Modern businesses are increasingly relying on integrated systems within the AWS (Amazon Web Services) cloud to deliver robust and scalable solutions. However, ensuring optimal performance in these integrated systems can be a complex task.
Optimizing your AWS cloud system for maximum efficiency can help you improve performance, reduce costs, and enhance overall operational effectiveness.
This article will discuss key strategies, such as load balancing, auto-scaling, caching, and data load strategies, for improving the performance of integrated systems within the AWS cloud.
What is Optimization in the AWS Cloud
Optimization in the AWS cloud refers to activities that improve the performance, effectiveness, and running costs of cloud-based systems and processes. You should focus on areas where improvement can be made easily while also ensuring the security of your existing system.

If the level of effort required for improvement becomes too high, it is no longer considered optimization. In such cases, it is referred to as system refactoring.
Refactoring is usually a way more costly process, which substantially changes the existing technical solution because it does not fulfill the requirements anymore. That’s why we should plan the incremental updates of the system in such a way we minimize those refactoring needs over time.
So, the ultimate target of system optimization is to implement strategies to achieve better results with minimal additional costs. You can also look at that process, like finding ways for cost reduction without compromising performance. You can achieve some parts of this target even without changing the source code.
For example, through strategies such as rightsizing instances or leveraging spot instances for non-critical workloads. You can also implement various cost optimization strategies and tools provided by AWS, which will give you further useful hints proactively.
Additionally, you can look at your current utilization of the AWS pricing model in the architecture and make changes to make it more effective. AWS even defines cost optimization as one of the performance efficiency pillars of a well-architected framework.
All such actions will delay or even completely remove the necessity of system refactoring in the long run.
It’s very important to find the right balance between how much you optimize resource usage and minimizing unused resources that lead to potential cost savings. That balance is implemented by taking into account resource usage patterns applicable to your application and the way how it is used.
That means you can always increase compute instances, storage, or networking services to achieve the desired performance levels. However, you should always check if the upgrade benefits you acquired cost less than the sum of costs you managed to save with such an architecture change.
Main Aspects of AWS Optimization
When looking at optimization in the AWS cloud, some of the aspects are more important than others. Let’s have a look at those that I found to be usually on the top of the list for the majority of optimization initiatives.
#1. Apply Load Balance Where Feasible
Load balancing plays a crucial role in distributing incoming traffic across multiple resources to ensure optimal performance. When designing the architecture, you should consider load balancing as many parts of the system as possible.
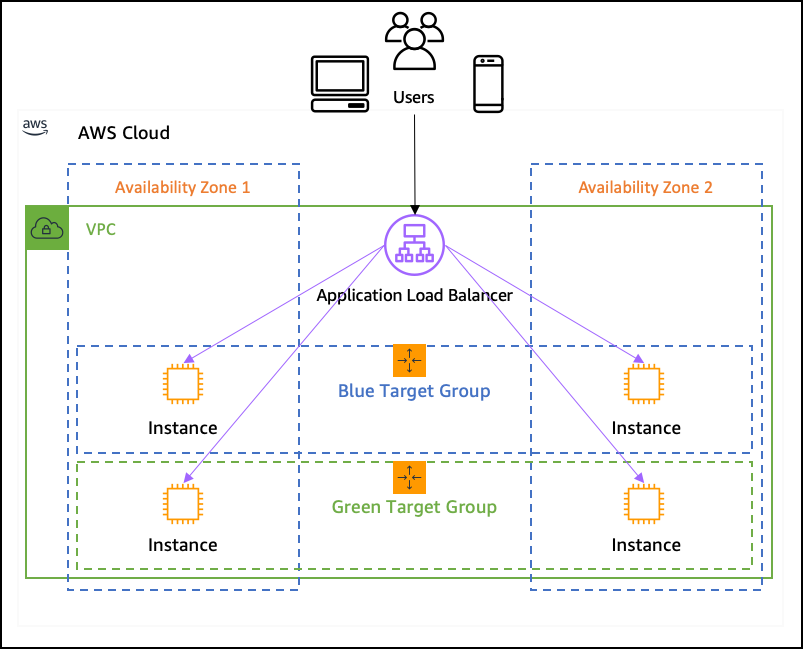
Systems are only getting more complex over time. You can’t predict how it will evolve in the course of the next several years. With the load balancing techniques, you can better prepare the platform for such growth going forward.
AWS offers Elastic Load Balancing (ELB) services that automatically distribute incoming traffic to multiple instances. Load balancing helps prevent any single resource from becoming overwhelmed, thus improving system performance. It does not even need to cost more because you can afford smaller instances in case of one big and powerful instance.
You can apply load balancing even on the network level (independently from the applications themselves) using gateway load balancers. This will spread the load across several firewalls or intrusion detection infrastructure components, making your entire platform more secure.
In AWS, you can design many instances as serverless instead of being standard Amazon EC2 instances (which generate costs constantly unless you shut them down), which means those additional instances don’t consume any costs if there is nothing to process unless they are actually in operations (which means in case of increased loads).
#2. Enable Auto-Scaling Where Reasonable
Auto-scaling allows your system to automatically adjust its capacity based on the incoming traffic. It can go both ways – upwards and downwards. AWS Auto Scaling is a specific functionality not every major cloud provider has, even today.
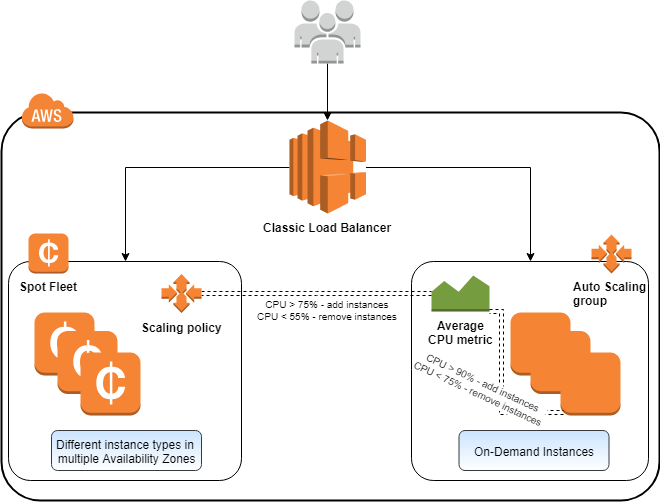
You can define scaling policies that automatically add or remove instances based on predefined conditions. This usually refers to horizontal scaling, when you start up one or more instances and then add it to the processing chain based on the current load.
Vertical scaling is also possible. That is when you change the configuration of existing instances to higher specs, such as a higher CPU specification, memory, or drive space. This is much easier to do in the cloud environment as you don’t need to deal with any physical hardware. The underlying hardware required to execute such vertical scaling is all managed by AWS, and you don’t need to worry about that at all.
The scaling will then (in line with your policies) scale up or scale down depending on how much traffic must be processed. The good thing is that once set, you don’t need to sit and watch the scaling processes.
They will automatically adjust. If you define the policies effectively and well-tailored to your usual processing volume, you will save on infrastructure costs overall. After that, you won’t pay for additional instances when they are not necessary.
Also, you won’t process the data too long if there is a load peak. Your system will handle varying computer workloads efficiently, improving performance during peak times and reducing cloud costs during low-demand periods.
#3. Caching Principles
Caching is a technique that stores frequently accessed data in a cache (related to some specific cloud service), reducing the need to fetch it from the original source repeatedly.
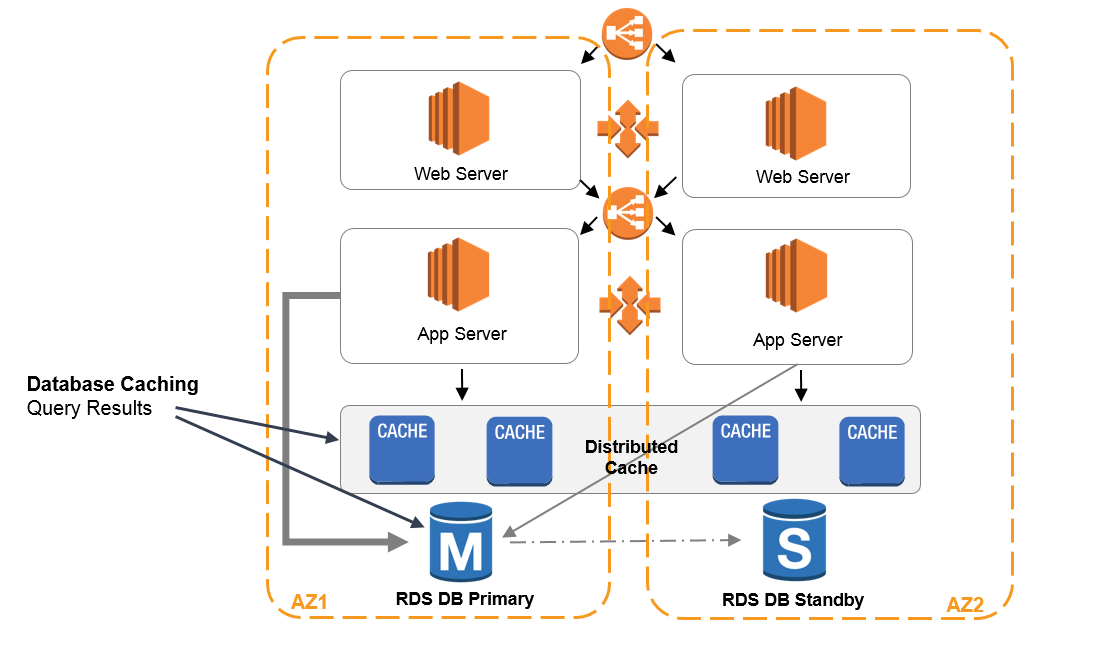
Amazon Web Services contains Amazon ElastiCache web service. It’s a fully managed in-memory caching service that supports popular caching engines like Redis and Memcached. You can leverage it and integrate it into your system architecture in the specific places where the user extracts the data very often.
With such caching strategies, you can significantly reduce the response time and improve the overall performance of your integrated systems. However, one area to carefully look at is to ensure the data you are reading are always up to date concerning the source system.
Although caching will enable much faster reads for the end users, it won’t be of much benefit if the data is already obsolete. In order to avoid that, you should consider the following caching properties:
- One way to ensure data freshness is by setting an expiration time or Time-to-Live (TTL) for cached data. When data reaches its expiration time, the cache is invalidated, and the next request will fetch the updated data from the source. If you set the appropriate TTL, you can balance the trade-off between data freshness and cache performance.
- Cache invalidation is a technique used to keep data up to date. When the underlying data changes, the cache needs to be invalidated to fetch the latest data from the source. AWS provides various mechanisms to trigger cache invalidation. For example, you can program AWS Lambda functions to do that or integrate cache invalidation with your application’s data update process.
- The cache-aside pattern means fetching data from the cache only if it exists. If not, retrieve it from the source and populate the cache. When updating data, the cache is invalidated, and subsequent requests will fetch the updated data from the source. This pattern ensures that the cache remains up to date while minimizing the impact on performance.
- The cache-through pattern updates the cache whenever there is a data update in the source. When there is a write operation on the source side, the cache is updated at the same time. This guarantees that the cache will always have the most up-to-date data, but it can result in additional overhead due to the requirement for synchronous updates.
- Maintaining cache coherency and consistency is crucial to ensure data remains up to date. You can achieve that by implementing proper synchronization mechanisms when updating data. This is how you avoid inconsistencies between the cache and the source. AWS provides services like Amazon ElastiCache, which will give you out-of-the-box features like cache replication and consistency models to ensure data integrity.
Effective Data Load Strategies
When integrating operating systems within the AWS cloud, it is essential to consider what data load strategies you will apply. Now, we are not talking that much about how fast the data refresh is happening (whether in real-time or batch-wise).
It’s more about how much data I need to process every time on the target side to get relevant results. Usually, the final choice is between full data load and incremental data load.
#1. Full Data Load Strategy
A full data load strategy will give you the benefit of simplistic and easy implementation difficulty. This is what I can see the project teams tend to do often.
The advantage of the shortest time to production (and lowest cost requirements for the initial version) is so tempting that the client and project teams alike are rarely eager to explore more options.
In a full data load strategy, you want to transfer all the data from the source system to the target system. This approach is very suitable for initial data synchronization or when you simply need to refresh the entire dataset. However, it can be time-consuming and resource-intensive. Sometimes, it is still the best strategy. For example, if the data on the source is frequently changing dramatically.
Let’s say that over 50% of all the data is changed before every next loading process in your architecture. In this case, it absolutely makes sense to implement the full data load process.
However, what if the source system changes only a small percentage of the whole data set now and then? And what if you scheduled to run the loading process every hour or even more frequently?
Those are the cases where a full data load means an absolute waste of time, high resource usage, storage cost, computing power, and money all at the same time. It might still be faster to implement, but in the long run, it will be significantly more costly than incremental load would be.
#2. Incremental Data Load Strategy
In an incremental data load strategy, you want to transfer only the changes or updates since the last synchronization run. This approach greatly reduces the amount of data that must be transferred between the systems or stored while the transfer is being executed.
Incremental data load strategy results in faster synchronization and improved performance metrics. It is ideal for scenarios where frequent updates occur.
However, Incremental load usually requires a much more sophisticated approach. It demands clever architecture design and sometimes even synchronizing well all the connecting processes that you require to accomplish the loading processes.
There’s also a much higher chance that you miss some portion of the data changes during the processes. This mostly happens if the source system is outside of your platform and direct responsibility.
In that case, obviously, you can’t have full control over processes that happen in the source system. You need to rely on good communication with the external vendor and make sure to update the integration patterns whenever the change in the source system happens.
Otherwise, you might not be getting the full set of last data increments. And maybe you don’t even know about that. That can happen if the change in the source system is of such a nature that all the existing interfaces and interconnections are still working flawlessly despite fetching less data than they should now.
Practical Example of AWS Optimization Process
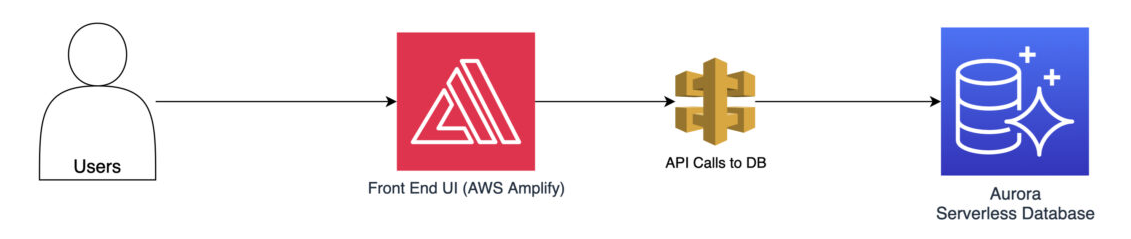
Let’s consider a real-world example to illustrate the practical application of these techniques. Imagine a popular shopping website hosted on AWS. During peak shopping seasons, the website is under extremely heavy traffic load, which leads to significantly slower response times. Potentially, it can even cause sporadic downtimes.
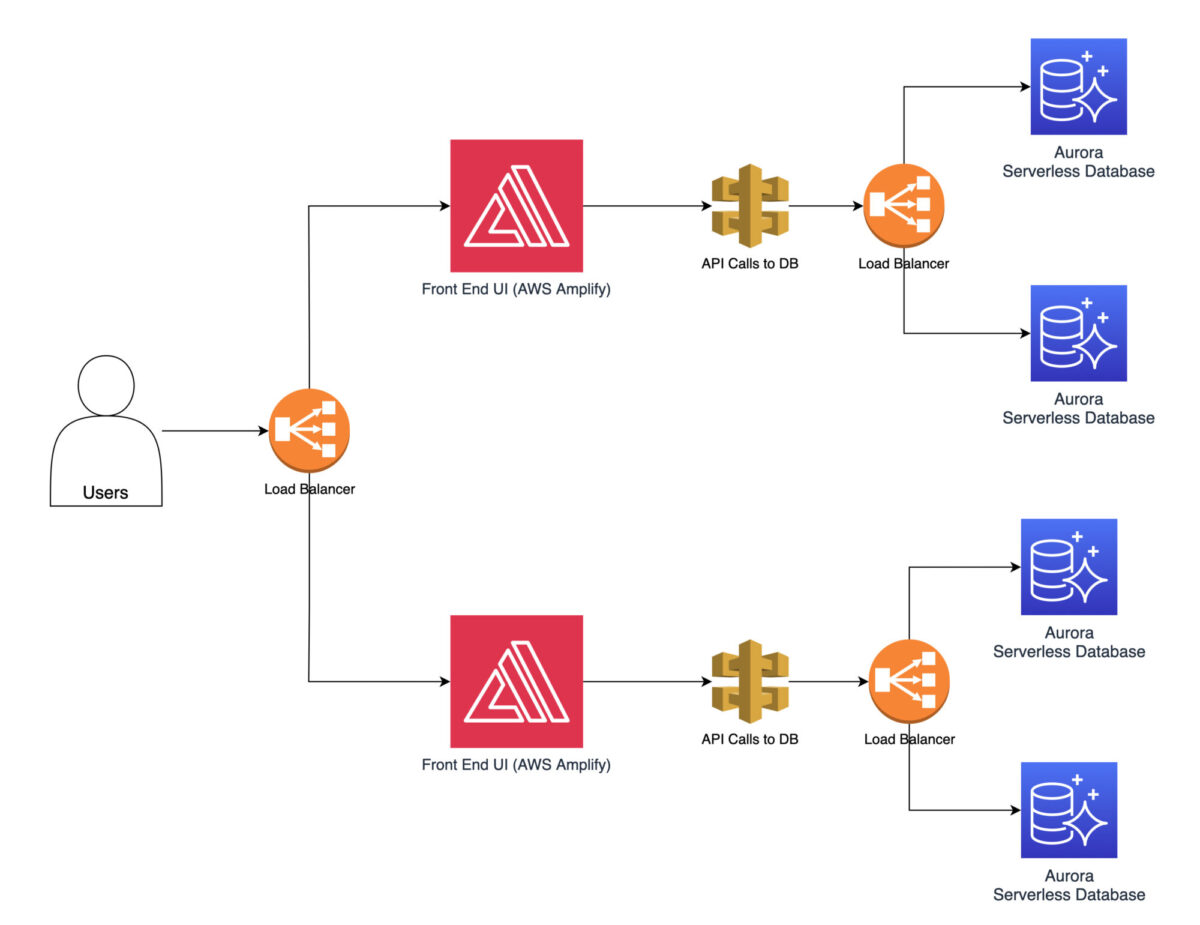
As a first step in performance optimization, you can implement load balancing using AWS Elastic Load Balancer. This ensures that you distribute incoming traffic evenly across multiple instances. This prevents the instances from becoming overwhelmed.
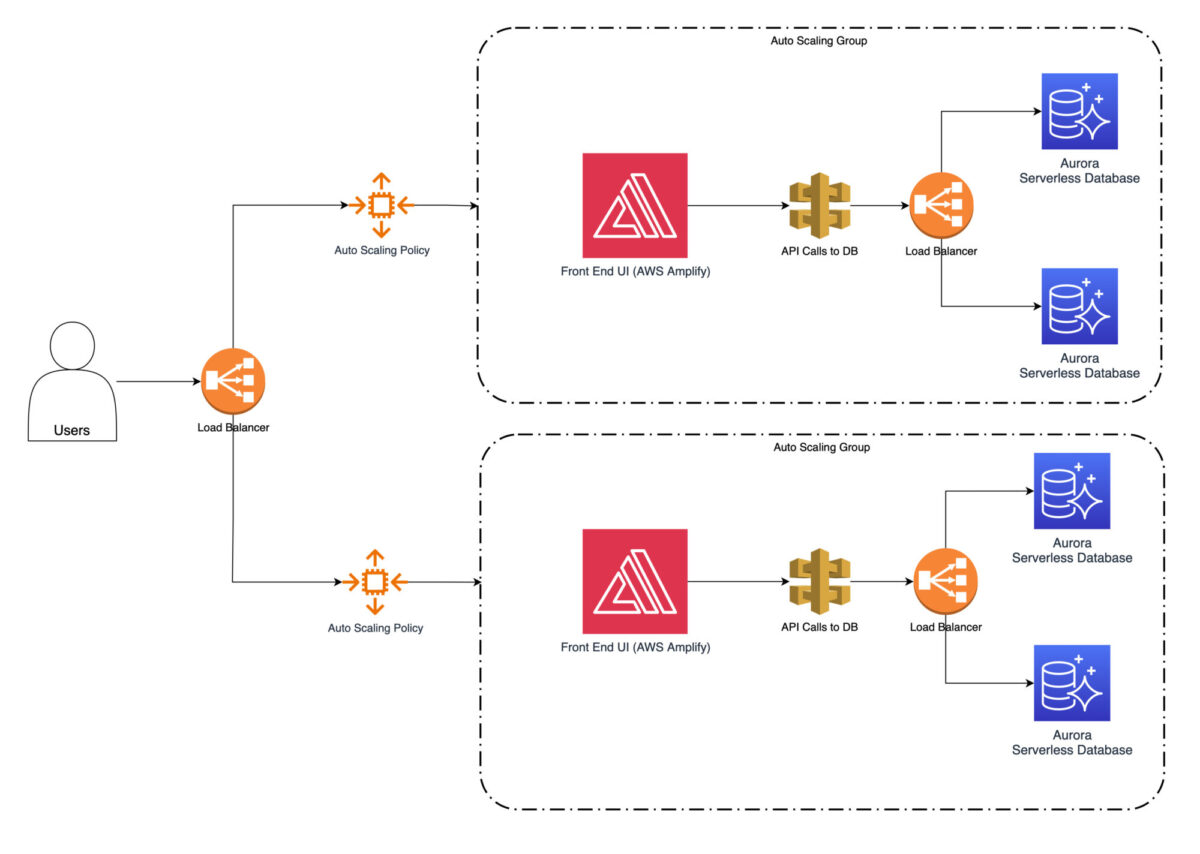
As a next step, you can configure auto-scaling to automatically add more instances during peak times and remove them during low-demand periods. This ensures that the website can handle the increased traffic and maintain optimal performance.
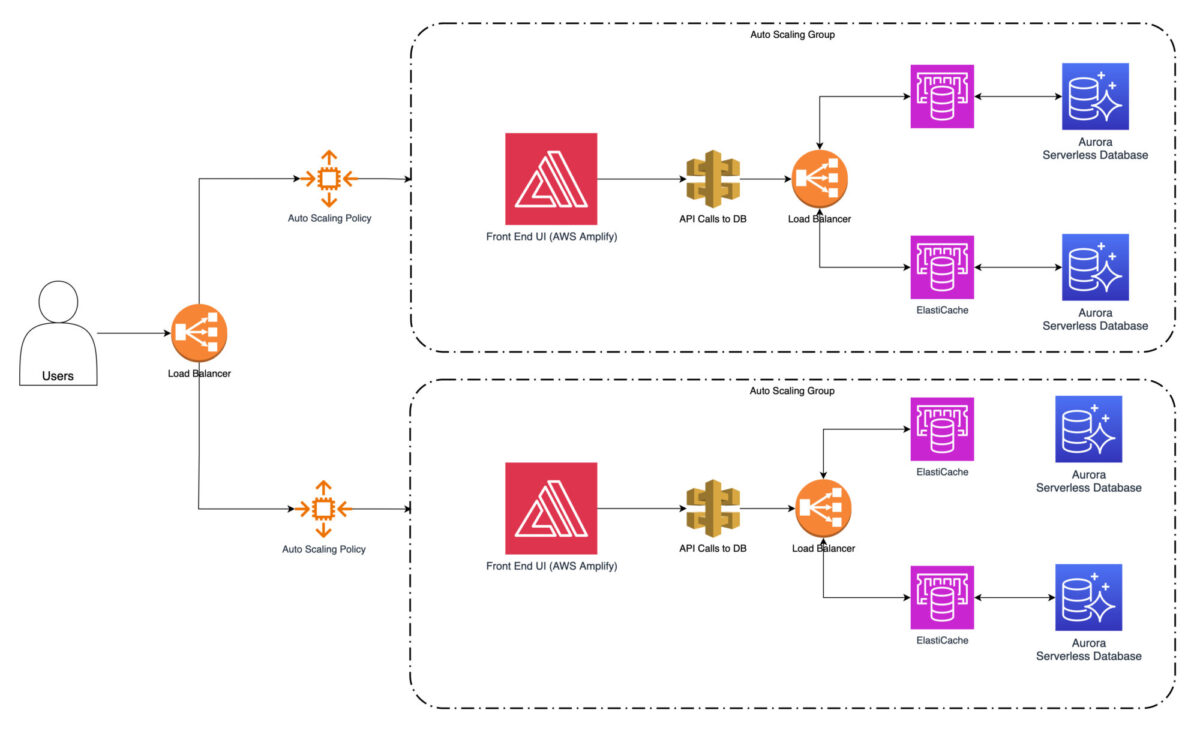
Finally, there is still a place for implementing caching strategies using Amazon ElastiCache, which will further reduce the time necessary to fetch the data from the source. Frequently accessed data, such as product information or user preferences, can be cached.
There is no big risk even with data being up to date, as such information is only very rarely changing. It will greatly reduce the need to fetch it from the database services repeatedly. This significantly improves response times and overall operating system performance.
Concluding Thoughts: Maximizing AWS Cloud Integration Efficiency
Optimizing performance in AWS cloud system integration and overcoming performance issues is an ongoing task. As your platform evolves, you should revisit the AWS architecture regularly.
To maintain optimal performance, it is advisable to regularly review the AWS architecture and implement techniques like load balancing, auto-scaling, caching strategies, and selecting the appropriate data load strategy.
The AWS optimization strategies and techniques discussed here are not just theoretical but can be put into practice in real-world projects. You can use these AWS optimization strategies to achieve high-performance integrated systems that meet the requirements of the digital landscape in today’s business world.