Parlons de la base de données de séries temporelles pour la surveillance distribuée.
Une base de données de séries temporelles est optimisée pour les données d’horodatage ou de séries temporelles. Les données de séries temporelles sont des mesures ou des événements qui sont suivis, surveillés, collectés ou agrégés sur une période de temps. Il peut s’agir de données collectées à partir des battements de cœur de capteurs de suivi des mouvements, de mesures JVM provenant d’applications Java, de données de marché, de données de réseau, de réponses d’API, de temps de fonctionnement de processus, etc.
Les bases de données de séries temporelles sont entièrement personnalisées avec des données horodatées, qui sont indexées et écrites efficacement de manière à ce que vous puissiez insérer des données de séries temporelles. Vous pouvez interroger ces données de séries temporelles beaucoup plus rapidement que dans une base de données relationnelle ou NoSQL.
Ces derniers temps, ce type de base de données a gagné en popularité. Et pourquoi pas ? Il fait un travail fantastique pour la surveillance des opérations commerciales et informatiques. La bonne nouvelle, c’est qu’il existe de nombreuses options parmi lesquelles choisir, et la plupart d’entre elles sont open-source.
InfluxDB
InfluxDB est l’une des bases de données de séries temporelles les plus populaires parmi les DevOps, écrite en Go. InfluxDB a été conçue dès le départ pour fournir un moteur d’ingestion et de stockage de données hautement évolutif. Elle est très efficace pour collecter, stocker, interroger, visualiser et prendre des mesures sur des flux de données de séries temporelles, d’événements et de mesures en temps réel.
Il fournit des politiques de sous-échantillonnage et de conservation des données pour permettre de conserver les données de grande valeur et de haute précision en mémoire, et les données de moindre valeur sur disque. Il est construit sur un mode cloud-native pour fournir une évolutivité à travers de multiples topologies de déploiement, y compris les environnements cloud sur site et hybrides.
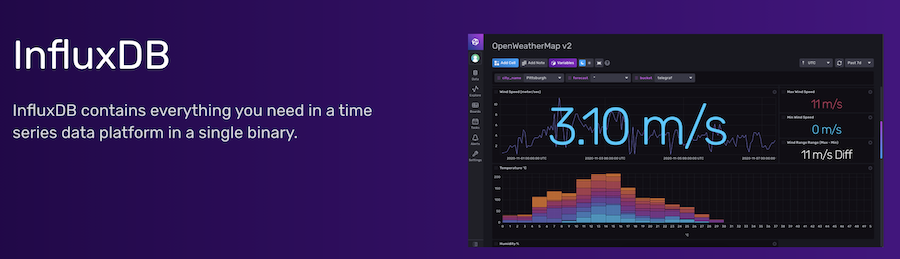
InfluxDB est une solution open-source prête pour l’entreprise. Elle utilise InfluxQL, qui est très similaire à un langage de requête de structure, pour interagir avec les données. La dernière version propose des agents, des tableaux de bord, des requêtes et des tâches dans une boîte à outils. Il s’agit d’un outil tout-en-un pour les tableaux de bord, la visualisation et les alertes.
Caractéristiques
- Haute performance pour les données de séries temporelles avec une ingestion à grande échelle et des requêtes en temps réel
- InfluxQL pour interagir avec les données, qui est un langage d’interrogation de type SQL
- Composant central de la pile TICK (Telegraf, InfluxDB, Chronograf et Kapacitor).
- Support de plugins pour des protocoles tels que collectd, Graphite, OpenTSDB pour l’ingestion de données
- Peut traiter des millions de points de données en seulement une seconde
- Politiques de rétention pour supprimer automatiquement les données périmées
Comme il s’agit d’un logiciel libre, vous pouvez le télécharger et le démarrer sur votre serveur. Cependant, InfluxDB Cloud est disponible sur AWS, Azure et GCP.
Prometheus
Prometheus est une solution de surveillance open-source utilisée pour comprendre les données métriques et envoyer les alertes nécessaires. Elle dispose d’une base de données locale de séries temporelles sur disque qui stocke les données dans un format personnalisé sur le disque.
Le modèle de données de Prometheus est multidimensionnel et basé sur des séries temporelles ; il stocke toutes les données sous forme de flux de valeurs horodatées. Il est très utile lorsque vous travaillez avec des séries temporelles entièrement numériques. La collecte et l’interrogation de données microservices est l’un des points forts de Prometheus.
Il s’intègre étroitement avec Grafana pour la visualisation et si vous êtes un débutant, lisez cet article d’introduction à Prometheus et Grafana.
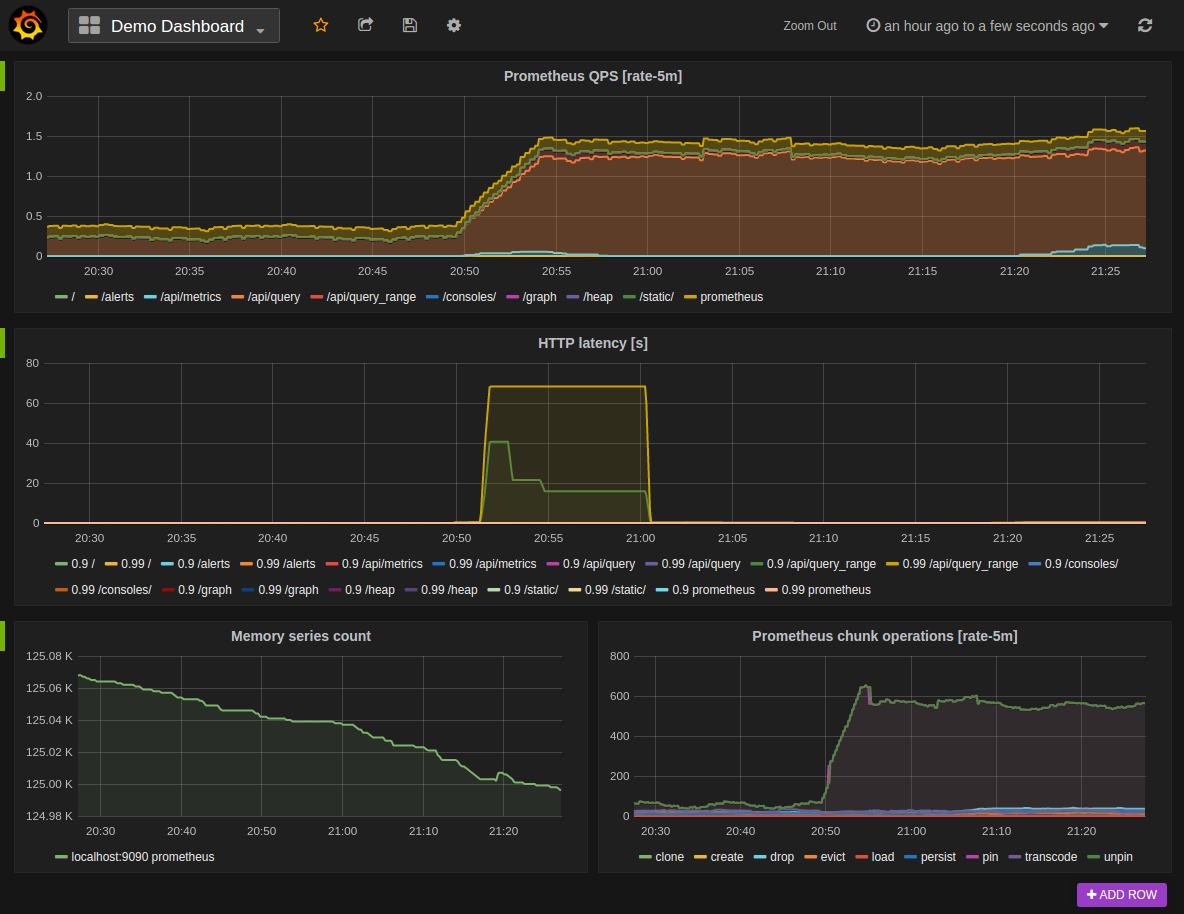
Fonctionnalités
- Modèle multidimensionnel utilisant des noms de mesures et des paires clé-valeur (étiquettes)
- PromQL pour l’interrogation des données de séries temporelles afin de générer des tableaux, des alertes et des graphiques Adhoc
- Utilise le mode HTTP pull pour collecter les données de séries temporelles
- Utilise une passerelle intermédiaire pour pousser les séries temporelles
Prometheus dispose de centaines d’exportateurs pour exporter les données depuis Windows, Linux, Java, les bases de données, les API, les sites Web, le matériel du serveur, PHP, la messagerie, etc. Pour surveiller Linux, consultez cette configuration Prometheus Grafana.
TimescaleDB
TimescaleDB est une base de données relationnelle open-source qui rend SQL évolutif pour les données de séries temporelles. Cette base de données est construite sur PostgreSQL.
Elle propose deux produits – la première option est une édition communautaire, gratuite, que vous pouvez installer sur votre serveur. La seconde option est TimescaleDB Cloud, où vous obtenez une infrastructure entièrement hébergée et gérée sur le cloud pour vos besoins de déploiement.

Il peut être utilisé pour la surveillance DevOps, la compréhension des métriques des applications, le suivi des données des appareils IoT, la compréhension des données financières, etc. Vous pouvez mesurer les journaux, les événements Kubernetes, les métriques Prometheus, et même les métriques personnalisées.
Pour les propriétaires de produits, vous pouvez l’utiliser pour comprendre la performance d’un produit au fil du temps, ce qui aide à prendre des décisions stratégiques pour la croissance.
Fonctionnalités
- Exécutez des requêtes 10 à 100 fois plus vite que PostgreSQL et MongoDB
- Peut s’étendre à des pétaoctets horizontalement et écrire des millions de points de données par seconde
- Très similaire à PostgreSQL, donc facile à utiliser pour les développeurs et les administrateurs
- Combine les fonctionnalités des bases de données relationnelles et de séries temporelles pour créer des applications puissantes.
- Algorithmes intégrés et caractéristiques de performance permettant de réduire considérablement les coûts.
Graphite
Graphite est une solution tout-en-un pour le stockage et la visualisation efficace de données de séries temporelles en temps réel. Graphite peut faire deux choses : stocker des données de séries temporelles et afficher des graphiques à la demande. Mais il ne collecte pas les données pour vous ; pour cela, vous pouvez utiliser des outils tels que collectd, Ganglia, Sensu, telegraf, etc.
Il se compose de trois éléments : Carbon, Whisper et Graphite-Web. Carbon reçoit les données de séries temporelles, les agrège et les enregistre sur le disque. Whisper est une base de données de séries temporelles qui stocke les données. Graphite-Web est l’interface qui permet de créer des tableaux de bord et de visualiser les données.
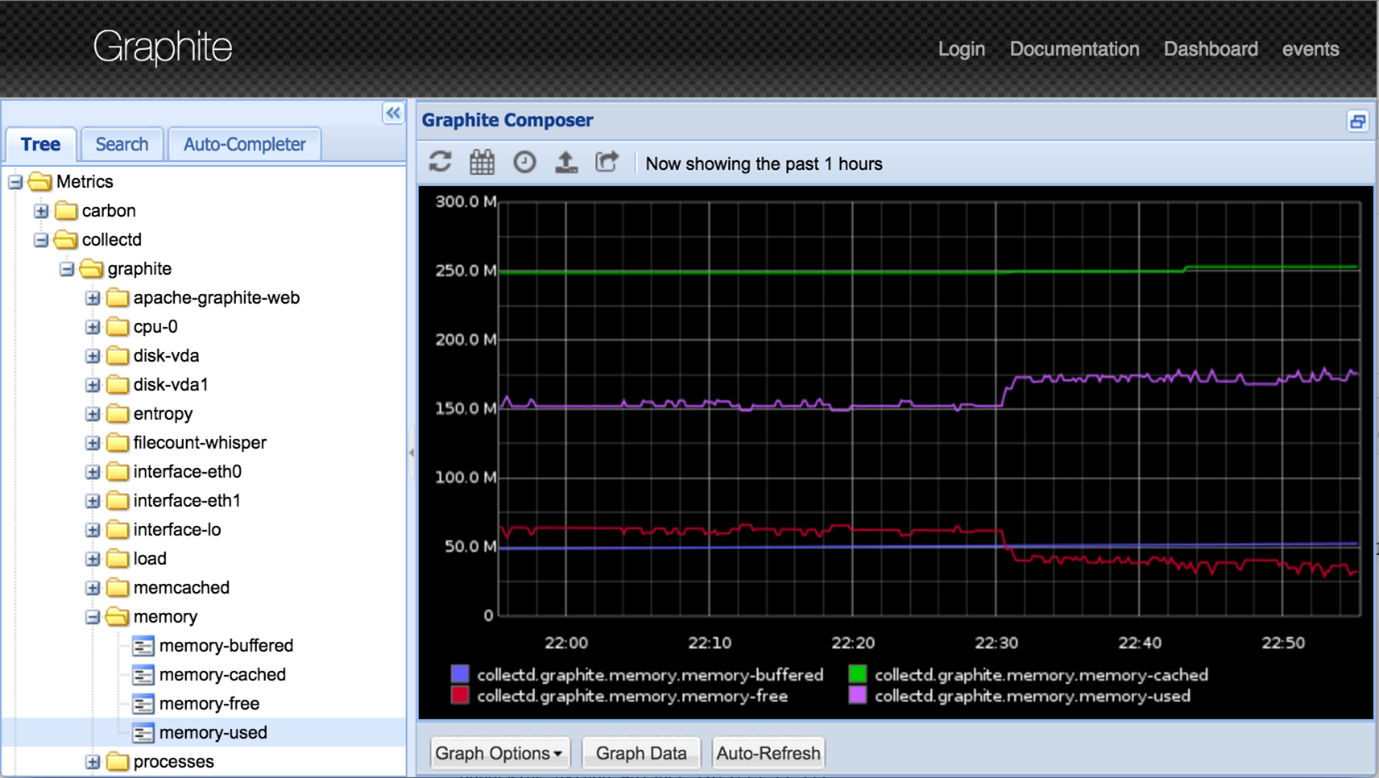
Les caractéristiques de Graphite :
- Le format de métrique dans lequel les données sont soumises est simple.
- API complète pour le rendu des données et la création de diagrammes, de tableaux de bord et de graphiques
- Fournit un riche ensemble de bibliothèques statistiques et de fonctions de rendu transformatives
- Chaîner plusieurs fonctions de rendu pour construire une requête cible.
QuestDB
QuestDB est une base de données relationnelle orientée colonnes qui permet d’effectuer des analyses en temps réel sur des données de séries temporelles. Elle fonctionne avec SQL et quelques extensions pour créer un modèle relationnel pour les données de séries temporelles. QuestDB a été codé à partir de zéro et n’a pas de dépendances, ce qui améliore ses performances.
QuestDB supporte les jointures relationnelles et de séries temporelles, ce qui permet de corréler les données. La façon la plus simple de démarrer avec QuestDB est de le déployer dans un conteneur Docker.
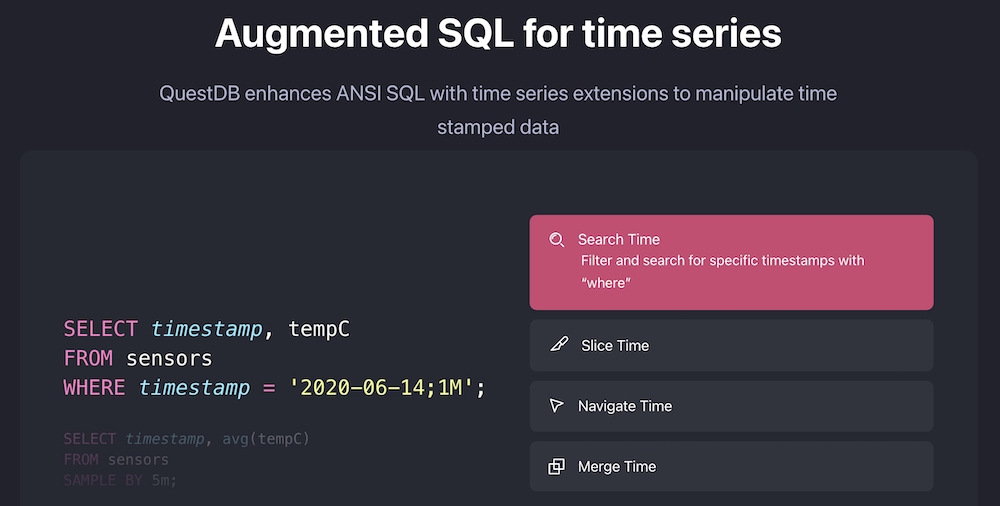
Fonctionnalités de QuestDB :
- Console interactive pour importer des données par glisser-déposer et les interroger
- Prise en charge sur cloud-native (AWS, Azure, GCP), sur site ou embarqué
- Fournit une intégration d’entreprise avec des fonctionnalités telles que l’annuaire actif, la haute disponibilité, la sécurité d’entreprise, le clustering
- Fournit des informations en temps réel à l’aide d’analyses opérationnelles et prédictives
AWS Timestream
Comment AWS peut-il ne pas figurer dans la liste ?
AWSTimestream est un service de base de données de séries temporelles sans serveur, rapide et évolutif. Il est principalement utilisé pour les applications IoT afin de stocker des trillions d’événements par jour et 1000 fois plus rapidement avec un coût de 1/10e des bases de données relationnelles.
Grâce à son moteur de requête spécialement conçu, vous pouvez interroger simultanément des données récentes et des données historiques stockées. Il fournit de multiples fonctions intégrées pour analyser les données de séries temporelles afin de trouver des informations utiles.
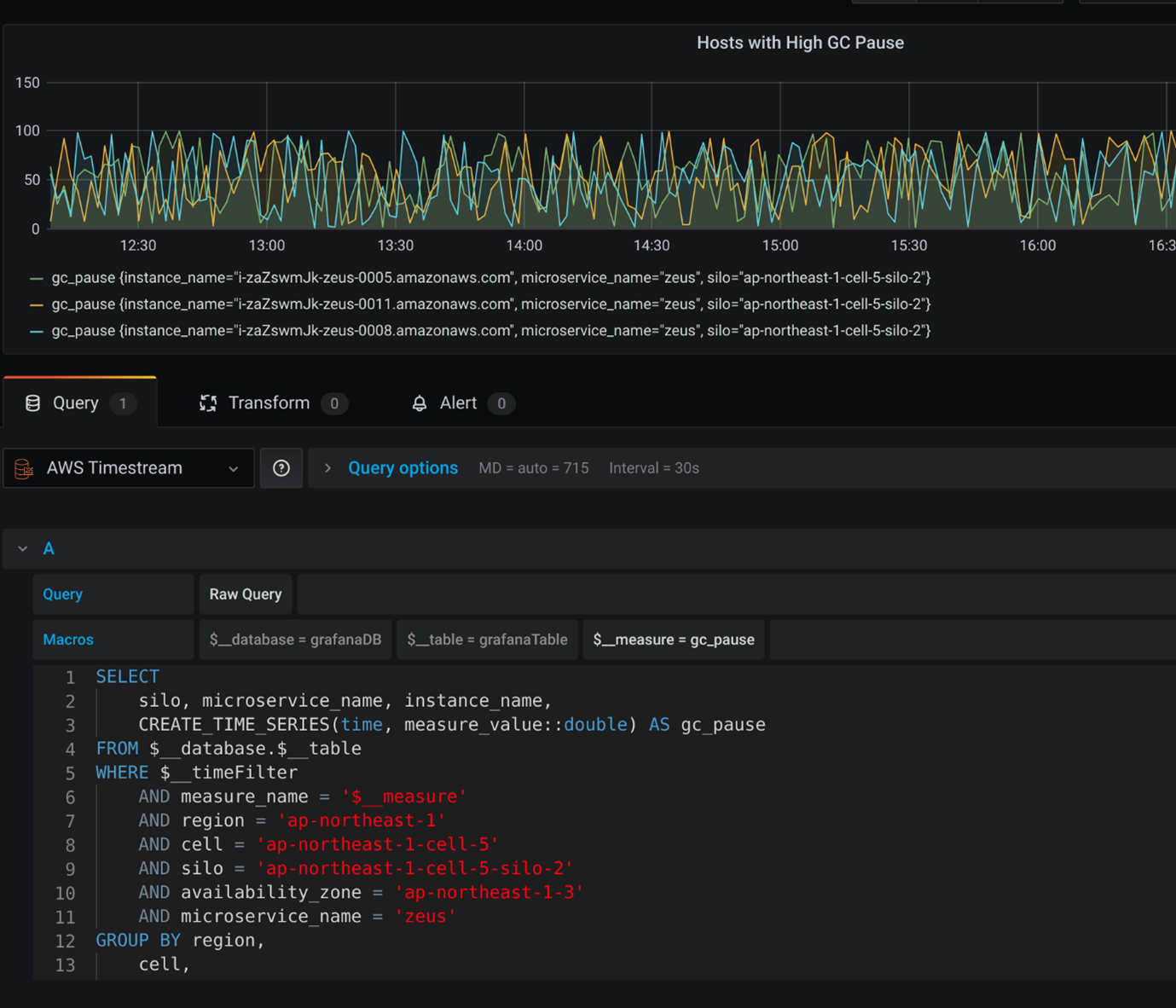
Caractéristiques d’Amazon Timestream :
- Pas de serveurs à gérer ou d’instances à provisionner ; tout est géré automatiquement.
- Rentabilité : vous ne payez que pour ce que vous ingérez, stockez et interrogez.
- Capable d’ingérer des milliers de milliards d’événements par jour sans baisse de performance
- Capacité d’analyse intégrée avec des fonctions SQL, d’interpolation et de lissage standard pour identifier les tendances, les modèles et les anomalies
- Toutes les données sont cryptées à l’aide du système de gestion des clés AWS (KMS) avec des clés gérées par le client (CMK)
OpenTSDB
OpenTSDB est une base de données de séries temporelles évolutive qui a été écrite au-dessus de HBase. Elle est capable de stocker des trillions de points de données à raison de millions d’écritures par seconde. Vous pouvez conserver les données dans OpenTSDB pour toujours avec leur horodatage d’origine et leur valeur précise, de sorte que vous ne perdez aucune donnée.
OpenTSDB dispose d’un démon de séries temporelles (TSD) et d’utilitaires en ligne de commande. Le démon des séries temporelles est responsable du stockage des données dans HBase ou de leur récupération. Vous pouvez communiquer avec le TSD à l’aide de l’API HTTP, de telnet ou de l’interface graphique intégrée. Vous avez besoin d’outils tels que flume, collectd, vacuumetrix, etc., pour collecter des données à partir de diverses sources dans OpenTSDB.
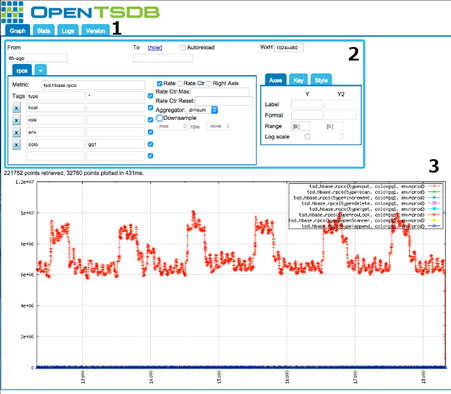
Caractéristiques d’OpenTSBD :
- Peut agréger, filtrer, sous-échantillonner les métriques à une vitesse vertigineuse
- Stocke et écrit les données avec une précision de l’ordre de la milliseconde
- Fonctionne sur Hadoop et HBase et évolue facilement en ajoutant des nœuds au cluster
- Utilise une interface graphique pour générer des graphiques
Conclusion
Depuis que de plus en plus d’appareils IoT/Smart sont utilisés de nos jours, un énorme trafic en temps réel est généré sur les sites web avec des millions d’événements par jour, les échanges sur le marché augmentent, et la base de données de séries temporelles est arrivée ! Les bases de données de séries temporelles sont indispensables dans votre pile de production pour la surveillance.
La plupart des bases de données de séries temporelles listées ci-dessus sont disponibles en auto-hébergement, alors n’hésitez pas à vous procurer une VM dans le nuage et à l’essayer pour voir ce qui vous convient.