Graph databases store highly-connected dense data and process queries efficiently. But, do you know when to use which graph database? Read to learn more.
“Data is the new oil.” The growth of any organization is based on how they effectively store and use data. 2.5 quintillion bytes of data are being generated each day. So, we need fault-tolerant systems and warehouses where data can be stored and managed effectively. Initially, relational databases were used.
But as time passed, the amount and type of data changed rapidly. Hence, there was a need to store video, audio, images, etc. This was the trigger point for the development of SQL, NoSQL databases, Hadoop, graph databases, etc. Each has its own use cases and deals with different data formats. Graph databases were developed to simplify operations on data and for effective storage.
Graph Databases
A graph is a data structure represented in the form of nodes and edges. A database is a collection of tables that stores data and the relationships between the data. A graph database is a database that stores data in nodes and the relationships that exist within data in the form of edges. Graph databases help handle real-time queries and manage many-to-many relationships between entities effectively.
Popular graph data models include property graphs and RDF graphs. Analytics and querying are mostly done using property graphs. Data integration is done using RDF graphs. The difference between Property and RDF graphs is that RDF graphs are represented in the form of triples, i.e., subject, predicate, and object.
Graph databases store data in nodes and the relationship between the data in the form of edges between the nodes. The edges in the graph can be directed (uni-directional) or undirected (bi-directional).
Query processing is done by traversing through the graph. Graph traversal algorithms that help to find the path from one node to another, the distance between the nodes, find patterns, loops within the graph, and the possibility for the formation of clusters, etc., are used for answering queries effectively.

Applications of Graph Databases
Graph databases are used in fraud detection. The nodes/ entities could be people’s names, addresses, date of birth, etc., and some fraudulent IP addresses, device numbers, etc. When a fraudulent node interacts with a non-fraudulent node, links are formed between them and are marked as suspicious.
Social media websites use graph databases to show recommendations of the people we might like to connect with and the content we want to view. It does this with the help of graph traversals in the database.
Network mapping and infrastructure management, configuration items, etc., are also effectively stored and managed using graph databases.
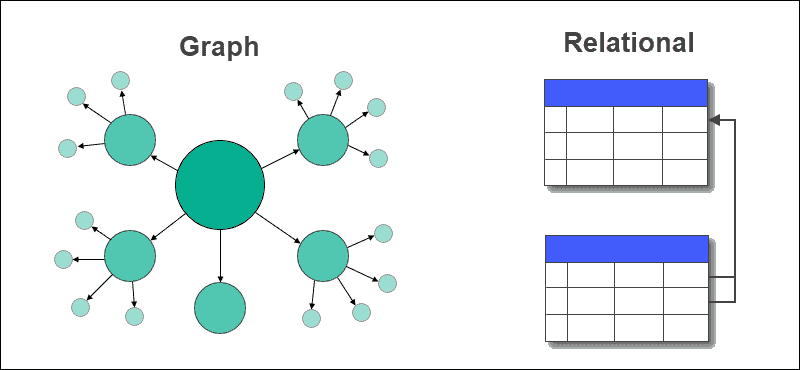
Graph Database vs. Relational Database
In a graph database, tables with rows and columns are replaced with nodes and edges. The relationships between data are stored on edges in a graph database.
A relational database stores relationships between tables using foreign keys and other tables. Extracting data or querying is easy and doesn’t require complex joins in a graph database, but it is not the case with relational databases.
Relational databases are most suited for use cases that involve transactions, whereas graph databases are suitable for relationship-heavy and data-intensive applications.
Graph databases support structured, semi-structured, and unstructured data, while relational databases need to have a fixed schema.
Graph databases satisfy dynamic requirements, while relational databases are generally used for known and static problems.
Let’s now look at the best graph database solutions.
Cayley
Cayley is an open-source graph database developed by Apache 2.0. It was built using Go and works on linked data. Cayley is the database used while building Google’s Freebase and knowledge graph. It supports multiple query languages like MQL and Javascript with a Gremlin-based graph object.

It is easy to use, fast and has a modular design. It can integrate and interact with various backend stores like LevelDB, MongoDB, and Bolt. It supports various third-party APIs written in multiple languages like Java, .NET, Rust, Haskell, Ruby, PHP, Javascript, and Clojure. It can be deployed in Docker and Kubernetes. The key areas in which Cayley is used are Information Technology, Computer Software, and Financial Services.
Amazon Neptune
Amazon Neptune is known for performing exceptionally well on highly connected datasets. It is reliable, secure, fully managed, and supports open graph APIs. It can store billions of relationships and query data with extremely low latency of some milliseconds.

The Neptune graph data model consists of 4 positions, namely, subject (S), predicate (P), object (O), and Graph (G). Each of these positions is used to store the position of the source node, target node, the relationship between them, and their properties.
It also uses a cache that speeds up the execution of reading queries. The data is stored in the form of DB clusters. Each cluster comprises a primary DB instance and read-replicas of DB instances. Neptune is highly secure as it uses IAM Authentication, SSL certification, and log monitoring. It is also easy to migrate data from other sources into Amazon Neptune. It also ensures resiliency by creating replicas and periodic backups. Some companies using Neptune include Herren, Onedot, Juncture, and Hi Platform.
Neo4j
Neo4j is a scalable, secure, on-demand, and reliable graph database. Neo4j was built using Java, using Cypher as the query language. It uses the Bolt protocol, and all transactions occur over an HTTP endpoint. It is much faster in answering queries as compared to other relational databases. It doesn’t have the overhead of complex joins, and its optimizations work well when the data set size is large and highly connected. It offers the advantage of graph storage along with the ACID properties of a relational database.

Neo4j supports various languages like Java, .NET, Node.js, Ruby, Python, etc., with the help of drivers. It is also used in graph data science, analytics, and machine learning workflows. Neo4j Aura DB is a fault-tolerant and fully managed cloud graph database. Companies like Microsoft, Cisco, Adobe, eBay, IBM, Samsung, etc., use Neo4j.
ArangoDB
ArangoDB is an open-source multi-model database. The multi-model approach enables users to query the data in any query language of their choice. The nodes and edges of ArangoDB are JSON documents. Every document has a unique id. Relationships between two nodes are indicated in the form of edges, and their unique ids are stored. Its good performance is due to the presence of a hash index.

Traversals, joins, and searches in the databases are enhanced. It helps in designing, scaling, and adapting to various architectures. It plays an important role in complex data science tasks like feature extraction and advanced search.
ArrangoDB can run in a cloud-based environment and is compatible with Mac Os, Linux, and Windows. LDAP Authentication, data masking, and encryption algorithms ensure the database is secure. It is used in risk management, IAM, fraud detection, network infrastructure, recommendation engines, etc. Accenture, Cisco, Dish, and VMware are some organizations using ArangoDB.
Check out Free and Open Source Database for Your Next Project
DataStax
DataStax is a NoSQL cloud database-as-a-service built on Apache Cassandra. It is highly scalable and uses cloud-native architecture. It is reliable and secure. Every document stored in a DataStax has an index that helps in easy searching and fast retrieval of data. Shards are created over the indexed data. Various data sources can be used to build applications with Datastax Enterprise tools, Kafka and Docker.

The data collected from sources is sent to a Hadoop ecosystem and DataStax. Hadoop manages security, operations, data access, and management by interacting with DataStax. The data is refined using Datastax development and operations tools.
The analyzed information is then used for statistical analysis, enterprise applications, Reporting, etc. As it is cloud-based, customers pay for what they use, and the pricing is reasonable. Verizon, CapitalOne, TMobile, and Overstock are some companies that use DataStax.
Orient DB
OrientDB is a graph database that manages data effectively and helps create visual representations for showcasing data. It is a multi-model graph database and was built using Java. It stores data in the form of key-value pairs, documents, object models, etc. It consists of 3 significant components: graph editor, studio query, and command line console.

A graph editor is used to visualize and interact with data. The Studio query interface is used to execute queries and provide output immediately in a pictorial and tabular format. The command line console is used to query data from OrientDB. It has a distributed architecture with multiple servers that can perform read and write operations. Replica servers are used for performing read and query operations. It supports indexing and is also ACID-compliant. Some of the companies using OrientDB are Comcast Corporation and Blackfriars Group.
Dgraph
Dgraph is a cloud graph database that supports GraphQL. It was built using Go. It minimizes the network calls and reduces latency by maximizing concurrent query processing. The seamless integration of Dgraph with GraphQL helps in the easy development of GraphQL backend applications.

A GraphQL mutation is passed through a Lambda function which interacts with the database and a data pipeline. This simplifies query processing. It is horizontally scalable, meaning the number of resources is increased with increasing queries and data. It provides various features like JWT-based authorization, data visualizer, cloud authentication, data backups, etc. Some organizations that use Dgraph include Intuit, intel, and Factset.
Tigergraph
Tigergraph is a property graph database developed using C++. It is highly scalable and performs advanced analytics on highly connected data. It uses a native graph structure for the storage of data and a graph processing engine for processing data. The database is stored on disk and in memory and also uses a CPU cache for fast retrieval. It uses the Map Reduce function for parallel data processing.
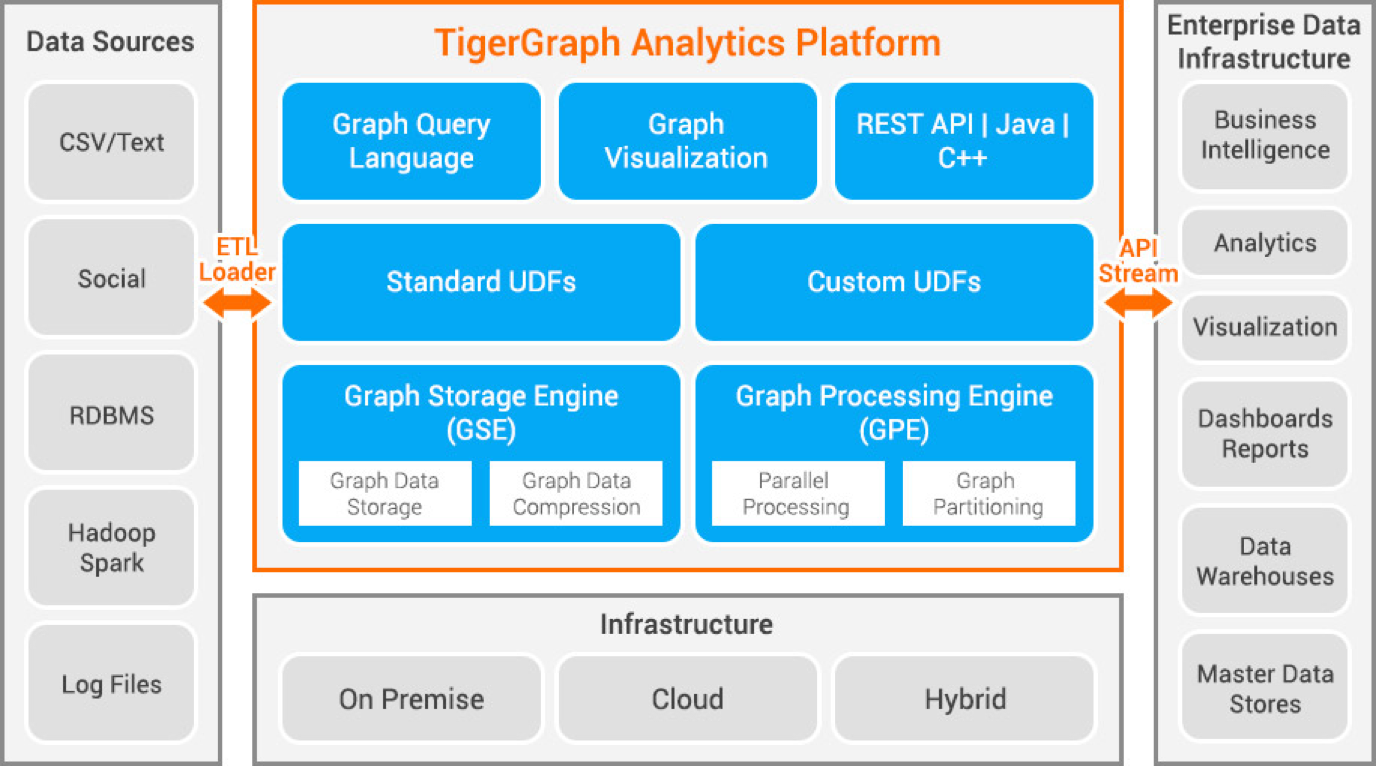
It is extremely fast and scalable. It does parallel computation and provides real-time updates. It uses data compression techniques and compresses the data by 10x. It partitions the data across servers automatically, saving the user the time and effort required to shard data manually. It is used for fraud detection in households, supply chain management, and improving health care. JPMorgan Chase, Intuit, and United Health Group are some organizations using Tigergraph.
AllegroGraph
AllegroGraph uses entity-event knowledge graph technology to perform analytics and decisions on highly connected, complex, and dense data. The data is stored in the JSON and JSON-LD format in the nodes of the graph. It uses the REST protocol architecture. It also deals with extremely large datasets by sharding the data based on specific criteria and spreading it across multiple knowledge-base repositories.
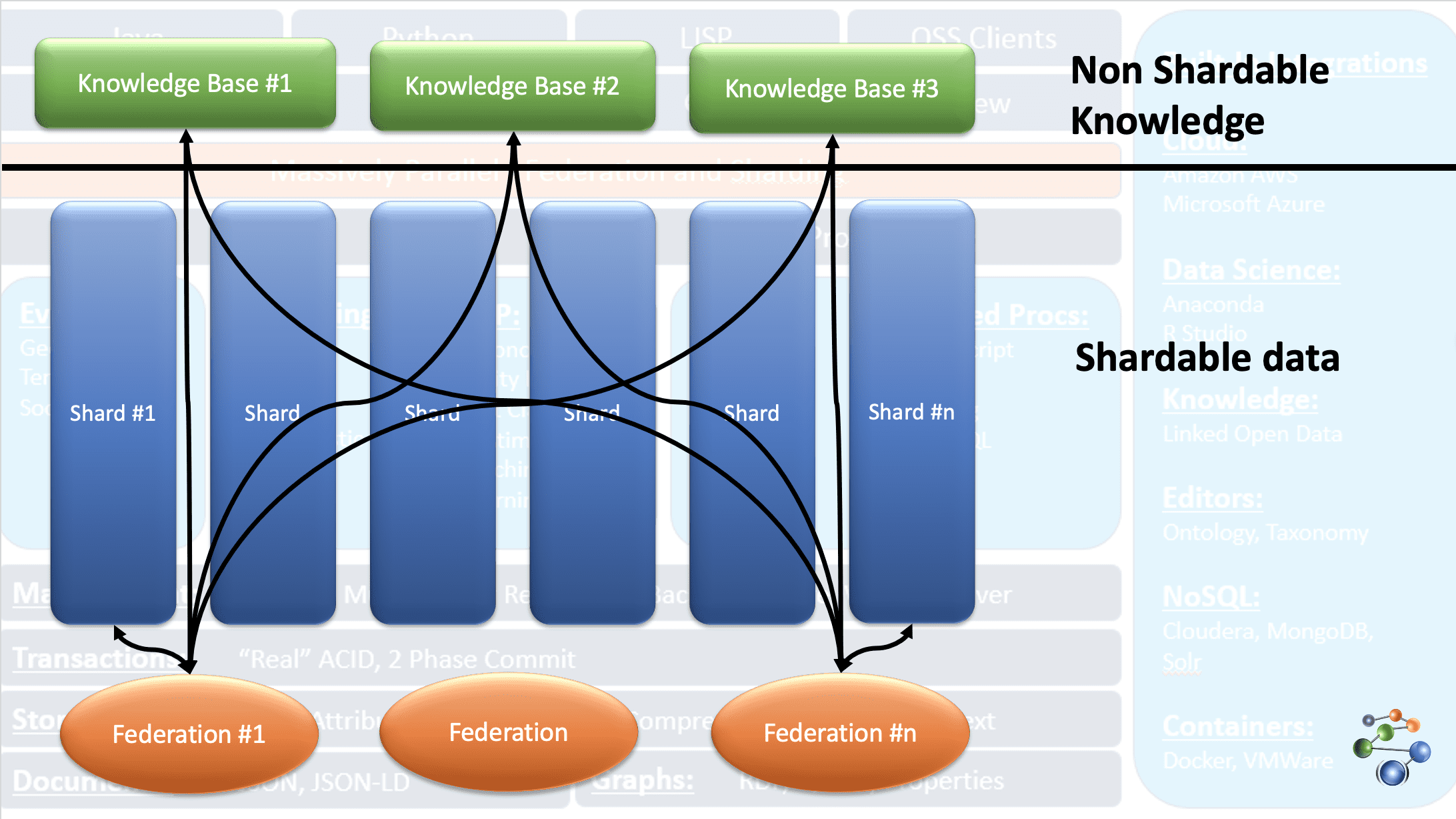
This is possible because of the FedShard feature of the AllegroGraph database. The execution of queries takes place by combining the federations with knowledge-base repositories. It supports XML schema types and uses triple indices. It stores geospatial data like latitudes & longitudes and temporal data like date, timestamp, etc. It is compatible with Windows, Mac, and Linux too. It is used in fraud detection, health care, entity identification, risk prediction, etc.
Stardog
Stardog is a graph database that performs graph data virtualization and links data from data warehouses and data lakes without physically copying the data into a new storage location. Stardog is built on RDF open standards. It supports structured, semi-structured, and unstructured data. This kind of materialization done by Stardog offers flexibility. It is the only graph database that combines knowledge graphs and virtualization.

Stardog uses an inference engine powered by AI to process and provide query outputs efficiently. It is an ACID-compliant graph database. Concurrent reads and writes are supported. It handles complex queries with ease due to the “state-of-the-art” architecture. It is used in IT Asset Management, data management & analytics and provides high availability. Some companies that use Stardog are Cisco, eBay, NASA, and Finra.
Final words
Graph databases help to query many-to-many relationships easily and store data effectively. They are scalable, secure, and can be integrated with many third-party tools, APIs, and languages. In recent years, they have been integrated with the cloud and provide the best performance.
They simplify complex joins into simple queries making it an easy task for the developers. Data-intensive tasks like IoT and Big Data are also graph databases. These will continue to evolve and will surely expand to other use cases in the future.