Building one machine learning model is relatively easy. Creating hundreds or thousands of models and iterating over existing ones is hard.
It is easy to get lost in the chaos. This chaos is worsened when you are working as a team, as you now have to keep track of what everyone is doing. Bringing order to the chaos requires that the whole team follows a process and documents their activities. This is the essence of MLOps.
What is MLOps?
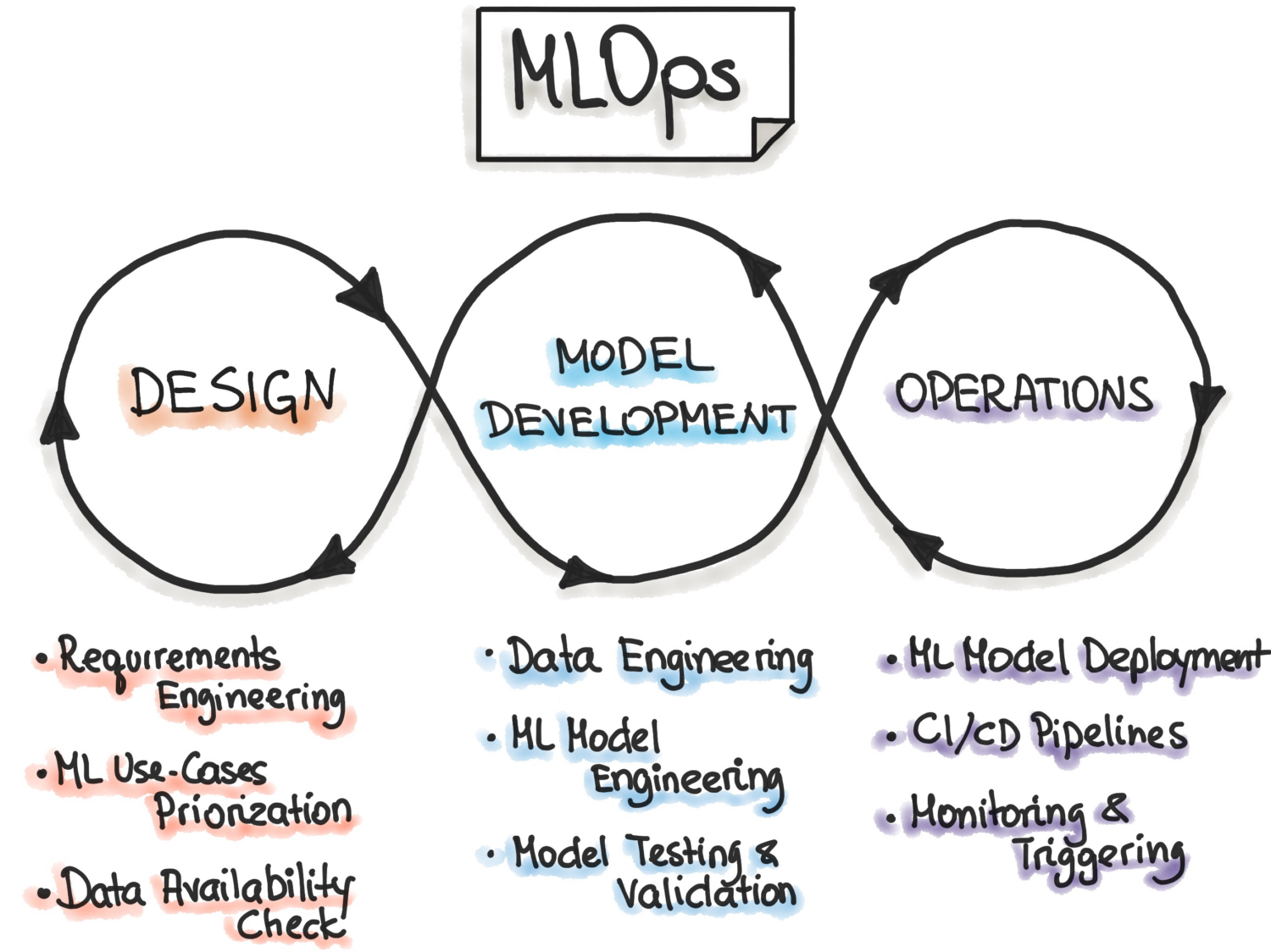
According to MLOps.org, Machine Learning Operationalisation is trying to build an end-to-end Machine Learning Development process to design, build and manage reproducible, testable, and evolvable ML-powered software. Essentially, MLOps is DevOps principles applied to Machine Learning.
Like DevOps, the key idea of MLOps is automation to reduce manual steps and increase efficiency. Also, like DevOps, MLOps includes both Continuous Integration (CI) and Continuous Delivery(CD). In addition to those two, it also includes Continuous Training (CT). The additional aspect of CT involves retraining models with new data and redeploying them.
MLOps is therefore an engineering culture that promotes a methodical approach to machine learning model development and the automation of various steps in the method. The process primarily involves data extraction, analysis, preparation, model training, evaluation, model serving, and monitoring.
Advantages of MLOps
In general, the advantages of applying MLOps principles are the same as the advantages of having Standard Operating Procedures. The advantages are as follows:
- A well-defined process provides a roadmap of all the crucial steps to be taken in model development. This ensures that no critical steps are missed.
- Steps of the process that can be automated can be identified and automated. This reduces the amount of repetitive work and increases the speed of development. It also eliminates human errors while reducing the amount of work that has to be done.
- It becomes easier to assess progress in a model’s development by knowing what stage of the pipeline the model is in.
- It’s easier for teams to communicate as there is a shared vocabulary for steps to be taken during development.
- The process can be applied repeatedly to developing many models, providing a way to manage the chaos.
So ultimately, the role of MLOps in machine learning is to provide a methodical approach to model development that can be automated as much as possible.
Platforms for Building Pipelines
To help you implement MLOps in your pipelines, you can use one of the many platforms we will discuss here. While the individual features of these platforms may be different, they essentially help you do the following:
- Store all your models along with their associated model metadata – such as configurations, code, accuracy, and experiments. It also includes the different versions of your models for version control.
- Store dataset metadata, such as data that was used to train models.
- Monitor models in production to catch problems such as model drift.
- Deploy models to production.
- Build models in low-code or no-code environments.
Let’s explore the best MLOps platforms.
MLFlow

MLFlow is perhaps the most popular Machine Learning Lifecycle management platform. It is free and open source. It provides the following features:
- tracking for recording your machine learning experiments, code, data, configurations, and final results;
- projects for packaging your code in a format that is easy to reproduce;
- deployment for deploying your machine learning;
- a registry for storing all your models in a central repository
MLFlow integrates with popular machine learning libraries such as TensorFlow and PyTorch. It also integrates with platforms such as Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning, and Databricks. It also works with different cloud providers such as AWS, Google Cloud, and Microsoft Azure.
Azure Machine Learning
Azure Machine Learning is an end-to-end machine learning platform. It manages the different machine lifecycle activities in your MLOPs pipeline. These activities include data preparation, building and training models, validating and deploying models, and managing and monitoring deployments.
Azure Machine Learning allows you to build models using your preferred IDE and framework of choice, PyTorch or TensorFlow.
It also integrates with ONNX Runtime and Deepspeed to optimize your training and inference. This improves performance. It leverages AI infrastructure on Microsoft Azure that combines NVIDIA GPUs and Mellanox network to help you build machine learning clusters. With AML, you can create a central registry to store and share models and datasets.
Azure Machine Learning integrates with Git and GitHub Actions to build workflows. It also supports a hybrid or multi-cloud setup. You can also integrate it with other Azure services such as Synapse Analytics, Data Lake, Databricks, and Security Center.
Google Vertex AI

Google Vertex AI is a unified data and AI platform. It provides you with the tooling you need to build custom and pre-trained models. It also serves as an end-to-end solution for implementing MLOps. To make it easier to use, it integrates with BigQuery, Dataproc, and Spark for seamless data access during training.
In addition to the API, Google Vertex AI provides a low-code and no-code tooling environment so that it can be used by non-developers such as business and data analysts and engineers. The API enables developers to integrate it with existing systems.
Google Vertex AI also enables you to build generative AI apps using Generative AI Studio. It makes deploying and managing infrastructure easy and fast. The ideal use cases for Google Vertex AI include ensuring data readiness, feature engineering, training, and hyperparameter tuning, model serving, model tuning and understanding, model monitoring, and model management.
Databricks

Databricks is a data lakehouse that enables you to prepare and process data. With Databricks, you can manage the entire machine-learning lifecycle from experimentation to production.
Essentially Databricks provides managed MLFlow providing features such as data logging ad version of ML models, experiment tracking, model serving, a model registry, and ad metric tracking. The model registry enables you to store models for reproducibility, and the registry helps you keep track of versions ad the stage of the lifecycle they are in.
Deploying models using Dataricks can be done with just a single click, and you will have REST API endpoints to use to make predictions. Among other models, it integrates well with existing pre-trained generative and large language models, such as those from the hugging face transformers library.
Dataricks provides collaborative Databricks notebooks that support Python, R, SQL, and Scala. In addition, it simplifies managing infrastructure by providing preconfigured clusters that are optimized for Machine Learning tasks.
AWS SageMaker

AWS SageMaker is an AWS Cloud Service that provides you with the tools you need to develop, train and deploy your machine learning models. The primary purpose of SageMaker is to automate the tedious and repetitive manual work involved in building a machine-learning model.
As a result, it gives you tools to build a production pipeline for your machine-learning models using different AWS services, such as Amazon EC2 instances and Amazon S3 storage.
SageMaker works with Jupyter Notebooks installed on an EC2 instance alongside all the common packages and libraries needed to code a Machine Learning model. For data, SageMaker is capable of pulling data from Amazon Simple Storage Service.
By default, you get implementations of common machine learning algorithms such as linear regression and image classification. SageMaker also comes with a model monitor to provide continuous and automatic tuning to find the set of parameters that provide the best performance for your models. Deployment is also simplified, as you can easily deploy your model to AWS as a secure HTTP endpoint that you can monitor with CloudWatch.
DataRobot
DataRobot is a popular MLOps platform that allows management across different stages of the Machine Learning lifecycle, such as data preparation, ML experimentation, validating, and governing models.
It has tools to automate running experiments with different data sources, test thousands of models and evaluate the best ones to deploy to production. It supports building models for different types of AI models for solving problems in Time Series, Natural Language Processing, and Computer Vision.
With DataRobot, you can build using out-of-the-box models, so you do not have to write code. Alternatively, you can opt for a code-first approach and implement models using custom code.
DataRobot comes with notebooks to write and edit the code. Alternatively, you can use the API so you can develop models in an IDE of your choice. Using the GUI, you can track the experiments of your models.
Run AI

Run AI attempts to solve the problem of underutilization of AI infrastructure, in particular GPUs. It solves this problem by promoting the visibility of all infrastructure and making sure it is utilized during training.
To perform this, Run AI sits between your MLOps software and the firm’s hardware. While occupying this layer, all training jobs are then run using Run AI. The platform, in turn, schedules when each of these jobs is run.
There is no limitation to whether the hardware has to be cloud-based, such as AWS and Google Cloud, on-premises, or a hybrid solution. It provides a layer of abstraction to Machine Learning teams by functioning as a GPU virtualization platform. You can run tasks from Jupyter Notebook, bash terminal, or remote PyCharm.
H2O.ai
H2O is an open-source, distributed machine learning platform. It enables teams to collaborate and create a central repository for models where data scientists can experiment and compare different models.
As an MLOps platform, H20 provides a number of key features. First, H2O also simplifies model deployment to a server as a REST endpoint. It provides different deployment topics such as A/B Test, Champoion-Challenger models, and simple, single-model deployment.
During training, it stores and manages data, artifacts, experiments, models, and deployments. This allows models to be reproducible. It also enables permission management at group and user levels to govern models and data. While the model is running, H2O also provides real-time monitoring for model drift and other operational metrics.
Paperspace Gradient
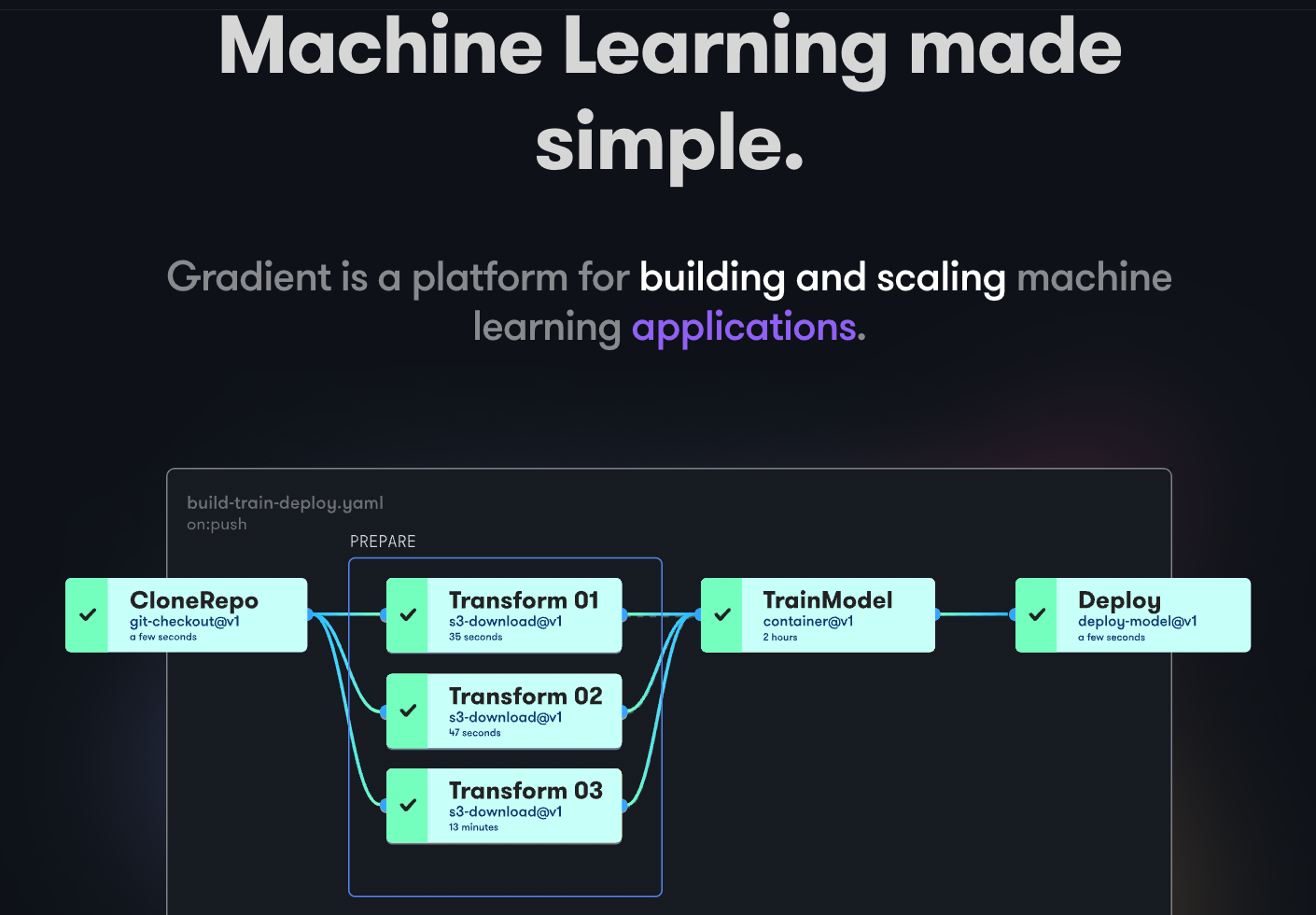
Gradient helps developers at all stages of the Machine Learning development cycle. It provides Notebooks powered by the open-source Jupyter for model development and training on the cloud using powerful GPUs. This allows you to explore and prototype models quickly.
Deployment pipelines can be automated by creating workflows. These workflows are defined by describing tasks in YAML. Using workflows makes creating deployments and serving models easy to replicate and, therefore, scaleable as a result.
As a whole, Gradient provides Containers, Machines, Data, Models, Metrics, Logs, and Secrets to help you manage different stages of the Machine Learning model development pipeline. Your pipelines run on Gradiet clusters. These clusters are either on Paperspace Cloud, AWS, GCP, Azure, or any other servers. You can interact with Gradient using CLI or SDK programmatically.
Final Words
MLOps is a powerful and versatile approach to building, deploying, and managing machine learning models at scale. MLOps is easy to use, scalable, and secure, making it a good choice for organizations of all sizes.
In this article, we covered MLOPs, why it is important to implement them, what is involved, and the different popular MLOps platforms.
Next, you may want to read our comparison of Dataricks vs. Snowflake.