When it comes to scrum delivery, people usually expect a release execution after the end of a sprint. This means directly after a successful demo presentation to the client.
But I always wondered how this could be such an automatic expectation. Especially if you consider the below possible activities that must happen before or alongside.
- Develop and complete all stories within the sprint. Some might be completed sooner, but most of the time, the stories are completed just before the end of the sprint. Maybe even after the demo presentation, to be open here.
- Perform all scheduled tests over the sprint content to ensure the code to be released is production ready.
- Catch up with discovered bugs and fix them in time before the release happens.
- Ensure the deployment pipeline is updated with the latest content and the pipeline itself is reliable to execute.
- Run the pipeline on all relevant environments to bring them into the latest state from code as well as data perspective.
- Prepare release notes and communicate with the client the impact of the release and what exactly will change afterward.
- If relevant, synchronize with other parallel scrum teams to ensure the dependent content will be released simultaneously. Nothing should be missing to ensure your release content will work as expected.
- On top of all this, go through all the scrum ceremonies. Not only related to the current sprint but also those targeted for the next sprint (e.g., stories refinement sessions).
Now imagine the sprint has two weeks.
Release activities by themselves take time and people to complete. But it can’t take too much. Just after the last day of the sprint comes directly the day one of the next sprint, and the circle shall begin again.
Does the expectation of release after each sprint still look so automatic?
Release Content Processing
If all processes within the sprint are automated, there is a possibility to just “pull the trigger” and install the latest code version into production at the end of each sprint. The problem is that I have never experienced such a perfect state of the scrum team.
If it is actually the case in some small-scale private businesses, I really envy them. But the reality in the corporate world is that a scrum team won’t achieve that level of maturity. On the contrary, release processes are usually connected with time-consuming activities reaching most of the following sprint, affecting that sprint from content and all metrics perspectives. The release is just a stressful act nobody on the team is happy to go through.
So I was after discovering the next best scenario for dealing with releases.
The conclusion was to make every second sprint the Release Sprint. Here is what it means.
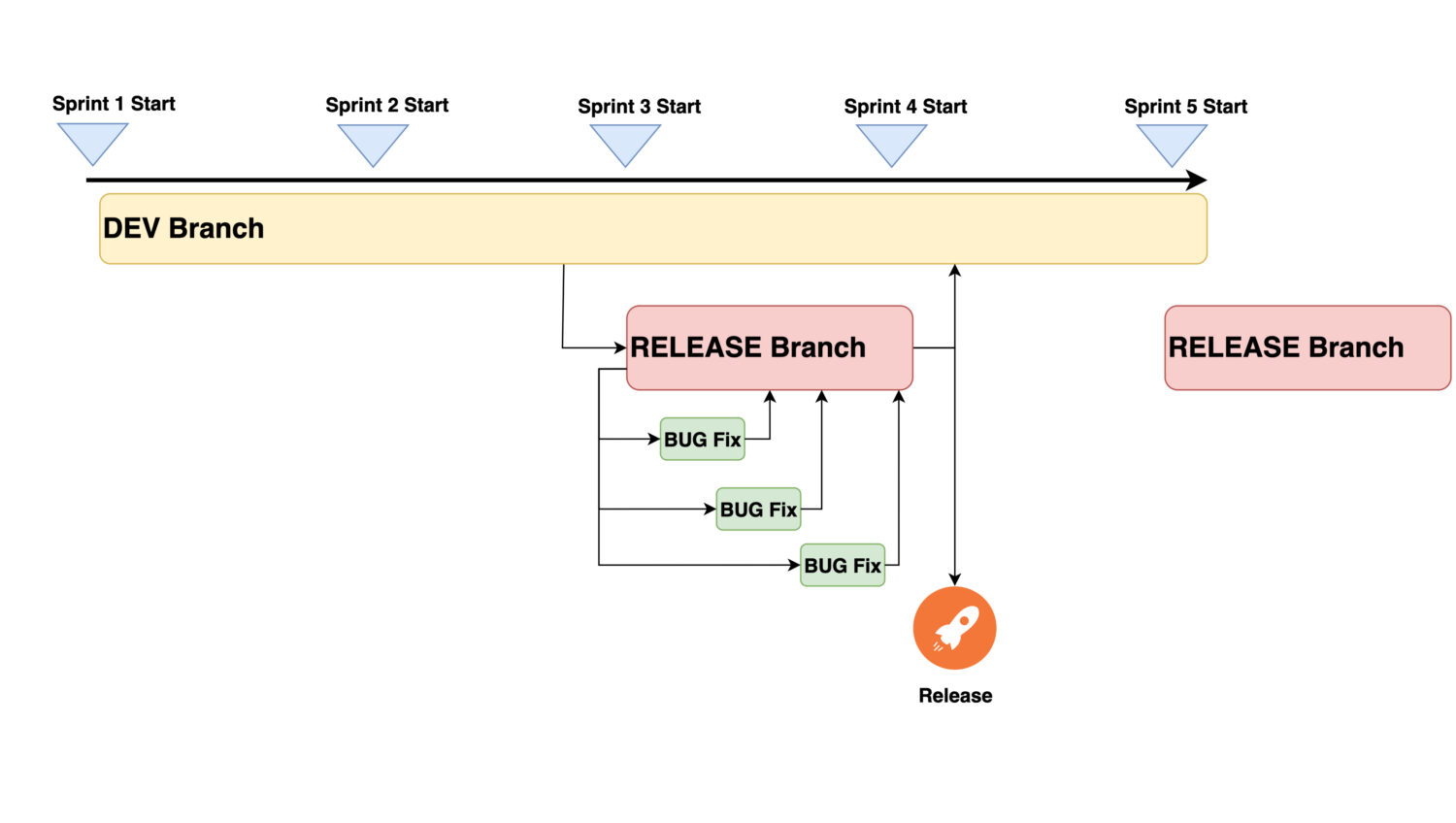
Separate Code Version For The Next Release

This is about handling separate branches in the GIT repository. There are many ways to approach the same problem, and all of them can be successful. But for the purpose of this article, I’m going to keep things simple to demonstrate the approach and its impact.
In order to impact the ongoing development activities as low as possible, it is important to separate the content for the next release into a separate branch. Let’s call it Release Branch. With this, the following will be resolved:
- The development team can continue in activities and merge into the main branch’s new stories without disruption.
- There is no risk that the release content will be affected by unexpected code modifications from the scrum team.
- Testing activities can be executed in an isolated space. Here, only changes necessary for resolving the testing will be introduced.
- Since the release pipeline will deploy into production only the content from the Release Branch, we have a clear process and full control over the to-be-released content. It can’t happen that some unexpected commit into the Git branch would break already tested code.
So just keep the next release content aside and let it conclude to a stable state, ready for release.
Time The Releases So That They Work Repeatedly
I gave up on the ambition to do the release after every single sprint was completed. It was super clear this would have no chance of working. At least not with such side effects as:
- impacting the next sprint development content,
- being unable to stabilize the release content,
- catching up with all the required testing activities, etc.
So the aim was to execute the release by the end of every second sprint. That would imply the following:
- A release will always contain stories from the last two already-finished sprints. Since the release is performed within the current (active sprint), this sprint content is not included in the release yet.
- There is a whole one-sprint time for necessary testing activities and bug fixes to be completed.
- The release owner has enough time to gather release-relevant information (test cases, release notes, etc.) with the non-release sprint. This way, they can operate basically standalone and keep the rest of the development team working on new stories.
- In case of bug discovery, the Release owner can quickly connect with the concrete developer to fix the problem and return to the current sprint content. So there should always be some percentage time allocated from the team’s capacity to support this bug fixing. How much exactly can be discovered over time.
It is clear the users won’t get the latest sprint content inside the latest release. But over time, this will become irrelevant. They will get two sprints of content with each next release anyway, after each second sprint.
This looks like a good compromise between rapid delivery satisfaction and keeping up with the scrum activities without significant disturbance.
Execute The Release Deployment

When testing, bug fixing, and pipeline readiness activities are successfully completed, it is quite a straightforward process to execute the production pipeline and complete the release to production.
Since it is deployed from a standalone branch, this can be basically an unnoticed and invisible activity. Nobody needs to know. If that is the case, it is the best possible implementation of the release deployment.
A prerequisite for that is to have created a solid automated DevOps pipeline. Not only used to deploy to the production environment but also to all the other lower-level environments. This might include dev, sandbox, test, quality assurance, performance environment, etc. This shall be a one-click to deploy all solutions for every single environment.
The release should not be a pain point or stress. Or a nightmare everybody fears and keeps preparing for that day for one week. No – instead, if nobody notices this ever at all, this is the best sign of a successful release.
Merge Back The Release Branch Into The Development Branch
The Release Branch now contains some special content that does not exist in the regular ongoing development branch. It is related to all the fixes that were implemented during the testing period. This content needs to be merged back into the development branch to ensure the fixes will stay there even after the next release.
At that point, the latest Release Branch serves as an emergency ready-to-redeploy production code. If an urgent high-priority issue needs to be resolved shortly after production deployment, it can use this branch. It is simple to take this code and implement the fix inside. This is still the exact copy of the current production code without any new unreleased content.
Finally, once the new testing period starts, the previous release branch can be deleted and replaced by a new one. The new one is again created as a copy from the current development branch.
Establish Regular Releases
And now we have it 😀—a solid process for approaching the release. The only thing missing is making a commitment to keep it regular. In this case, after every second sprint.

By keeping it regular, we actually set the ground to make it easier to accomplish, mainly because:
- If the release is after a not-too-long time, there is not so much new content to install to production. The increment is small and considered stable.
- Now so much new content means not overwhelmingly a lot of testing activities and test case creation. Fewer communications, agreement calls, and collaboration with stakeholders about what everything needs to be re-validated. They will also agree that it is not so long since the last release. So less importance is put into this action.
- The team will get used to this cycle; over time, it will be a natural part of the team.
- As a side effect, development and testing environments often get data refreshed. That is anyway needed for each new testing cycle. So it won’t be just another scheduled activity to do. Rather, an action that is already part of the established process. This change of perspective has so much influence on the atmosphere of the team. One would not believe that.
Conclusion
This chapter concludes my previous posts about the topic of the scrum lifecycle. Also, it is about what proved to be working in real life.
Often, teams start the agile way and do many things wrongly. Then they evolve, eventually, and start to do things differently. This series could help some of them to do this change faster.
Neither is this release approach the only one workable, nor is it without problems. Those will still exist, and the teams have to deal with them. Then improve what is possible and forget what has no sense.
But from what I know, this approach, although a simple one, proved that change is possible. From chaotic, unpredictable sprints to more stable delivery with regular releases that one can rely on and plan with. And it does not require a special, highly complicated methodology – just simple rules and willingness to follow the plan.