Sora AI is a text-to-video model developed by OpenAI, the minds behind ChatGPT. It makes video production faster and more affordable, making it perfect for social media, marketing, or brainstorming prototypes. The character movements, lighting, proportions, and minute details (such as facial blemishes and fur texture) are fairly precise. As such, Sora AI is shaping up to become the ideal text-to-video AI model.
Sora’s user-friendly interface, along with powerful features like the Storyboard tool and integration with ChatGPT, makes it easy to create impressive videos quickly. With options like Remix, Re-cut, and Style Presets, you can get creative, and the tool ensures high-quality outputs (up to 1080p) for professional results.
Preventing powerful models like Sora from being used to create inappropriate animation (hateful, copyright infringing, and other negative possibilities) is vital. Not only for our safety, but to enforce rational best practices in the industry, which OpenAI is taking seriously.
Let me show you how to use Sora AI.
- Go to sora.com using your preferred web browser and Login.
- Enter your credentials (email and password) in the provided fields.
- Click Log In to access your account.
Write Sora Prompt
You’ll find the composer at the bottom of the screen, where you can write a text prompt to describe your video.
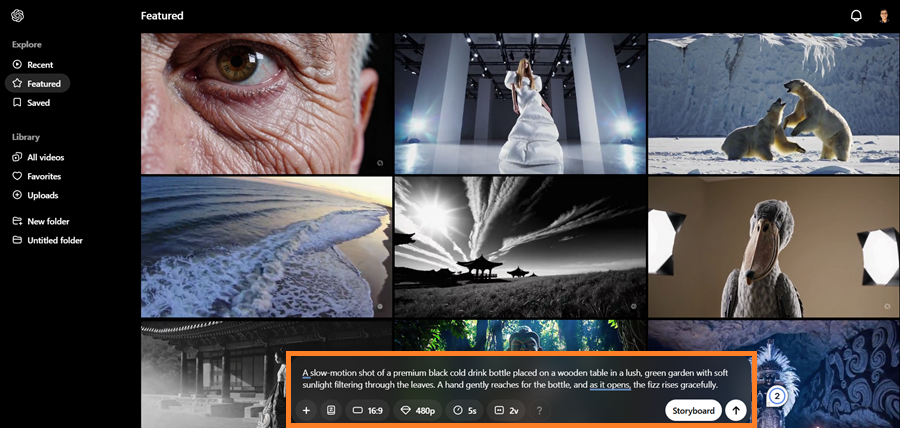
Review Settings
Before creating, you can customize your settings:
- Add a style preset
- Change aspect ratio, resolution, and duration
- Adjust the number of video variations generated from a single prompt
- Check out the help icon to check how many credits this will cost.
Click Create and the video will appear in your library, starting to generate.
View and Edit Videos
Place your cursor over the variations to see them in real-time, or drag to slow them down. Click a video to open it in a larger view, and use the arrow keys to scroll through the clips.
To modify your clip, use the toolbar for editing:
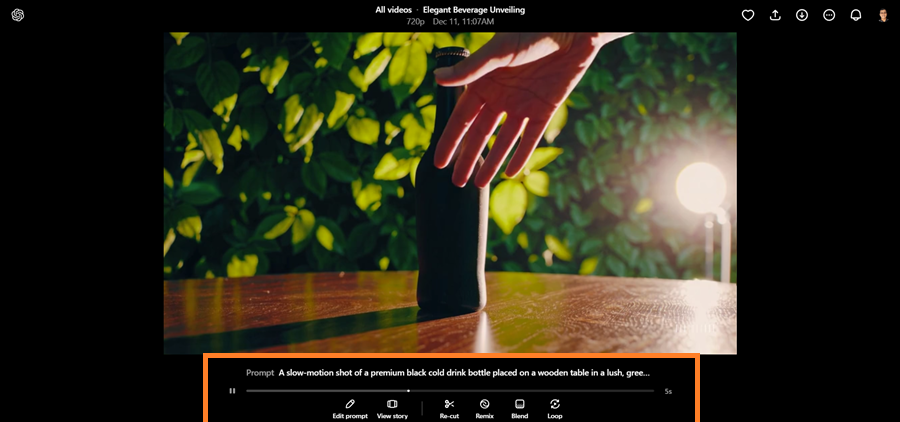
- Prompt/Storyboard Changes
- Recut (Trim or extend sections)
- Remix (Describe changes using natural language)
- Blend (Mix content with another video)
- Loop (Create repeating sections)
At the top, use quick actions to favorite, share, or download your video. Explore the community for inspiration, share your work, and learn new techniques.
Here is one I created, it looks cool. Isn’t it?
Best Practices to Write Effective Video Generation Prompts
Here are some of the best practices for writing effective video generation prompts.
- Subject: Explain the context or theme clearly.
- Visual elements: Describe key visuals, like characters, objects, and background.
- Actions and interactions: Detail what happens in the video (camera angle, movements)
- Emotions and tone: Indicate the emotional tone, and expressions (happy, dramatic, informative).
- Video style: Mention the style (animation, live-action, movie).
- Target audience: Specify who the video is for.
- Length and format: Select video duration and aspect ratio.
- Clarity and conciseness: Keep it simple and direct.
- Use relevant keywords: Help the AI understand your intent.
- Provide examples: Share reference videos or images if needed.
- Iterative refinement: Adjust your prompt based on the results.
Tip: Try different variations and choose the best one for your needs.
Examples of How Sora AI Works
Sora boasts industry-defining animation in many areas (lighting, minute details, and more), but it has difficulties with the usual AI pitfalls.
What Sora AI Can’t Do Yet
There are some issues interpreting concepts and directions. For example, when told to generate footage of a “Hermit crab using an incandescent lightbulb as its shell,” Sora produces visuals of a crab-like creature with a generic shell on its back that possesses a lightbulb on its rear end.
In this beachgoing length of animation, it’s clear that the character is only vaguely crab-like. Yes, it has legs and claws, but no living species of crab (or crab-like animals) have a shell like the one depicted in Sora’s imagery. Moreover, the lightbulb is not being used as a shell, it’s merely attached to the back of the character’s frame.
Another example can be found on OpenAI’s dedicated webpage about Sora. In one of the five videos outlining Sora’s current weaknesses, a prominent one depicts a man running on a treadmill in reverse. Criteria like directions—up, down, left, and right—are currently challenging for Sora to analyze. OpenAI has been transparent and honest about where their in-development text-to-video model is lacking, which seems like a sign that they know where and how to improve.

Overall, there are 5 (known) major issues with Sora AI’s graphics:
- Directional interpretation
- Characters and objects appear and disappear
- Objects and characters move through one another
- Defining when objects are meant to be rigid or soft
- Determining the outcomes of physical interactions between characters and objects
Keep in mind that Sora AI still has a long way to go before it’s ready for the public. As such, its current failings are bound to be addressed and corrected—at least to some degree.
What Sora AI Does Well
I really liked the quality of the videos Sora generates. The video I created had different camera angles and zoom-in/zoom-out effects, just like a real movie.
It handles more complex scenes with multiple elements and detailed backgrounds. The realism is much better too, with a more accurate representation of physics, human movement, and facial expressions, making the videos look more lifelike. Additionally, there are plenty of customization options, like selecting filters, resolution, time, quality, and different effects, giving me more control over the final result.
While OpenAI’s upcoming text-to-video generator can’t handle all aspects of intimate character and object interactions, the visuals are nearly flawless when the focus is on the environment.
Sweeping camera shots depicting coastal scenery and snowy bird’s-eye views of Tokyo are beautifully realistic. Equally, faux wildlife footage looks convincing.
What’s more, Sora is adept at combining organic and inorganic components when the instructions are vague. Unlike complex and unique prompts like “Give a hermit crab a lightbulb for a shell,” simpler ones with more freedom such as “Cybernetic German Shepherd” yield more appealing results.
Remember that AI models need to learn through ingesting data. There are many more visual examples of dogs with prosthetics than images of hermit crabs with glass objects on their backs.
On a similar note, Sora AI has access to a wealth of nature footage to produce documentary-style animation almost indistinguishable from real life. Generating visuals like a butterfly resting on a flower is consistent and elegant.
For inverse reasons, Sora can create impressively aesthetic content in completely fictional settings. When there is less real-world physics to consider, text-to-video AI models often logically fill in the gaps in prompt information. Therefore, simulations representing science fiction concepts like drones racing on the planet Mars look great—albeit not realistic (by nature of the prompt).
Coming up with a prompt for more cartoon-like animation benefits from this freedom. If the wording of a prompt is fine-tuned, Sora can turn a paragraph’s worth of input text into a stretch of animation on par with the likes of Pixar and other big-name animation studios. The outcome could be the adorable frolicking of a spherical squirrel—or anything else the user desires.
The Weird World of Text-to-Video Generators
In addition to those flocking toward AI video generators for design and filmmaking goals, some wish to access Sora for fun. By pushing the limits of prompt details, users can end up with some hilarious—and bizarre—content. From surrealistic bicycle races across oceans to merging with a blanket on a bed, some outputs are enjoyed more for their comedic value than for artistic purposes.
On one hand, the fantastical aspects are enticing for creative types looking for amusement. While, on the other hand, such visuals are sure to make the development of films easier. For instance, if a director wants to shoot a scene set in an alternate reality where animals eat jewelry, there would be tons of animal rights issues—to say the least. However, with access to Sora AI, such scenes can be generated on a computer with no risk whatsoever.
These days, the film industry is much better than it used to be at treating non-humans with compassion on set. If it wasn’t, surely this Golden Retriever podcast would have something to say about it! In all seriousness, text-to-video generators will revolutionize how movies are made.
A Look Into Sora AI’s Technical Processes
To understand how Sora can create stunning vistas and perform magic tricks with a spoon, look at OpenAI’s technical report.
The process starts with compressing image data into spacetime patches that act as transformer tokens. Using layman’s terms: spacetime patches (in this case) are small sections of visual information that have time markers. Transformer tokens are the tiniest tier of data units used in AI training—each patch is a token.
Breaking the process down further:
- Image inputs are identified
- The image inputs are dissected into patches
- Random patches (tokens) are analyzed until all have been processed
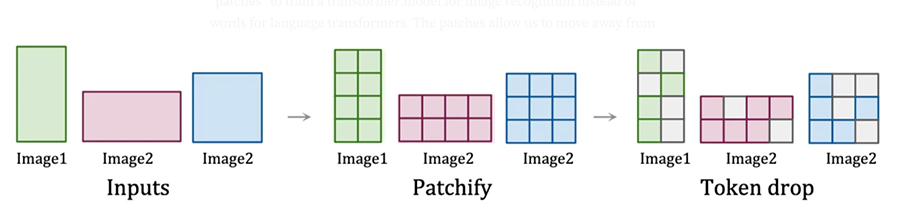
The process of patching and then turning visual data into tokens lets AI models learn efficiently. This lets Sora determine how elements are related, when actions are supposed to happen, as well as a great deal more. In addition, this lets Sora consume visual data from multiple resolutions and aspect ratios. Specifically, the ingestion of images and videos in their native formats trains AI models how to gauge various visual aspects more accurately through the comparison of differences between each token.
With that said, the process doesn’t end here! After the tokens are gobbled up, complex computing runs multiple times per content generation sequence. In the beginning (at base compute), the video created looks abstract. However, as training compute increases, Sora becomes more and more capable of producing visuals analogous to real life.

Author’s Opinion
What’s been seen of Sora so far blows the competition out of the water. Existing text-to-video generators are only viable for inserting a human host into content. Nothing currently on the market can create complex, stunning, and (mostly) realistic videos from only text prompts.
To balance the scales: Sora AI has a long way to go before replacing humans. With that said, it shows incredible promise for many artistic and scientific purposes. Not only can it be a fantastic tool in filmmaking, but it may one day allow scientists to simulate previously impossible scenarios. Yes, Sora’s concept of physics needs to improve a lot before it can be used for the latter reason; however, it—and other AI models like it—will likely get there in a few years.
For instance, imagine a world where the brightest minds can use text-to-video generators to simulate the outcomes of various accidents. Doing so can help researchers create safety suits of unparalleled quality at a fraction of their previous budget. In turn, this would cut down on injuries, medical bills, and hospital operation costs—all of which would benefit society.
However, that’s a way off yet. While leaders in the industry are working on deepening the understanding of Sora and similar models, there are plenty of wacky AI videos to enjoy. Until then, sit back, relax, and plan for the future.
What’s next?
AI tools are helping businesses and individuals to do work faster, and it is cost-effective. For further reading, please get familiar with the following tools.