You are using Kubernetes. Great! How about its security?
We all know that Kubernetes has become one of the best container orchestration platforms today. More than 80% of organizations today are leveraging Kubernetes in one way or another. It simply automates provisioning configurations and management of the containers.
But apart from the simplicity, security also has one of the most crucial parts of any containerized application. You must know how to provide robust security to the applications running on the Kubernetes cluster. The security issues have increased exponentially in the last few years, so this domain’s focus is on every organization.
If you know the basics of Kubernetes, then you would know, Kubernetes, by default, assigns an IP address to every port in the clusters and provides IP-based security. But Kubernetes provides only the basic security measures. Unfortunately, when you talk about the advanced security monitoring and compliance enforcement of admins, Kubernetes doesn’t provide that security level. But fortunately, many third-party open-source Kubernetes scanners can help you secure your Kubernetes clusters.
Here are a few benefits of using Kubernetes Scanners:
- Identifies the misconfigurations and vulnerabilities in the cluster, containers, pods
- Provides solutions to correct the misconfigurations and remove the vulnerabilities
- It gives a real-time view of the cluster health.
- Gives more confidence to the DevOps team to develop and deploy the applications on a Kubernetes cluster
- It helps to avoid cluster failure by identifying the issue in the early stage.
Let’s explore the following tools to help you find security vulnerability and misconfiguration to provide security to your containerized applications.
Best Kubernetes Security Scanner
Trivy
Trivy is a vulnerability scanning tool by Aqua Security capable of scanning Kubernetes, AWS, container image, virtual image Git repo (remotely), and more.
Trivy supports most of the popular programming languages and operating systems, and even it can help you find security issues and misconfiguration in IaC files.
Kube Bench
Kube Bench is one of the open-source quality security tools that check if your deployments meet the CIS’s security benchmark (Center for Internet Security).
It supports the benchmark tests for multiple versions of Kubernetes. Apart from that, it also points out the errors and helps in fixing them. It provides the solution to fix the errors. This tool also checks to ensure that user authorization and authentication are proper, the data is securely encrypted. It ensures that deployment allowed up allows the CIS principal.

Kube Bench features:
- Written as Go application
- Test for Kubernetes masters and nodes
- Available as a container
- Tests are defined in YAML, easier to extend and update
- Supports JSON-format output
Checkov
Checkov is a security tool used to prevent cloud misconfigurations during build time for Kubernetes, Terraform, Cloudformation, Serverless framework, and other infrastructure-as-code-languages. It is written in Python and aims to increase security adoption and best practices compliance.
You can run scans using Checkov to analyze the infrastructure as code.
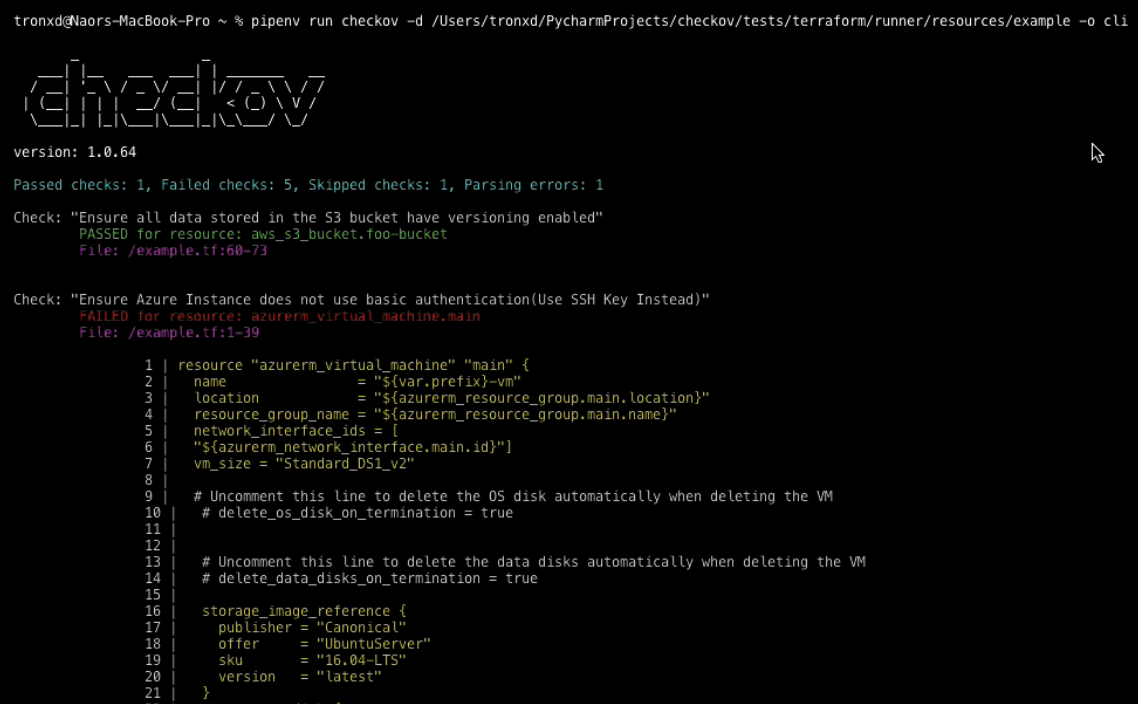
Checkov features:
- Open-source and straightforward to use
- More than 500 built-in security policies
- Compliance best practices for AWS, Azure & Google Cloud
- Supports multiple output format – CLI, JUnit XML, JSON
- Integrate scans to your ci/cd pipelines
- Runs scan for input folder that contains your Terraform & Cloudformation files
MKIT
MKIT stands for Managed Kubernetes Inspection Tool. This tool helps you quickly identify key security risks for Kubernetes clusters and their resources. It has quick and easy ways to assess the misconfigurations in the cluster and the workloads.
The tool comes with an interface that runs on http://localhost:8000 by default. It gives you a view of failed checks and passed checks. In the affected resources section, you will get the details of affected and non-affected resources.
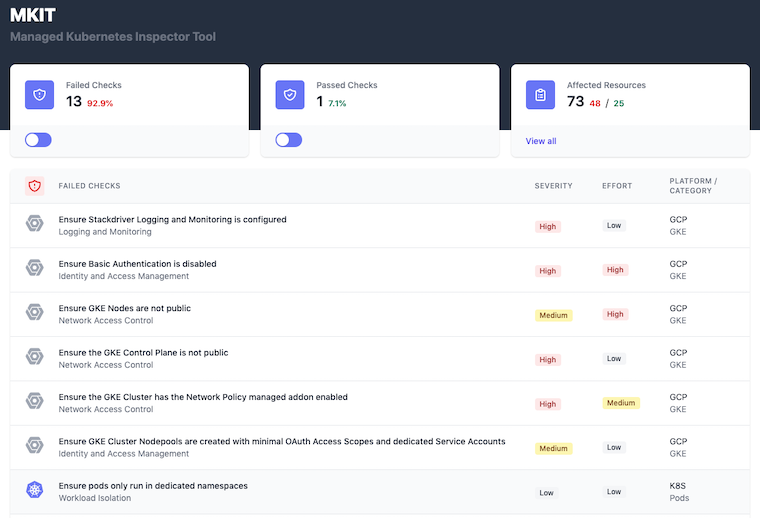
MKIT features:
- Built using all open-source libraries and tools
- Easy to install and use
- Supports multiple Kubernetes providers – AKS, EKS, and GKE
- Stores sensitive data inside the container
- Provides a web interface
Kubei
Kubei is used to assess the immediate risks in a Kubernetes cluster. The majority part of Kubei is written in the Go programming language. It covers all the CIS Docker benchmarks.
It scans all the images used by the Kubernetes cluster, application pods, system pods, etc. You get multiple options to customize the scan in terms of vulnerability level of interest, speed of the scan, scope of the scan, etc. With the GUI it provides, you get to view all the vulnerabilities it finds in the cluster and how to mitigate them.
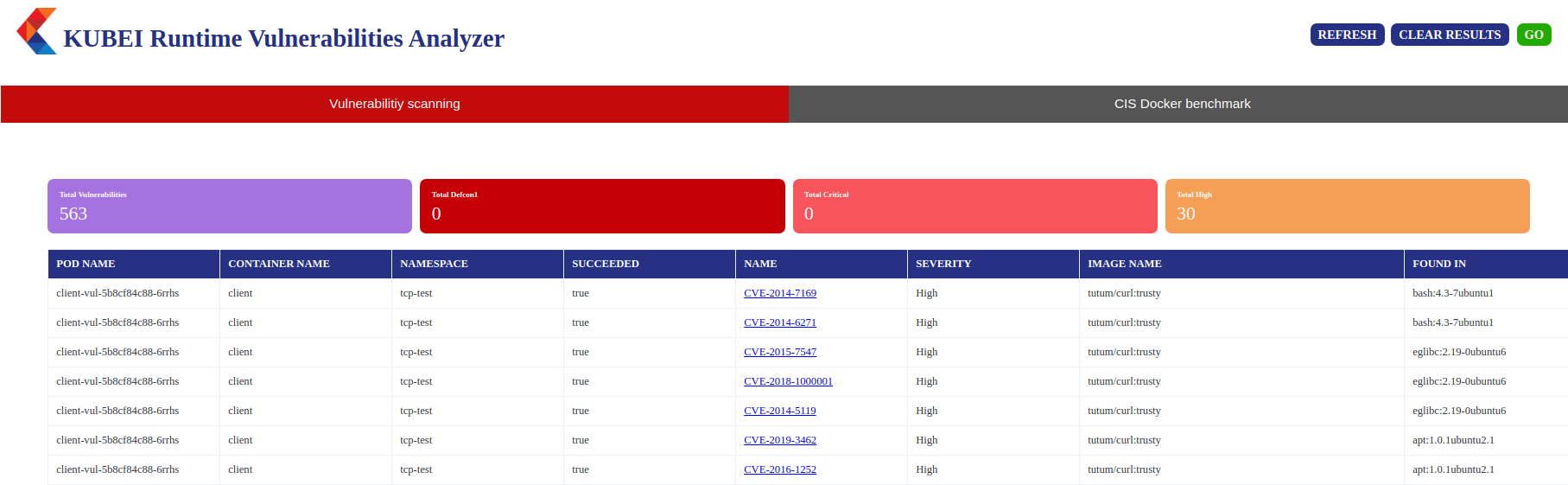
Kubei features:
- Open-Source Kubernetes Runtime Vulnerability Scanner
- Scans public images hosted in your registry
- Provides Real-time status of the cluster health
- Web User Interface for visualization of scans
- Provides multiple custom options for scan
Kube Scan
Kube Scan is a container scanner that comes as a container itself. You install it in a new cluster, after which it scans the workloads that are currently running in your cluster and shows you the risk score and the risk details in the friendly web UI. The risk score is rated from 0 to 10, 0 means no risk, and 10 means high risk.
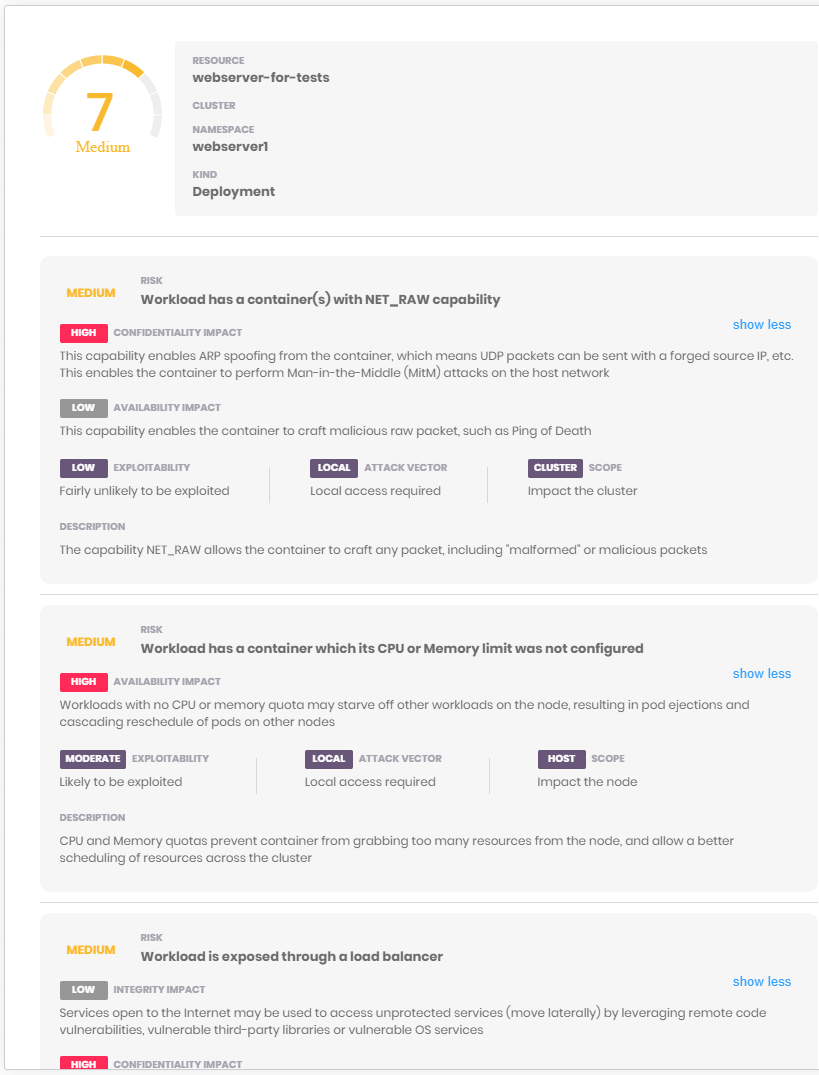
The formula used and scoring rules used by Kube scan is based on KCCSS, the Kubernetes Common Configuration Scoring System, which is an open-source framework. It is similar to CVSS (Common Vulnerability Scoring System). It uses more than 30 security settings like Kubernetes policies, capabilities, privilege levels and creates a risk baseline to provide a risk score. The risk score is also based on the ease of exploitation or the high impact and scope of exploitation.
Kube Scan features:
- Open-source risk assessment scoring tool
- Web UI with risk assessment and risk score details
- It runs as a container in the cluster.
- Rescans the cluster every 24 hours
Kubeaudit
Kubeaudit, as the name, suggests is an open-source Kubernetes cluster auditing tool. It finds the security misconfigurations in the Kubernetes resources and tell you how to resolve them. It is written in the Go language to use it as a Go package or a command-line tool. You can install it on your machine using brew with a single command.
It suggests various practices such as running applications as a no root user, giving read-only access to the root filesystem, avoid giving more privileges to applications in the cluster to prevent common security concerns. It has an extensive list of auditors used to test the Kubernetes cluster’s security concerns, such as SecurityContext of pods.
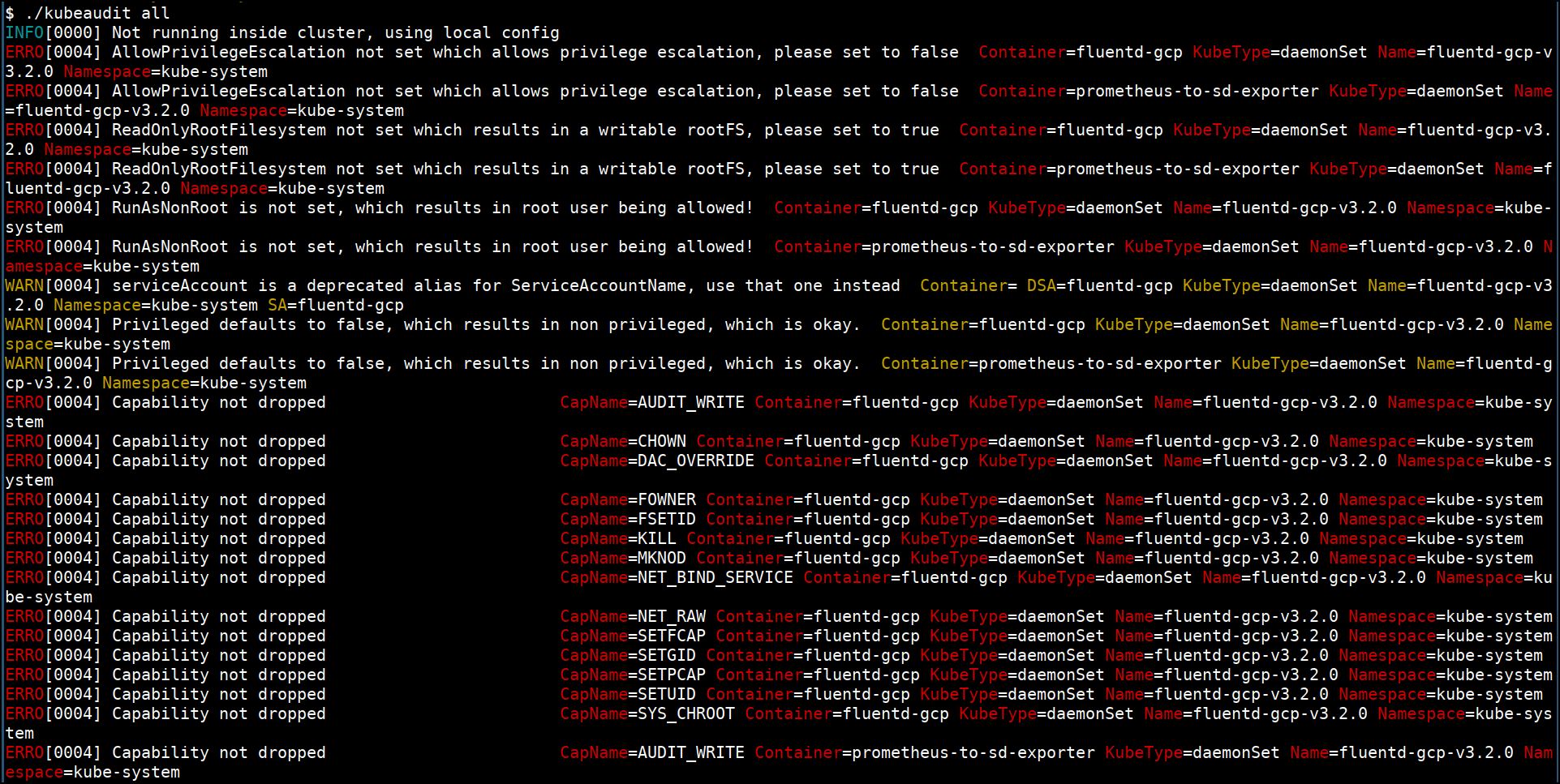
Kubeaudit features:
- Open-source Kubernetes auditing tool
- Provides three different modes – manifest, local, cluster, to audit the cluster
- Gives the audit result at three levels of severity – Error, Warn, Info
- Uses several in-built auditors for auditing containers, pods, namespaces
Kubesec
Kubesec is an open-source Security risk analysis tool for Kubernetes resources. It validates the configuration and the manifest files used for Kubernetes cluster deployment and operations. You can install it on your system using its container image, its binary package, an admission controller in Kubernetes, or a kubectl plugin.
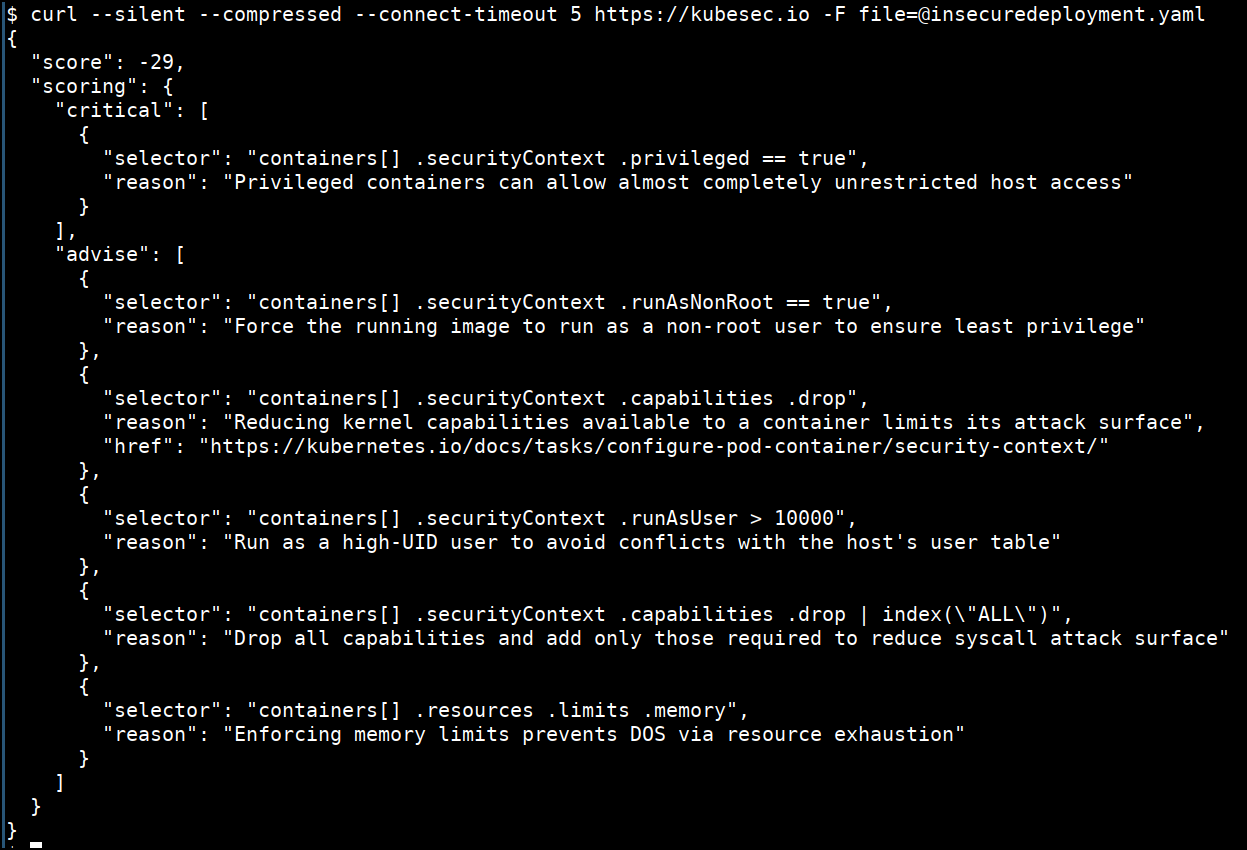
Kubesec features:
- An open-source risk analysis tool
- It comes with a bundled HTTP server that runs in the background at 8080 by default.
- Run Kubesec-as-a-Service via HTTPS at v2.kubesec.io/scan
- It can scan multiple YAML documents in a single input file.
Conclusion
These tools aim to keep the Kubernetes cluster and its resources secure and make it difficult for hackers to break into the applications running inside the cluster. The scanners will help you deploy the applications on the cluster more confidently. So, go ahead and try out these tools and identify the vulnerabilities in them before a hacker does.