raise (at least +20%) since my expenses are skyrocketing.
GPT-4
GPT-4o
GPT-4o mini
GPT o1-preview
GPT-o1 mini
Prompt 2 Assessment
More or less every GPT model aced the job of writing the raise-requesting communication. It was a simple enough email I expect every LLM to write without using impractical phrasing.
Still, the GPT o1-preview felt the bluntest in the opening lines, followed by GPT-4o mini. Both of them didn’t make any background, whereas every other GPT brought up “personal issues” before jumping to the salary part.
GPT-4 and GPT-4o had the smoothest openings. Plus, GPT-4 and o1-mini suggested inputting key accomplishments, which are important while discussing raises.
o1-mini further reminded the boss that the increment is necessary to maintain productivity and focus. This was effective and very human.
Prompt 3: Creating Summaries
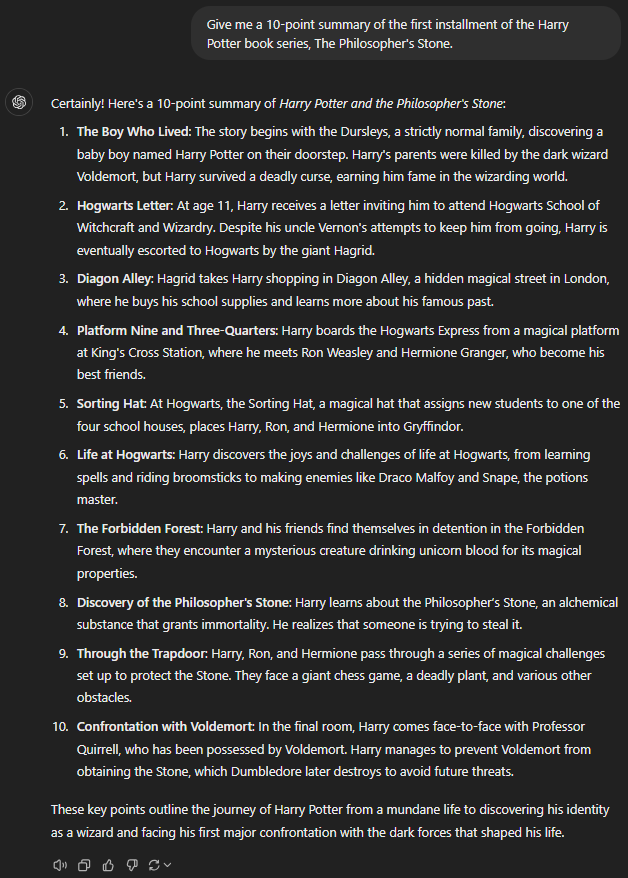
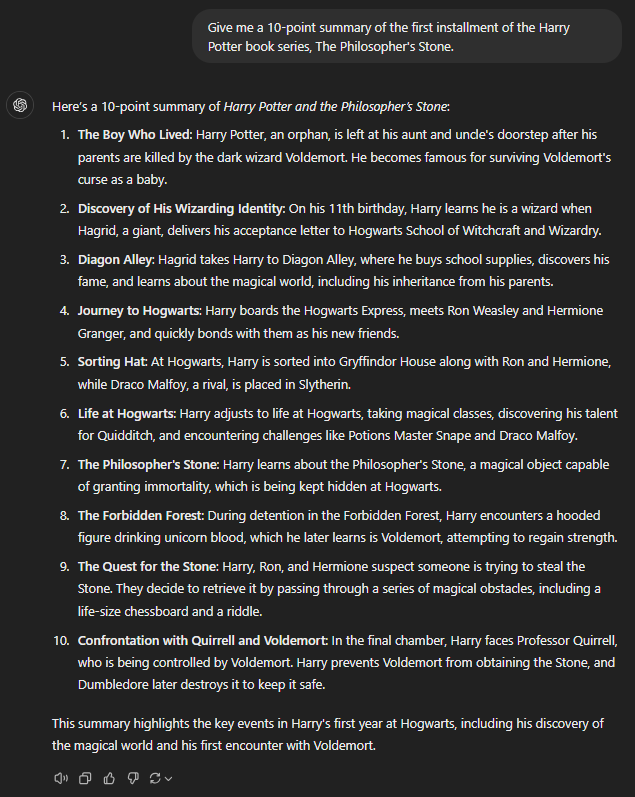
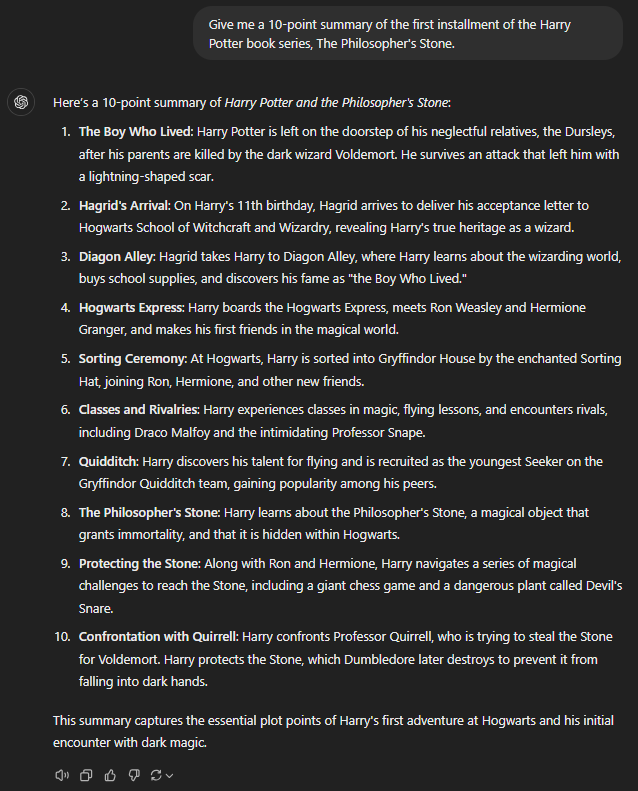
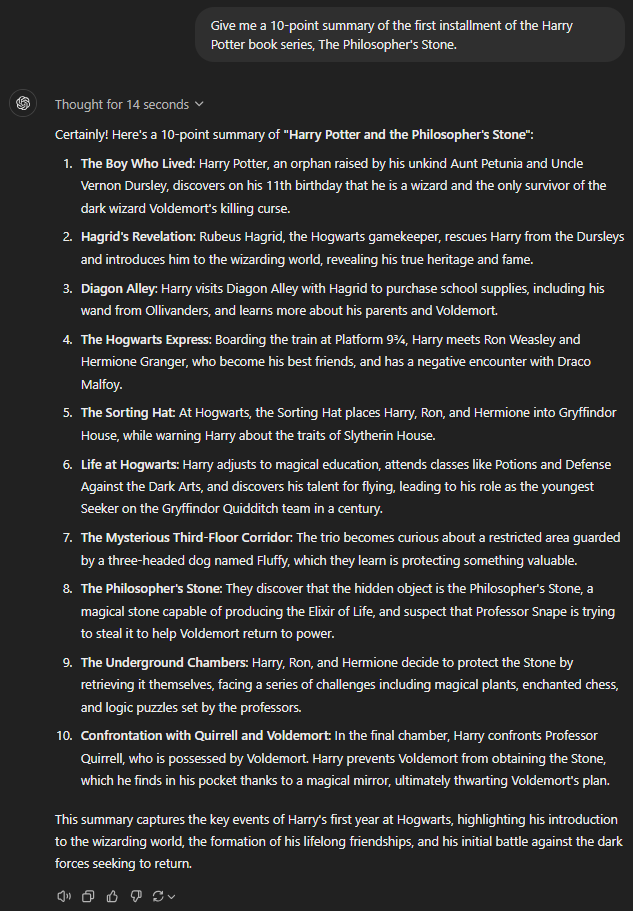
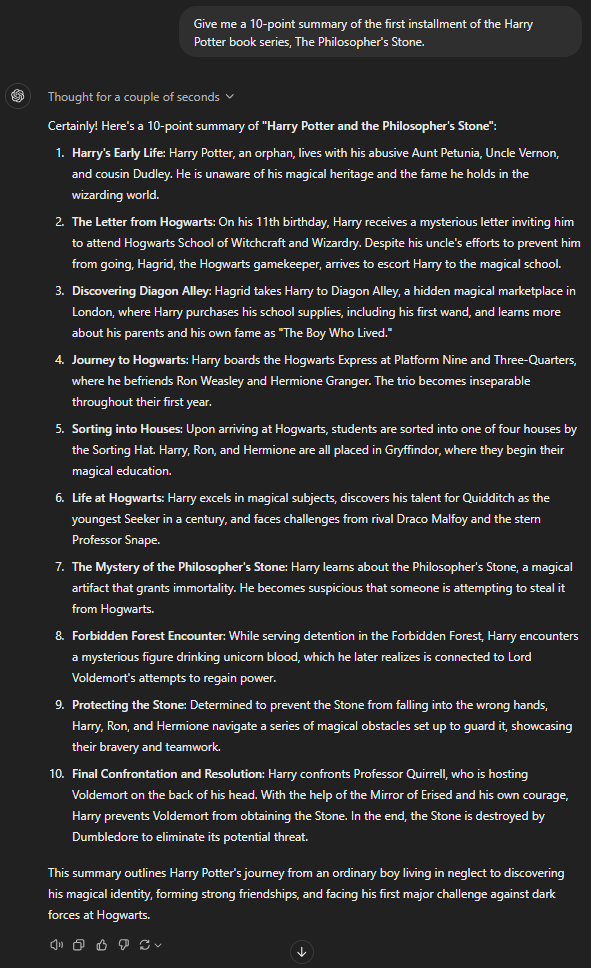
Give me a 10-point summary of the first installment of the Harry Potter book series, The Philosopher's Stone.
GPT-4
GPT-4o
GPT-4o mini
GPT o1-preview
GPT o1-mini
Prompt 3 Assessment
Writing a summary is one of the easiest things for a large language model. Unsurprisingly, all the GPTs did a commendable job summarizing the first book of the Harry Potter saga.
Still, the devil is always in the details.
In the context of this prompt, it’s important to start with the mention of Harry’s relatives, Durselys, being abusive and bullish. GPT-4 and 4o completely missed that point. 4o even missed writing about the magical platform Nine and Three Quarters, which was the true entry point of Harry in the wizarding universe.
However, even the top GPT models missed some details. For example, o1-preview didn’t mention anything about the forbidden forest, and o1-mini could not include the third-floor corridor.
Overall, summaries prepared with GPTs are hit or miss. While no one was perfect, the o1-preview was the best for the club.
Prompt 4: Write a Poem
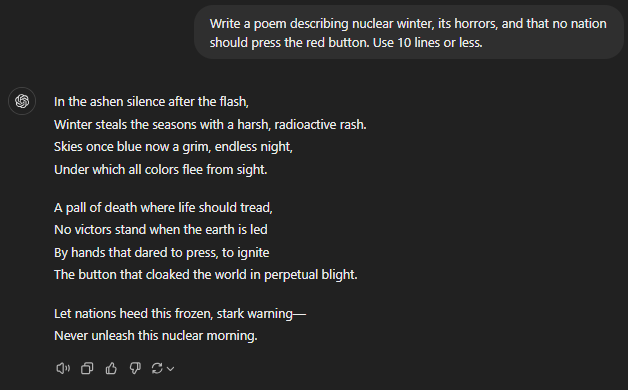
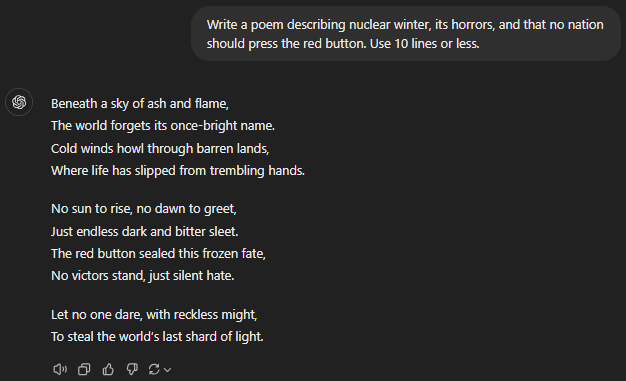
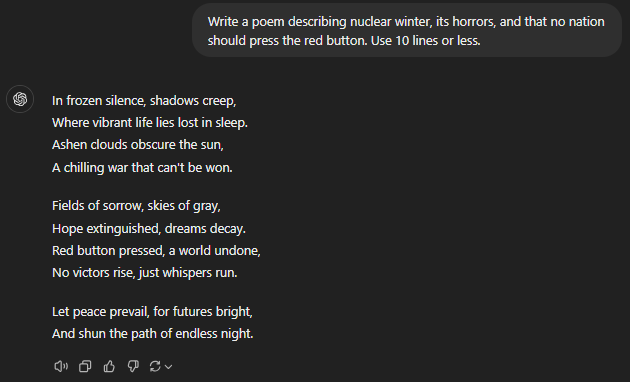
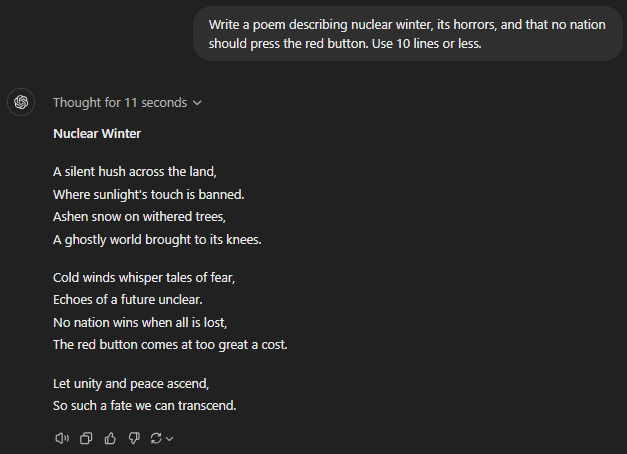
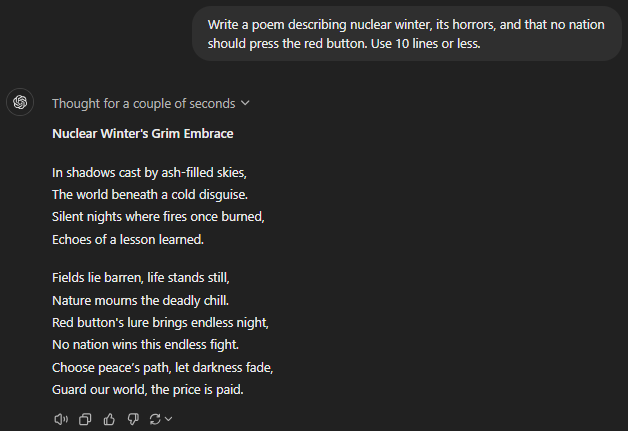
Write a poem describing nuclear winter, its horrors, and that no nation should press the red button. Use 10 lines or less.
GPT-4
GPT-4o
GPT-4o mini
GPT-o1 preview
GPT-o1 mini
Prompt 4 Assessment
Both of the advanced GPT models (o1 preview and o1 mini) suffered from lacklustre creative performance. These models assumed that nuclear war had already consumed the world, even when it was nowhere mentioned in the prompt. The idea was to describe a nuclear winter to warn people in power never to go down that path.
All the others, 4, 4o, and 4o mini, painted a grim nuclear winter picture and followed the prompt as-is. Personally, the 4o mini had the maximum impact with the fewest words.
Prompt 5: Logical Puzzle
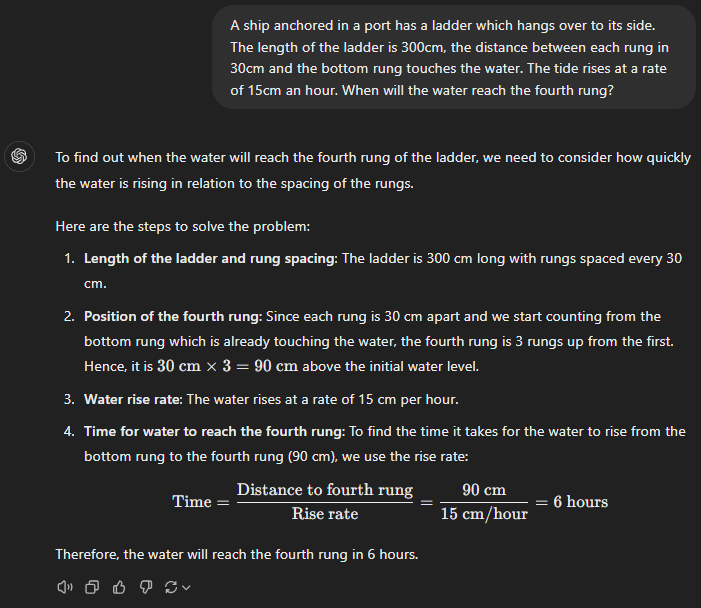
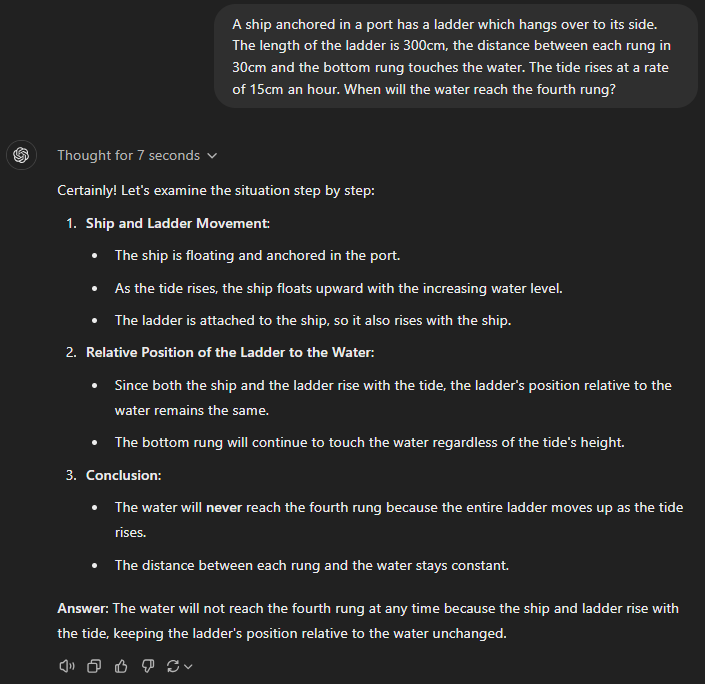
A ship anchored in a port has a ladder which hangs over to its side. The length of the ladder is 300cm, the distance between each rung in 30cm and the bottom rung touches the water. The tide rises at a rate of 15cm an hour. When will the water reach the fourth rung?
GPT-4
GPT-4o mini
GPT-4o
GPT-o1 preview
GPT-o1 mini
Prompt 5 Assessment
This was a simple, logical situation. Since the water was rising, so were the ship and the ladder attached to it. It was clear that the distance between the water surface and the fourth rung would remain constant, and they would never come into contact.
So, it was pretty bad to witness advanced GPTs such as o1-mini fail. While the o1-preview did succeed, it also broke down the simplest tasks and suffered from overanalysis.
Unfortunately, GPT-4 and GPT-4o mini could not understand the basics of how things work in water.
That brings us to GPT-4o, which took this problem like an intelligent human and quickly worked it out.
Prompt 6: Basic Reasoning
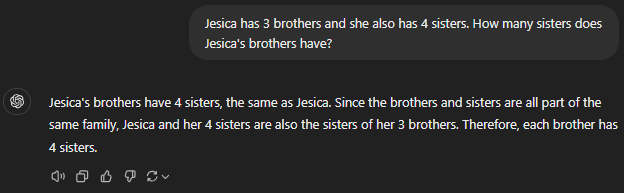
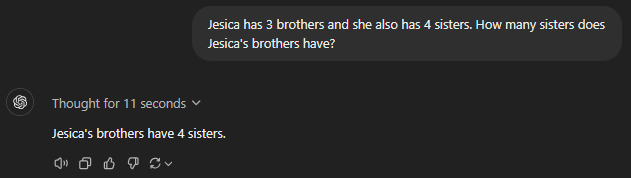
Jesica has three brothers and four sisters. How many sisters do Jesica's brothers have?
GPT-4
GPT-4o
GPT 4o mini
GPT o1-preview
GPT o1-mini
Prompt 6 Assessment
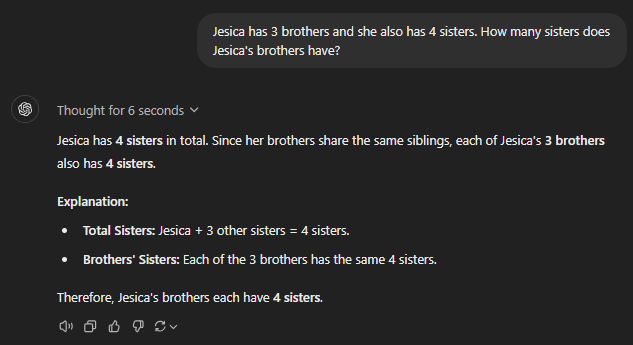
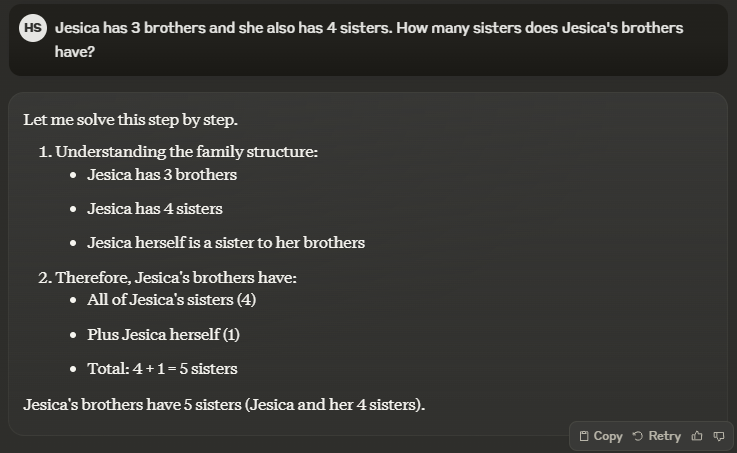
General or speciality, all GPT models failed at this basic reasoning puzzle. They could not count the actual number of female siblings in the family, which was indeed five (including Jesica).
It wasn’t complex at all since the prompt clearly mentioned that Jesica has four sisters. Just to clarify, I did confirm that all of the GPTs consider Jesica to be female.
This reminds us that AI models can be extremely unreliable and that human oversight is unavoidable.
Bonus: Meanwhile, Anthropic’s Claude got this easily.
Prompt 7: Practical Thinking
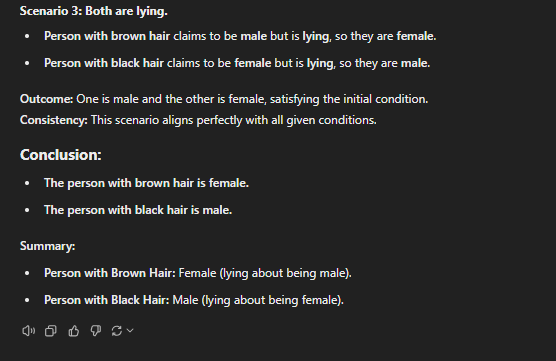
A male and a female are sitting on a bench. 'I'm a male,' says the person with brown hair. 'I'm a female,' says the person with black hair. If at least one of them is lying, who is the male and who is the female?
GPT-4
GPT-4o
GPT-4o mini
GPT o1-preview
GPT o1-mini
Prompt 7 Assessment
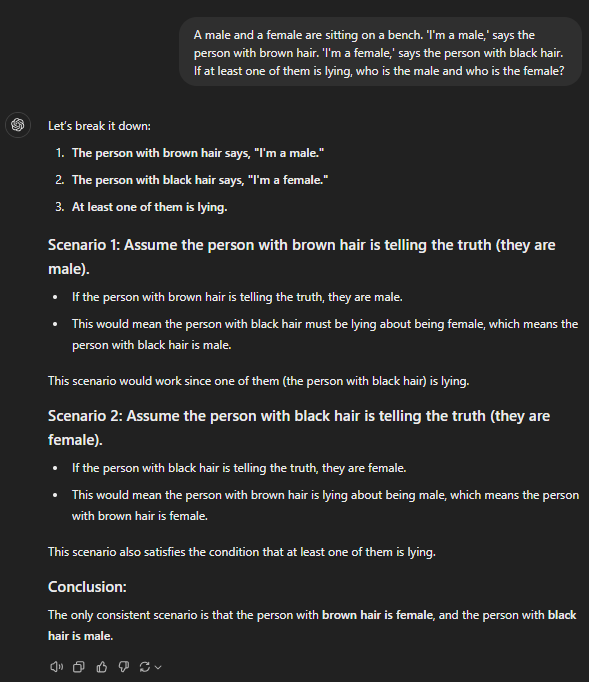
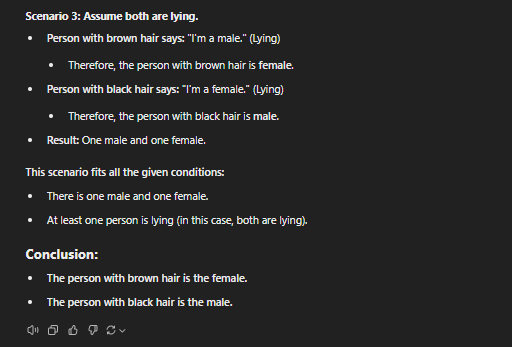
This was a simple puzzle. The only possible solution is that both people lie about their genders. GPT-4 had no solution to this brain teaser, whereas all the others solved it correctly.
However, o1-mini and 01-preview have a more structured (and pro-longed) way of tackling problems, which makes them fit for advanced reasoning.
ChatGPT Versions: Under the Cover
While all GPT models look the same on the surface, it’s important to know why OpenAI developed each of these models because the use cases aren’t one-size-fits-all type anymore.
General purpose model with advanced reasoning abilities
8,192 tokens
8,192 tokens
September 2021
GPT-4o
Faster and cheaper than GPT-4. Abilities similar to GPT-4 Turbo.
128,000 tokens
16,384 tokens
October 2023
GPT-4o mini
Cheapest GPT made for smaller tasks. Similar to GPT-3.5 Turbo
128,000 tokens
16,384 tokens
October 2023
GPT o1-preview
Complex reasoning with an internal thought process.
128,000 tokens
32,768 tokens
October 2023
GPT o1-mini
Faster and cheaper than o1-preview
128,000 tokens
65,536 tokens
October 2023
Except for the GPT-4 Legacy, all the latest models can take up to 128K tokens (1 token ~ four English characters) context. This means they are particularly well suited for longer conversations.
Likewise, GPT o1-mini can produce long replies, extending up to 65,536 tokens (~49,150 words) in one go. This is also clearly reflected in the o1-mini responses we saw earlier in this article. Every such output was lengthy compared to what was produced by other GPT models. However, this also means higher API costs since OpenAI bills based on (input, cached, and) output tokens.
I would suggest starting with GPT-4o mini since it’s the most cost-effective of them all and performs okay overall. One should move to GPT-4o next, followed by o1-mini and o1-preview, respectively.
As for GPT-4, OpenAI has already tagged it as “Legacy”. However, there is still little news of when OpenAI will push GPT-4 into sunset.
The Way Ahead
Rumours about AI replacing jobs in the future aren’t completely wrong.
First, automation did this in the manufacturing industry, and now it’s spreading wings everywhere else.
Now, it can do math, poetry, and write letters. However, the fact that it rarely says NO to a prompt and hardly learns from its mistakes puts it way behind humans.
“AI won’t replace us, but someone using AI can“. This is not just a random quote doing rounds on the internet. It’s the reality we have to live with.
Here at Geekflare, our marketing team uses ChatGPT in interesting ways. We use it for content summarization, grammar checking, suggesting titles for new articles, and whatnot.
Conclusively, there are many ways to benefit from and race ahead of stereotypes that see AI as a useless piece of junk. The only thing to remember is that someone (human) must judge AI work, as even the top-shelf GPTs can be (grossly) inaccurate and misleading.