Data quality tools can inspect and analyze business data to determine if the data is useful enough to be used for making business decisions.
That said, data quality management is crucial in data centers since cloud complexity is growing.
You need a way to effectively scrub, manage, and analyze data from various sources, including social media, logs, the IoT, email, and databases.
This is where using data quality tools makes sense.
These tools can correct data in case of formatting errors, typos, etc., and eliminate unnecessary data. These can also implement rules, remove costly data inconsistencies, and automate processes to enhance your company’s revenue and productivity.
Let’s understand what data quality means, explore its purpose and common features, and look at some of the best data quality tools you can use.
What do you Mean by Data Quality?
Data quality measures how valuable a given piece of data is based on factors, including completeness, reliability, consistency, and accuracy. Measuring data quality is essential for businesses to identify errors, remove inconsistencies, and enable significant cost savings.
The data quality processes include data ingestion, data profiling, data parsing, data cleansing, standardization, data matching, data execution, data deduplication, data merging, and finally, data exporting.
Why are Data Quality Tools Essential?
One of the success factors for many organizations is the quality of data they use. Quality data provides insights you can trust and leverage in your business processes and decisions while reducing resource waste. This helps enhance your organization’s efficiency and profitability.
But what happens when you don’t use quality data?
Well, if you utilize bad or poor data, it could result in serious consequences for your business. You might end up making poor business decisions, strategies, and analytics with inaccurate, incomplete, and unreliable data.
There are a lot of examples that inaccurate data can cause, such as wrong customer addresses, incomplete customer records, lost sales, improper financial reporting, and more. As a result, your business can suffer tremendously in terms of money, fame, and whatnot.
This is why using quality data is a wise decision for every business, and data quality tools offer you exactly that.
It will help you maintain high-quality data that can enable you to meet various international and local regulatory requirements. Overall, you will improve business agility and efficiency with accurate and reliable data using good data quality software.
Common Features in Data Quality Software

The data quality solutions give procedures and processes to generate quality data so businesses can use valuable data when needed. This helps in improving productivity, reliability, and stability.
Here are some of the common features you can expect in data quality tools:
- Legitimacy and validity
- High accuracy
- Relevance with proper timeliness
- Consistency and reliability
- Comprehensiveness and completeness
- Uniqueness and granularity
- Accessibility and availability
- Data standardization and deduplication
- Data profiling and discovery
- Cleansing and integration
How to Choose the Best Data Quality Tool?

Choosing the right data quality solution is important for businesses to make better decisions. Since many data quality tools are available in the market, deciding what’s best can be confusing. So, keep in mind these points while selecting a data quality tool:
- Identify data challenges in your business
- Understand what data quality tools can be beneficial for your organization that can solve those challenges
- Know the strengths and weaknesses of multiple data cleansing tools to shape your decision
- Check the pricing plans and choose the one within your budget. You can also get a free trial before paying for the tool.
Now, let’s explore some of the best data quality tools with their features and benefits.
ZoomInfo OperationsOS
Get the best B2B high-performing commercial data delivered on your terms. ZoomInfo OperationsOS offers flexible, prime, and accessible data that help you accelerate your business. Its best-in-class fill accuracy, match rates and fill rate offer the best data reliability.
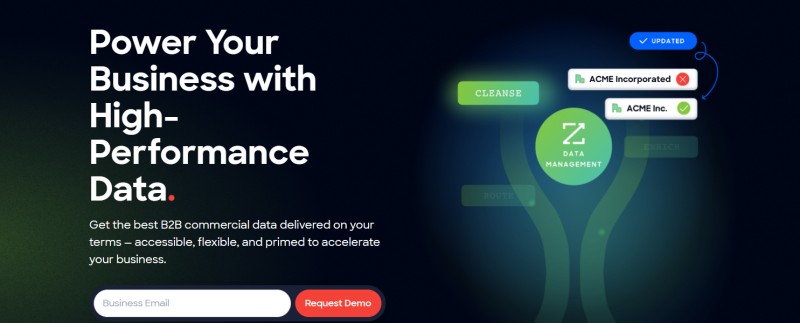
Infuse your MAP, cloud data warehouse, and CRM and identify your customers across the channels to record the most actionable and accurate data. You can tap into the global database of different companies, from small to global enterprises covering hierarchies, technographic, and firmographics.
ZoomInfo OperationsOS offers a single platform for streaming intent, best contact data, and scoops so that you can go beyond just data to the full picture. You can easily integrate B2B data into any workflow or system of your choice by APIs, orchestration apps, flat files, or data shares.
You can use subscriptions and enrich APIs and comprehensive search to integrate with ZoomInfo intelligence and data in real-time. You will also get automated data orchestration for better engagement-ready data.
In addition, ZoomInfo OperationsOS helps you improve your business productivity by integrating its innovative technology and comprehensive data with your platforms.
Talend
Get the best data quality solution for your business with Talend. It lets you quickly identify quality issues, discover patterns, and spot anomalies with the help of graphical and statistical representations.
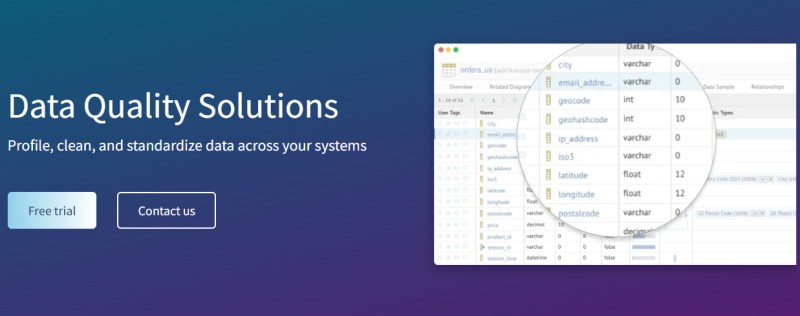
This tool will help you easily clean, standardize, and profile data across your systems. Talend can also address data quality problems as your data flows through the procedures. It has a self-service interface that is convenient for business and technical users.
Talend ensures trusted data will always be available during integration, which effectively enhances sales performance and reduces cost. The built-in Talend Trust Score offers instant, actionable, and explainable confidence evaluations to differentiate cleansed datasets from the data that needs cleansing.
Talend cleanses incoming data automatically with machine learning-enabled validation, standardization, and deduplication. The tool enriches your data by joining it with external sources’ details, such as business identification or postal validation codes.
You can selectively collaborate and share data with trusted users without exposing personal information to unauthorized users. Talend protects sensitive data with masking and ensures compliance with external and internal data privacy and protection regulations.
Get your free trial today.
OpenRefine
Previously known as Google Refine, OpenRefine is a robust tool used for working with messy data, cleaning it, and transforming it from one format to another. You can even extend your data with external data and web services.
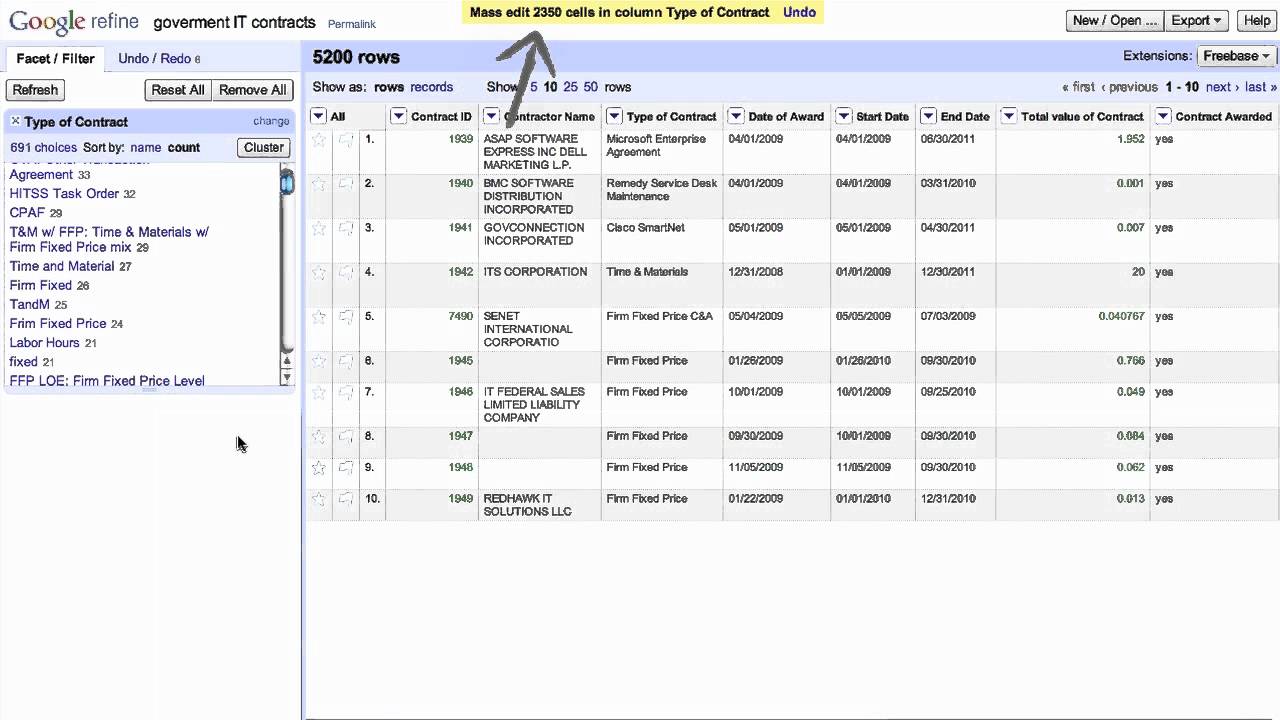
OpenRefine keeps the data private on your system until you want to collaborate or share. It is available in over 15 languages and is a part of the Code for Science and Society. You will get to explore large sets of data quickly with OpenRefine.
Easily extend and link your dataset with multiple web services with the help of OpenRefine. Some web services let OpenRefine upload the cleansed data to a database, such as Wikidata. It also helps you clean and transforms the data.
You can apply advanced cell transformations while importing data in different formats. Here, the cells contain various values that you need to deal with. You can also filter your data and partition it with regular expressions. In addition, you can automatically identify topics by using name-entity extraction on the full-text fields.
Ataccama
Understand the state of the data, improve it, and prevent bad data from getting inside your systems with Ataccama’s self-driven data quality management platform. It will help you continuously monitor your data quality with minimal effort.
Ataccama One automates your data quality management by connecting it with your source. You can leverage AI for quick results, which means better data quality without extra effort. It provides a friendly interface for users to enjoy smarter and faster data quality management.
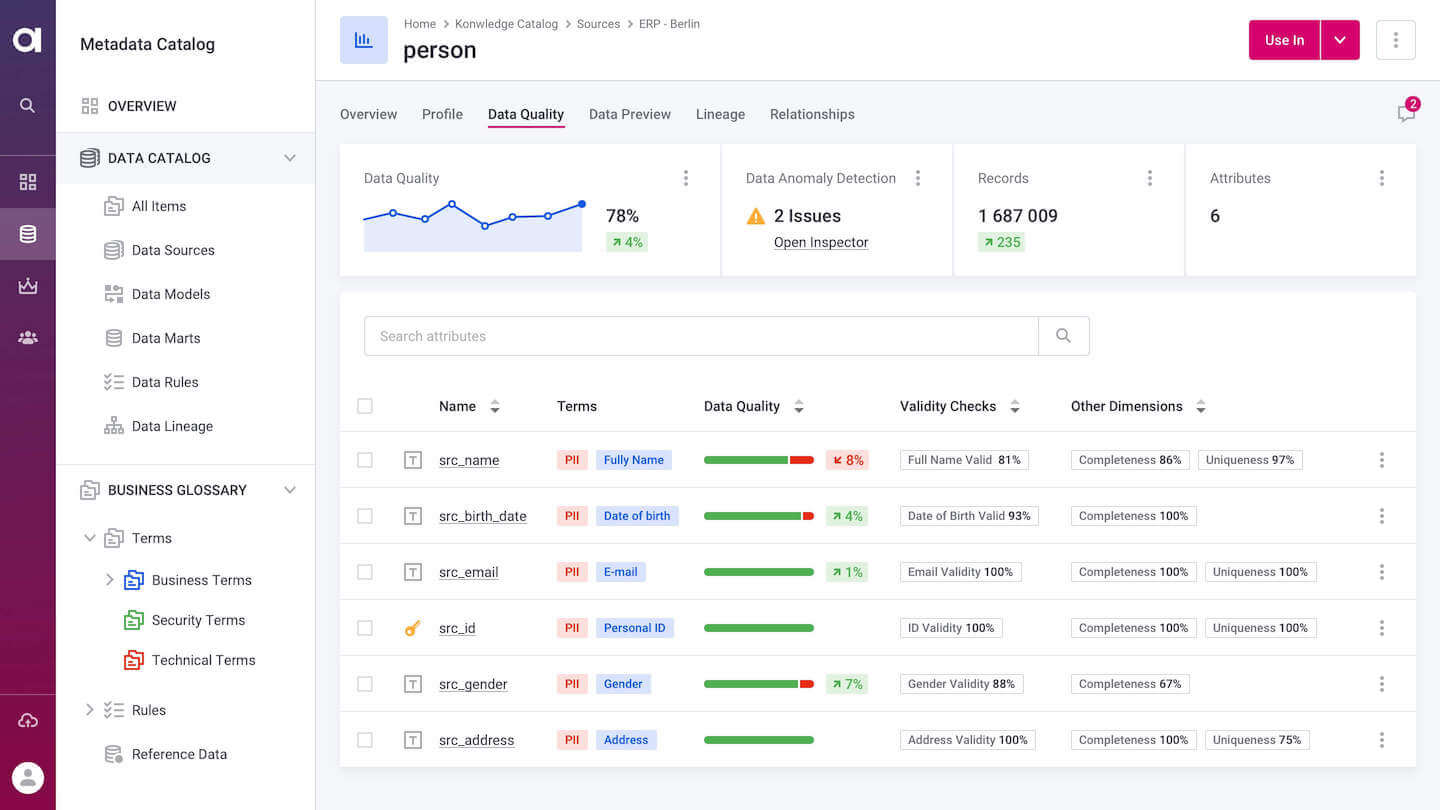
Instantly detect potential issues spot in your data on the go. Ataccama’s self-learning engine identifies business terms and data domains and assigns rules to data quality from a library. It also improves overall quality over time and detects changes automatically to take action immediately if needed.
From data lineage to the MDM and business domains, data quality is needed everywhere; hence, Ataccama successfully provides data quality tools for your business. You can customize the rules easily in a user-friendly interface with the help of rich expression language or sentence-like conditions.
Furthermore, Process any amount of data faster with Ataccama. It is built for technical data teams, highly regulated governance teams, fast analytical teams, and other teams alike. You can also base your decisions on comprehensive and accurate reports.
Dataedo
Increase trust and improve the quality of your data with Dataedo’s data quality tools. It helps you understand where your data is coming from and validate its quality by peaking values and gathering invaluable feedback.
Dataedo lets you identify, understand, and correct flaws in your data to support business processes and effective decision-making. It ensures data quality on different levels:
- You can identify the data source and how it is transformed by data lineage to evaluate the data’s trustworthiness.
- You can use sample data to understand what data is stored on the data assets and ensure it is of good quality.
- Gather feedback on quality from users in the community.
Dataedo never lets you make any bad decisions from your data that can cost your company millions of dollars. It provides context across the data with data lineage diagrams, data documentation, and feedback through a data catalog.
You can give your employees access to the data catalog so that they can understand the data in a better way and reduce making errors.
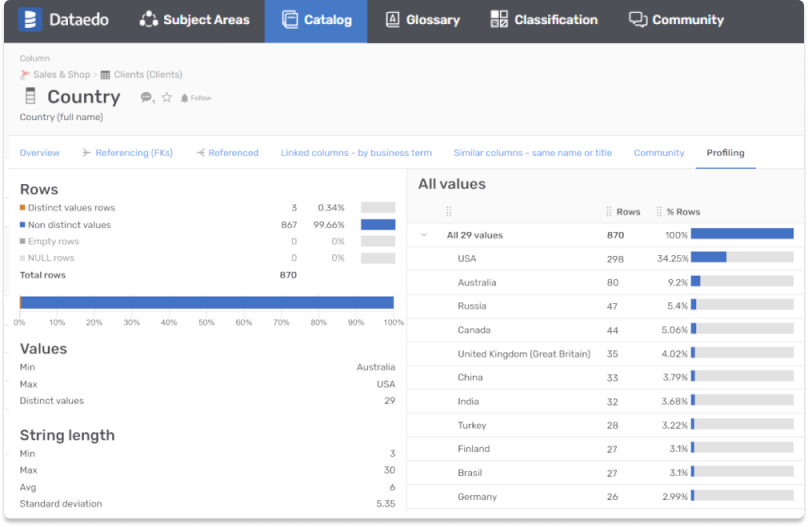
Moreover, use a web data catalog that allows data users to post feedback. You can also add warnings to data assets so that other members can look into it. In addition, increase trust in your data and support data governance, as data quality is essential. Dataedo offers many features, including:
- Data profiling
- Data lineage to map data sources
- Business Glossary
- Discover and document relationships and each data element
- Community-driven quality assurance
Start your 14-day free trial today and stop making poor decisions.
Data Ladder
Get an end-to-end data matching and quality engine with Data Ladder and enhance the accuracy and reliability of the enterprise data environment without friction. The tool can intelligently link, prepare, and integrate data from any source.
Data Ladder’s DataMatch Enterprise (DME) is a software toolkit for code-free profiling, matching, deduplication, and cleansing. It helps in identifying potential problems in your data. You will get an out-of-the-box profiling tool that provides metadata to build a cogent profile analysis across all datasets.
Standardize your organization data and make it consistent, unique, and accurate by using built-in libraries, sophisticated pattern recognition features, and proprietary matching capabilities. Data Ladder’s intuitive interface reduces the number of clicks required to complete data cleansing.
DME employs real-time and powerful data matching algorithms that work on the nature of the data. It contains phonetic, domain-specific, numeric, and fuzzy matching algorithms. In addition, you can tune weight variables and the level of these algorithms to ensure maximum accuracy.
Furthermore, Data Ladder helps you check the validity of the physical mailing addresses in your contact’s databases. Its robust address verification module automatically corrects addresses, adds information, and compares a list of valid addresses. All the data cleansing functions and features are done through Data Ladder’s standardized and RESTful API.
Moreover, you will get intelligent profiling and searching of large datasets, casing names, splitting addresses, transforming data values, ad more. DME also offers high performance, robust matching technology, seamless integration, real-time syncs, an intuitive interface, and quick implementation features.
Experience the single solution for all your data problems. Download your trial today.
Insycle
Instead of spending more time on messy data work, use Insycle to enjoy a modern way to cleanse, update, and organize customer data in a single place. It will allow your team to execute tasks efficiently with the CRM data.

Identify duplicate companies, deals, contacts, etc., by any fields and merge in bulk with the help of flexible rules, preview mode, automation, and CSV report. The tool will enhance personalization by standardizing address, industry, job titles, and other text fields. You can also create and segment targeted campaigns easily by using consistent data.
Import data from CSV files using flexible update controls and templates to avoid overwriting and duplicating important data. Cleanse prior to import and identify improperly and incompletely formatted data and fix it. You can also quickly remove fake contact emails, phone numbers, data, etc.
Update fields ad records in bulk using functions like proper case names, remove whitespace, and more. You will get an easy ETL and the option to compare CSV records to existing ones to match the rows and identify the missing ones.
You can easily select bulk update records and fields with a click without wasting time exporting to CSV and wrestling with IDs, SQL, and VLOOKUP.
Explore your company’s database to know which fields are used and how many values every field has. Additionally, define your data workflows for the tasks to run automatically and automatically, fix data, and maintain a precise database. You can also share updated data views with your teams to work together on the same records.
Try Insycle for free for 7-days and experience the best quality management.
Great Expectations
Understand what to expect from your organization’s data with Great Expectations. It helps teams to eliminate pipeline debt through data documentation, testing, and profiling. It supports a variety of use cases related to data validation issues.
Great Expectations’ framework plays an essential role in data engineering tools by respecting your namespaces in your records and is specially designed for extensibility. It will also allow you to add a production-ready validation to the pipeline daily and maintain data in clean and human-readable documentation.
Furthermore, Great Expectations’ data profilers run automatically to generate data documentation. It also creates other types of documentation, such as data dictionaries, customized notebooks, slack notifications, and more.
In addition, the tool provides fast data and captures insights for future testing and documentation. Its every component is designed to help you maintain better data quality.
Install Great Expectations using pip and see it in action on your company’s data.
Conclusion
No matter how skilled your data quality teams are, data quality issues can still happen unless they are empowered with the right tools. A self-service and all-in-one data quality tool, it can profile data, perform data cleansing, eliminate duplicates, and bring accurate, complete, and reliable data to improve your business strategies and decisions.
Thus, choose the best data quality tool based on your required features and budget. Check whether it has a free trial to understand how it works before you purchase it.
You may also explore the best data wrangling tools to format your data for analytics.