Your one-stop explainer on Deepfakes and to make them easily with Faceswap.
Deepfakes consist of using artificial intelligence and deep learning-based techniques to change audio or video content in a video through manipulation of the same. Artificial Intelligence isn’t that ‘artificial’ anymore. These times have put it dangerously close to us humans.
It can suggest, write, create art, and now looks and talks like the living.
This is one of the most recent developments in this domain we should take advantage of. However, this is also one we must beware of.
This article is purely for educational purpose – for you to know how people create Deepfakes. Geekflare does not endorse creating Deepfakes for deception or unethical purposes.
What Are Deepfakes?
The word Deepfake is coined by combining deep learning and fake. In simple terms, you can also assume this is expertly manipulated or deeply faked media.
As per Wikipedia, this is also known as synthetic media in which an existing image, audio, or video is modified to represent someone else entirely.
Typically, deepfakes make renowned personalities appear to say something they otherwise wouldn’t.
Based on its creator’s skill, it can be extremely tough to tell if it’s real or fake.
How Deepfakes Work?
Put simply, a part of the original video (say a face) is replaced by a similar looking fake. In such a case, it can also be called a faceswap, like in this Deepfake ‘Obama’ video.
However, it’s not limited to video alone, and we have deepfakes images and audio as well (and who knows, deepfake VR avatars in the near future).

The working methodology behind such trickeries primarily depends on the application and the underlying algorithm.
As per this research paper by Disney, there are various techniques, including encoders-decoders, Generative Adversarial Networks (GANs), Geometry-based deepfakes, etc.
However, the following sections are majorly affected by how it works with Facewap. This is a free and open-source Deepfake software that allows for multiple algorithms to get the expected result.
There are three major processes to generate deepfakes: extraction, training, and conversion.
#1. Extraction
This is about detection and squeezing out the subject area of interest from media samples, the original and the one for the swap.
Based on the hardware capabilities, there can be many algorithms to opt for efficient detection.
For instance, Faceswap has a few different options for extraction, alignment, and masking based on CPU or GPU efficiency.
Extraction simply identifies the face in the overall video. Alignment spots crucial features of any face (eyes, nose, chin, etc.). And lastly, masking blocks out other elements of the image except for the area of interest.
The overall time taken for the output is important in selecting any option, as choosing resource-intensive algorithms on mediocre hardware can result in failure or a substantially long time to render acceptable results.
Besides the hardware, the choice also depends on the parameters like whether the input video suffers from facial obstructions like hand movements or glasses.
A necessary element, in the end, is cleaning (explained later) the output, as the extractions will have a few false positives.
Ultimately, the extraction is repeated for the original video and the fake (used for swapping).
#2. Training
This is the heart of creating deepfakes.
Training is about the neural network, which consists of the encoder and decoder. Here, the algorithms are fed the extracted data to create a model for the conversion later.
The encoder converts the input into a vector representation to train the algorithm to recreate the faces back from vectors, as done by the decoder.
Afterward, the neural network evaluates its iterations and compares them with the original by assigning a loss score. This loss value falls over time as the algorithm keeps iterating, and you stop when the previews are acceptable.
Training is a time-consuming process, and the outputs generally improve based on the iterations it performs and the quality of input data.
For instance, Faceawap suggests a minimum of 500 images each, original and for swap. In addition, the images should differ significantly among themselves, covering all possible angles in unique lighting for the best recreation.
Owning to the training length, some applications (like Faceswap) allow one to stop the training midway or continue later.
Notably, the photo-realism of the output also depends on the algorithm’s efficiency and the input. And one is again restricted by the hardware capabilities.
#3. Conversion
This is the last chapter in the deepfake creation. The conversion algorithms need the source video, the trained model, and the source alignment file.
Subsequently, one can change a few options relating to color correction, mask type, desired output format, etc.
After configuring these few options, you just wait for the final render.
As mentioned, Faceswap works with many algorithms, and one can play between to get a tolerable faceswap.
Is that all?
No!
This was just face swapping, a subset of deepfake technology. Face swapping, like the literal meaning, only replaces a portion of the face to give a faint idea about what deepfakes could do.
For a credible swap, you might also need to mimic the audio (better known as voice cloning) and the entire physique, including everything that fits in the frame, like this deepfake video of Morgan Freeman.
So, what’s at play here?
What might have happened is that the deepfake author shot the video himself (as indicated in the last few seconds), lip-synced the dialogue with Morgan Freeman’s synthetic voice, and replaced his head.

Conclusively, it’s not just about faceswap but the whole frame, including the audio.
You can find tons of deepfakes on YouTube to the point it becomes scary about what to trust. And all it takes is a power-packed computer with an efficient graphics card to begin.
However, perfection is hard to achieve, and it’s especially true with deepfakes.
For a convincing deepfake that can mislead or wow the audience takes skill and a few days to weeks of processing for a minute or two of a video, though artificial intelligence face swap tools do make the task easier.
Interestingly, that’s how capable these algorithms are as of now. But what the future holds, including how effective these applications can be on lower-end hardware, is something that has made entire governments nervous.
However, we won’t dive into its future repercussions. Instead, let’s check how to do it yourself for little fun.
Creating (Basic) Deepfake Videos
You can check many applications available to make deepfake videos. One of them is Faceswap, which we’ll be using.
There are a few things we’ll ensure before proceeding. First, we should have a good-quality video of the target depicting varying emotions. Next, we’ll need a source video to swap onto the target.
In addition, close all the graphic card intensive applications like browsers or games before proceeding with Faceswap. This is especially true if you have less than 2 gigs of VRAM (video RAM).
Step 1: Extracting Faces
The first step in this process is extracting the faces from the video. For this, we have to select the target video in the Input Dir and list an Output Dir for the extractions.

In addition, there are a few options, including detector, aligner, masker, etc.; the explanations for each are in the Faceawap FAQs, and it would be a waste to rehash the information here.

It’s generally good to review the documentation for a better understanding and a decent output. However, there are helpful texts within Faceswap you can find by hovering over the specific option.

Put simply, there is no universal way, and one should start with the best algorithms and work their way down successfully to create a convincing deepfake.
For context, I used Mtcnn (detector), Fan (aligner), and Bisenet-Fp (masker) while keeping all the other options as-is.
Originally, I tried it with S3Fd (best detector) and a few other masks combined. However, my 2Gb Nvidia GeForce GTX 750Ti couldn’t bear the brunt, and the process failed repeatedly.
Finally, I toned down my expectations and the settings to see it through.
Besides selecting the appropriate detector, maskers, etc., there are a few more options in Settings > Configure Settings which help tweak individual settings further to help the hardware.

Put simply, select the lowest possible Batch-Size, Input Size, and Output Size, and check LowMem, etc. These options aren’t available universally, and it’s based on a specific section. Additionally, the help texts further aid in selecting the best options.
Though this tool does an excellent job of extracting faces, the output frames can have much more than required to train (discussed later) the model. For instance, it will have all the faces (if the video has more than one) and some improper detections not having the target face at all.
This leads to cleaning the datasets. Either one can check the output folder and delete oneself or use the Faceswap sorting to get some help.
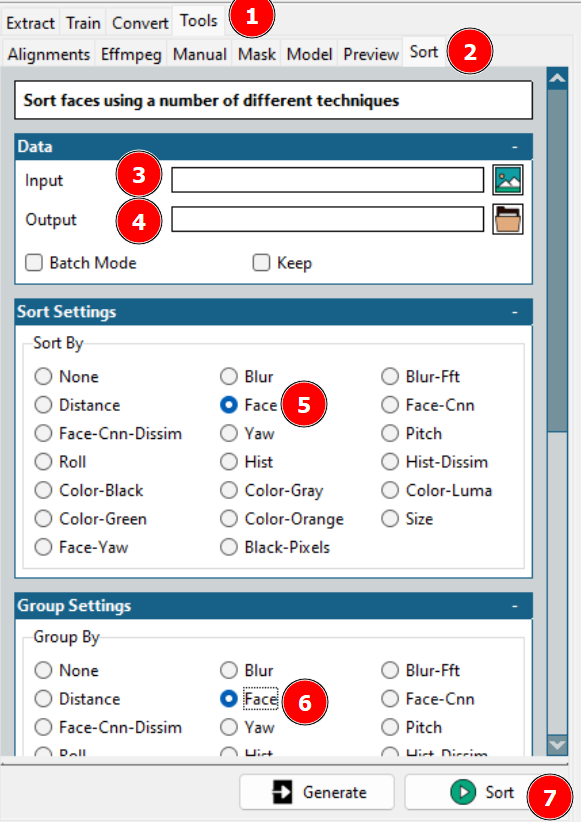
Using the aforementioned tool will arrange different faces in sequence from where you can club the necessary ones together in a single folder and delete the rest.
As a reminder, you’ll also want to repeat extraction for the sourced video.
Step 2: Training the Model
This is the longest process in creating a deepfake. Here, Input A refers to the target face, and Input B is about the source face. Besides, the Model Dir is where the training files will be saved.
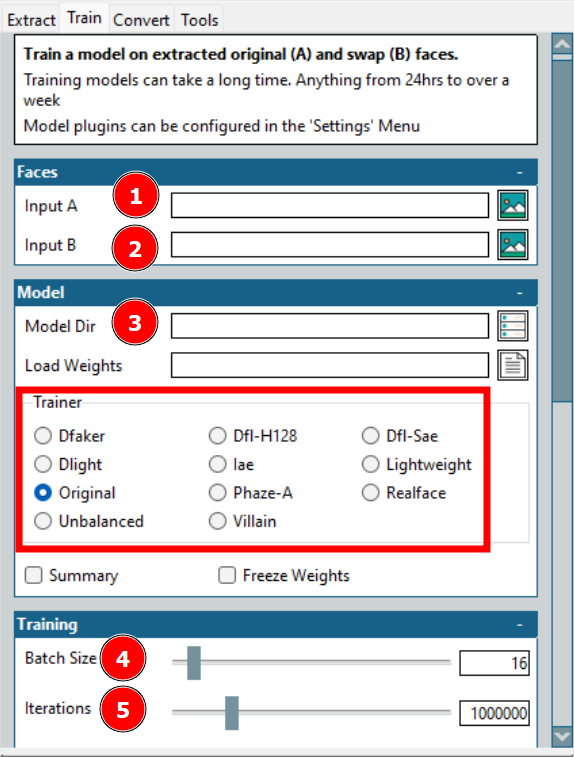
Here the most significant option is Trainer. There are plenty with individual scaling options; however, what worked for my hardware is Dfl-H128 and Lightweight trainers with the lowest configuration settings.
Next is the batch size. A higher batch size reduces the overall training time but consumes more VRAM. Iterations have no fixed effect on the output, and you should set a high enough value and stop the training once the previews are acceptable.
There are a few more settings, including creating a timelapse with preset intervals; however, I trained the model with the bare minimum.
Step 3: Swapping Onto Original
This is the last feat in the deepfake creation.
This generally doesn’t take as much time, and you can play with many options to get the desired output quickly.
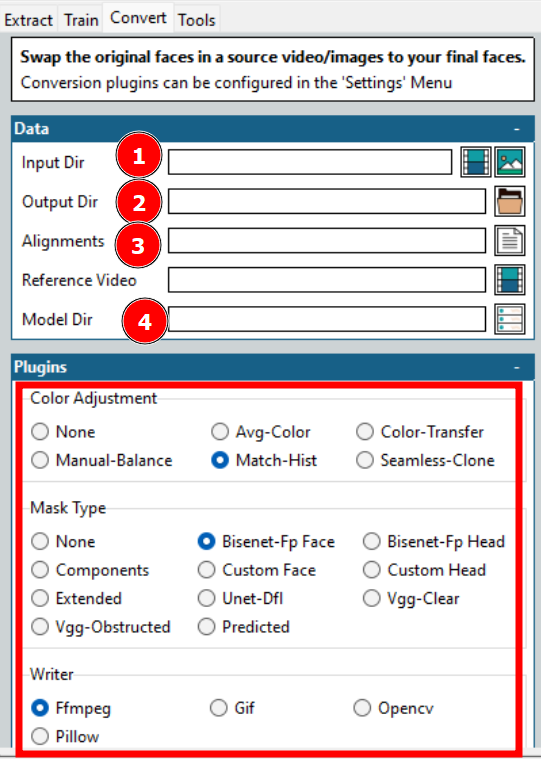
As indicated in the above image, these are a few options one needs to opt for to start the conversion.
Most options are already discussed, like the Input and Output directory, Model directory, etc. One crucial thing is the Alignments which refers to the alignment file (.fsa) of the target video. It gets created in the Input Directory during the extraction.
The Alignments field can be left blank if that specific file hasn’t been moved. Otherwise, one can select the file and move on to other options. However, remember to clean the alignment file if you have cleaned the extractions earlier.
For this, this mini tool lies in the Tools > Alignments.
Start by selecting the Remove-Faces in the Job section, select the original alignment file and the cleaned target faces folder, and click the Alignments at the bottom right.
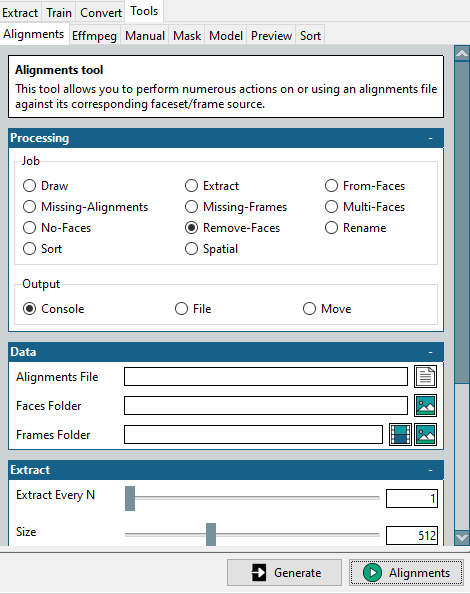
This will create a modified alignment file, matching the optimized faces folder. Please remember we need this for the target video, which we want to swap into.
A few more configurations include the color adjustment and mask type. Color adjustment dictates the mask blending, and you can try a few, check the preview, and select the optimal option.
Mask type is more important. This, again, depends on your expectations and the available hardware. Typically, you also need to consider the input video characteristics. For instance, Vgg-Clear works well with frontal faces without obstructions, whereas Vgg-Obstructed can also do with obstructions, such as hand gestures, glasses, etc.
Next, the Writer presents a few choices based on the output you want. For E.g., select Ffmpeg for a video render.
Overall, the key to a successful deepfake is previewing a few outputs and optimizing according to the time availability and the hardware’s potency.
Applications of Deepfake
There are good, bad, and dangerous applications of deepfakes.
The good ones consist of recreating history lessons by the ones that were actually there for greater engagement.
In addition, they are being used by online learning platforms to generate videos from texts.
But one of the greatest beneficiaries will be the film industry. Here, it’ll be easy to picture the actual lead performing stunts, even when it will be the stuntperson risking their life. Additionally, making multi-lingual movies will be easier than ever.
Coming to the bad ones, unfortunately, there are many. The biggest deepfake application to date, as a matter of fact, 96% (as per this Deeptrace report), is in the porn industry to swap celebrity faces onto porn actors.
In addition, deepfakes are also weaponized against ‘standard’ non-celebrity women. Usually, such victims have high-quality photographs or videos on their social media profiles which are used for deepfakes scams.
Another scary application is vishing, aka voice phishing. In one such case, the CEO of a UK-based firm transferred $243,000 on the orders of the ‘CEO’ of its German parent company, only to later find out that it was actually a deepfake phone call.
But what’s even more dangerous is deepfake provoking wars or asking for surrender. A most recent attempt has seen the Ukrainian president, Volodymyr Zelenskyy, telling his forces and people to surrender in the ongoing war. However, the truth this time was given away by the subpar video.
Conclusively, there are many deepfake applications, and it’s just starting out.
This brings us to the million-dollar question…
Is Deepfakes Legal?
This majorly depends on the local administration. Although, well-defined laws, including what’s allowable and what’s not, are yet to be seen.
Still, what’s obvious is it depends on what you’re using the deepfakes for—the intent. There is hardly any harm if you intend to entertain or educate anyone without upsetting the swapping target.
On the other hand, malicious applications should be punishable by law, irrespective of the jurisdiction. Another grey area is copyright infringement which needs proper consideration.
But to reiterate, you should check with your local government bodies about legal deepfake applications.
Keep an Eye Out!
Deepfkaes leverages artificial intelligence to make anyone say things.
Don’t trust anything you see on the internet is the first advice we should act upon. There is tons of misinformation, and their efficacy is only increasing.