Serverless computing doesn’t mean you don’t need servers. You just have fewer servers to manage. Let’s look at some of the best runtime platforms to host your serverless applications.
In a traditional application, you manage the entire application logic execution on a VM, physical, or cloud server. However, the trend is changing.
By going to serverless architecture, you offload the application code execution task to a serverless computing platform. It has many benefits.
- You don’t need to worry about hosting runtime (Node.js, Python, Go, etc.)
- Pay what your application consumes (cost-effective)
- Don’t worry about application grown demand (scalable)
- Let the provider manage the security, software updates
- Easy integration with other services offering by the provider
- Fast time to application deployment and changes
It’s a great deal for a developer and business owner where you focus on your code and expert handle the execution. If you are new to Serverless, then you may refer to this introductory course.
Let’s explore the following FaaS (Functions as a Service) platform.
AWS Lambda
AWS Lambda is one of the first to offer a platform where you run your code and administration is managed (behind the scene) by AWS.
Initially, it supported only Node.js, but today, you can run Python, Go, Java, C#.
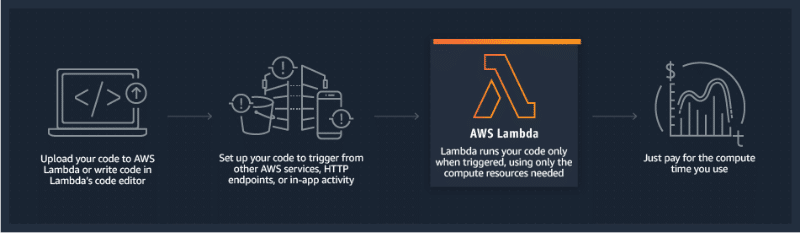
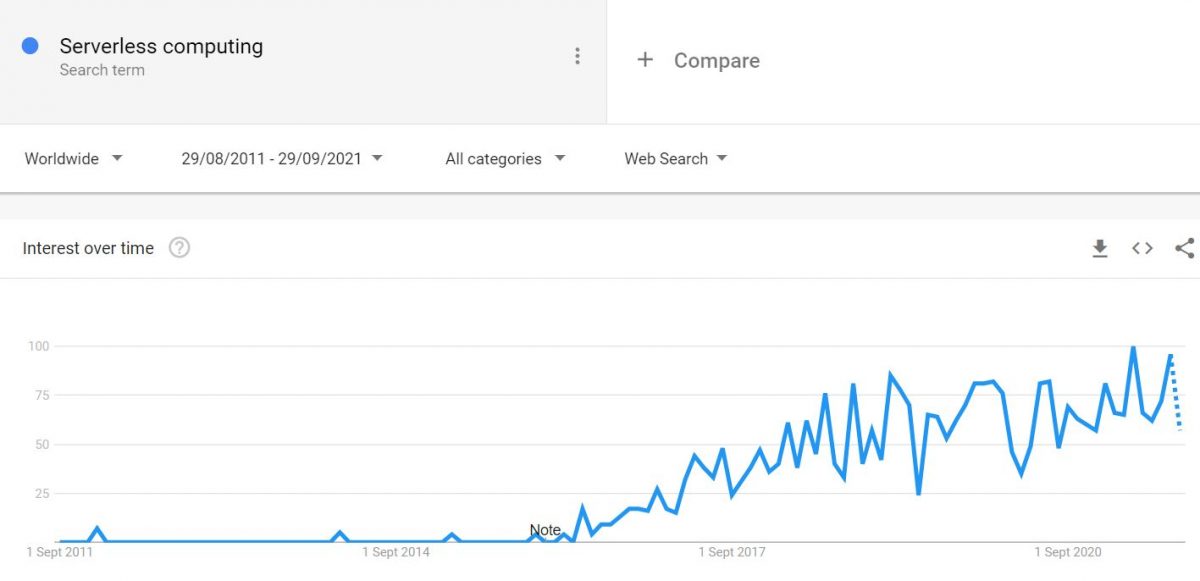
As you can see in the illustration, you need to upload your application code, and Lambda will handle the execution. You can either do it manually or automate it by triggering through AWS services or web applications.
AWS Lambda can be helpful in many real-time scenarios like file processing, streaming, data validation, data transformations, handling API requests, etc.
Some of the features:
- Seamless integration with other AWS products
- Stateless Lambda functions
- High-available and fault-tolerant infrastructure
- Extensive logging and monitoring
- Automatic scaling
- and many more.
Good news if you want to play around, AWS offer 1 million requests and 400,000 GB-seconds compute time at no cost under the free tier.
A free tier would be sufficient for a hobby or small project. If you are interested in learning, then you can check this hands-on online course by Stephane Maarek.
And if you are worried about the regulation, AWS Lambda is HIPPA, PCI, ISO, and SOC compliant.
Cloudflare Workers
Cloudflare is not just a CDN and security company; they offer a lot more than that. Lately, they have introduced Cloudflare workers, which allow you to run JavaScript at their more than 150 data centers worldwide.
Cloudflare uses the V8 JS engine, so if you need to execute your JavaScript at a faster speed, give it a try.

You can integrate workers with the Serverless framework for faster deployment. You can get it started from as low as $5 per month.
They got a few scripts (recipes) for you to take a look at and play around with to get familiar.
AWS Fargate
AWS Fargate is Amazon’s serverless compute solution to run containers. It offers a pay-as-you-go solution that lets you build serverless platforms. Fargate spares you the burden of managing infrastructure and takes care of scaling, patching, and securing servers.
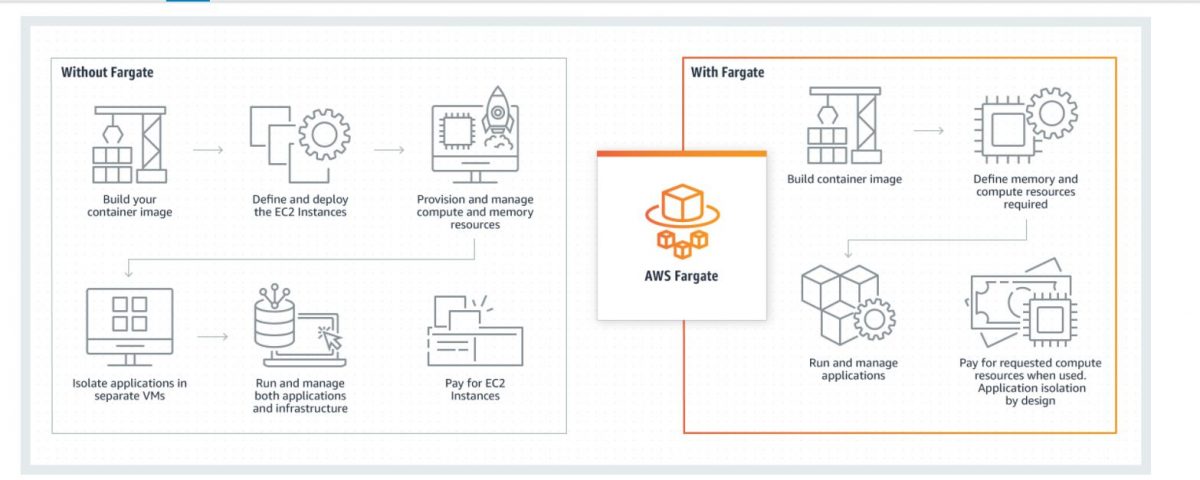
AWS Fargate is compatible with Amazon ECS (Elastic Container Service) and Amazon (EKS) Elastic Kubernetes Container Service.
The benefits offered by AWS Fargate are:
- Focused solution to run containers
- Payment based on CPU resources, memory, and storage used
- Support for AI and ML development environment
- Dedicated runtime environment for ECS and EKS tasks to improve security
- Integration with Amazon CloudWatch Container Insights to let you monitor your applications with ease
Azure Functions
Event-Driven computing supports a large number of programming languages.
- JavaScript
- C#
- F#
- Java
- Python
- PHP
- TypeScript
- Bash
- PowerShell
Azure Functions take care of infrastructure demand by your application and scale up or down as and when required. You don’t have to worry about capacity planning.
You can trigger a function from a web application, HTTP API from a mobile application, blob storage, streaming, webhooks, and a lot more.
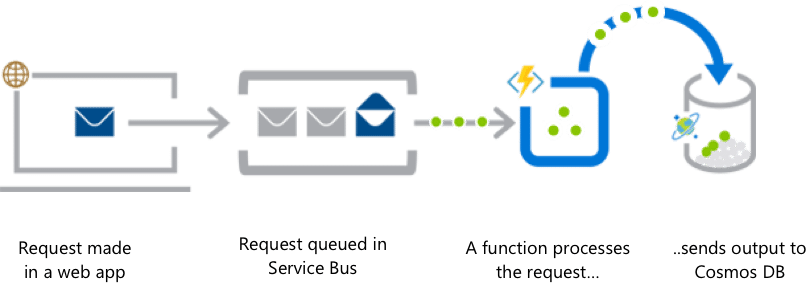
Pricing is based on the total time it takes to run your code. There is no upfront cost, and Azure offers 1 million executions for FREE every month.
Go ahead and leverage Azure Functions to build your serverless application for SaaS products, API, etc.
Google Cloud
Google Cloud offers a bunch of serverless computing solutions.
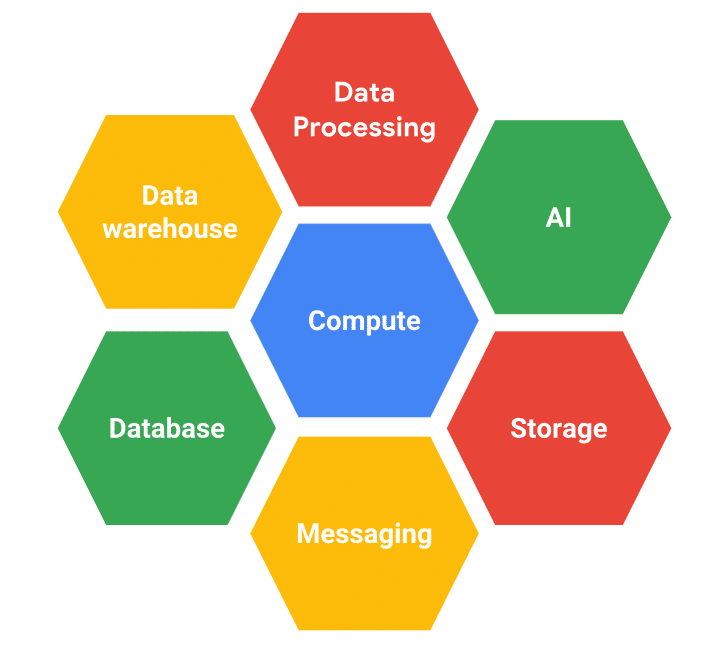
App Engine – a fully managed platform for web and mobile applications. You can deploy your application built in PHP, Python, C#, Node.js, Ruby, Go, etc. You pay for what resources your application consumes and scale based on the demand.
Cloud Functions – an event-driven platform to run Node.js and Python applications in the cloud. You can use Functions to build IoT backends, API processing, chatbots, sentiment analysis, stream processing, and more.
There are more – Storage, Firestore, BigQuery, Dataflow, Pub/Sub, ML engine. Probably, everything you need to build an enterprise-ready serverless application architecture.
IBM Cloud Functions
IBM Cloud Functions is based on Apache OpenWhisk to develop application action that quickly executes on an event trigger.
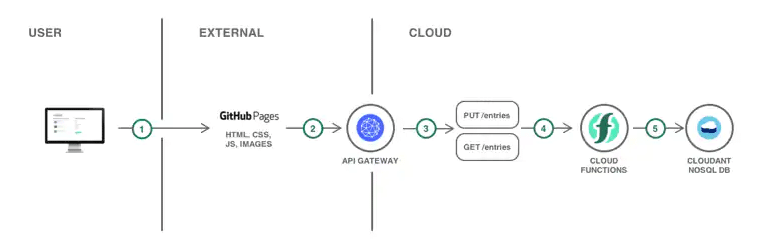
There are some great tutorials on building a serverless platform, API, mobile backend, searchable video, etc., to give you an idea of how it works.
Alibaba Function Compute
An excellent option for China and the International market. Lately, Alibaba announced a serverless computing offering that lets you upload and run code without managing the servers and core infrastructure.
An illustration of real-time IoT message processing serverless flow.
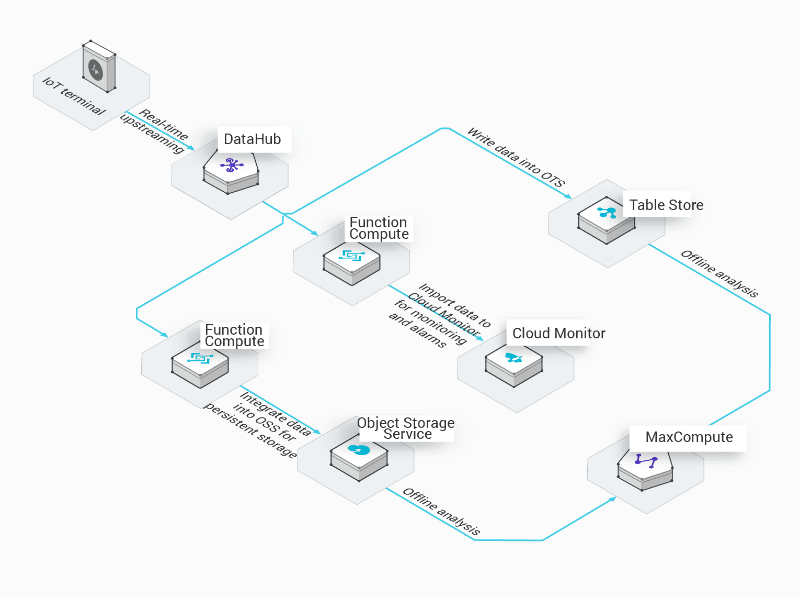
Alibaba offers 1 million requests FREE per month. Good for trying out.
The serverless concept is not just FaaS (functions as a service) but a lot more. I hope the above platform helps you build a robust application without worrying about server administration and maintenance. And most importantly, at a lower cost.
Deno Deploy
Deno Deploy is the perfect choice if you’re searching for hassle-free serverless JavaScript hosting. It lets you deploy your projects without configuration – isn’t that a developer’s dream? Furthermore, it supports edge functions, static sites, and applications.

Deno Deploy is your go-to option for businesses seeking flexibility, scalability, and security in subhosting.
Here are some key highlights of Deno Deploy:
- Customizable user workflows with JavaScript integration
- Secure scaling with multi-tenancy
- Precise resource control in multi-tenant workloads
- Hassle-free serverless JavaScript hosting with Deno Deploy
- Support for edge functions, static sites, and applications
- Ideal for businesses looking for flexible, scalable, and secure subhosting
- No configuration is required for project deployment
You can integrate JavaScript for customizing user workflows, securely scale with multi-tenancy, and maintain precise control over resources in multi-tenant workloads.
DigitalOcean App Platform
Without any underlying infrastructure, this DigitalOcean App Platform allows developers to publish code directly to DigitalOcean servers. It carries the extra burden and helps developers launch apps quickly by deploying code directly from popular repositories.

This tool enhances developer productivity by supporting popular languages and frameworks, resulting in faster development and deployment. Some key features include built-in security, accelerated deployment, valuable insights, quick addition of functions, and more.
Vercel
The creators of Next.js developed the following tool on the list and designed it explicitly for Next.js applications. Vercel essentially serves as a front-end cloud platform, equipping developers with the frameworks, infrastructure, and workflows needed to create a faster, more personalized web experience.

It functions as a comprehensive toolkit for web development, encompassing everything from automated API management to seamless image enhancements and performance optimizations. Vercel provides all the necessary tools to turn your website vision into reality.
Furthermore, it seamlessly integrates with your backend. What’s more, Vercel also offers end-to-end testing on localhost, making it an excellent choice for developers.
Conclusion
Going serverless is a great way to save on hosting and infrastructure management costs. Moving legacy applications can be challenging; I get that. But, if you are building a modern new app, you should consider serverless in your architecture. Here are some of the valuable resources to learn Serverless.
Good luck!