Many times I’ve seen a “smart” AI give a polished, convincing answer that was completely wrong. For example, a legal assistant might confidently answer compliance questions but completely miss a regulation update released just weeks ago. The response sounds correct, yet it’s outdated, and in real business scenarios, that kind of mistake can be costly.
The model wasn’t broken. It was doing exactly what it was trained to do (work with data it had already seen).
This happens because generic models like GPT or Claude are generalists, not specialists. They’re trained on broad, internet-scale data, not on your internal policies, proprietary documents, or recent updates.
If you’re wondering how to train AI on your own data, you don’t need to build a model from scratch. What you actually need is to customise an existing model in the right way.
Today, there are two proven ways to train AI on custom data: Retrieval-Augmented Generation (RAG) and Fine-Tuning. I’ve seen most teams get this decision wrong on their first attempt. So in this guide, you’ll learn how each works, when to use one over the other, and how to build a reliable AI system without over-engineering or unnecessary costs.
Why Train AI on Custom Data?
You might think a powerful prompt was all you needed. At first, it works. The AI sounds smart, answers quickly, and feels impressive. But over time, cracks start to show, and they all trace back to one core issue: “Generic models don’t understand your business.”
The Limitations of Generic Models
Large language models are trained on broad, public datasets with a fixed knowledge cutoff. This means they don’t know your internal documents, company rules, or recent updates unless that information is provided every time. As a result, answers may sound confident but fail to reflect how your business actually operates.
This limitation becomes dangerous in areas like HR, legal, finance, or compliance. A model that doesn’t know your rules will confidently default to generic ones and that’s a risk most businesses can’t afford.
When Prompt Engineering Hits a Ceiling
Prompt engineering is useful, but it’s not a long-term solution. You can keep adding instructions, examples, and constraints, but at some point the prompts become brittle and hard to maintain. Every new edge case requires another rewrite, and consistency starts to break down across conversations.
This is usually the moment teams realize they can’t scale with prompts alone. If you’re repeatedly explaining the same context or correcting the same mistakes, it’s a clear sign that it’s time to train the AI model on custom data instead of overloading the prompt.
Moving beyond generic chat
Training an AI on your own data changes the role it plays in your organization. Instead of acting like a generic chatbot, it becomes a trusted internal system that reflects how your business actually operates.
You retain control over your intellectual property, because your knowledge lives in your data not in ad-hoc prompts. You achieve brand voice consistency, which is especially important for customer-facing or policy-driven responses. And you improve data privacy, since sensitive information doesn’t need to be repeatedly pasted into conversations.
This is the real value of AI training on your own data: not just better answers, but safer, more consistent, and more reliable systems that can actually scale with your business.
RAG vs. Fine-Tuning
Before moving into the step-by-step process, it’s important to clearly understand RAG and Fine-Tuning. These two approaches solve different problems, and confusing them often leads to higher costs and poor results.
At a high level, both methods help customise a pre-trained model, but they do so in fundamentally different ways.
Retrieval-Augmented Generation (RAG)
Instead of memorizing facts, the AI looks them up in your database before answering.
Here’s the simplest way I explain RAG.
Imagine you hire a smart engineer. They’re capable, but you don’t train them on every detail of your company. Instead, you give them access to a large internal library of policies, documents, manuals, and records. Whenever someone asks a question, the engineer doesn’t depend on memory. They pull the most relevant documents, read them, and then answer.
That’s exactly how RAG works.
With RAG, the model itself remains unchanged. Your documents, such as policies, manuals, FAQs, or internal records, are stored externally in a searchable format. When a question is asked, the system retrieves the most relevant pieces of information and passes them to the model as context. The model then generates an answer based on the retrieved data.
The key insight:
With RAG, the knowledge stays outside the model. This makes the system flexible and easy to update.
Best for:
RAG is ideal when you’re training an LLM with custom data that updates frequently, such as inventory systems, HR policies, customer orders, internal documentation, news, or technical support content. When information changes often, RAG lets you update data instantly without retraining the model, keeping costs and maintenance low.
RAG: Real Pricing Breakdown
RAG is much cheaper because there is no training involved. Most costs come from infrastructure, not compute. You store your data in a vector database and retrieve it when needed.
Typical RAG setups cost a few hundred dollars per month. Managed vector databases usually fall in the $100 to $500 monthly range, while self-hosted options can be much cheaper. The initial setup, such as document ingestion and chunking, usually takes a few days of engineering time.
Ongoing costs are low. You only update documents and re-index when needed. There is no retraining and no need for GPUs.
In total, RAG usually costs $200 to $1,000 to set up, and $100 to $500 per month to run. This is often around one-tenth the cost of fine-tuning.
Fine-Tuning
Fine-tuning changes the model’s internal weights so it “thinks” differently, not just answers differently.
Using the same example, fine-tuning is like fully onboarding that engineer into your company. Instead of giving them a library, you spend weeks training them in your codebase, standards, and unique workflows. Over time, they stop looking things up they know how things are done.
That’s what fine-tuning does to an LLM. You take a pre-trained model and train it further on a smaller, highly curated dataset. This process adjusts the model’s internal parameters so your domain knowledge, tone, and logic become part of the model itself.
The key insight:
With fine-tuning, the knowledge is embedded inside the model’s neural network. There’s no external lookup step during inference.
Best for:
Fine-tuning works best when you want to train your own language model to follow a specific style, maintain consistent tone, format code or responses precisely, or apply complex medical or legal logic. It’s especially effective for static or repetitive tasks where the rules don’t change often.
Fine-Tuning: Real Pricing Breakdown
Fine-tuning is expensive mainly because it requires heavy compute. Serious fine-tuning usually needs powerful GPUs. A single high-end GPU can cost tens of thousands of dollars, and most real setups need more than one. If you use the cloud instead, you still pay high hourly rates, and training often runs for days. One training run alone can cost between one and five thousand dollars.
Memory costs also add up. Large models need large amounts of VRAM. A common rule is around 16 GB of VRAM per billion parameters. For a 7B model, traditional fine-tuning can require over 100 GB of memory. Techniques like LoRA or PEFT reduce this, but training still takes hours or days and is not free.
Engineering and data costs are often ignored, but they matter a lot. Fine-tuning needs ML engineers, training pipelines, monitoring, and evaluation. Data must be cleaned and labeled, which takes time and money. Even a small team can spend two to four weeks on one fine-tuning cycle.
In practice, for a small company, fine-tuning a 7B model usually costs between $2,000 and $10,000 or more per training cycle, once you include infrastructure and labor. If the data changes, you often have to pay this cost again.
Should You Choose RAG or Fine-Tuning?
The easiest way to make this decision is to separate facts from behavior. Once you do that, the choice becomes much clearer.
Use RAG for facts
Facts change all the time. Policies get updated, documentation evolves, and new information is added regularly. If this kind of data is built directly into the model, you’ll have to retrain it every time something changes which quickly becomes expensive and hard to manage.
RAG solves this by keeping your data outside the model. The AI simply looks up the latest information before answering. This makes RAG the best choice when accuracy and up-to-date information matter.
If your AI needs to answer questions based on current policies, internal documents, or live data, RAG is the safer and more practical option.
Use Fine-Tuning for style
Style and behavior don’t change as often as facts. Once you decide how your AI should speak formal or friendly, short or detailed that usually stays the same.
Fine-tuning is useful here because it teaches the model how to respond, not what to look up. It helps enforce consistent tone, structured answers, and predictable behavior across all responses.
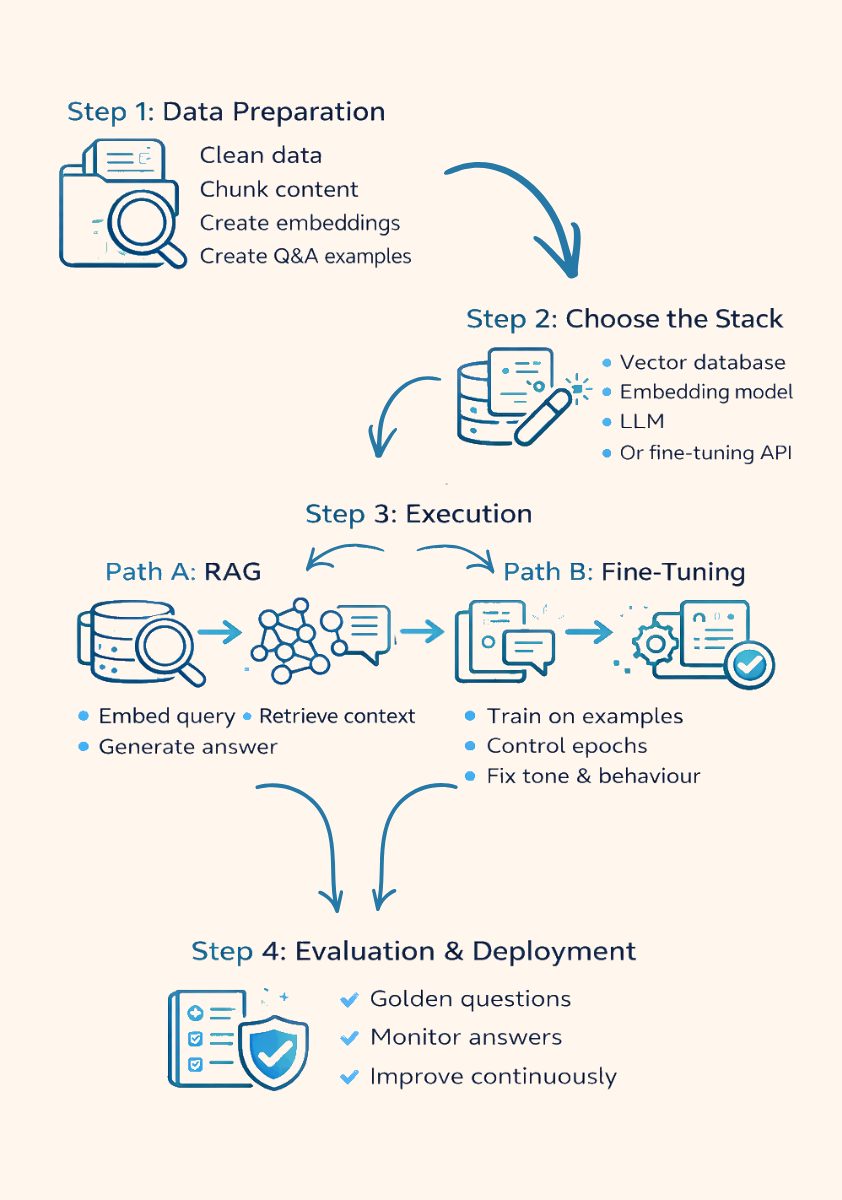
How to Train AI on Custom Data: A Step-by-Step Guide
Training AI on custom data does not mean building a model from scratch. In most cases, it’s about using the right approach for the right problem and keeping the system simple.
Whether the goal is to train an AI model using RAG or train OpenAI with your own data using fine-tuning, the steps below make the process easy to follow.
Step 1: Data Preparation
Everything starts with data. If the data is unclear or messy, the AI will give unreliable answers.
For RAG: Chunking and Vectorising Documents
RAG works by letting the AI look up information instead of memorizing it. To make this work:
- Clean documents and remove outdated information
- Break content into small, meaningful chunks
- Convert each chunk into embeddings so the AI can search by meaning
This allows the AI to find the right information when a question is asked. When documents change, they can be updated without retraining the model.
For Fine-Tuning: Creating JSONL (Question/Answer) pairs
Fine-tuning teaches the AI how to respond using examples.
This requires:
- Clear question-and-answer pairs
- Consistent tone and structure
- Only high-quality examples
A small number of good examples works better than a large set of poor ones.
Step 2: Choosing Your Stack
The tools used should match the chosen approach.
For RAG:
- Vector databases like Pinecone, Weaviate, or Qdrant store document embeddings
For Fine-Tuning:
- Fine-tuning APIs like OpenAI or Hugging Face handle training
To connect everything:
- Frameworks such as LangChain or LlamaIndex
- Embedding models from OpenAI, Gemini, or Cohere
Using common, well-supported tools keeps the system easier to maintain.
Step 3: The Execution
This is where the system starts working.
Path A: RAG execution
In a RAG setup:
- The user query is converted into an embedding
- Relevant document chunks are retrieved from the vector database
- Retrieved content is passed to the model as context
- The model generates an answer based on that context
This approach keeps information fresh and easy to update.
Path B: Fine-Tuning execution
In fine-tuning:
- The model is trained on prepared JSONL examples
- Training runs over multiple epochs
- Epochs must be controlled to avoid overfitting or loss of general knowledge
Fine-tuning is most effective when behaviour and tone need to stay consistent.
Step 4: Evaluation & Deployment
Before going live, the AI should be tested using a golden dataset a small set of questions with known correct answers.
This helps confirm:
- Answers are correct
- Responses stay within defined rules
- Errors and hallucinations are reduced
After deployment, real user questions should be monitored and used to improve data or training over time.
Common Pitfalls and How to Avoid Them
Even with the right approach, many AI projects fail due to avoidable mistakes. These issues don’t usually come from the model itself they come from how the system is designed and how the data is handled. Understanding these pitfalls early can save time, cost, and rework.
Garbage In, Garbage Out
No model can fix bad data. Clean, well-structured data matters far more than model size or sophistication.
If your documents are outdated, contradictory, or poorly written, the AI will confidently produce incorrect answers. This often leads teams to blame the model, when the real problem is the input. Before training or indexing data, it’s essential to remove duplicates, resolve conflicts, and clearly define rules or policies.
In practice, a smaller model with clean data almost always performs better than a larger model trained on messy inputs.
Hallucinations vs. Omissions
RAG and Fine-Tuning fail in different ways, and it’s important to recognize the difference.
With RAG, the most common issue is omissions. If relevant information isn’t retrieved due to poor chunking or weak embeddings, the model answers without full context. The response may sound reasonable, but misses critical details.
With Fine-Tuning, the risk is hallucination through overconfidence. When a model is trained too aggressively or on narrow data, it can forget general knowledge. This is known as catastrophic forgetting, where the model confidently provides incorrect or incomplete information outside its training scope.
Careful testing and balanced training help reduce both problems.
Over-Engineering
One of the most expensive mistakes is trying to train your own language model from scratch when it isn’t necessary.
Training a full LLM requires massive datasets, specialized hardware, and ongoing maintenance. For most business use cases, this effort adds complexity without meaningful benefits. If the goal is to answer questions using internal knowledge, RAG can usually solve the problem faster and at a fraction of the cost.
The simplest solution that meets the requirement is often the best one. Starting with RAG and adding fine-tuning only when needed keeps systems flexible and manageable.
The Future
The way teams train AI on custom data is changing fast. The focus is shifting away from heavy infrastructure and complex pipelines toward lighter, more efficient methods and simpler platforms that reduce operational overhead.
PEFT and LoRA
Traditional fine-tuning is expensive because it requires updating a large number of model parameters. This is where PEFT (Parameter-Efficient Fine-Tuning) techniques like LoRA (Low-Rank Adaptation) come in.
Instead of retraining the entire model, these methods update only a small subset of parameters. This dramatically reduces memory and compute requirements. As a result, it’s now possible to train LLMs on custom data using a consumer-grade laptop or a modest cloud instance.
This makes fine-tuning more accessible for smaller teams and startups, especially when the goal is to adjust tone, format, or behavior rather than inject large amounts of new knowledge.
AI Platforms
Another major shift is the move away from fragmented toolchains. Managing separate tools for embeddings, vector databases, retrieval pipelines, deployment, and monitoring adds unnecessary complexity.
Platforms like Geekflare AI aim to simplify this process by bringing key parts of the pipeline into a single dashboard. Instead of stitching together multiple services, teams can manage model access, deployment, and data handling in one place.
RAG capabilities are already available through Geekflare Connect’s Data Dources option. Businesses can already upload proprietary data to Data Sources and query internal information securely. This BYOK (Bring Your Own Key) approach keeps costs predictable and gives teams control over their AI usage without building custom infrastructure.
What this means in practice
The future of AI training on your own data is not about bigger models, it’s about smarter workflows. Efficient fine-tuning methods and integrated platforms make it easier to start small, stay flexible, and scale only when necessary.
For most teams, this means faster experimentation, lower costs, and far fewer operational headaches.
FAQs
Pre-training is the process where a language model learns general language patterns from massive public and licensed datasets. This phase is extremely resource-intensive and is handled by model providers.
Fine-tuning happens after pre-training. It adapts an existing model to behave in a specific way using a much smaller, focused dataset. Fine-tuning does not teach the model general knowledge from scratch it teaches it how to respond according to a defined style, structure, or domain logic.
The amount of data depends on the approach.
For RAG, the focus is on document quality, not volume. Even a few well-written documents can be enough if they clearly cover the required knowledge.
For fine-tuning, hundreds of high-quality examples are often sufficient. Clean, consistent examples usually perform better than thousands of loosely defined ones.
In most cases, yes. RAG avoids training costs because the model is not retrained. Updates only require adding or modifying documents, which keeps ongoing expenses low.
Fine-tuning involves compute, time, and engineering effort. While techniques like PEFT and LoRA reduce costs, fine-tuning is still more expensive than RAG for use cases with frequently changing data.
Yes. Some platforms allow teams to upload documents and query internal data without building custom pipelines.
For example, Geekflare AI provides Data Sources where businesses can upload documents and use them to query internal information. With a BYOK (Bring Your Own Key) approach, this becomes a cost-effective way to start AI training on your own data without writing code or managing infrastructure.




