Google JAX or Just After Execution is a framework developed by Google to speed up machine learning tasks.
You can consider it a library for Python, which helps in faster task execution, scientific computing, function transformations, deep learning, neural networks, and much more.
About Google JAX
The most fundamental computation package in Python is the NumPy package which has all the functions like aggregations, vector operations, linear algebra, n-dimensional array and matrix manipulations, and many other advanced functions.
What if we could further speed up the calculations performed using NumPy – particularly for huge datasets?
Do we have something that could work equally well on different types of processors like a GPU or TPU, without any code changes?
How about if the system could perform composable function transformations automatically and more efficiently?
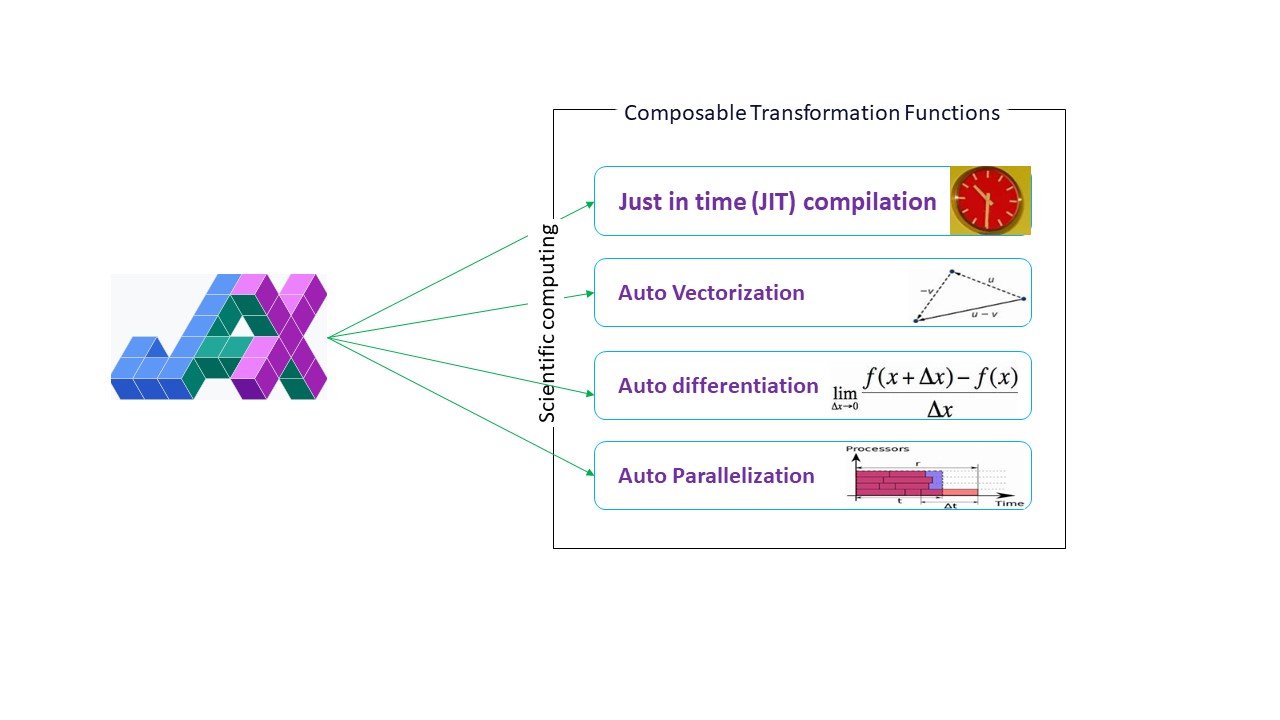
Google JAX is a library (or framework, as Wikipedia says) that does just that and perhaps much more. It was built to optimize performance and efficiently perform machine learning (ML) and deep learning tasks. Google JAX provides the following transformation features that make it unique from other ML libraries and help in advanced scientific computation for deep learning and neural networks:
- Auto differentiation
- Auto vectorization
- Auto parallelization
- Just-in-time (JIT) compilation
All the transformations use XLA (Accelerated Linear Algebra) for higher performance and memory optimization. XLA is a domain-specific optimizing compiler engine that performs linear algebra and accelerates TensorFlow models. Using XLA on top of your Python code requires no significant code changes!
Let’s explore in detail each of these features.
Features of Google JAX
Google JAX comes with important composable transformation functions to improve performance and perform deep learning tasks more efficiently. For example, auto differentiation to get the gradient of a function and find derivatives of any order. Similarly, auto parallelization and JIT to perform multiple tasks parallelly. These transformations are key to applications like robotics, gaming, and even research.
A composable transformation function is a pure function that transforms a set of data into another form. They are called composable as they are self-contained (i.e., these functions have no dependencies with the rest of the program) and are stateless (i.e., the same input will always result in the same output).
Y(x) = T: (f(x))
In the above equation, f(x) is the original function on which a transformation is applied. Y(x) is the resultant function after the transformation is applied.
For example, if you have a function named ‘total_bill_amt’, and you want the result as a function transform, you can simply use the transformation you wish to, let’s say gradient (grad):
grad_total_bill = grad(total_bill_amt)
By transforming numerical functions using functions like grad(), we can easily get their higher order derivates, which we can use extensively in deep learning optimization algorithms like gradient descent, thus making the algorithms faster and more efficient. Similarly, by using jit(), we can compile Python programs just-in-time (lazily).
#1. Auto differentiation
Python uses the autograd function to automatically differentiate NumPy and native Python code. JAX uses a modified version of autograd (i.e., grad) and combines XLA (Accelerated Linear Algebra) to perform automatic differentiation and find derivates of any order for GPU (Graphic Processing Units) and TPU (Tensor Processing Units).]
Quick note on TPU, GPU, and CPU: CPU or Central Processing Unit manages all the operations on the computer. GPU is an additional processor that enhances the computing power and runs high-end operations. TPU is a powerful unit specifically developed for complex and heavy workloads like AI and deep learning algorithms.
Along the same lines as the autograd function, which can differentiate through loops, recursions, branches, and so on, JAX uses the grad() function for reverse-mode gradients (backpropagation). Also, we can differentiate a function to any order using grad:
grad(grad(grad(sin θ))) (1.0)
Auto differentiation of higher order
As we mentioned before, grad is quite useful in finding the partial derivatives of a function. We can use a partial derivative to calculate the gradient descent of a cost function with respect to the neural network parameters in deep learning to minimize losses.
Calculating partial derivative
Suppose a function has multiple variables, x, y, and z. Finding the derivative of one variable by keeping the other variables constant is called a partial derivative. Suppose we have a function,
f(x,y,z) = x + 2y + z2
Example to show partial derivative
The partial derivative of x will be ∂f/∂x, which tells us how a function changes for a variable when others are constant. If we perform this manually, we must write a program to differentiate, apply it for each variable, and then calculate the gradient descent. This would become a complex and time-consuming affair for multiple variables.
Auto differentiation breaks down the function into a set of elementary operations, like +, -, *, / or sin, cos, tan, exp, etc., and then applies the chain rule to calculate the derivative. We can do this in both forward and reverse mode.

This is not it! All these calculations happen so fast (well, think about a million calculations similar to the above and the time it may take!). XLA takes care of the speed and performance.
#2. Accelerated Linear Algebra
Let’s take the previous equation. Without XLA, the computation will take three (or more) kernels, where each kernel will perform a smaller task. For example,
Kernel k1 –> x * 2y (multiplication)
k2 –> x * 2y + z (addition)
k3 –> Reduction
If the same task is performed by the XLA, a single kernel takes care of all the intermediate operations by fusing them. The intermediate results of elementary operations are streamed instead of storing them in memory, thus saving memory and enhancing speed.
#3. Just-in-time Compilation
JAX internally uses the XLA compiler to boost the speed of execution. XLA can boost the speed of CPU, GPU, and TPU. All this is possible using the JIT code execution. To use this, we can use jit via import:
from jax import jit
def my_function(x):
…………some lines of code
my_function_jit = jit(my_function)Another way is by decorating jit over the function definition:
@jit
def my_function(x):
…………some lines of codeThis code is much faster because the transformation will return the compiled version of the code to the caller rather than using the Python interpreter. This is particularly useful for vector inputs, like arrays and matrices.
The same is true for all the existing python functions as well. For example, functions from the NumPy package. In this case, we should import jax.numpy as jnp rather than NumPy:
import jax
import jax.numpy as jnp
x = jnp.array([[1,2,3,4], [5,6,7,8]])Once you do this, the core JAX array object called DeviceArray replaces the standard NumPy array. DeviceArray is lazy – the values are kept in the accelerator until needed. This also means that the JAX program does not wait for results to return to the calling (Python) program, thus following an asynchronous dispatch.
#4. Auto vectorization (vmap)
In a typical machine learning world, we have datasets with a million or more data points. Most likely, we’d perform some calculations or manipulations on each or most of these data points – which is a very time and memory-consuming task! For example, if you want to find the square of each of the data points in the dataset, the first thing you’d think of is creating a loop and taking the square one by one – argh!
If we create these points as vectors, we could do all the squares in one go by performing vector or matrix manipulations on the data points with our favorite NumPy. And if your program could do this automatically – can you ask for anything more? That’s exactly what JAX does! It can auto vectorize all your data points so you can easily perform any operations on them – making your algorithms much faster and more efficient.
JAX uses the vmap function for auto-vectorization. Consider the following array:
x = jnp.array([1,2,3,4,5,6,7,8,9,10])
y = jnp.square(x)By doing just the above, the square method will execute for each point in the array. But if you do the following:
vmap(jnp.square(x))The method square will execute only once because the data points are now vectorized automatically using the vmap method before executing the function, and looping is pushed down into the elementary level of operation – resulting in a matrix multiplication rather than scalar multiplication, thus giving better performance.
#5. SPMD programming (pmap)
SPMD – or Single Program Multiple Data programming is essential in deep learning contexts – you’d often apply the same functions on different sets of data residing on multiple GPUs or TPUs. JAX has a function named pump, which allows for parallel programming on multiple GPUs or any accelerator. Like JIT, programs using pmap will be compiled by the XLA and executed simultaneously across the systems. This auto parallelization works for both forward and reverse computations.

We can also apply multiple transformations in one go in any order on any function as:
pmap(vmap(jit(grad (f(x)))))
Multiple composable tranformations
Limitations of Google JAX
Google JAX developers have thought well about speeding up deep learning algorithms while introducing all these awesome transformations. The scientific computation functions and packages are on the lines of NumPy, so you don’t have to worry about the learning curve. However, JAX has the following limitations:
- Google JAX is still in the early stages of development, and though its main purpose is performance optimization, it doesn’t provide much benefit for CPU computing. NumPy seems to perform better, and using JAX may only add to the overhead.
- JAX is still in its research or early stages and needs more fine tuning to reach the infrastructure standards of frameworks like TensorFlow, which are more established and have more pre-defined models, open-source projects, and learning material.
- As of now, JAX doesn’t support Windows Operating System – you’d need a virtual machine to make it work.
- JAX works only on pure functions – the ones that do not have any side effects. For functions with side effects, JAX may not be a good option.
How to install JAX in your Python environment
If you have python setup on your system and want to run JAX on your local machine (CPU), use the following commands:
pip install --upgrade pip
pip install --upgrade "jax[cpu]"If you want to run Google JAX on a GPU or TPU, follow the instructions given on GitHub JAX page. To set up Python, visit the python official downloads page.
Conclusion
Google JAX is great for writing efficient deep learning algorithms, robotics, and research. Despite the limitations, it is used extensively with other frameworks like Haiku, Flax, and many more. You will be able to appreciate what JAX does when you run programs and see the time differences in executing code with and without JAX. You can start by reading the official Google JAX documentation, which is quite comprehensive.