If you’ve been using Linux for a while, you already know about grep — Global Regular Expression Print, a text-processing tool that you can use to search files and directories. It is very useful in the hands of a Linux power user. However, using it without regex can limit its capabilities.
But what is Regex?
Regex is regular expressions which you can use to improve grep search functionality. Regex, by definition, is an advanced output-filtering pattern. With practice, you can use regex effectively, as you can use it with other Linux commands as well.
In our tutorial, we’ll learn how to use Grep and Regex effectively.
Pre-Requisite
Using grep with regex requires good Linux knowledge.
You also need access to a laptop or computer running the Linux operating system. You can use any Linux distro of your choice. And, if you have a Windows machine, you can still use Linux with WSL2. Check out our detailed take on it here.
Access to the command line/terminal allows you to run all the commands provided in our grep/regex tutorial.
Furthermore, you also need access to a text file(s) which you’ll need to run the examples. I used ChatGPT to generate a wall of text, telling it to write about tech. The prompt that I used is as below.
“Generate 400 words on tech. It should include most tech. Also, make sure that you repeat technology names across the text.”
Once it generated the text, I copy-pasted it and saved it in the tech.txt file, which we will use throughout the tutorial.
Lastly, a basic understanding of the grep command is a must. You can check out 16 grep command examples to refresh your knowledge. We’ll also introduce the grep command briefly to get you started.
Syntax and Examples of grep Command
The grep command syntax is simple.
$ grep -options [regex/pattern] [files]As you can notice, it expects a pattern and the list of files you want to run the command.
There’re plenty of grep options available that modify its functionality. These include:
- – i: ignore cases
- -r: do recursive search
- -w: perform a search to find whole words only
- -v: display all the non-matching lines
- -n: display all the matching line numbers
- -l: print the file names
- –color: colored result output
- -c: shows match count for the pattern used
#1. Search for a Whole Word
You’ll need to use the -w argument with grep for a whole word search. By using it, you bypass any strings that match the given pattern.
$ grep -w ‘tech\|5G’ tech.txt
As you can see, the command results in an output where it searches for two words, “5G” and “tech,” throughout the text. It then marks them with red color.
Here, the | pipe symbol is escaped so that grep doesn’t process it as a metacharacter.
#2. Case-Insensitive Search
To do a case-insensitive search, use grep with the -i argument.
$ grep -i ‘tech’ tech.txt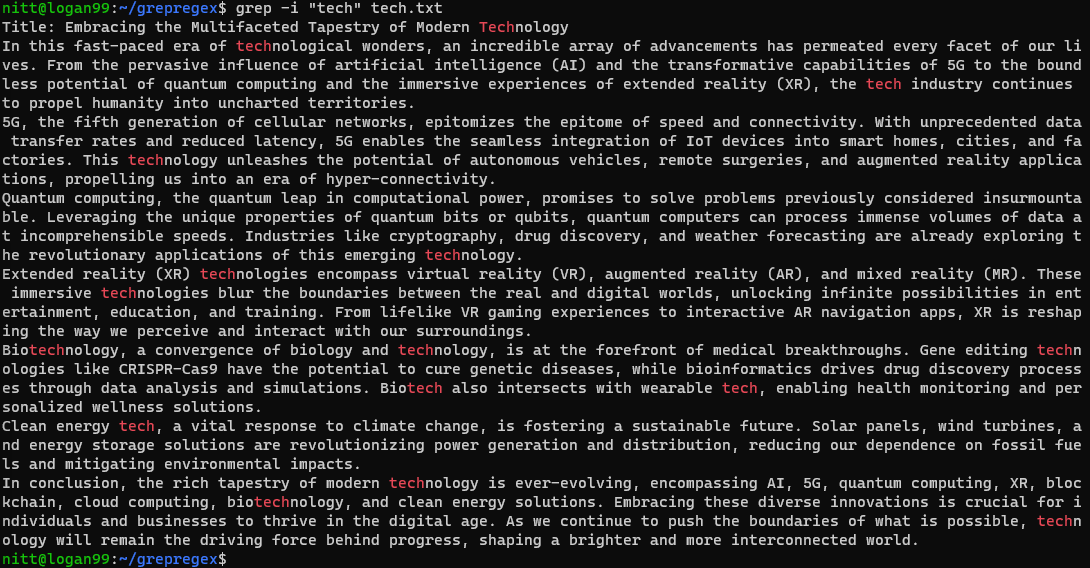
The command searches for any case-insensitive instance of the “tech” string, be it a complete word or part of it.
#3. Do a Non-matching Line Search
To display all the lines that don’t contain a given pattern, you’ll need to use the -v argument.
$ grep -v ‘tech’ tech.txt
The output shows all the lines that don’t contain the word “tech.” Also you’ll see empty lines as well. These lines are the lines that are after a paragraph.
#4. Do a Recursive Search
To do a recursive search, use the -r argument with grep.
$ grep -R ‘error\|warning’ /var/log/*.log#output
/var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1]
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg':
/var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!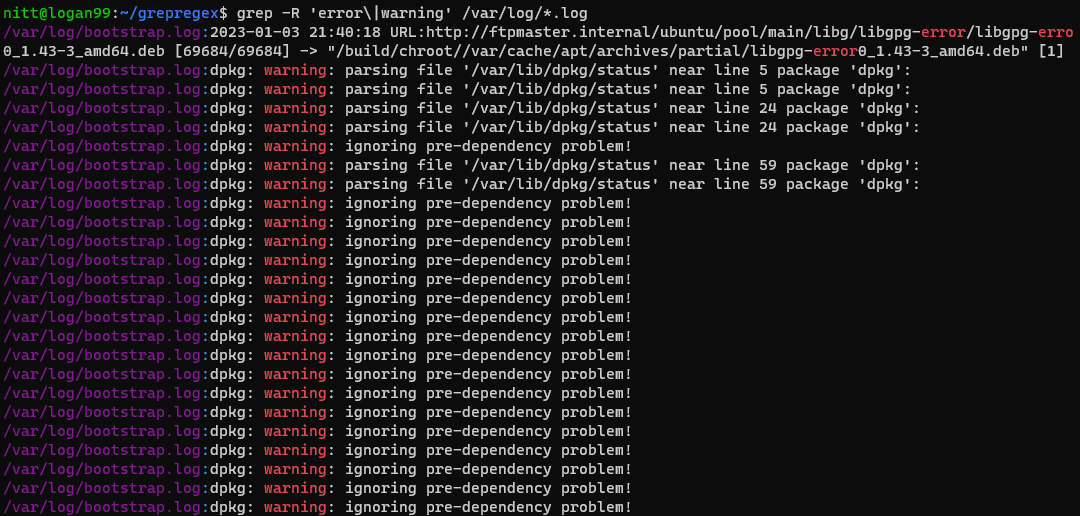
The grep command recursively searches for two words, “error” and “warning,” in the /var/log directory. This is a handy command to learn about any warnings and errors in the log files.
Grep and Regex: What it is and Examples
As we’re working with regex, you need to know that regex offers three syntax options. These include:
- Basic Regular Expressions (BRE)
- Extended Regular Expressions (ERE)
- Pearl Compatible Regular Expressions (PCRE)
The grep command uses BRE as the default option. So, if you want to use other regex modes, you’ll need to mention them. The grep command also treats metacharacters as they are. So, if you use metacharacters such as ?, +, ), you’ll need to escape them with the backslash (\) command.
The syntax of grep with regex is as below.
$ grep [regex] [filenames]Let’s see grep and regex in action with the examples below.
#1. Literal Word Matches
To do a literal word match, you’ll need to provide a string as regex. After all, a word is also a regex.
$ grep "technologies" tech.txt
Similarly, you can also use literal matches to find current users. To do so, run,
$ grep bash /etc/passwd#output
root:x:0:0:root:/root:/bin/bash
nitt:x:1000:1000:,,,:/home/nitt:/bin/bash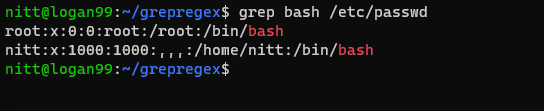
This displays the users that can access the bash.
#2. Anchor Matching
Anchor matching is a useful technique for advanced searches using special characters. In regex, there are different anchor characters that you can use to represent specific positions within a text. These include:
- ‘^’ caret symbol: The caret symbol matches the start of the input string or line and looks for an empty string.
- ‘$’ dollar symbol: The dollar symbol matches the end of the input string or line and looks for an empty string.
The other two anchor matching characters include the ‘\ b’ word boundary and ‘\ B’ non-word boundary.
- ‘\ b’ word boundary: With \b, you can assert the position between a word and a non-word character. In simple words, it lets you match complete words. This way, you can avoid partial matches. You can also use it to replace words or count word occurrences in a string.
- \B non-word boundary: It is the opposite of \b word boundary in regex as it asserts a position that is not between two-word or non-word characters.
Let’s go through examples to get a clear idea.
$ grep ‘^From’ tech.txtUsing caret requires entering the word or pattern in the correct case. That’s because it is case-sensitive. So, if you run the following command, it’ll not return anything.
$ grep ‘^from’ tech.txtSimilarly, you can use the $ symbol to find the sentence that matches a given pattern, string, or word.
$ grep ‘technology.$' tech.txt
You can combine both ^ and $ symbols as well. Let’s look at the example below.
$ grep “^From \| technology.$” tech.txtAs you can see, the output contains sentences starting with “From” and sentences ending with “technology.”
#3. Grouping
If you’re looking to search multiple patterns at once, you’ll need to use Grouping. It helps you create small groups of characters and patterns that you can treat as a single unit. For example, you can create a group (tech) that includes the term, ‘t’, ‘e’,’ c’,’ h.’
To get a clear idea, let’s check out an example.
$ grep 'technol\(ogy\)\?' tech.txt
With grouping, you can match repeated patterns, capture groups, and search for alternatives.
Alternative Search With Grouping
Let’s see an example of an alternative search.
$ grep "\(tech\|technology\)" tech.txt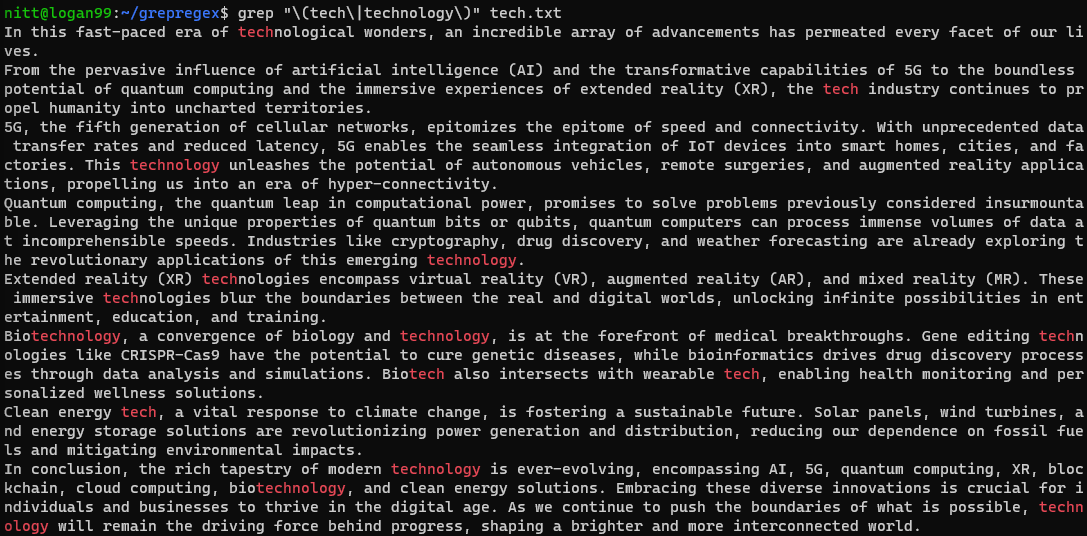
If you want to perform a search on a string, then you’ll need to pass it with the pipe symbol. Let’s see it in the example below.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"#output
“tech technological technologies technical”
Capturing Groups, Non-capturing Groups, and Repeated Patterns
And what about capturing and non-capturing groups?
You’ll need to create a group in the regex and pass it to the string or a file for capturing groups.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"#output
tech655 tech655nical technologies655 tech655-oriented 655
And, for non-capturing groups, you’ll need to use the ?: within parenthesis.
Lastly, we have repeated patterns. You’ll need to modify the regex to check for repeated patterns.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'#output
‘teach tech ttrial tttechno attest’Here, the regex looks for one or more instances of the ‘t’ character.
#4. Character Classes
With character classes, you can write regex expressions easily. These character classes use square brackets. Some of the well-known character classes include:
- [:digit:] – 0 to 9 digits
- [:alpha:] – alphabetic characters
- [:alnum:] – alphanumeric characters
- [:lower:] – lowercase letters
- [:upper:] – uppercase letters
- [:xdigit:] – hexadecimal digits, including 0-9, A-F, a-f
- [:blank:] – blank characters such as tab or space
And so on!
Let’s check a few of them in action.
$ grep [[:digit]] tech.txt
$ grep [[:alpha:]] tech.txt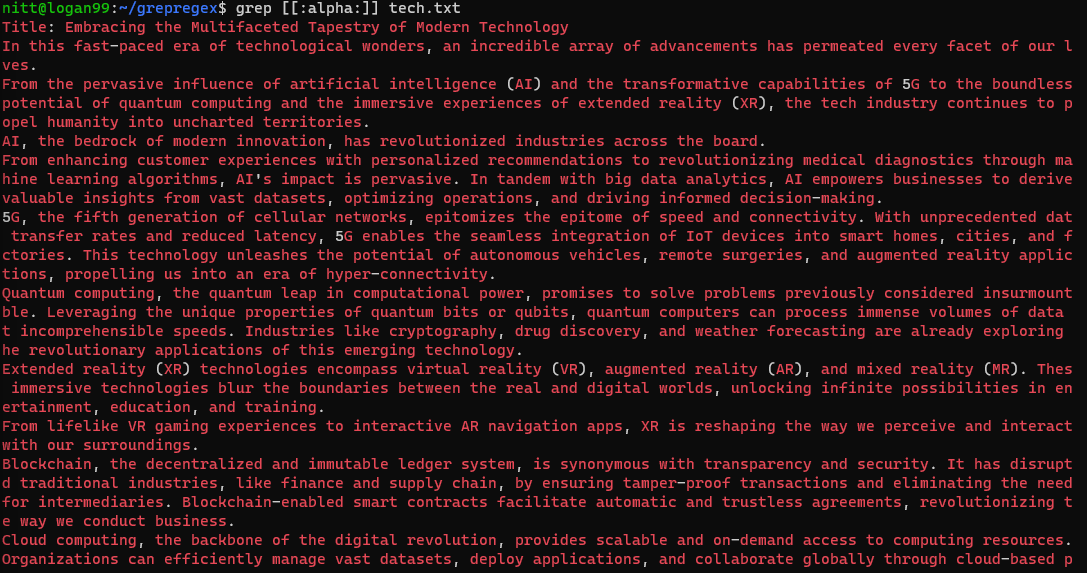
$ grep [[:xdigit:]] tech.txt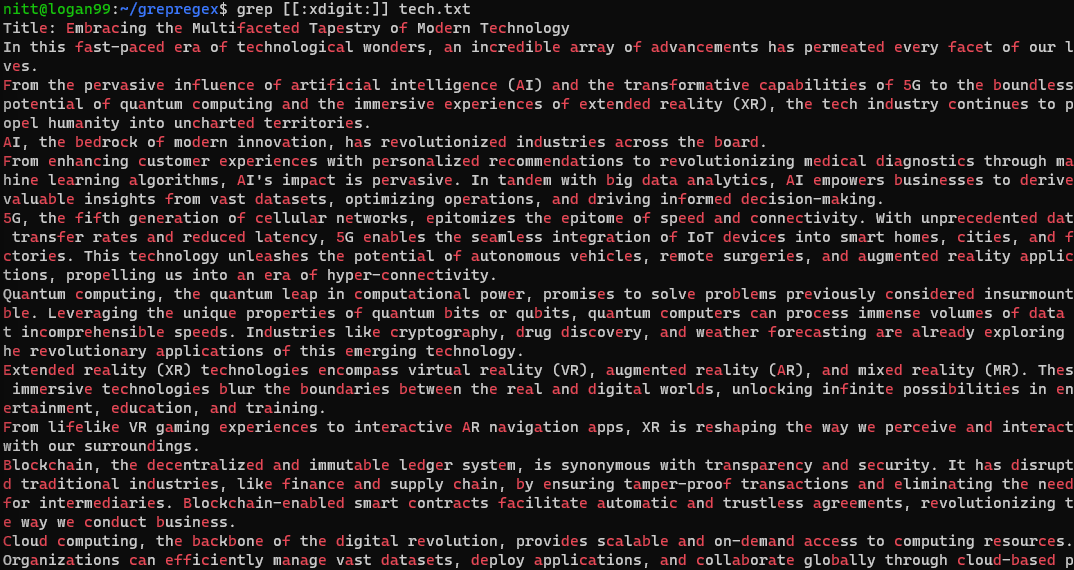
#5. Quantifiers
Quantifiers are metacharacters and are at the core of regex. These let you match exact appearances. Let’s look at them below.
- * → Zero or more matches
- + → one or more matches
- ? → Zero or one matches
- {x} → x matches
- {x, } → x or more matches
- {x,z} → from x to z matches
- {, z} → up to z matches
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'#output
‘teach tech ttrial tttechno attest’Here, it searches for the ‘t’ character instances for one or more matches. Here -E stands for extended regex (that we’ll discuss later.)

#6. Extended Regex
If you don’t like adding escape characters in the regex pattern, you must use extended regex. It removes the need to add escape characters. To do so, you’ll need to use the -E flag.
$ grep -E 'in+ovation' tech.txt
#7. Using PCRE to Do Complex Searches
PCRE (Perl Compatible Regular Expression) lets you do much more than write basic expressions. For example, you can write “\d” which denotes [0-9].
For example, you can use PCRE to search for email addresses.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"#output
Contact me at [email protected]
Here, PCRE ensures that the pattern is matched. Similarly, you can also use a PCRE pattern to check for date patterns.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"#output
The Sparkain site launched on 2023-07-29
The command finds the date in YYYY-MM-DD format. You can modify it to match other date format as well.
#8. Alternation
If you want alternative matches, you can use the escaped pipe characters (\|).
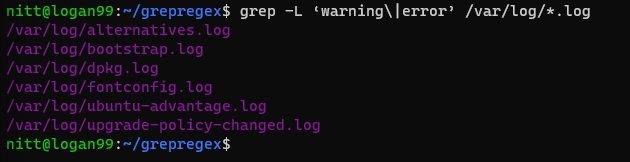
$ grep -L ‘warning\|error’ /var/log/*.log#output
/var/log/alternatives.log
/var/log/bootstrap.log
/var/log/dpkg.log
/var/log/fontconfig.log
/var/log/ubuntu-advantage.log
/var/log/upgrade-policy-changed.logThe output lists the file names containing “warning” or “error.”
Final Words
This leads us to the end of our grep and regex guide. You can use grep with regex extensively to refine searches. With correct use, you can save plenty of time and help automate many tasks, especially if you’re using them to write scripts or use the regex in carrying out searches through the text.
Next, check out frequently asked Linux interview questions and answers.