Speech-to-Text solutions are becoming popular, especially after the advent of voice search services like Alexa.
These solutions bring more efficiency to the table for individuals and businesses alike.
In fact, writing is an essential task that everyone needs to do in their professional careers, be it writing an email, blog post, newsletters, and novels to preparing presentations, documenting ideas, taking notes, and whatnot.
Even if you type faster, this speed is still less than the speed while speaking. The thing is, writing physically is way slower than the actual processing speed of your brain. This means there’s a good scope of saving your time spent on typing stuff.
In this age of automation, it is possible to type with your voice without involving your hands.
Yes, that’s true, and this technology is Speech to Text software.
It helps you type faster using your voice, accelerate your workflow, enhance your efficiency, and provide rest to your hands.
In this article, I’ll discuss a few things about Speech to Text software and how it can benefit you.
Now, let’s discuss some of the best speech-to-text software in the market to help you leverage all these benefits.
- Nuance Dragon
- Notta
- Dictation
- SpeechTexter
- Speechnotes
- Otter
- Rev.ai
- Google Cloud
- IBM Watson
- Microsoft Azure
- Show less
You can trust Geekflare
At Geekflare, trust and transparency are paramount. Our team of experts, with over 185 years of combined experience in business and technology, tests and reviews software, ensuring our ratings and awards are unbiased and reliable. Learn how we test.
First, let’s explore for personal use.
Nuance Dragon
Put your words to work with the help of AI-powered Dargon Speech Recognition solutions and empower your employees to create high-quality documentation.
You can use Dragon Professional Individual to create emails, forms, reports, and more through your voice. It has the latest generation speech engine that transcribes and dictates faster with accuracy so you can save your time on documentation and dedicate it to other important activities. It will also help you tailor the way you work for more significant gains.
Smart Format Rules adapt automatically while writing abbreviations, phone numbers, dates, and more. You can also apply underline or bold by voice. Furthermore, you can import-export custom lists for acronyms or other terminology and create custom voice commands and time-saving macros. The tool will also let you transcribe from .wav, .wma, .dss, .ds2, .mp3, and .m4a.

To use the Dragon Speech Recognition, you must have at least 4 GB RAM, Intel or AMD CPU, free 8 GB of hard disk space, and a Windows 7 or above operating system. Get the mobile edition to create documents, edit, share, and format them from your mobile device.
Whether you are visiting a client at the local coffee shop or job site, the mobile edition will be with you wherever you go. This way, you can get the same solution on your mobile device with 99% accuracy and no limits of words. For data security, Dragon Anywhere Mobile’s cloud solutions maintain a 99.5% uptime and run on geographically dispersed data centers hosted on MS Azure, a HITRUST CSF-certified hosting infrastructure.
All the data are encrypted with 256-bit encryption, and you get unparalleled flexibility, accuracy, and speed. Boost your business productivity with a minimum subscription plan of $500 and get a 30-day money-back guarantee. If you choose a mobile edition, you can take a week’s FREE trial and continue the subscription at $15/month.
Notta
Trusted by millions of users worldwide, Notta is a versatile speech-to-text solution that captures every spoken word accurately. It is available on the Web, iOS, and Android devices.
This incredible tool supports over 50 languages, including English, Spanish, French, Portuguese, Chinese, Japanese, and many more, making it ideal for global users and diverse transcription needs.
Notta boasts a friendly user interface: simply click ‘Instant record’ and you can start dictating your documents, emails, or notes. As you speak, the transcript appears in real-time with automatic timestamps, allowing you to easily navigate through key moments in the audio. It also separates multiple speakers, in case you’re recording a conversation.
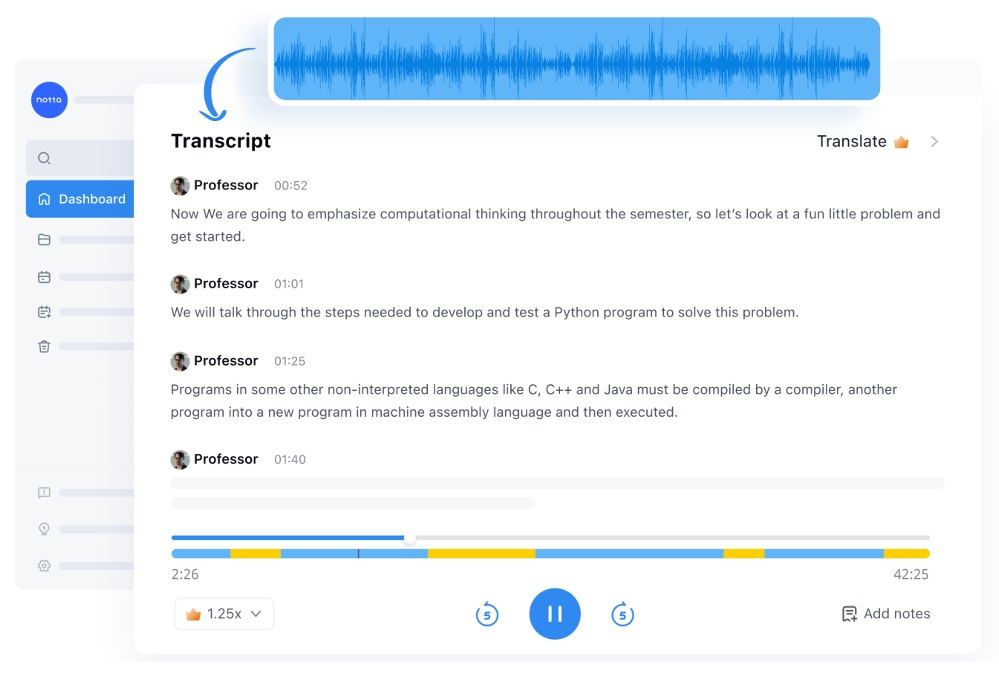
Once done, you can review and edit the text directly within the app, as well as export it to other platforms such as Google Doc and Notion, making it a valuable tool for both personal and professional use. For those seeking efficiency, the automatic summary feature even provides key points and action items of transcribed content, saving you valuable time.
Alongside dictation, you can transcribe online meetings across platforms like Zoom and Google Meet, as well as upload audio & video files to get a transcript.
Finally, Notta employs enterprise-grade security measures and complies with SOC-2 and GDPR, ensuring your data is securely stored.
Dictation
Explore the magical world of speed recognition while writing emails or other documents by using Dictation. It transcribes speech to text accurately in real-time and works directly in Google Chrome.
You can easily add paragraphs, smileys, punctuation marks, and special characters using its voice commands. It also includes many phrases that help you perform certain useful commands. This online application stores texts in the browser; hence, nothing gets uploaded to any site.

For example, if you want to insert a smiley, you can say these words in simple English “Smiling Face”. Dictation can also recognize hundreds of languages and dialects as well and transcribe them easily. Apart from English, it supports languages, including popular ones like Spanish, French, Portuguese, Italian, Hindi, etc.
In addition to that, Dictation utilizes Google Speech Recognition for transcribing spoken words into written text. In fact, it stores the texts under its text editor laced with rich formatting options. You can painlessly copy, tweet, publish, save the text as plain text, play it as speech, print the texts, or email.
SpeechTexter
Start dictating with SpeechTexter and convert your voice into words without any trouble. It is a FREE multilingual speech-to-text app that aims to assist you in transcribing any documents, reports, books, blog posts, etc., by using just your voice.
Its custom dictionary lets you add short commands if you want to insert commonly used data such as addresses, phone numbers, punctuation marks, and so on.

Chrome browser supports this app technology for desktop along with Android OS for smartphones. It is not yet implemented for other browsers that include Chrome on mobiles. SpeechTexter is ideal for writers, bloggers, teachers, students, journalists, etc., from across the globe.
The application offers more than 90% accuracy in general and even 95% accuracy for US English. You can also use this tool to learn how to pronounce certain words in a foreign language while developing fluency in speaking skills.
Features included in SpeechTexter are continuous, powerful speech recognition in real-time, a custom dictionary with custom commands, and 60+ supported languages. Some of these languages include Arabic, Bulgarian, Chinese, Danish, English, German, French, Hindi, Japanese, Korean, Polish, Russian, Spanish, Tamil, Urdu, Zulu, and many more.
Speechnotes
Battle-tested for years, Speechnotes is trusted by thousands and millions of bloggers, writers, thinkers, drivers, and people who prefer easy and fast typing. It makes your life easy as you don’t have to struggle writing long texts anymore.
Speechnotes never stops listening while taking breaks to think or breathe, unlike other speech to text solutions. It includes a built-in keyboard designed to make the writing process faster with easy dictation and tapping for symbols and punctuation.
This speech-enabled notepad empowers your creativity and ideas with features like optional Google Drive backup, so you don’t lose any notes. It offers higher levels of accuracy by incorporating Google Speech Recognition, and you can enjoy 1-tap stamping of the existing date or time.

It works online directly in your Google Chrome browser, so no install or download is required. The solution can run on your desktop, PC, Chromebook, and laptop. In addition, Speechnotess reduces spelling errors, and typos and you can share the document or export and print them with just a single tap.
Other features included in it are auto-capitalization and spacing, auto-saving, drive backup, text edits during dictation, simultaneous voice-typing, widgets for 1-click transcription, and fun emojis. It also recognizes multiple verbal commands such as newline, punctuation, etc.
You will get 10 editable keys that you can use to insert any text, and this tool is also great for common texts, addresses, emails, phrases, greetings, etc., that you frequently use, so you don’t have to retype them each time.
They value user privacy and hence, never store your data or share it with 3rd-parties. As the solution uses speech-to-text engines by Google, only relevant data goes to them. You can also go for an optional Google OAuth to upload files into your Google Drive.
And, the following is good for businesses to build powerful applications; all of them are powered by AI.
Otter
Create rich notes with the help of Otter for your meetings, lectures, interviews, and other essential voice conversations. This AI-powered assistant also helps organizations and teams transcribe important conversations, no matter how big or small they are.
Their new release Otter 2.0, brings more functionality and helps improve productivity and collaboration. Also, their Business plan has capabilities that are tailor-made, especially for SMBs and even enterprises. All you need is to record the voice and review it in real-time. And then, you are free to search, play, organize, edit, and share the conversations from the device of your choice.
You can record conversations right on your web browser or smartphone. Otter also gives you the flexibility of importing and synchronizing the recordings out of other services, and you can integrate it with Zoom as well.

You get live transcribing functionality to stream transcripts in real-time and include rich texts, images, audio, key phrases, and speaker ID within minutes. You can export voice notes and inform others so everyone can be on the same page. You can also create groups and invite collaborators on the projects and organize them effectively.
Otter saves your money and time by letting you transcribe instantly, record, and search for things you need faster. It lets you jump from summary keywords to view instances in your notes, search quickly, accelerate the playback, skip silence and skim through long recordings, and more.
Ambient Voice Intelligence powers Otter, and this is why Otter learns every day and gets smarter. You can train Otter to recognize voices, help you collaborate and work smarter, and learn special phrases or terminologies.
Otter’s Basic plan is FREE, and you get 600 minutes of transcription quota monthly with 40 minutes of transcription/conversation. The paid plans start from US$8.33/month for 6k minutes of monthly transcription quota and 4 hours of transcription/conversation.
Rev.ai
Rev.ai is an excellent speech-to-text live streaming app powered by the top speech recognition API in the world. Just switch on your microphone and start speaking to convert your voice into text.
It helps entertainment and media companies boost the accessibility of all the live broadcast/web content they organize. Rev.ai also helps education institutions to increase the reach of their lectures, events, and webinars with live streaming.
You can also transcribe calls to train your sales or support agents and transcribe meetings and events in real-time. Their English model covers all leading English accents from across the globe, eliminating the need for you to pay extra or switch models to capture different conversations and speakers. Additionally, they are going to add more languages in the upcoming days.

With Rev.ai, you get real-time captions and limited lags. They utilize natural processing language (NPL) to generate highly accurate transcripts that are readable, context-aware, and fully punctuated. Share industry-specific terminology, unique names, etc., to boost transcript accuracy.
You can also filter approximately 600 offensive words quickly out of your captions. You can even add stamps to view the start and end timings of every word. Rev.ai supports multiple streaming protocols, including RTMPS and WebSocket.
All these speech-to-text options are great for personal use and even work for businesses. Now, let’s find out some more API options if you want to build awesome speech-to-text products for your business.
Google Cloud
Convert your voice to text accurately using a powerful API built with the AI technologies powered by Google. It lets you transcribe your stuff stored in files or in real-time. You can deliver a great user experience through voice commands using this solution.
Apart from this, you can gain deep insights regarding customer interaction to enhance your service. Achieve top-level accuracy by applying the most sophisticated deep learning and neural network algorithms of Google for automatic speech recognition (ASR).
No matter where your users are, you can reach out to them globally with a voice recognition solution that supports 125+ languages and their variants. You can deploy the solution wherever you want in the cloud using the API or Speech-to-Text On-Prem to deploy on-premises.

You can incorporate speech transcription easily on your apps using the Speech-to-Text API. You get two options to record your voice, either using a microphone or uploading a file saved on your device. Next, you can choose the language and start transcribing.
You can benefit from features such as speech adaptation that lets you customize speech recognition to transcribe rare words and domain-specific words by providing some hints and boosting the accuracy. You can turn spoken numbers automatically into addresses, currencies, years, etc.
Choose from many trained models available for phone calls and voice control and optimize video transcription to meet domain-specific quality needs. Receive speech-recognition output in real-time as your API processes the provided audio input from microphones or pre-recorded files.
IBM Watson
IBM’s Watson Speech to Text is an advanced speech recognition and transcription solution that is AI-powered. It enables accurate and fast transcription in various languages and uses cases, including speech analytics, agent assistance, and customer self-service.

Getting started with their sophisticated machine learning models is easy, and you can even customize them based on your unique use case, audio characteristics, and domain language. IBM’s AI is best-in-class and embeds seamlessly with Watson Speech to Text.
Use this solution with confidence as your data remains protected under IBM’s sturdy data governance practices. It is designed for global languages, and you can deploy it on-premises or any cloud – private, public, or hybrid.
Reduce wait time of customers by addressing typical queries more efficiently and faster. You can also use it to assist agents during calls with best-action prompts and document search. It also lets you identify customer complaints, call patterns, and agent training problems.
Its features include automatic speech recognition leveraging neural technologies and model training options to improve recognition accuracy with options like language and/or acoustic training.
Microsoft Azure
Speech to Text service by Microsoft Azure converts your voice into text with higher accuracy. This state-of-the-art software supports 85+ global languages along with variants. You can customize models by adding specific words and enhance the accuracy of your text for domain-specific phrases.
Enable analytics or search on your transcribed texts even in the programming languages of your choice. Deploy speech to Text anywhere at the container edges or in the cloud. The software you develop with their technology would be backed by the same powerful technology powering other Microsoft products.
This solution supports audio inputs from multiple sources such as audio files, blob storage, and microphones. You can use speaker diarization for determining the exact words, and you also get highly readable transcripts automatically with punctuation and formatting.
Design your speech-to-text models to learn industry-specific terminologies. You can also overcome barriers in speech recognition, such as accents, background noise, and unique vocabularies. Customize the models by uploading transcripts and audio data and generate custom speech recognition models automatically using your Office 365 data and optimize the accuracy.
Azure offers comprehensive data security and privacy, including certifications by HIPAA, PCI DSS, ISO, HITECH, and FedRAMP. They never store your data, and you are free to view or delete your encrypted speech data or models at any time.
What Is Speech to Text Software?

Speech to Text software is a tool that leverages the technology of speech recognition and then converts the words you speak into written text.
These solutions are enriched with modern technologies like machine learning and artificial intelligence to identify human speech and understand them to process into accurate words.
Many speech-to-text solutions also support multiple languages spoken globally and are not restricted to just English. And they support different audio inputs as well, like microphones and stored files on your computer or cloud.
Why Do You Need Speech to Text Solution?
Speech recognition software aims at making your life easier whether you are a writer, solopreneur, or business owner.
If you perform your business activities all by yourself, you may hardly find time to write your ideas. At this time, this software will help you tons. Or, if you run a business and want to increase organizational efficiency, you can use this software.
It works for everyone and lets you multitask. You don’t have to ram your fingers on your keyboard with rage anymore; all it needs is your voice.
There are many benefits of using a speech to text software, such as:
Saves time
When you have many things on your plate, and you barely get time to write everything, you may lose interesting ideas that knock on your door at that time.
In this scenario, you can use a speech to text software to type your brilliant ideas by capturing your voice. You can also save time when your typing speed is not that fast, and you have to complete a big document at the earliest.
Increases efficiency
Using a speech to text software, you can increase your organizational efficiency by expediting your workflow. You can use it for your presentations, documentation, etc. that otherwise take a lot of time while typing by hand.
Blessing for people with certain disabilities
If anyone in your team has certain physical disabilities or accessibility issues, the speech-to-text software is hugely helpful for them. It can help people have difficulties using their hands due to trauma, dyslexia, or other disabilities that restrict them from using conventional input devices.
They can draft whatever they want using their voice without having to use a keyboard. Moreover, anyone can leverage it to give their hands some rest, especially to those who are tired of writing all day long.
Conclusion
This is the age of automation where you have so many options available to increase your efficiency and reduce manual work. One such solution is speech to text software that helps you type using your voice.
Hence, utilize this technology by choosing the speech-to-text software I’ve mentioned above to save your time and give your hands the rest they deserve.