Web scraping is the automated process of extracting unstructured data from websites and transforming it into a structured format. While traditionally used for marketing and finance, web scraping has undergone a massive evolution.
According to data, the primary use case for web scraping has fundamentally shifted. Today, over 65% of enterprise web scraping is dedicated to feeding data pipelines for AI models and LLMs.
Whether you are building an AI agent, generating leads, or analyzing competitors, web scraping is the engine that powers modern business intelligence.
What is Web Scraping?
Web scraping is the act of using bots or automated scripts to copy data from web pages.
The internet has billions of pages, but it is typically formatted in HTML for humans to read, not for machines to analyze. Companies or individuals who web scrape want to gather a sizable amount of data that cannot be collected manually in a short timeframe. The scraping process downloads the web pages, parses the code, and extracts specific data points into a local database.
Imagine getting this page content without any styling and fancy layout. Just the text!
Web Scraping vs. Web Crawling
Beginners often confuse the two and misunderstand them as the same thing. While both are frequently used interchangeably, they are different.
- Web Crawling is the process of discovering and indexing web pages. It looks at the structure of the web. Ex: Googlebot crawling the web to find links.
- Web Scraping is the process of extracting specific data points or whole content from those pages. It looks at the content of the web. Ex: getting product prices from Amazon.

Modern Web Scraping Bottleneck
Historically, extracting public data was straightforward. Today, websites utilize aggressive bot detection methods like Cloudflare Turnstile or CAPTCHAs to preserve server resources. Because of this, traditional DIY scraping scripts often fail.
This is where Geekflare scraping API come into play. Geekflare represents the next generation of data extraction API approach that bypasses the common issues faced by traditional methods. By utilizing advanced AI technologies, Geekflare eliminates the need for manual intervention in handling IP blocks, CAPTCHAs, or dynamic JavaScript rendering.
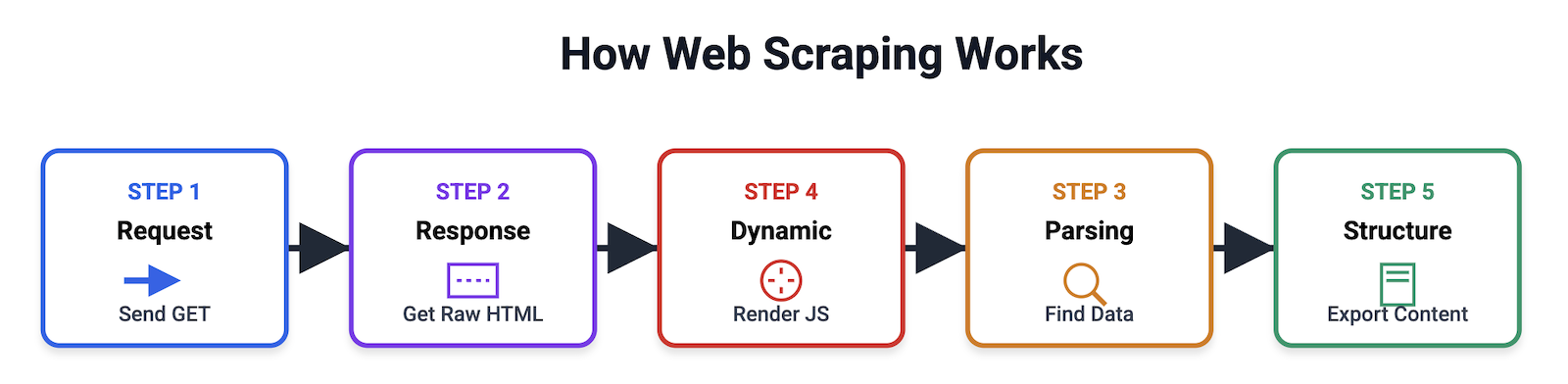
How Web Scraping Works
The web scraping process usually follows these five main stages:
- Sending the HTTP Request – the scraper sends a GET request to the target webpage’s URL, asking the server to return the page’s contents.
- Receiving the Response – the web server processes the request and sends back an HTTP response. A successful request will return the raw HTML content. Unsuccessful requests give errors like 403 Forbidden or 429 Too Many Requests.
- Parsing – because raw HTML is chaotic, the scraper uses parsing libraries like BeautifulSoup, Cheerio, or lxml to navigate the Document Object Model (DOM) tree via XPath or CSS selectors to locate specific text.
- Handling Dynamic Content – modern websites load content dynamically. Standard scrapers fail here. Advanced tools use headless browsers like Puppeteer or Playwright to execute JavaScript and render the page exactly as a human user would see it before extracting the data.
- Data Structuring – the scraper cleans the extracted data and exports it into a structured format like JSON, CSV, Markdown, or clean HTML.
4 Different Types of Web Scrapers
Depending on your technical expertise, you can choose from four main types of scrapers:

Self-Built Scrapers
You can build in Python or Node.js. You have full control and are highly flexible but require constant maintenance to fix broken selectors and manage proxy infrastructures. You can refer to my guide on how to build a lightweight scraper for Markdown.
Puppeteer and Playwright are popular libs to render JS sites, which you can use when building in-house scrapers.
Browser Extensions
An extension that runs directly in Chrome or Firefox. They are great for lightweight scraping and small-scale extraction.
Easy Scraper and Simplescraper are popular Chrome extensions.
Cloud Scrapers
Remote servers that handle the infrastructure for you. These offer high scalability and built-in proxy rotation.
Geekflare API, Bright Data, ScrapingBee are popular scraper APIs.
AI Scrapers
Next-gen scrapers that use LLMs to visually understand a webpage. Instead of writing code to find an HTML tag, you ask the AI to “extract all products lower than $10“. It is a new trend in scraping.
What Is Web Scraping Used For?
Here are the top use cases driving the industry today:
AI & LLM Training
To harvest massive datasets from forums, articles, and public repositories to train machine learning models and AI agents. For faster processing and less token consumption, you should feed data in Markdown format.
Price Comparison
E-commerce companies and agencies scrape competitors to adjust pricing or track Minimum Advertised Price (MAP) violations across retailers.
Lead Generation
To extract public contact info from directories and B2B platforms to build highly targeted outreach lists for sales teams.
Sentiment Analysis
Scraping social media, Reddit, and product reviews to gauge public sentiment about a brand, product, or political event.
Financial Data
Hedge funds scrape real-time stock prices, SEC filings, and even satellite imagery metadata to make algorithmic trading decisions.
Real Estate Aggregation
Compiling property prices, locations, and historical trends from various site listings to spot undervalued properties.
Content Aggregation
Platforms like Google News or Apple News scrape headlines globally to create centralized feeds.
Is Web Scraping Legal?
Web scraping is generally legal, provided you are extracting publicly available data. However, the legal landscape is highly nuanced. If you are scraping, you must consider the following:
1. Data Privacy Regulations (GDPR & CCPA).
2. Copyright Laws.
3. Terms of Service (ToS).
4. Respect robots.txt and rate limiting.
Disclaimer: This does not constitute legal advice. Always consult a legal professional in your region regarding your specific scraping use case.
Common Challenges of Web Scraping
If you build your own scrapers, you will face
- CAPTCHAs, Turnstile
- IP Blocking & Rate Limiting
- Website Structure Changes
- JavaScript Rendering
Can I Use ChatGPT to Scrape a Website?
Yes, you can use ChatGPT for web scraping, but with limitations.
ChatGPT is for conversational search, not bulk data extraction. It cannot scrape 100,000 pages of an marketplace site, nor can it bypass heavy anti-bot protections.
It’s best to use ChatGPT, Claude, or Gemini to extract certain pages content or summarize than to leverage complete web scraping.
Future Trends in Web Scraping
As we move further into 2026, the data extraction industry is being redefined by these trends:
AI Scraping Agents
Instead of writing scripts, you will deploy AI agents. You will give a prompt like “Find all AI companies in London and extract their developers’ emails,” and the agent will navigate, click, and scrape autonomously.
Anti-Bot AI vs. Scraping AI
The war between bot protection and scrapers is now AI-driven. Proxies are no longer enough; scrapers must now spoof human biometric behaviors like mouse movement and scrolling.
Scraping as a Service (SaaS)
DIY scraping is becoming difficult to maintain and expensive for smaller companies. API solutions like Geekflare API are becoming the industry standard.