In this article, you will learn about different ways to play around with commits in Git.
As a developer, you would have across such situations multiple times where you would have wanted to roll back to one of your previous commits but not sure how to do that. And even if you know the Git commands like reset, revert, rebase, you are not aware of the differences between them. So let’s get started and understand what git reset, revert and rebase are.
Git Reset
Git reset is a complex command, and it is used to undo the changes.
You can think of git reset as a rollback feature. With git reset, you can jump between various commits. There are three modes of running a git reset command: –soft, –mixed, and –hard. By default, git reset command uses the mixed mode. In a git reset workflow, three internal management mechanisms of git come into the picture: HEAD, staging area (index), and the working directory.
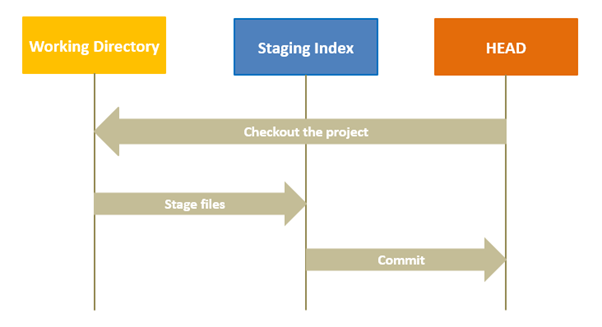
The working directory is the place where you are currently working, it is the place where your files are present. Using a git status command, you can see what all files/folders are present in the working directory.
Staging Area (Index) is where git tracks and saves all the changes in the files. The saved changes are reflected in the .git directory. You use git add “filename” to add the file to the staging area. And like before, when you run git status, you will see which files are present in the staging area.
The current branch in Git is referred to as HEAD. It points to the last commit, which happened in the current checkout branch. It is treated as a pointer for any reference. Once you checkout to another branch, the HEAD also moves to the new branch.
Let me explain how git reset works in hard, soft, and mixed modes. Hard mode is used to go to the pointed commit, the working directory gets populated with files of that commit, and the staging area gets reset. In soft reset, only the pointer is changed to the specified commit. The files of all the commits remain in the working directory and staging area before the reset. In mixed mode (default), the pointer and the staging area both get reset.
Git Reset Hard
The purpose of git hard reset is to move the HEAD to the specified commit. It will remove all the commits with happened after the specified commit. This command will change the commit history and point to the specified commit.
In this example, I will add three new files, commit them and then perform a hard reset.
As you can see from the command below, right now, there is nothing to commit.
$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
nothing to commit, working tree cleanNow, I will create 3 files and add some content to it.
$ vi file1.txt
$ vi file2.txt
$ vi file3.txtAdd these files to the existing repository.
$ git add file*When you rerun the status command, it will reflect the new files I just created.
$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file:
file1.txt
new file:
file2.txt
new file:
file3.txtBefore committing, let me show you, I currently have a log of 3 commits in Git.
$ git log --oneline
0db602e (HEAD -> master) one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testNow, I will commit to the repository.
$ git commit -m 'added 3 files'
[master d69950b] added 3 files
3 files changed, 3 insertions(+)
create mode 100644 file1.txt
create mode 100644 file2.txt
create mode 100644 file3.txtIf I do ls-files, you will see the new files have been added.
$ git ls-files
demo
dummyfile
newfile
file1.txt
file2.txt
file3.txtWhen I run the log command in git, I have 4 commits, and the HEAD points to the latest commit.
$ git log --oneline
d69950b (HEAD -> master) added 3 files
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testIf I go and delete the file1.txt manually and do a git status, it will show the message that the changes are not staged for commit.
$ git status
On branch master
Your branch is ahead of 'origin/master' by 3 commits.
(use "git push" to publish your local commits)
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted:
file1.txt
no changes added to commit (use "git add" and/or "git commit -a")Now, I will run the hard reset command.
$ git reset --hard
HEAD is now at d69950b added 3 filesIf I recheck the status, I will find there is nothing to commit, and the file I deleted has come back into the repository. The rollback has happened because after deleting the file, I did not commit, so after a hard reset, it went back to the previous state.
$ git status
On branch master
Your branch is ahead of 'origin/master' by 3 commits.
(use "git push" to publish your local commits)
nothing to commit, working tree cleanIf I check the log of git, this is how it will look.
$ git log
commit d69950b7ea406a97499e07f9b28082db9db0b387 (HEAD -> master)
Author: mrgeek <[email protected]>
Date:
Mon May 17 19:53:31 2020 +0530
added 3 files
commit 0db602e085a4d59cfa9393abac41ff5fd7afcb14
Author: mrgeek <[email protected]>
Date:
Mon May 17 01:04:13 2020 +0530
one more commit
commit 59c86c96a82589bad5ecba7668ad38aa684ab323
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:54:53 2020 +0530
new commit
commit e2f44fca2f8afad8e4d73df6b72111f2f2fd71ad (origin/master, origin/HEAD)
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:16:33 2020 +0530
testThe purpose of hard reset is to point to the specified commit and update the working directory and staging area. Let me show you one more example. Currently, the visualization of my commits looks like below:

Here, I will run the command with HEAD^, which means I want to reset to the previous commit (one commit back).
$ git reset --hard HEAD^
HEAD is now at 0db602e one more commitYou can see the head pointer has now changed to 0db602e from d69950b.
$ git log --oneline
0db602e (HEAD -> master) one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) test
If you check the log, the commit of d69950b is gone, and the head now points to 0db602e SHA.
$ git log
commit 0db602e085a4d59cfa9393abac41ff5fd7afcb14 (HEAD -> master)
Author: mrgeek <[email protected]>
Date:
Mon May 17 01:04:13 2020 +0530
one more commit
commit 59c86c96a82589bad5ecba7668ad38aa684ab323
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:54:53 2020 +0530
new commit
commit e2f44fca2f8afad8e4d73df6b72111f2f2fd71ad (origin/master, origin/HEAD)
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:16:33 2020 +0530
TestIf you run the ls-files, you can see file1.txt, file2.txt, and files3.txt are not in the repository anymore because that commit and its file got removed after the hard reset.
$ git ls-files
demo
dummyfile
newfileGit Soft Reset
Similarly, now I will show you an example of a soft reset. Consider, I have added the 3 files again as mentioned above and committed them. The git log will appear as shown below. You can see ‘soft reset’ is my latest commit, and HEAD is also pointing to that.
$ git log --oneline
aa40085 (HEAD -> master) soft reset
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testDetails of the commit in the log can be seen using the below command.
$ git log
commit aa400858aab3927e79116941c715749780a59fc9 (HEAD -> master)
Author: mrgeek <[email protected]>
Date:
Mon May 17 21:01:36 2020 +0530
soft reset
commit 0db602e085a4d59cfa9393abac41ff5fd7afcb14
Author: mrgeek <[email protected]>
Date:
Mon May 17 01:04:13 2020 +0530
one more commit
commit 59c86c96a82589bad5ecba7668ad38aa684ab323
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:54:53 2020 +0530
new commit
commit e2f44fca2f8afad8e4d73df6b72111f2f2fd71ad (origin/master, origin/HEAD)
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:16:33 2020 +0530
testNow using the soft reset, I want to switch to one of the older commits with SHA 0db602e085a4d59cfa9393abac41ff5fd7afcb14
To do that, I will run the below command. You need to pass more than 6 starting characters of SHA, the complete SHA is not required.
$ git reset --soft 0db602e085a4Now when I run the git log, I can see the HEAD has been reset to the commit I specified.
$ git log
commit 0db602e085a4d59cfa9393abac41ff5fd7afcb14 (HEAD -> master)
Author: mrgeek <[email protected]>
Date:
Mon May 17 01:04:13 2020 +0530
one more commit
commit 59c86c96a82589bad5ecba7668ad38aa684ab323
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:54:53 2020 +0530
new commit
commit e2f44fca2f8afad8e4d73df6b72111f2f2fd71ad (origin/master, origin/HEAD)
Author: mrgeek <[email protected]>
Date:
Mon May 17 00:16:33 2020 +0530
testBut the difference here is, the files of the commit (aa400858aab3927e79116941c715749780a59fc9) where I had added 3 files are still in my working directory. They have not got deleted. That’s why you should use a soft reset rather than a hard reset. There is no risk of losing the files in the soft mode.
$ git ls-files
demo
dummyfile
file1.txt
file2.txt
file3.txt
newfileGit Revert
In Git, the revert command is used to perform a revert operation, i.e., to revert some changes. It is similar to the reset command, but the only difference here is that you perform a new commit to go back to a particular commit. In short, it is fair to say that the git revert command is a commit.
The Git revert command does not delete any data while performing the revert operation.
Let’s say I am adding 3 files and performing a git commit operation for the revert example.
$ git commit -m 'add 3 files again'
[master 812335d] add 3 files again
3 files changed, 3 insertions(+)
create mode 100644 file1.txt
create mode 100644 file2.txt
create mode 100644 file3.txtThe log will show the new commit.
$ git log --oneline
812335d (HEAD -> master) add 3 files again
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testNow I would like to revert to one of my past commits, let’s say – “59c86c9 new commit”. I would run the command below.
$ git revert 59c86c9This will open a file, you will find the details of the commit you are trying to revert to, and you can give your new commit a name here, and then save and close the file.
Revert "new commit"
This reverts commit 59c86c96a82589bad5ecba7668ad38aa684ab323.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch master
# Your branch is ahead of 'origin/master' by 4 commits.
# (use "git push" to publish your local commits)
#
# Changes to be committed:
# modified: dummyfileAfter you save and close the file, this is the output you will get.
$ git revert 59c86c9
[master af72b7a] Revert "new commit"
1 file changed, 1 insertion(+), 1 deletion(-)Now to make the necessary changes, unlike reset, revert has performed one more new commit. If you check the log again, you will find a new commit because of the revert operation.
$ git log --oneline
af72b7a (HEAD -> master) Revert "new commit"
812335d add 3 files again
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) test
Git log will have all the history of commits. If you want to remove the commits from the history, then revert is not a good choice, but if you want to maintain the commit changes in the history, then revert is the suitable command instead of reset.
Git Rebase
In Git, rebase is the way of moving or combining commits of one branch over another branch. As a developer, I would not create my features on the master branch in a real-world scenario. I would work on my own branch (a ‘feature branch’), and when I have a few commits in my feature branch with the feature added, I would then like to move it to the master branch.
Rebase can sometimes be a little confusing to understand because it is very similar to a merge. The goal of merging and rebasing both is to take the commits from my feature branch and put them on to a master branch or any other branch. Consider, I have a graph which looks like this:
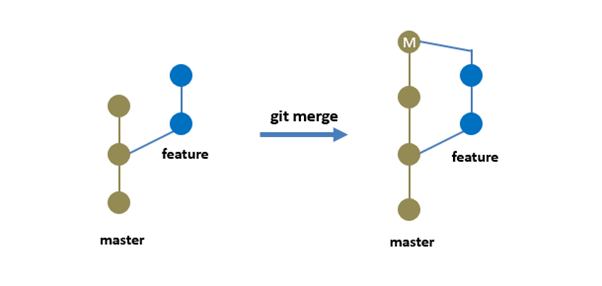
Suppose you are working in a team with other developers. In that case, you can imagine that this could get really complex where you have a bunch of other developers working on different feature branches, and they have been merging multiple changes. It becomes confusing to trace.
So, this is where rebase is going to help. This time, instead of doing a git merge, I will do a rebase, where I want to take my two feature branch commits and move them onto the master branch. A rebase will take all my commits from the feature branch and move them on top of the master branch commits. So, behind the scenes, git is duplicating the feature branch commits on the master branch.

This approach will give you a clean straight-line graph with all the commits in a row.

It makes it easy to trace what commits went where. You can imagine if you are on a team with many developers, all the commits are still in a row. So, it is really easy to follow even if you have many people working on the same project at the same time.
Let me show you this practically.
This is how my master branch looks like currently. It has 4 commits.
$ git log --oneline
812335d (HEAD -> master) add 3 files again
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testI will run the below command to create and switch to a new branch called feature, and this branch will be created from the 2nd commit, i.e. 59c86c9
(master)
$ git checkout -b feature 59c86c9
Switched to a new branch 'feature'If you check the log in the feature branch, it has only 2 commits coming from the master (mainline).
(feature)
$ git log --oneline
59c86c9 (HEAD -> feature) new commit
e2f44fc (origin/master, origin/HEAD) testI will create feature 1 and commit it to the feature branch.
(feature)
$ vi feature1.txt
(feature)
$ git add .
The file will have its original line endings in your working directory
(feature)
$ git commit -m 'feature 1'
[feature c639e1b] feature 1
1 file changed, 1 insertion(+)
create mode 100644 feature1.txtI will create one more feature, i.e., feature 2, in the feature branch and commit it.
(feature)
$ vi feature2.txt
(feature)
$ git add .
The file will have its original line endings in your working directory
(feature)
$ git commit -m 'feature 2'
[feature 0f4db49] feature 2
1 file changed, 1 insertion(+)
create mode 100644 feature2.txtNow, if you check the log of the feature branch, it has two new commits, which I executed above.
(feature)
$ git log --oneline
0f4db49 (HEAD -> feature) feature 2
c639e1b feature 1
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testNow I want to add these two new features to the master branch. For that, I will use the rebase command. From the feature branch, I will rebase against the master branch. What this will do is it will re-anchor my feature branch against the latest changes.
(feature)
$ git rebase master
Successfully rebased and updated refs/heads/feature.Now I am going to go ahead and checkout the master branch.
(feature)
$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 3 commits.
(use "git push" to publish your local commits)And finally, rebase the master branch against my feature branch. This will take those two new commits on my feature branch and replay them on top of my master branch.
(master)
$ git rebase feature
Successfully rebased and updated refs/heads/master.Now if I check the log on the master branch, I can see the two commits of my features branch have been added to my master branch successfully.
(master)
$ git log --oneline
766c996 (HEAD -> master, feature) feature 2
c036a11 feature 1
812335d add 3 files again
0db602e one more commit
59c86c9 new commit
e2f44fc (origin/master, origin/HEAD) testThat was all about reset, revert and rebase commands in Git.
Conclusion
That was all about reset, revert and rebase commands in Git. I hope this step-by-step guide was helpful. Now, you know how to play around with your commits as per the need using the commands mentioned in the article.