Meet Qwen2.5-Omni-7B: The AI That Understands Everything?

Alibaba has unveiled another AI model under its Qwen umbrella, Qwen2.5-Omni-7B. It’s an open-source, end-to-end multimodal AI model designed to process and generate text, audio, images, and video. This comparatively smaller model brings multimodal capabilities to devices like smartphones and laptops.
A Unified AI Model for Multimodal Interaction
The Qwen2.5-Omni-7B is built as an “omni model,” meaning it can handle multiple inputs and outputs. The model also enables users to engage in real-time voice and video chats through Qwen Chat.
In addition, it has been open-sourced under the Apache 2.0 license, making it widely accessible for researchers and developers via platforms like Hugging Face, GitHub, and ModelScope.
Thinker-Talker Architecture
One of the major highlights of Qwen2.5-Omni-7B is its Thinker-Talker architecture. This design divides the model’s functions into two key components:
- Thinker: It acts as the brain, processing, and understanding multimodal inputs to generate structured representations and text.
- Talker: It functions as a voice generator, converting the structured data into smooth, natural speech output.
Performance Across Modalities
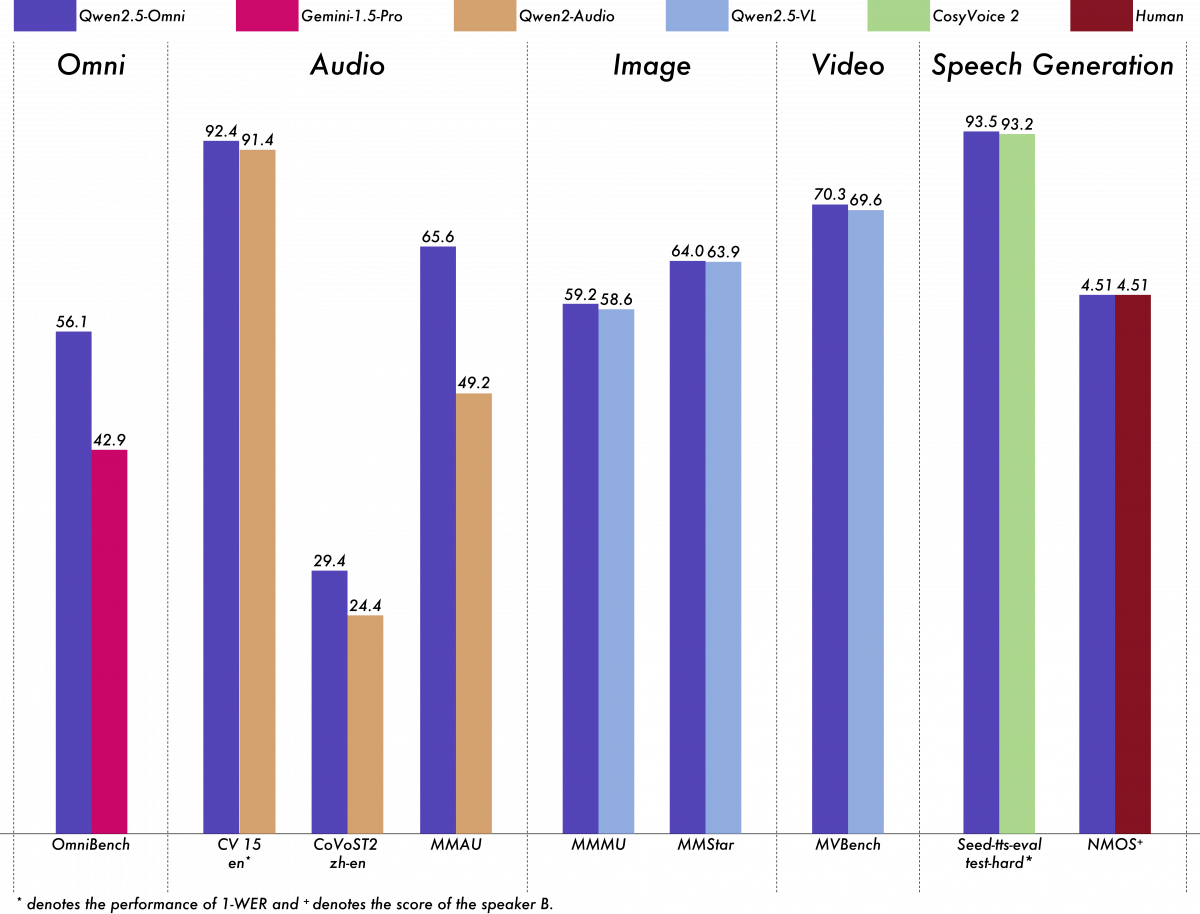
The company has conducted benchmarking tests comparing Qwen2.5-Omni-7B with other AI models, including Gemini 1.5 Pro, Human, and various single-modality models. The results highlight Qwen2.5-Omni’s strong capabilities across multiple modalities. In tasks that require cross-modal reasoning, such as OmniBench, it achieves state-of-the-art performance, surpassing many existing models.
In single-modality tests, Qwen2.5-Omni excels in speech recognition (Common Voice), translation (CoVoST2), and audio understanding (MMAU). It also demonstrates impressive image reasoning on MMMU and MMStar and high scores in video comprehension (MVBench). Speech generation tasks like Seed-tts-eval delivers near-human performance, reaffirming its advancements in AI-driven voice synthesis.